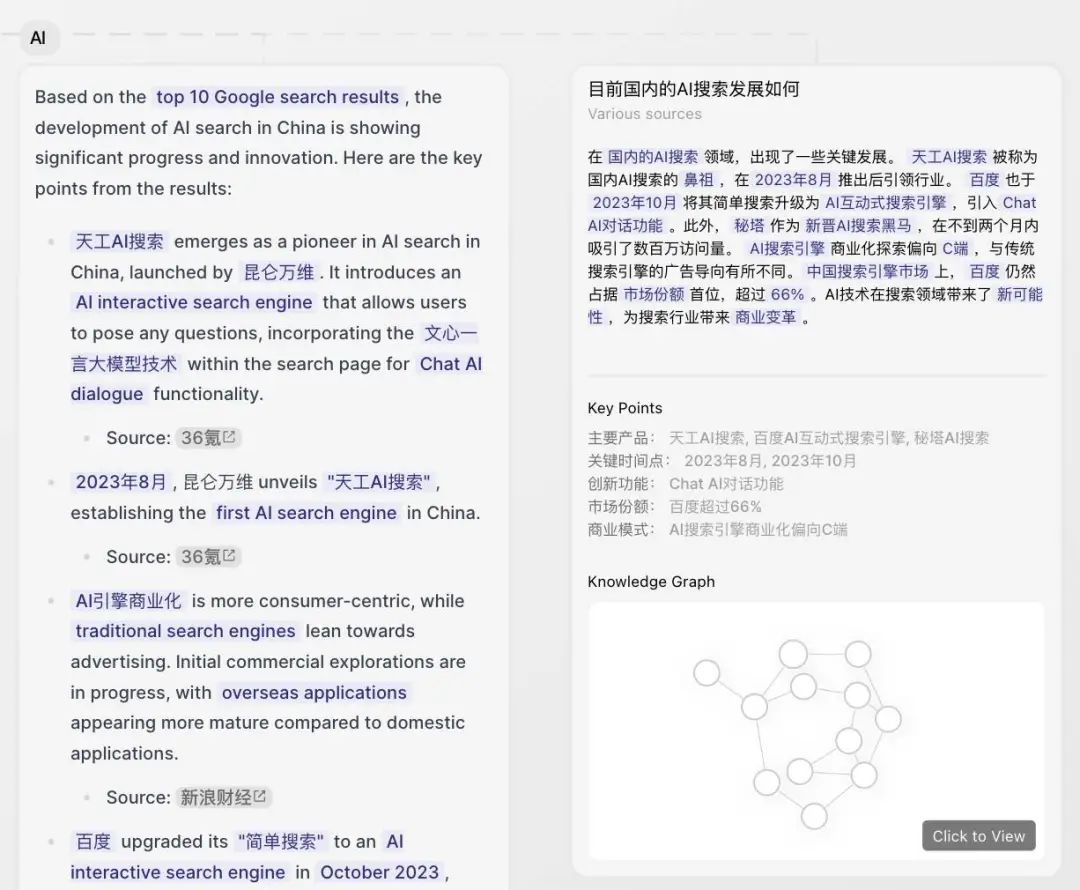
iPhone 1 问世的时候,全球智能手机的渗透率在 10%,已经跨过了 5% 的基本门槛。iPhone 是在智能机品类内的一种革新,并没有创造新的品类。实际上,一代 iPhone 多为 iPod 的换购用户,增量用户一般,一直到 iPhone 4 实现了明显的差异化 ID 设计后,iPhone 的销量才大涨。
苹果的崛起,背后是功能机向智能机升级的浪潮。即使没有 iPhone ,智能机的价值也是确定的,以通讯为核心,兼容上网、拍照和音乐的功能。
在某种意义上,智能手机是一种组合式的创新。
XR 则是一种全新的品类,自 1968 年萨瑟兰在实验室捣鼓出它的初代模型后,XR 一直在解决它在软硬件层面的技术缺陷,而从未达到过一种完整可用的状态。
也因此,它也就从未接受过大规模的用户审视。
一款产品,只有越过 5% 的渗透率门槛,才能说建立了消费者习惯,而 XR,根据 statista 的数据,2023 年 VR 头显的渗透率不足 1.3%(相对于整体目标市场),AR 的出货速度虽然有大幅增长,但绝对总量可以忽略不计。
如果以 Quest Rift 发布作为时间节点,那么 XR 从 16 年到现在,已经发展了 8 年。
当然,如果以 20 年更加成熟的产品 Quest 2 来计算,XR 至今发展了 4 年。
说惨也不惨,毕竟折叠屏手机从柔宇 18 年发布第一款消费级折叠手机开始,到现在也就 1% 的渗透率(中信数据)。
大哥不笑二哥。
根据Harry Dent的观点,渗透率低于 10%,产品尚处于导入期,发展会相当缓慢。
这也不奇怪,根据创新扩散曲线,新技术的使用者往往是技术爱好者,这批人才占总体市场的 2.5%,就算全覆盖也白搭,只能作为产品使用的种子。
如果再细一点来看,按照技术成熟度曲线,XR 的市场期望已经过了上升期和峰顶,正处于滑入低谷的阶段,各路媒体不断唱衰,国内爱奇艺、PICO 和腾讯的 XR 裁撤,Quest 3 销量不及预期,都给市场预期撒了一把盐,幸好24 年初果子哥奶了一把,不过等热度过去,估计早期购买者各种吃灰的新闻就要层出不穷了。
