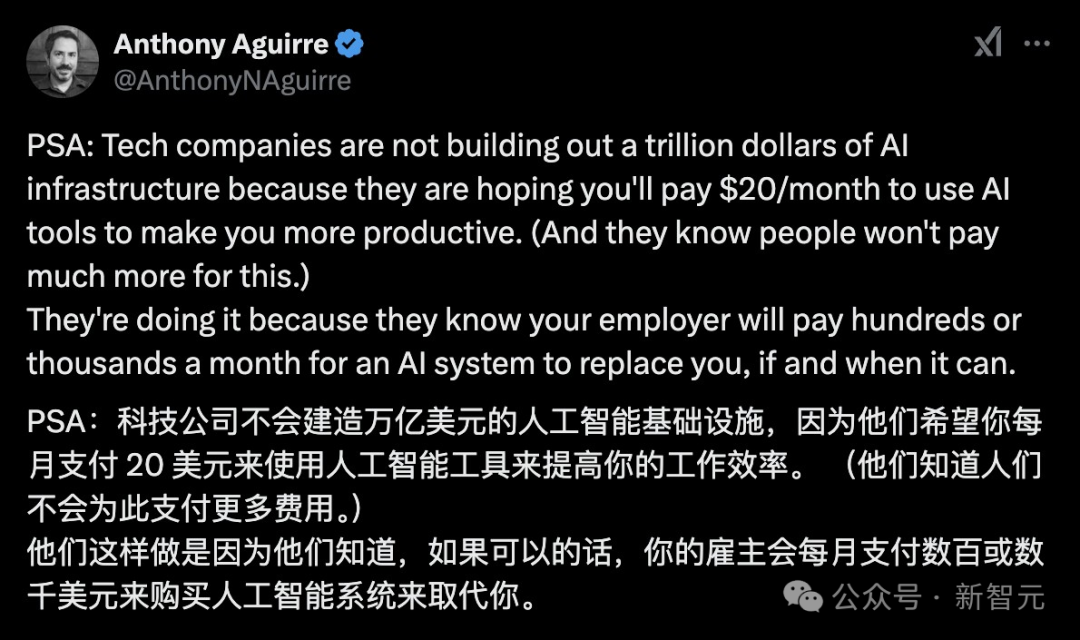
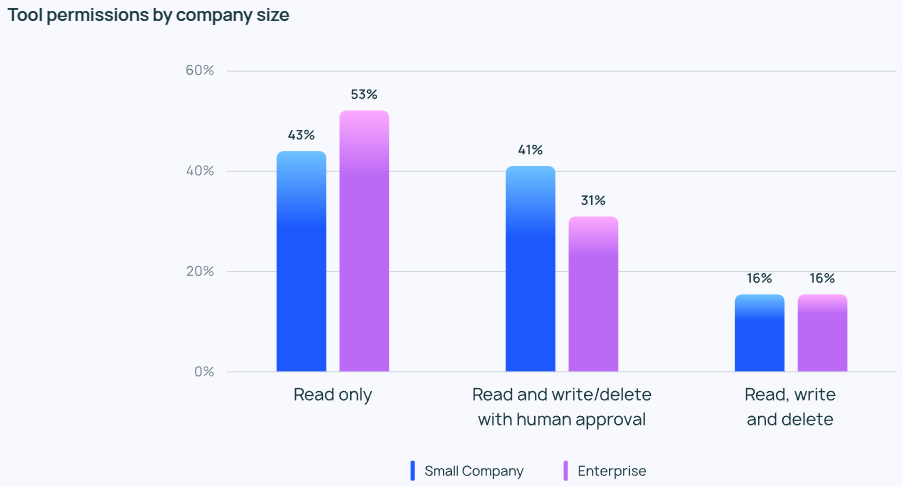
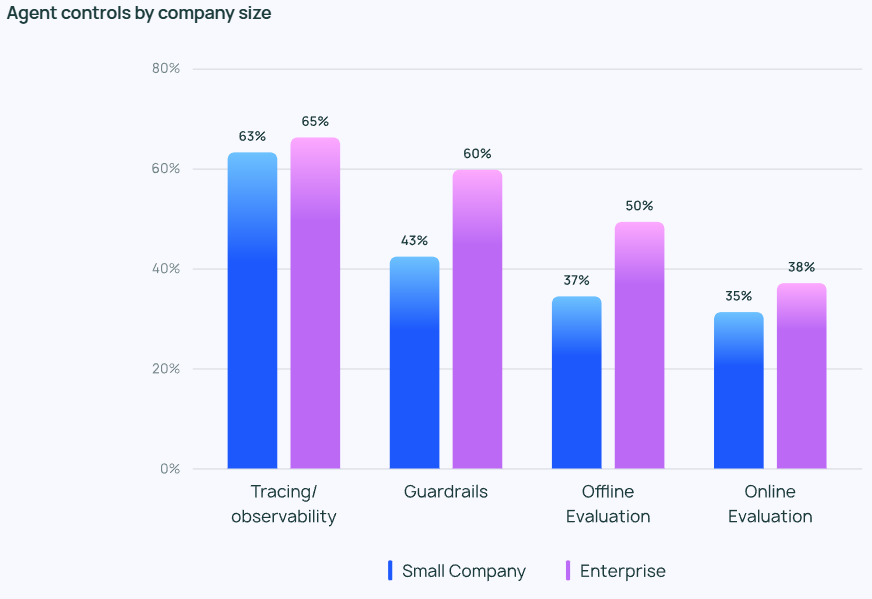
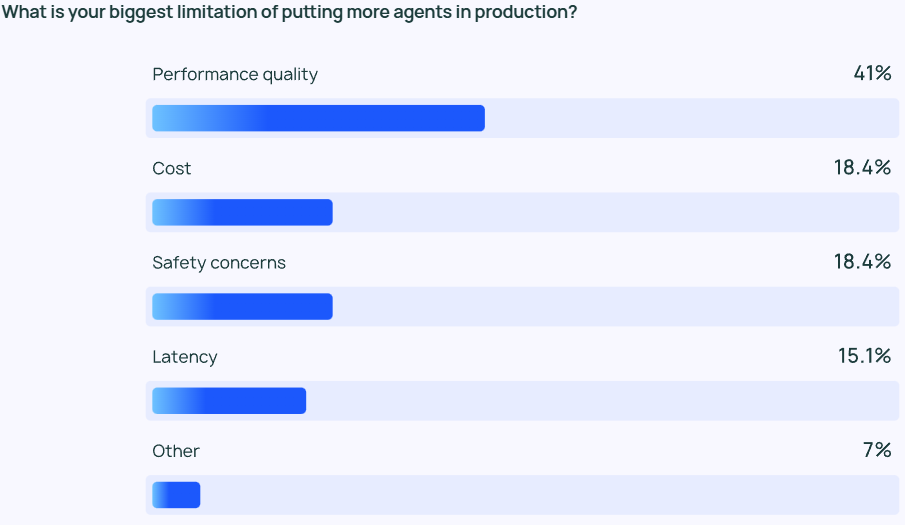
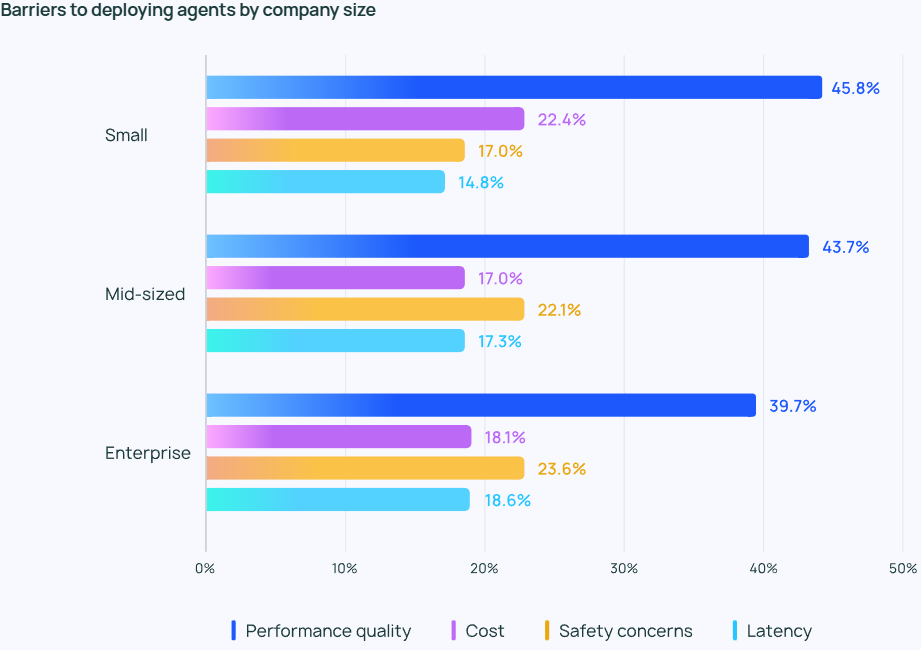