这一阶段渗透率常常远低于 5%,也符合 XR 目前的现状。
按照一般的推算,滑入低谷距离进入成熟期,一般要 5-10 年,渗透率能够达到 5%;再用 2-5 年,渗透率从 5% 提升到 20%,再用不到 2 年的时间,渗透率提升到 50%,产品进入成熟期。
所以,乐观的估计,XR 如果想成为和手机一样的产品,就算价值已经被充分验证,达到成熟期也还要 8 年左右。
如果不乐观,这个时间可能还要翻一倍。
那怎么提高渗透率?
路径也很清晰,最初聚焦技术爱好者(功能不敏感但价格敏感)和早期采用者(价格不敏感但功能敏感),然后聚焦细分市场,一点一点积累客户案例(充分的使用案例),滚雪球壮大,把早期大众吃掉,渗透率差不多就到了 50%。
产品生命周期、技术成熟度、创新扩散曲线,这些概念都不新鲜,只是分析商业逻辑的基本工具。
或许理论会过时,也不适用新的技术,但也能给我们提供参考。
指望 AVP 一下子把 XR 行业提升到成熟期是不可能的,没有人能够违背事物的基本规律。
但 AVP 重新唤醒了投资者和目标用户的兴趣,这可能是它最大的功绩。当然,还有给行业秀一下果子的解决方案,在软硬件和宣发侧提供些参考价值。
基础的判断建立以后,大概可以明确一个观点:XR 还需要至少 8 年的发展,没有谁能够一蹴而就,整个行业的玩家都要一起努力,踏踏实实,构建更多的产品用例。
在这个共识之下,我们回过头来看 XR 的基本价值。
01
先明确一个概念,所谓 XR,其实泛指 VR、AR 和 MR 在内的所有虚拟现实形态,其中也包括苹果自己搞的空间计算,算是 VR+MR。
- VR:完全的虚拟现实,与现实没有互动
- AR:以现实为主,一些基本信息叠加在现实环境中,作为现实环境的增强,但不会改变现实环境
- MR:虚拟与现实融合,虚拟物体可以与现实实现互动,改变现实的某些状态
光听概念,其实挺绕的,而且概念之间也扯不清楚。
就说 VR 吧,自己完全虚拟一个游戏世界,不与现实搭边,这很好理解,是典型的 VR 场景。可是如果把现实世界的某处景物原封不动地 3D 建模,比如之前影视飓风扫描的庐山场景,这是虚拟还是现实?
又或者再进一步,用数字孪生,通过 3D 建模+传感器,实时显示某座工厂的当前状态,并根据传感器状态实时调整工厂相关设备的参数,这就算是 MR 了吗?
AR 的概念也很奇怪,它和 MR 之间又扯不清楚,比如前段时间热门的虚拟钢琴游戏,道理上讲它只是显示虚拟的音符,真正操作的是用户自己,而不是 AR 设备直接和钢琴通信,更改状态。那这算是虚拟与现实交互了吗?
如果通过提示信息而让使用者通过物理行为更改现实物体的状态也算的话,那这个边界又可以无限扩大。
所以,与其区分或者纠结 VR、AR 和 MR 的概念,不如换一种定义,根据它们的技术路线,简单分为眼镜和头显 ,反而要清爽很多。
本质上,无论是哪种 R,实际上只有两种硬件形态,而任一形态也都可以实现任一种 R。
在侧重点上,眼镜更看重设备的便携性,而头显则更看重设备的渲染能力,这是两者的根本分野。
选择眼镜的厂家,是希望设备能够被用户随身携带,最终目标是和正常的眼镜一样;而选择头显的厂家,则更看重在设备本身所能实现的性能。
这就和笔记本一样,最早是主机,后来是便携笔记本,再后来又有了超薄笔记本,便携和性能的取舍一直是电子设备的矛盾点。
理想的情况下,我们渴望的是既轻便又有强空间计算能力的 XR 设备,但当前的技术水平下可能是一种妄想。
更现实来看,眼镜和头显这两种硬件形态会始终并行存在,各自针对不同的使用领域。
由于性能的限制,头显所能实现的其实是智能眼镜的全集。那我们不妨先从头显聊起,看看一个完全形态的产品,它的媒介特性究竟是怎样的(我们假设头显 VST 的渲染和延时都在理想状态,和眼镜的光学无二)。
02
头显作为一种媒介,最核心的特质在于创造了一个自由支配物理规则的虚拟空间,从而实现对于现实的模拟和再造。
这里面最最核心和关键的就是空间,也可以叫「空间化」。
人类创造的所有媒介形态,其实都是对现实的模拟和再造,摄影是、绘画是、电影是,就连动画也算。
它们都是对现实的模拟,区别只在于抽象程度。又由于掌握了物理规律,人类可以对现实进行再造,比如让动物讲话,或制造仿真软件,这让实验科学能够进一步拓展。
头显的最大贡献在于,它让媒介形态从平面转为空间。
这与 2D 同 3D 的对比不同,空间化的最大区别在于把观看者纳入了空间中,而非游离在空间之外。
一个新的元素「空间化」,再加上人类原先积累的对于现实模拟和再造的经验,就可以真正创造出真正意义上的赛博空间。
当然,这只是思辨意义上的快乐,宝珠也会蒙尘,一件事物不会因为它很有意义而被大众广泛使用,即使具备「空间化」的特点,头显也仍然要结合具体的情境讨论,在每个细微场景下它的实际用途。
讨论最重要的是问对问题。
那么最不会出错的问题是:什么样的场景需要「空间化」?
乐观主义者会觉得这是一个不言自明的问题,谁会不想要一个赛博空间呢?《神经漫游者》、《黑客帝国》、《盗梦空间》…我们不就活在这样的文化氛围中吗?
这样想当然没错,但想象是所有活动中最省力的一种。
头显只能提供提供「空间化」的能力,真正创造出赛博空间依赖于愿意为此投入时间、精力、金钱等各种资源的人。
这就好比PC带来了「信息化」,手机带来了「互联化」,可真正让 PC 走入千家万户是因为它对于信息的存储和对于数据的计算处理,而手机则由于它的通讯能力被广泛使用。
我们现在似乎把 PC 和手机都当成了一个平台,上面有各种应用。但它们都有一个核心的根,甚至这个根在最开始就是清楚明晰的,平台只是在这个根的基础上长出的果。
而头显的根又是什么?