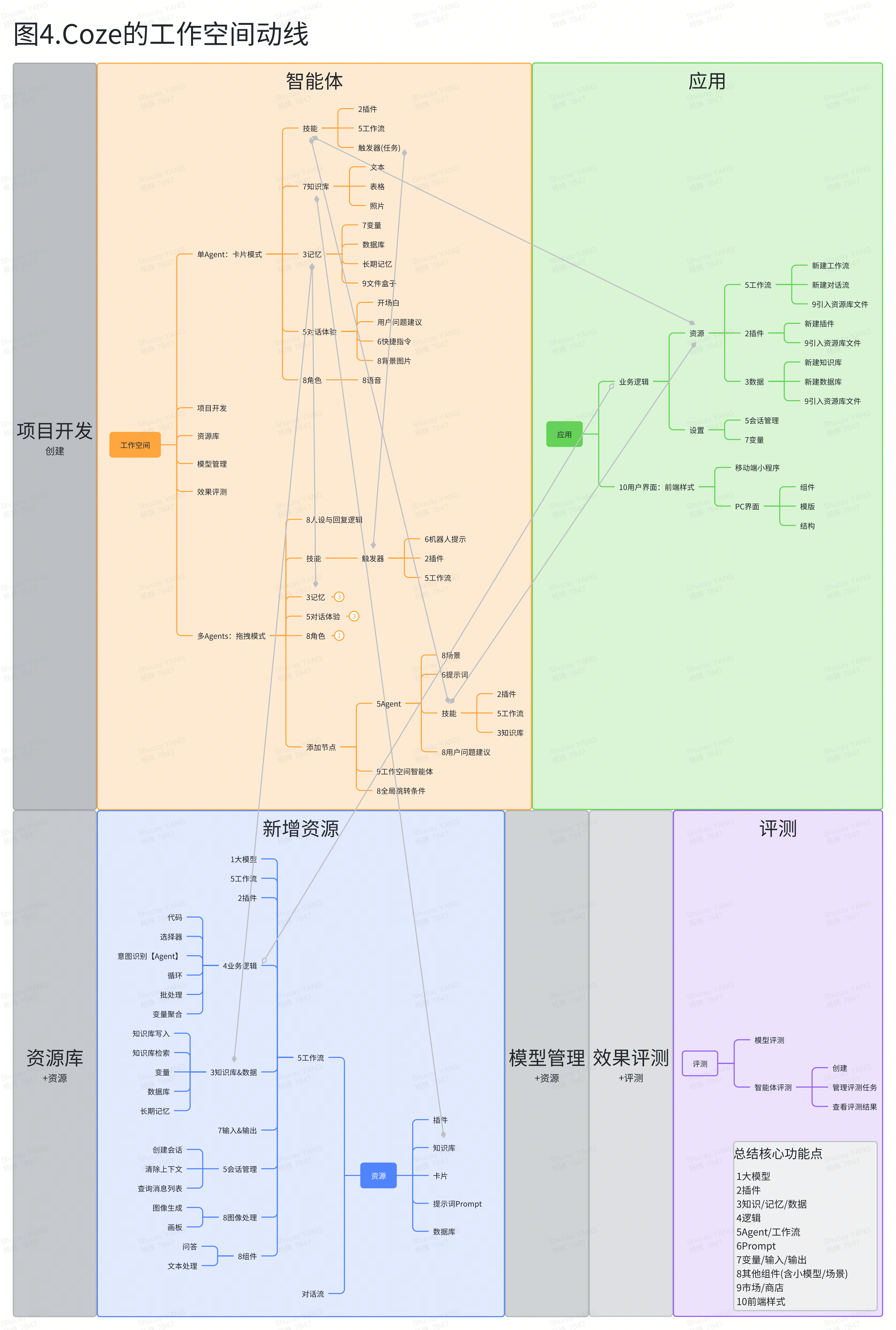
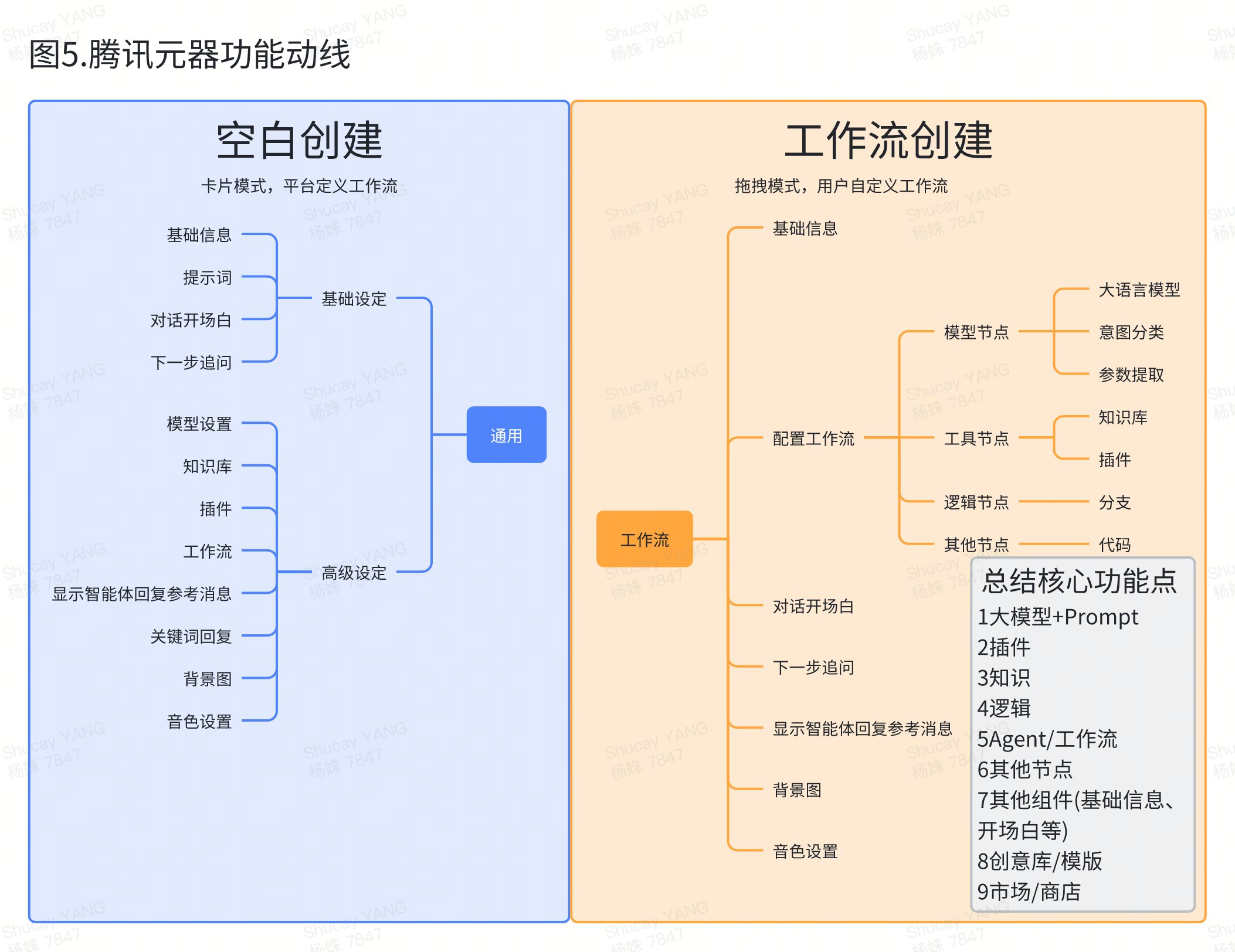
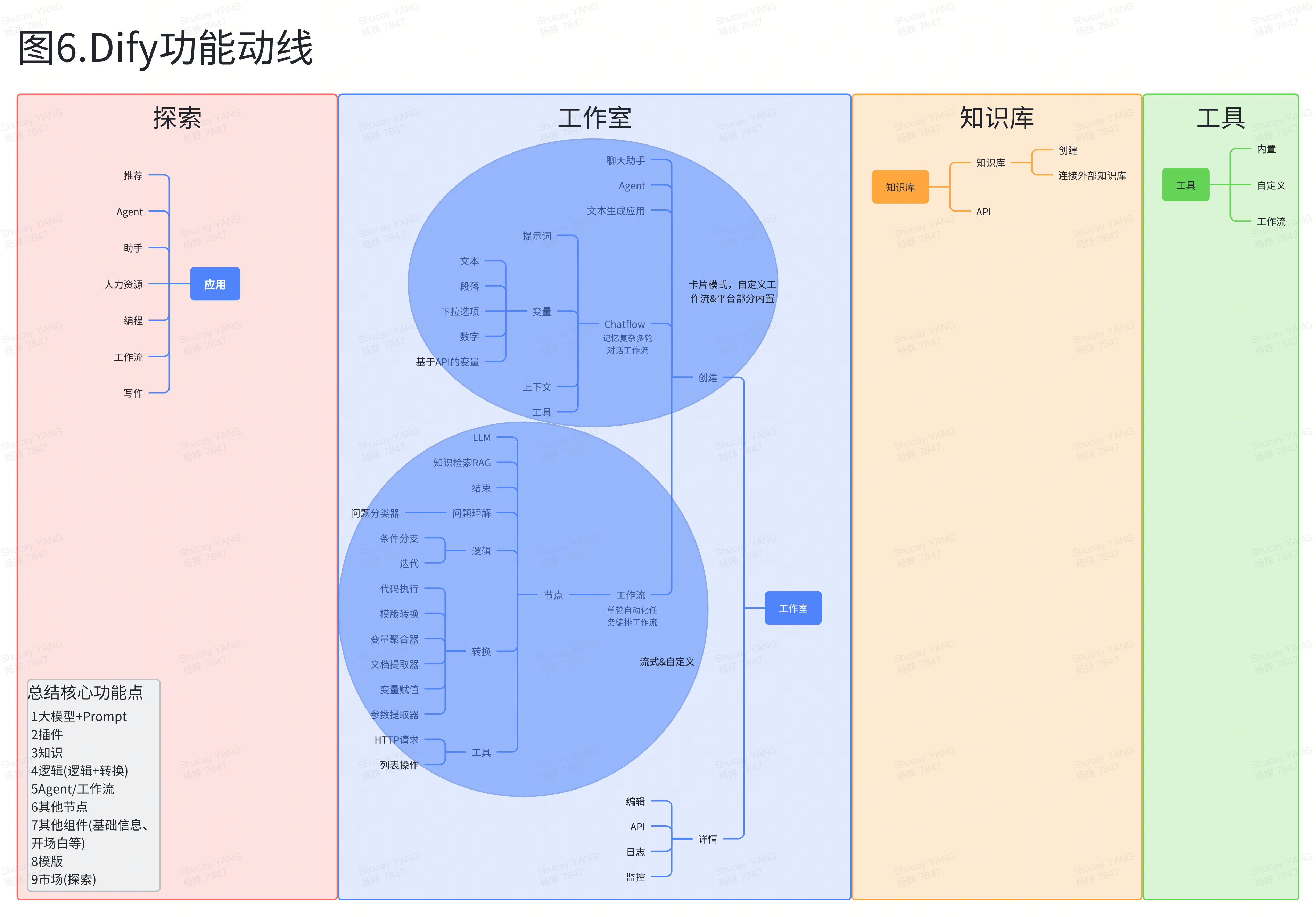
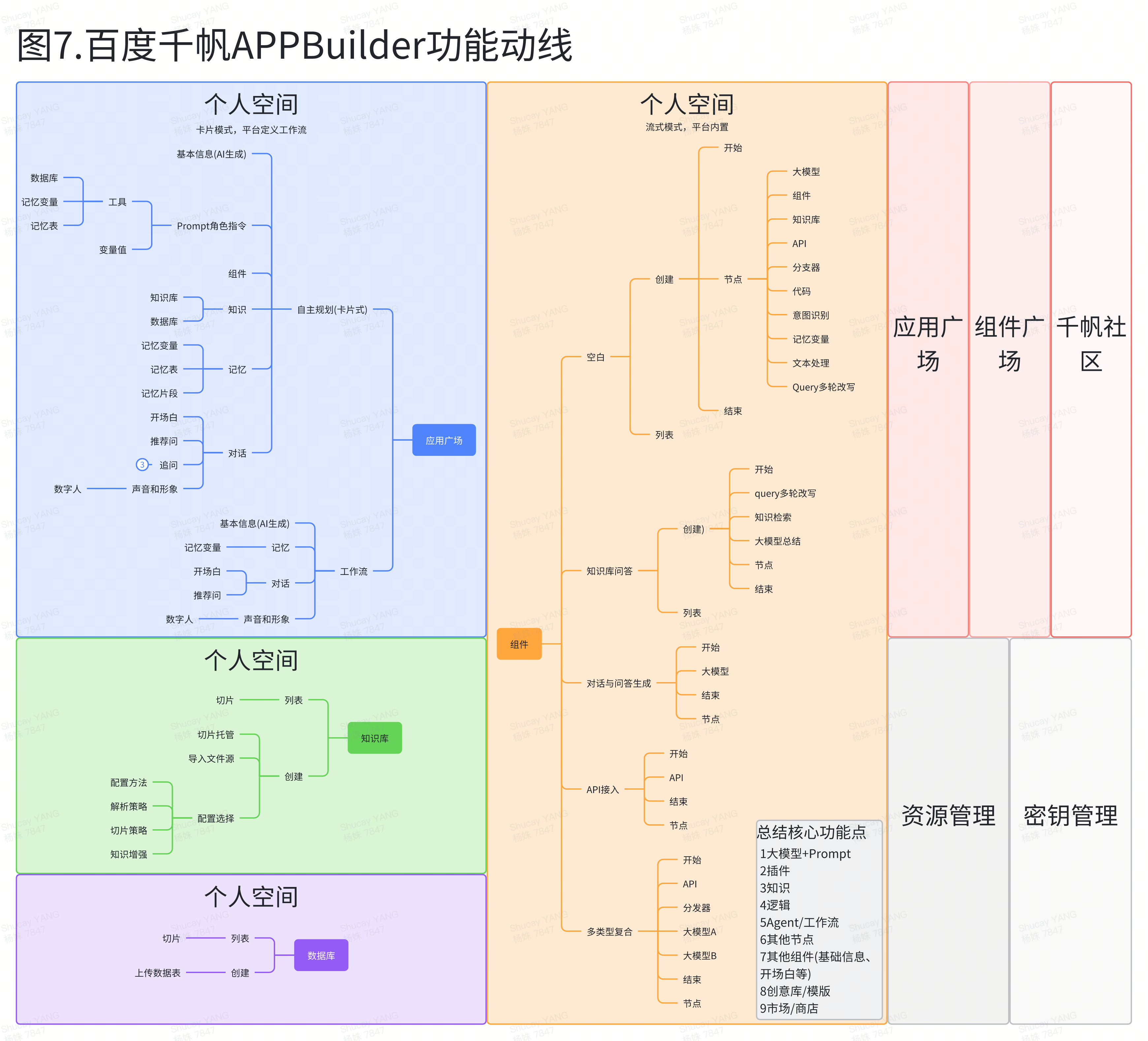
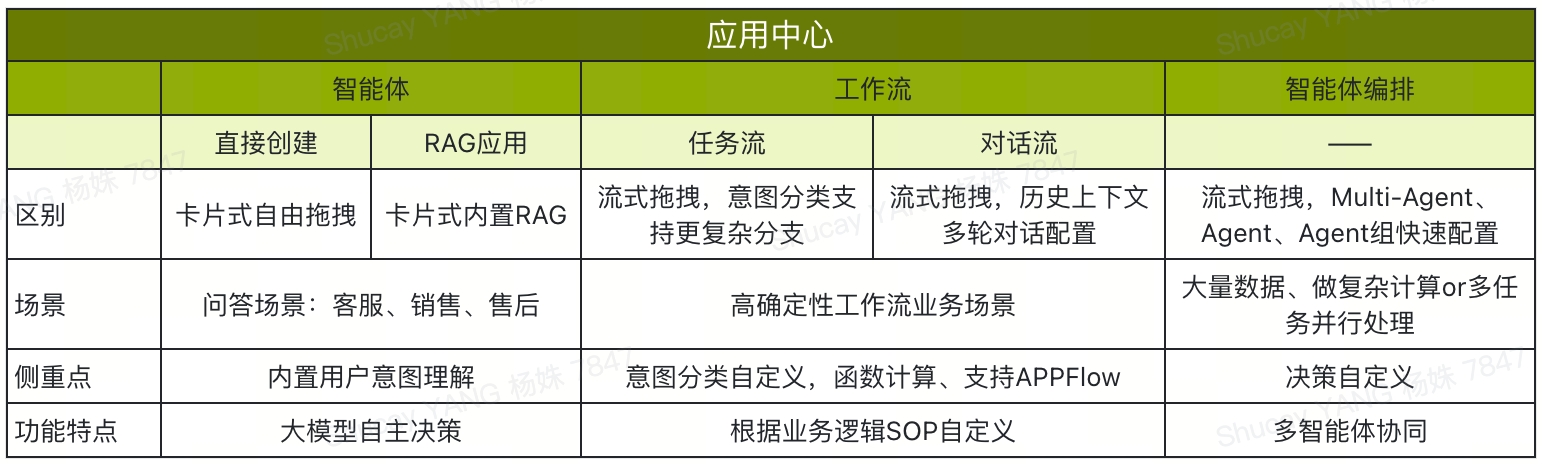