以及,从商业化的角度,头显是否真的存在和信息存储、数据处理和通讯同等量级的市场?
03
追溯头显的历史,最早运用在飞行领域,用于夜间导航(红外成像显示人眼无法察觉信息),汤姆.福内斯的超级驾驶舱项目,简化了原先繁复的仪表盘,而以头显搞出了一套全新的交互。
这些的核心在于头显的佩戴方式:以平视的视角捕捉和呈现信息,同时不遮挡外界环境。
信息叠加在真实空间之上,对真实世界的物理状态予以提示,佩戴者可以所见即所得,直接通过虚拟屏幕进行相关操作,实现对佩戴者操作效率的提高。
头显对于需要复杂信息处理和操作的作业环境都可以起到作用,平视佩戴+可视化数据+信息处理(核心是空间化带来的多窗口和动态拟真)促成效率提升和错误率降低。
这条路很多公司都在走,微软、联想都注重工业场景。
操作场景外,头显对于制造业也有较大的作用。硬件制造需要原型设计,头显的空间化使得零部件得以具象化,虚拟空间的组装将极大地节省如汽车、飞机等精密机器的制造。
头显和 3D 打印一样,拥有改造传统工作流的能力。
零售业也同制造业类似,本质上都是要低成本提前呈现还没有确定的产品形态,并能够灵活调整,这就是比特相比物理分子的优势。
服装在线试穿可能还有些困难,但装修是确定可做的方向。
归纳起来,XR 能够为制造业、工业带来的是降本、增效、缺陷降低,为零售带来转化率的提升(不确定性降低)。
04
教育是另一种可能。
最早萨瑟兰创造虚拟头显时,其目的就是为了使得抽象事物可视化,他的原话是:
我们生活在一个物理世界中,通过长期的熟悉,我们已经对这个物理世界的特性了如指掌。我们对这个物理世界有一种参与感,这种参与感使我们能够很好地预测它的特性。例如,我们可以预测物体会落在哪里,从其他角度看众所周知的形状是怎样的,以及在摩擦力作用下推动物体需要多大的力。但我们对带电粒子的力、非均匀场中的力、非投影几何变换的影响以及高惯性、低摩擦运动缺乏相应的了解。与数字计算机相连的显示器让我们有机会熟悉物理世界中无法实现的概念。这是一个数学仙境的望远镜。
第一台虚拟头显(完全电脑渲染内容)呈现的内容是一颗环乙烷分子,佩戴者可以从各个角度观察它的结构。
这充分体现了头显「空间化」的特点,佩戴者不再只是看,而是真正可以和环乙烷分子互动,在不同视角观察它的结构,再进一步,甚至可以观察不同分子的合成过程。
对于教育或者学习而言,抽象事物空间化是尤为重要的事,我们生活在物理空间,所以习惯以空间化的方式思考事物,抽象化->具象化->可视化->空间化,通过这样的递进而使得事物被最终理解。
比如「局部最优解」和「梯度下降」远不如小球在凹凸的山丘上滚动来的直观,如果能够直观地在空间中看到它的演变过程,理解就会更加方便。
即使信息本身是抽象的,但它的交互方式如果能够转变为空间化,就会激发人的空间思考方式。
一块虚拟空间下的无限画布,多角度、多平面。不同平面间的白板结构本身就会激发新的思考,在空间下的走动也会促进灵感。
空间化单纯从结构上来说也能带来新的信息组织和思考行为。
但教育是内容导向的产业,需要专业领域的知识背景+合理的空间可视化编排,事实上即使是如今的视频时代,整体的教育方式也还是以书面文字为主,可视化的方式都还没有普及,空间化更任重道远了。
05
文旅、现场表演/展览/展示、影视也会有较大的应用场景。