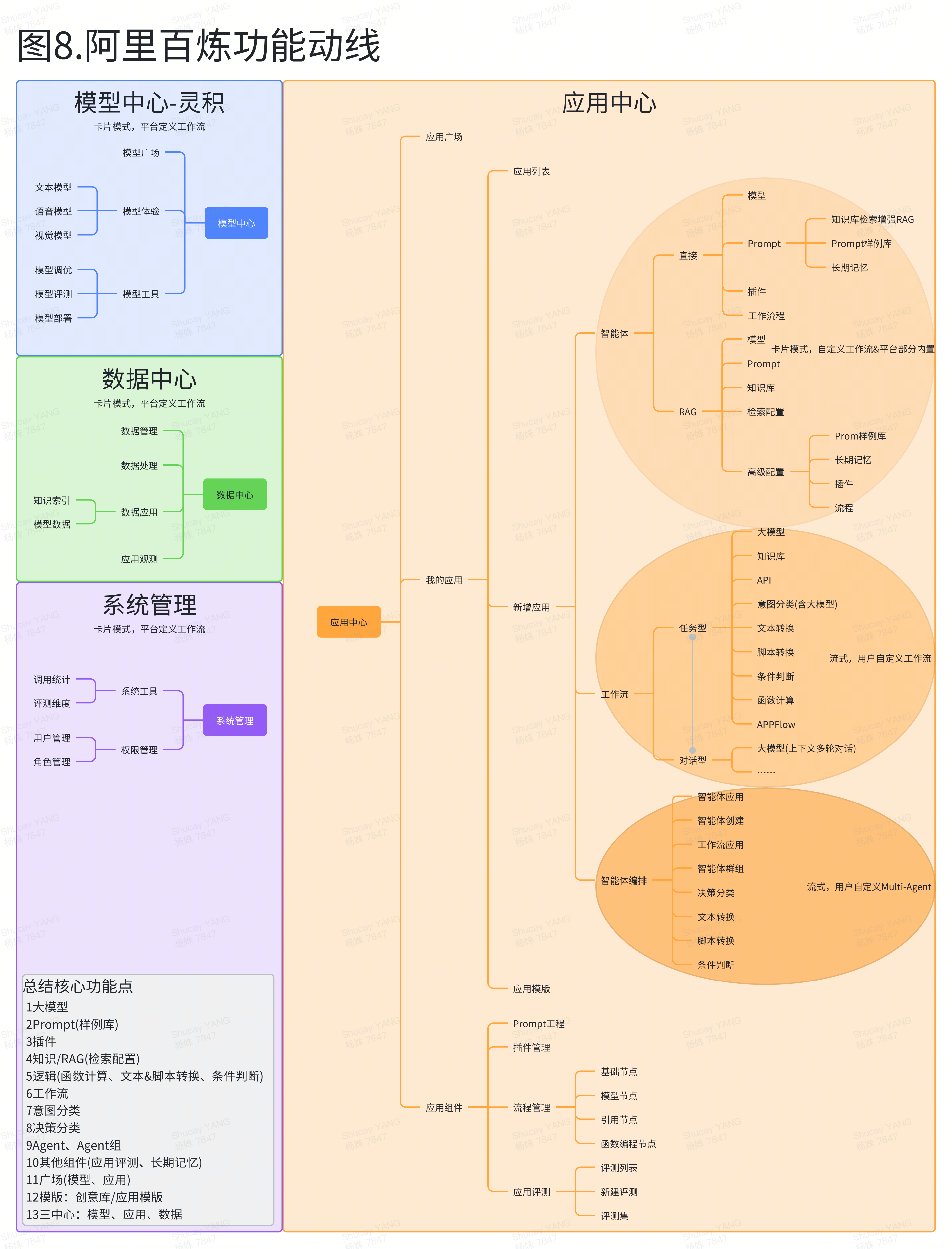
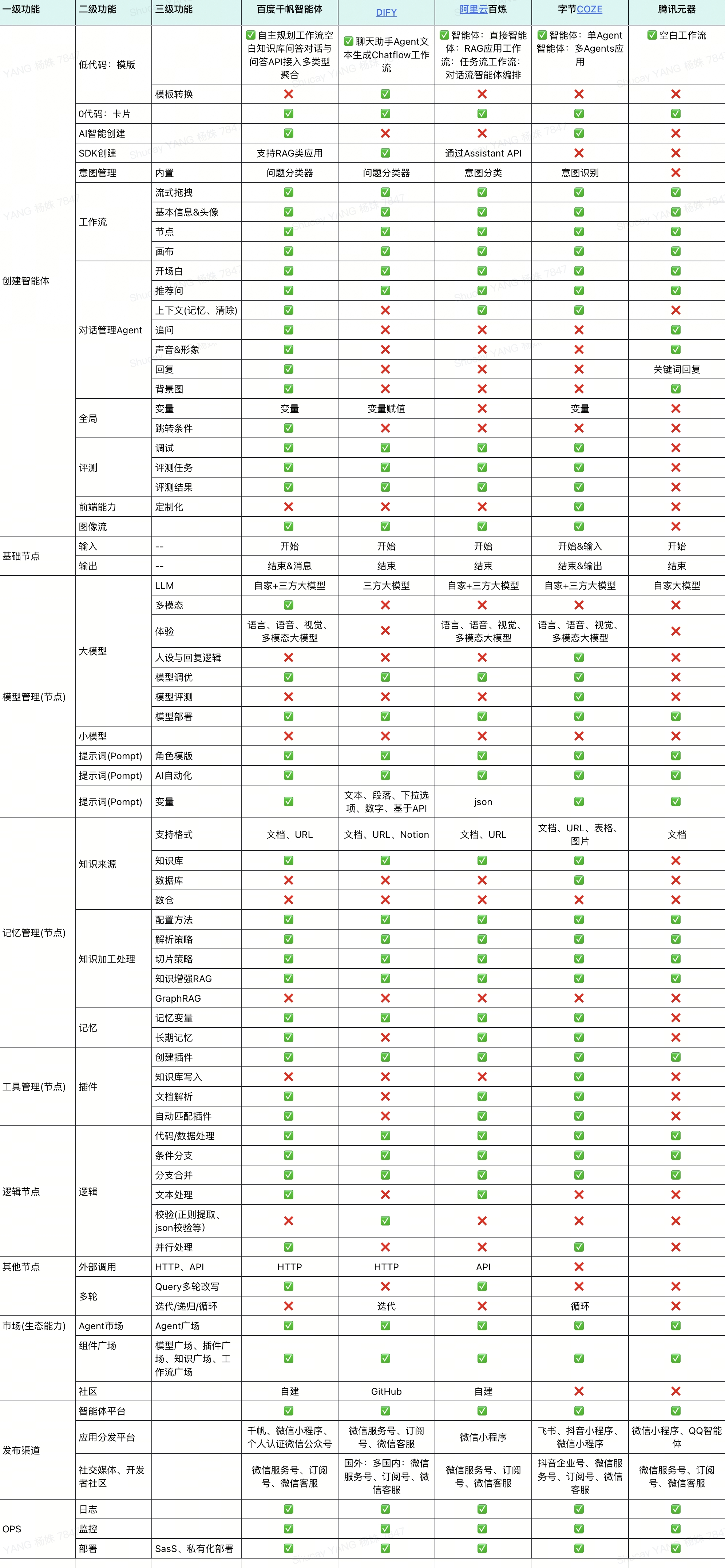
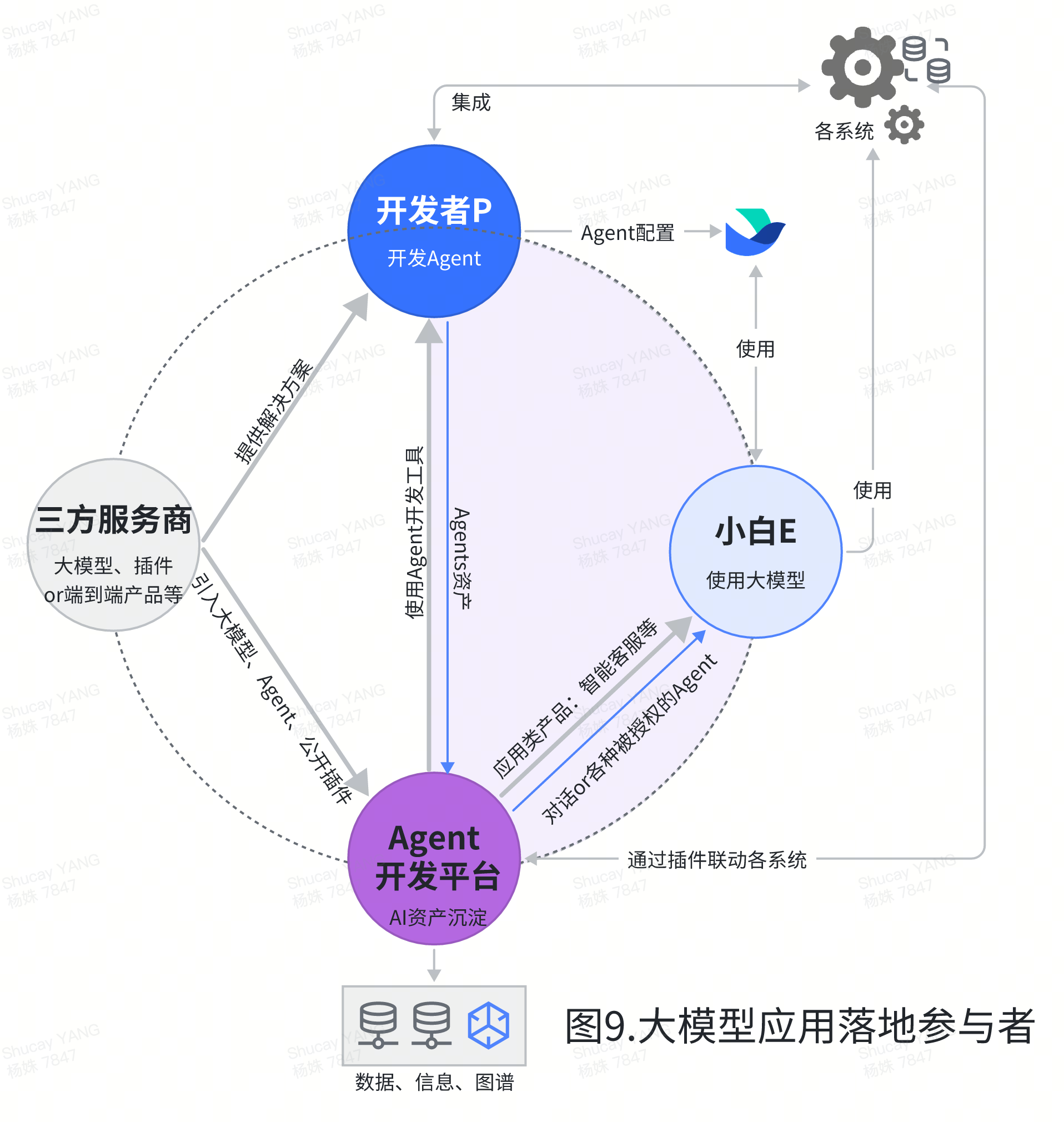
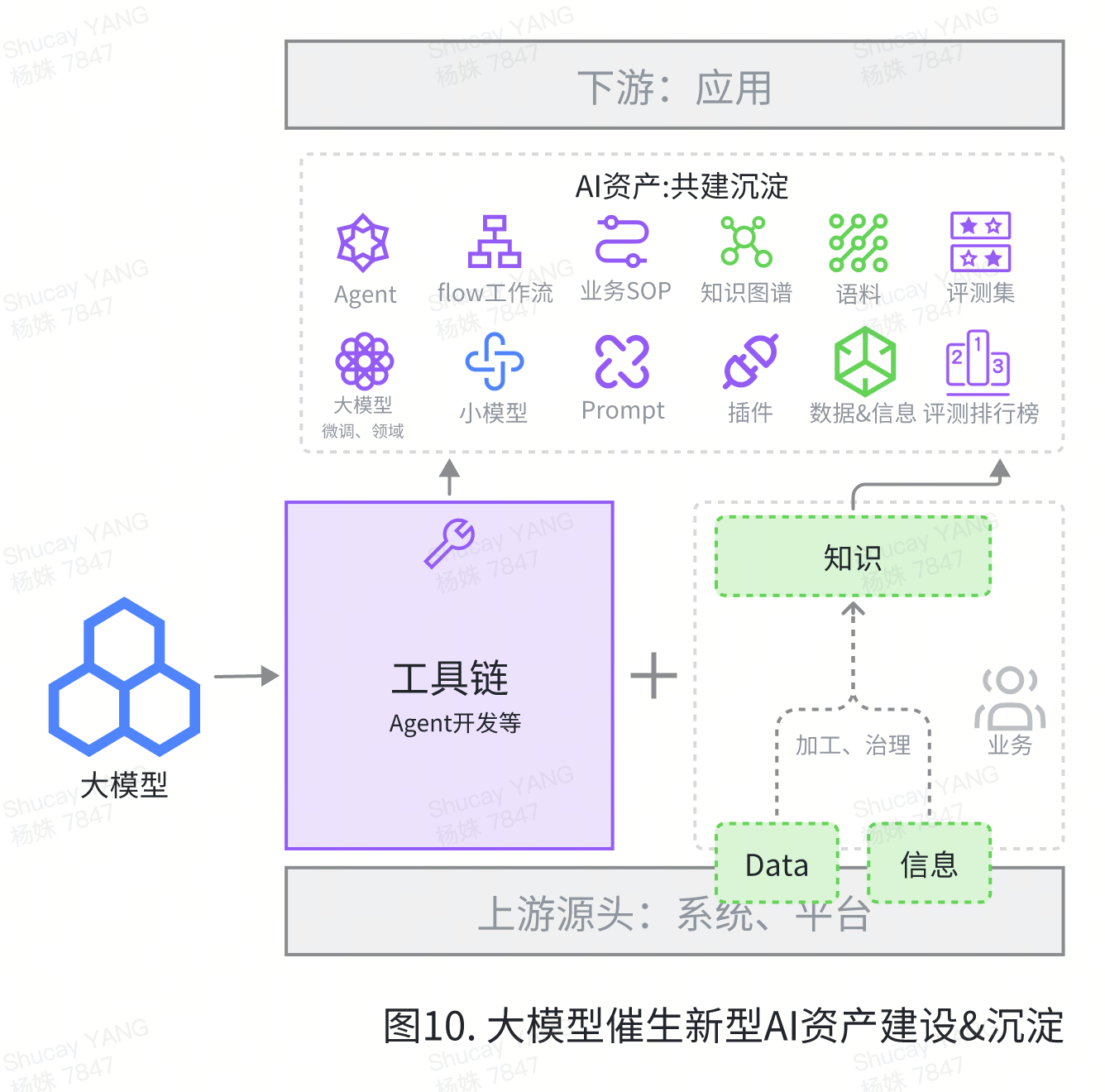
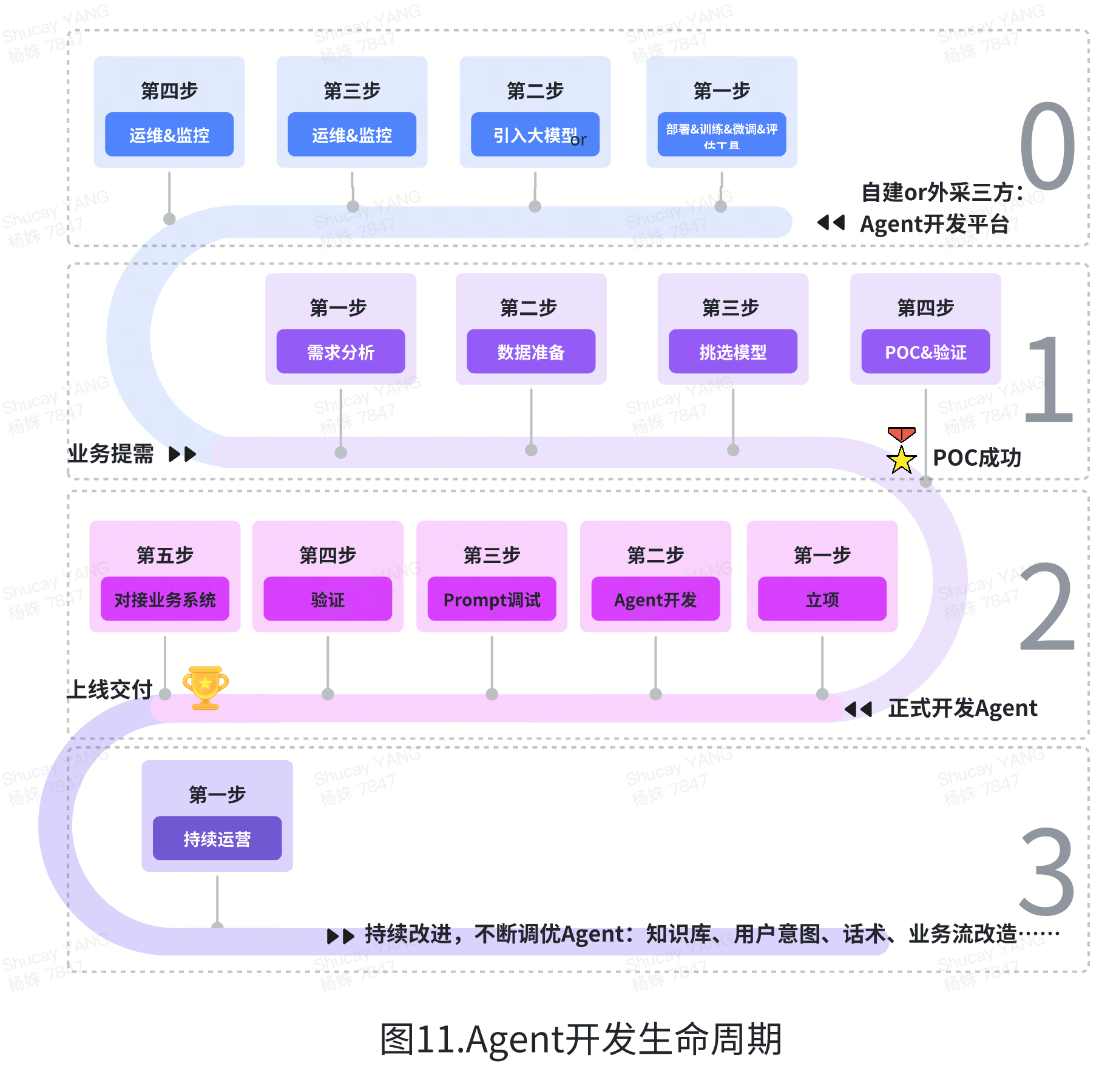
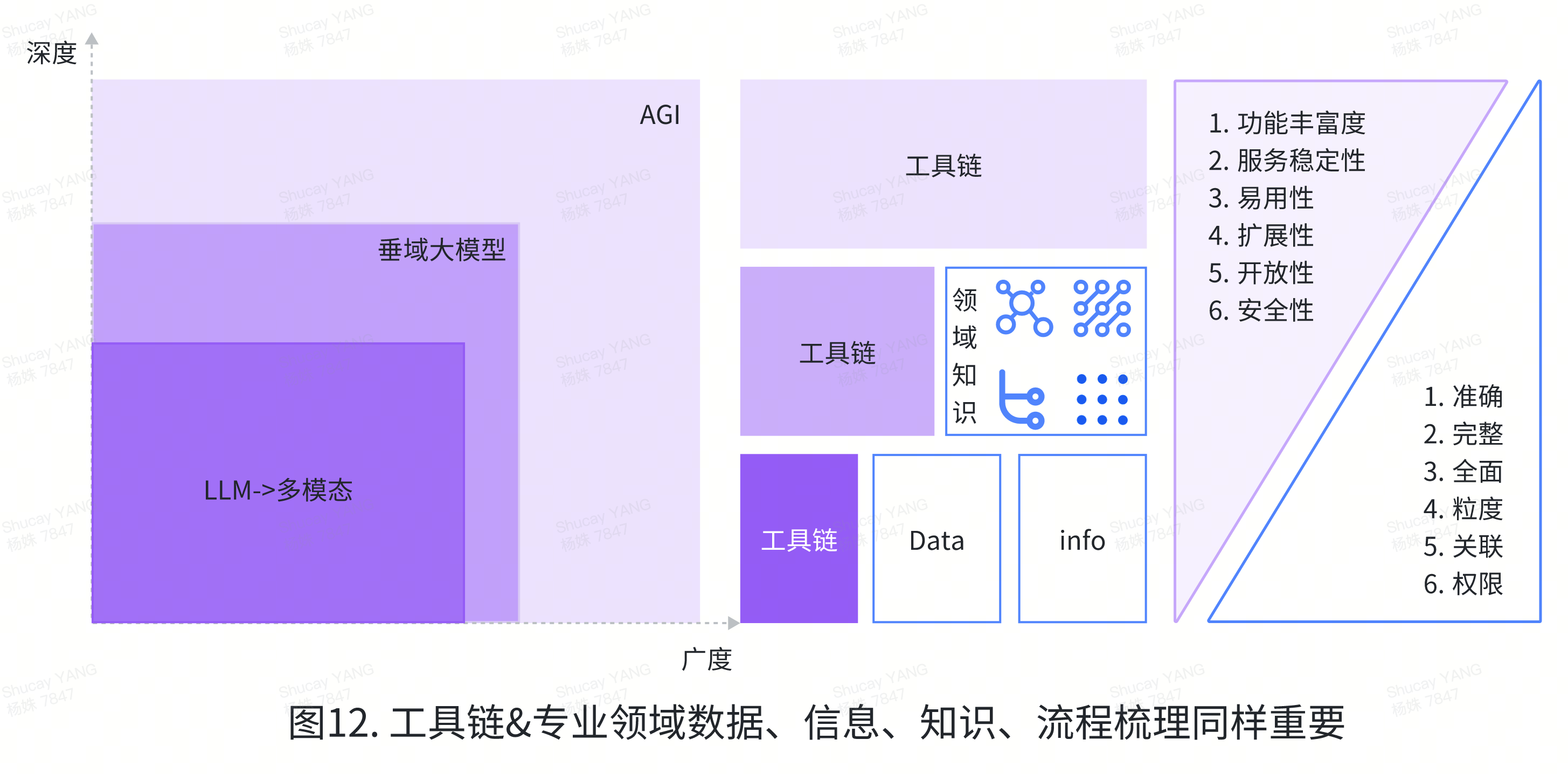
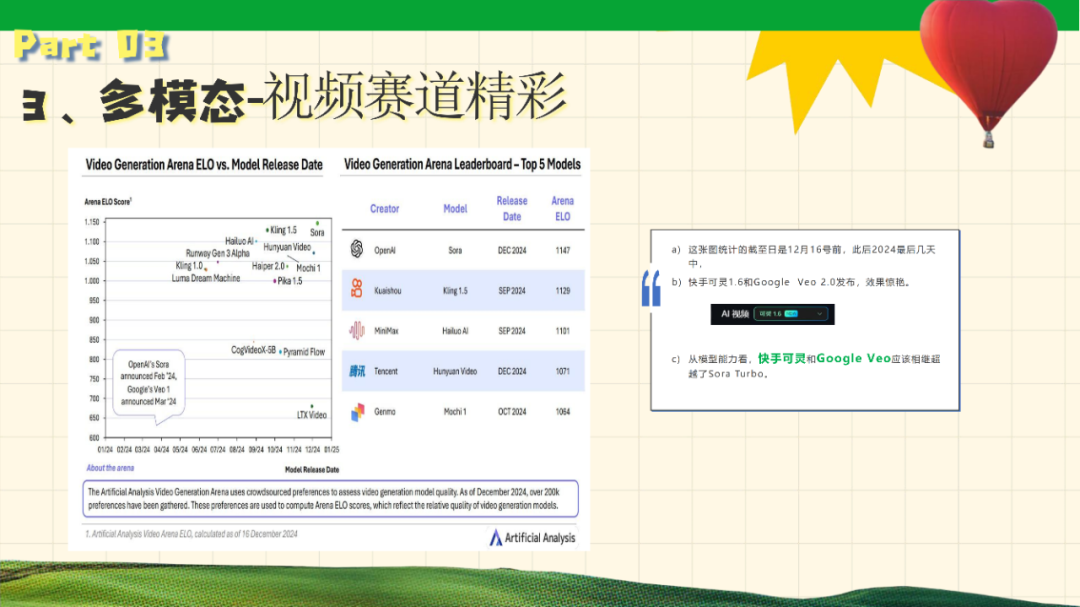
展望AI未来
目前AI算法和人类神经系统的区别
数量上
人类的大脑估计已经包含860亿个(10^11次方)神经元,这些细胞信号传递到对方通过多达100万亿(10^15)突触连接。