海利格在 1957 年拍摄了纽约的街头景象,把它装到一台巨大的机器中,观众可以看到立体的纽约街头景象,感受风、声音和气味。
58 年后,《纽约时报》重新拍摄了纽约的街头景象,佩戴者通过 Oculus Rift 即可漫步纽约街头,并与故事中的人物互动。
头显的一大核心特质是对于穿越时间和空间的限制(空间化+自定义的物理规则),对于旅行来说,交通是一种阻碍。
景区可以通过对于实景的建模,再造一个真实的虚拟环境(搭配物理引擎),从而突破空间的限制。
头显另一难以复刻的魅力是:它是一辆时间列车,能够带你重回过去的景象,真实淌游在历史画卷中。
另外,景点的本质是稀缺性,展览、现场表演也是如此。
现场感(沉浸+社会关系)的重回,能够让供给被充分增加,话剧、演唱会、展览这些非标品可以像电影一样被二次分发,实现非标品的流媒体分发。
头显的另一大特质是对于现实环境的实时再现,结合远程在线直播将实现真正的千里眼, 在线实时直播旅行画面,跟随别人的视角;远程审厂,不用再跋山涉水;远程医疗;远程工作指导;头显对于远程会议、远程办公或许没有较大的用处,远程会议替代不了商务出行,出行带来的是一种态度,说明一种重视,同时也方便人情关系的培养;远程办公也无法替代近场办公,后者本质上是一种物理意义上的掌控。
而对于影视而言,头显所带来的则是无与伦比的沉浸感,虽然用户的自由选择会是一种困扰,但虚拟叙事已经探索出了微互动的路径,技术问题不会成为一种困扰,只有内容制作的成本和新的叙事逻辑需要琢磨。
只要体会过《纸鹤》、《花房姑娘》等 VR 作品的观众,不会怀疑它在叙事上的巨大魅力。
06
说到沉浸感,就不得不聊聊游戏,相比于影视,虚拟游戏带来的是沉浸感+互动感,仿佛一个真实的虚拟世界。
但主机游戏都有上限,且价格下探到 2000 元以内的价位,才能有一定的市场竞争力。
直面 C 端的产品,除了内容本身外,硬件本身就有成本。除非有相对丰富的内容供给,否则难以说服消费者购买。但是它的上限可能就是 Switch,远不是手机这个量级。
头显自诞生起,大家就看好它在游戏上的前景。
从 1990 年左右雅利达和任天堂就开始尝试,受限于硬件没有成功,一直到 Quest 2 带来新的浪潮。
几个游戏硬件的天花板:PS2 和 NDS 大概 1.5 亿台,Switch 大概在 1.3 亿台,现在 Quest 2 大概 1800 万,比照老大哥们,未来的市场容量差不多也就是亿级。
没有人怀疑沉浸感这件事,但一直强调沉浸感可能是个问题。
即使是《阿斯加德之怒 2》,它固然无比沉浸,但没有让我有想长时间待在里面的欲望。我把原因归结为:没有人喜欢呆在一个空寂的世界,哪怕是鲁滨逊还有星期五陪着。
社会交往这件事很重要,它不是社交,而是一种氛围,这种氛围带来一种熟悉感和群体的归属感。
为什么玩游戏时要透视现实环境,真的体验过就会懂,当你完全沉浸时是蛮孤独的一件事,陌生的环境里只有你一个人。
而人是要时刻感知周围环境的,不然会有一种莫名的恐惧,透视现实环境实际上带给人一种安全和稳定,它是一个参照的锚点。
当获得沉浸感的时候,玩家丧失的是对现实的感知,熟悉感和安定感,带来了负面产物——孤独感。这些在你玩 Switch 或者 Steam 的时候是不会有的。
唯一让我不会有这个感觉的是VR Chat,因为有人。
如果虚拟游戏想要获得成功,融入社交是必不可少的,哪怕完全没有互动的环节,只要知道有人和自己一起,孤独感就会消融。