GPT-4是8个2200亿参数组成的混合专家模型,8 x 220B = 1.76万亿连接,与真实人脑仍然差50多倍。
功耗上
人脑功耗10w。
一张NVIDIA A100功耗250w,更别说万卡集群,简单计算相差25万倍。
机制上
人脑神经元种类多样、神经递质多样,多为化学信号,维度信息高。
人工神经元结构简单单一,传递为简单电信号,维度信息低。
结构上
人工神经元之间的连接则是一开始就被固定好了的,比如根据实际需求需要设计一个多大的神经网络网络模型,那么这个网络模型的参数和连接方式就基本已经被固定了。虽然可以通过神经元之间的随机失活等方法可以局部的改变神经网络内部的连接,但是这种改变仍然无法让人工神经元像生物神经元一样根据外界输入的数据信息而选择性的提取需要的特征信息。
生物的神经元之间是没有任何顺序的,可以随时根据外界传入的信息有条件的随意连接,但是人工神经网络内部的神经元之间是有顺序排列的,也就是神经网络的层数,人工神经元只能在神经网络的不同层之间发生连接,由于数学矩阵运算的规律,在同一层神经网络之间的神经元是无法连接的。
而且无论从目前效果和上述的巨大区别上,目前的LLM离真正的AGI还有很大的差距,想象看一个人类拥有互联网级别信息的时候,智慧程度会跟现在LLM一样吗?
所以很多人说数据即将用尽的观点是偏颇的,算法倒是学习效率低下才是本质。

但也说明深度仿生的联结主义潜力巨大。但未来会如何呢?