有一种可能性,可以提供社交的充分供给,即借助大模型,但这条路受限于大模型当前的能力。
Character.ai 已经在这条路上尝试,Vtuber 也在盛行,不过 Character 只公布了月活,还没有留存率的数据。Vtuber 的头部公司也还没有跑出头部的企业。归根结底,还是 GPT 本身的能力问题,还没有办法真正扮演一个人。
两个能聊得来的人,需要兴趣相投,这背后是对于兴趣话题领域专业知识的积累和独特观点的碰撞共鸣,GPT 还没有办法达到这个水平,尤其是独特观点。
从我个人的体会来看,在观点层面上,多数时间仍然在说一些正确的废话。因此,直面 C 端的 XR 内容,当下的阶段,仍然逃不开真实的社交关系链。
目前来看,真正刚需的产品都不在 C 端,但 B 端的用户很难往 C 端迁移,存在一个客户群的鸿沟。
在 C 端,似乎找不到一个如通讯、信息存储与数据处理那般刚需级的需求,它更多是体验的升级。
也因此,丰富的优质内容供给 + 社交链是这类产品的合理路径,通过提供足够多的优秀内容,来抵充硬件本身的成本。等到硬件的量大起来,再有越来越多三方的丰富应用,最终成为一个平台级的硬件。很多人吹 AIGC,但我并不特别看好。
现在缺的是优质内容,不是缺内容。
粗制滥造的内容没有意义,反而对生态是一种破坏。
真正创造好的内容的,仍然只属于少数人,专业的生产者。AIGC 能够成为他们工作流的一环,对现有的工作进行提速,那就是最大的贡献,但指望它颠覆,甚至 AI 自生成内容,就有点天方夜谭了。
它的难度可能不啻于大模型真正地理解人类语义而非是序列预测。
07
工业操作、制造业、教育、文旅…抛开功能性的需求不谈,头显想要成为平台级的硬件,最终的归宿仍然落在 C 端内容上。
那么问题来了,假设优质内容充分、社交链充分,头显真的能成为手机级的智能硬件吗?
我的看法是仍然不行。
手机最初由于硬件成为刚需,而后能够成为风靡全球的产品,离不开它的两大特性:移动化 + 碎片化。
这是被说烂的观点,但恰恰这两者与头显都是冲突的。
头显笨重,不方便携带;它的沉浸式体验恰好与碎片化是相反的。
看看我们最常干的事:刷微信、刷朋友圈、刷抖音、刷小红书、刷 B 站、来一把十来分钟的游戏。
这些事项,最大的特点就是短。
物质充裕的情况下,人类最大的痛苦就是无聊,没有一刻可以闲下来。
可是大部分时间人是无目的,人需要随便什么东西,去填补这种空虚,而又不至于特别沉浸。
头显和这种临时化的需求是天然违背的,但偏偏这又是它的天赋点所在。
网游小说里,大家在虚拟世界沉迷,要么是现实世界已经被机器人掌控了,要么是发明了夜间睡眠仓。
工业化的生活结构下,这种矛盾是注定了的。
是生活把时间分割成碎片,人是无可奈何的。
因此,头显的最大参照物仍然是电脑,它更适合完整时间下的使用,主流场景是家中。如果它的分辨率有一天到达了可工作的水平(且成本压下来),或许还能够占领办公市场,但 PC 级的出货量和使用频率,可能也是头显的极限。
08
既然头显不行,那么阉割了的智能眼镜呢?
或许可以。
智能眼镜的核心是为了便携服务的,所以它阉割了许多性能,目的是为了让眼镜做轻做小,最终可达到如普通眼镜一般在清醒时间皆可穿戴的目标。
那么阉割之后,智能眼镜所保留下来的能力,能不能让它打败手机,成为一种新的潮流?
我们可以看下空间化的具体衍生:多窗口、拟真交互、虚拟环境…哪一条可以在碎片化下生存。
关乎沉浸感或拟真的自然不可以,这与碎片化违背,也是性能消耗的大头。
那么多窗口?智能手机受限于屏幕方面,在尺寸方面已经走到了镜头。
折叠屏虽然增大了尺寸,但也不会有 iPad 的效果,而 iPad 本身的累计出货量也才刚超过 1 亿,说到底,iPad 虽然大,可也没大到能够带来全新体验的程度。
那么 XR 的多窗口,能否给信息呈现带来新的可能?
XR 的多窗口,有两个特征:一是大,所以可以铺多个窗口;二是具有空间结构,这就是所谓的空间屏概念。
空间屏突破了手机的物理限制,而使得信息以空间化的方式多屏呈现。
按照果子哥的定义,存在 Window 和 Box 两种,我们可以边刷网页(window),边逗宠(box,宠物以空间化的方式呈现)。
如果只是 window 和 box 两个层级,智能眼镜努努力还是可以达到的。但这不是智能眼镜的核心,如果这样,它仍然只是一种体验的升级,而没有带来根本性的创新。
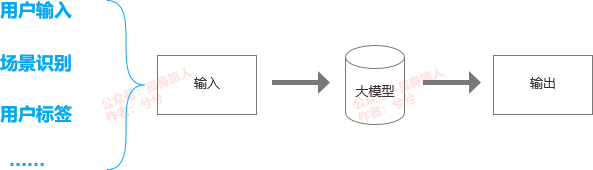
真正爆炸的组合是眼镜+空间化+多模态模型的完美搭配。
要不说上天拯救了 AR,如果不是 CloseAI(笑)带来了多模态,智能眼镜的上限可能就是观影眼镜,最多成为像 TWS 耳机一样的手机配件。
可是拥有多模态模型后,它的空间化的信息呈现方式就派上用场,它的眼镜形态也成为最完美的多模态载体。
我不想谈论个人助手的可行性,要真正实现这个目标还有一大堆事情,至少要实现 agent 之间的自调用。
我也不觉得目前的实时翻译能够帮助智能眼镜扩圈,毕竟它的使用范围有限。
拍照记录和观影可能是现阶段最大的杀手锏,这都跟多模态没有太大关系。
所以接下来谈论的仍然是一种玄学,但具有想象和令人兴奋的空间。
软件一直以来处理的是二手数据,中间需要用户作为中转。看到一件衣服,需要先拍下来,再淘宝识图,寻找到对应的商品。
智能眼镜+多模态以后,所见即所得,同时信息可以直接显示在眼前,多窗口模式下同时打开多个购物软件,旁边再有一个张大妈显示该商品的历史价格变动。
于是,整个交互流程被极大简化,多窗口带来的信息呈现优势不言自明。
人类 80% 的信息来自视觉,智能眼镜带来了实时的视觉捕捉,多模态带来了实时的语义理解。实时视觉捕捉+语义理解,将带来极多的崭新的可被捕获的视觉数据。而最终,得益于 XR 的空间化,这些数据的使用和呈现以更具效率和可视化的形式,更舒服地呈现在用户眼前。
于是,会有新的应用去处理新的数据,在新的形式下构建新的交互方式,这是智能眼镜所能带来的平台级的革命。
而年轻的冒险者们,趁着大象转身的时候,抓住新的可能。
09
当然,还有很多问题留待解决:
- 要达到 B 端的需求,设备的屏幕分辨率需要进一步提升,捕捉外界信息的摄像头也要继续升级;
- 延迟要进一步降低,果子哥已经做到 12 毫秒,其他家还差得远;
- 通信要进一步提升性能,无论是云端 WiFi 和 5G,还是设备间的本地通信(如果是分体式,计算主体和显示主体分离,当前的蓝牙显然是不够的,还需要其他的无线通讯方式);
- 新结构与 ID 造型(如何便携);
- 多模态大模型的发展(幻觉、agents、prompt、专业知识库);
- 功耗与续航;
急不得,按照商业的发展规律,至少还有 8 年,XR 设备才有可能成为主流。
耐心去解决切实存在的问题,希望我们能够构建想要的未来。