Transfomer后时代的观点
辛顿和伊利亚 — 压缩即智能

奥特曼在今年10月份接受采访说:伊利亚(OpenAI前首席科学家伊利亚·苏茨克维)总是说,这些模型的真正意义在于压缩,我们要找出如何压缩尽可能多的知识,这就是我们打造人工智能的方式。压缩就像是智慧密钥,我已经对此冥想很久,但我确信自己仍然没有完全理解它,但那里有些更深刻的东西。
就上上文提及到的注意力机制一样。随着进化的脚步,生命体本身由简至繁,而人类历史发展到今天,我们的生存环境和所需要学习、掌握的工作任务和过去的丛林生活复杂到不知多少。为了应对这个变化,大脑会如何进化呢?是发展成一个同时处理庞大的信息并且容量超大的大脑,还是发展成虽然容量不大,但可以迅速地分析信息,并配有一个高效率信息选择和投注机制,将所有计算能力都放在重要的任务上的大脑呢?很明显的,后者更有优势,而且大自然也为我们选择了这个目标。
人脑的注意力是一个用来分配有限的信息处理能力的选择机制。而Transfomer的自注意力是通过概率分布和权重分配实现该机制。
“预测即压缩, 压缩即智能”
这一观点最早由Ilya Sutskever在其博文和访谈中提出。Ilya Sutskever在不同场合提到,当我们谈论“预测下一个Token”时,本质上是在进行信息压缩。一个理想的预测模型, 应该能够以最简洁的形式(即最短的程序或描述)来表示输入数据中的关键模式和规律。预测是通过生成特定数据集的最短程序来实现的【46】。
Geoffrey Hinton从另一个角度阐释了压缩与智能之间的联系。他指出, 人工智能系统之所以能够展现出理解、类比、创新等高级认知能力, 关键在于它们能够发现并利用不同事物和概念之间的共同结构。如果AI系统能够掌握这种高度概括的表示,就可以实现跨域的类比和泛化。而要做到这一点,就需要AI系统从大量表面差异巨大的事例中提炼和压缩出最本质的共性。换言之, 机器要成为一个智能的类比推理者, 首先需要成为一个高效的信息压缩者。
可以抽象的理解为:压缩就是寻找第一性原理的过程,数据越多,总结出的第一性原理更具有普遍性。
综合Sutskever和Hinton的观点, 我们可以得出以下几点认识:
1. 从信息论的角度看, 学习的本质是一个逐步压缩数据的过程。通过在输入数据中发现可泛化的模式和规律, 学习系统可以用更简洁的表示来重构原始信息, 从而降低其描述复杂度;同时减少信息在压缩中的损失。
2. 大规模机器学习, 尤其是基于海量数据训练的深度神经网络, 可以看作是朝着最优压缩逐步逼近的过程。随着模型规模和数据量的增大, 神经网络能够捕捉到越来越抽象和一般化的特征, 其内部表示可以压缩更多的信息。
3. 压缩能力与智能水平密切相关。一个高度智能的系统, 应该能够基于少量信息对世界进行大量的重构和预测。这就要求系统在学习过程中最大限度地提取和内化数据中的关键模式和规律。因此,追求更强的压缩能力, 可以为我们指引通往AGI(通用人工智能)的道路。
杨立昆 — 世界大模型
杨立昆在题为《朝向能学习、思考和计划的机器进发》的演讲中,清晰地指明了以自监督学习为代表的 AI 系统的优缺点。

我们今天正在使用的LLM还无法做到真正的理解世界,这其中有很多原因,但最主要的原因是:LLM的训练方式是用一段缺失了部分文字的文本去训练一个神经网络来预测缺失的文字。事实上,LLM并不预测词语,而是生成字典中所有可能词语的概率分布,然后从概率分布中选择一个词放入文本序列的尾部,再用新生成的文本去预测下一个词,这就是所谓的自回归预测【47】。
但这种自回归的方式与人类的思维方式有很大的不同。人类大部分的思考和规划都是在更抽象的表征层面上进行的–人类对思考的意识只存在于高级表征中-比如人类不是靠像素点识别物体的,而是又像素点形成的光影、轮廓等,知识来源于此,而不是在更深层次的神经网络中,换句话来说,如果输出的是语言(说出的话)而不是肌肉动作,人类会在给出答案之前先思考好答案。但是LLM不这样做,它们只是本能地一个接一个地输出文字,就像人类的某些下意识动作一样。
然而,单靠这种方式,我们并不能真正做到推理,也很难处理非离散的复杂现实数据。要实现人类级别的智能,我们仍然缺少一些至关重要的要素。比如,一个十岁的孩子学会收拾餐桌、把碗盘放进洗碗机,只需看一遍就能学会。而一个17岁的青少年经过大约20小时的练习就能学会开车。然而,我们还没有达到五级自动驾驶,也没有能够帮忙收拾餐桌的家用机器人。
实现真正的智能需要的一个关键能力是“分层规划”,也就是我们人类在面对复杂问题时,能够分阶段、分层次地进行解决。比如从纽约去巴黎,我们会先计划怎么到机场,而不是从一开始就去计算整个行程中每一步的肌肉动作。如何让AI具备这种分层规划能力,目前仍是一个未解的难题。
真正的世界模型是:我对某时刻T时世界状态的想法,叠加此时我可能采取的行动,来预测在时间T+1时的世界状态。这里所指的世界状态并不需要代表世界的一切,不一定需要包含所有的细节,它只需要代表与这次行动规划相关的足够多的信息。
十年来,我们使用生成式模型和预测像素的模型,试图通过训练一个系统来预测视频中将发生什么来学习直观物理,但失败了,我们无法让它们学习良好的图像或视频表征,这表示,我们无法使用生成式模型来学习对物理世界的良好表征。
目前,看起来可以更好地构建世界模型的一种新方法是”联合嵌入”,称为JEPA(联合嵌入式预测架构),其基本思路是获取完整的图像及其损坏或转换的版本,然后将它们同时通过编码器运行(一般来说,编码器是相同的,但也不一定),然后在这些编码器之上训练一个预测器,以根据损坏输入的表征来预测完整输入的表征。JEPA与LLM有什么区别?【48】
LLM是通过重建方法生成输入,生成未损坏、未转换的原始输入,因此必须预测所有像素和细节。而JEPA并不尝试预测所有像素,只是尝试预测输入的抽象表征,从本质上学习世界的抽象表征(例如风吹树叶,JEPA在表征空间中预测,会告诉你树叶在动,但不会预测每个树叶的像素)。
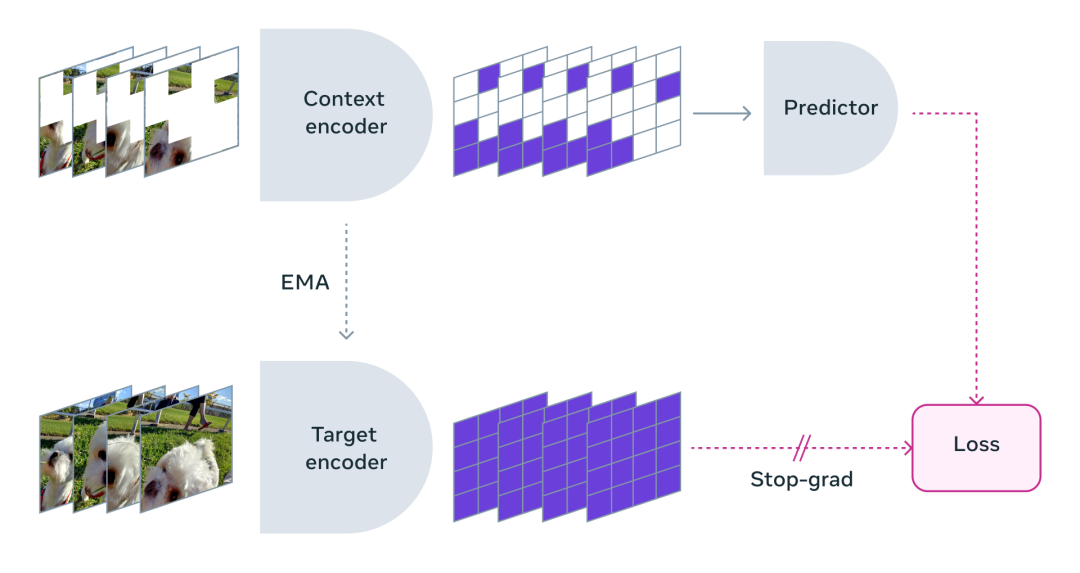
JEPA的真正含义是,以自我监督的方式学习抽象表征,这是智能系统的一个重要组成部分。人类有多个抽象层次来描述世界万象,从量子场论到原子理论、分子、化学、材料,一直延伸到现实世界中的具体物体等,因此,我们不应只局限于以最低层次进行建模。
基于该理念设计的 V-JEPA 是一种“非生成模型”,通过预测抽象表示空间中视频的缺失或屏蔽部分来进行学习。
四、大模型产业链——综述
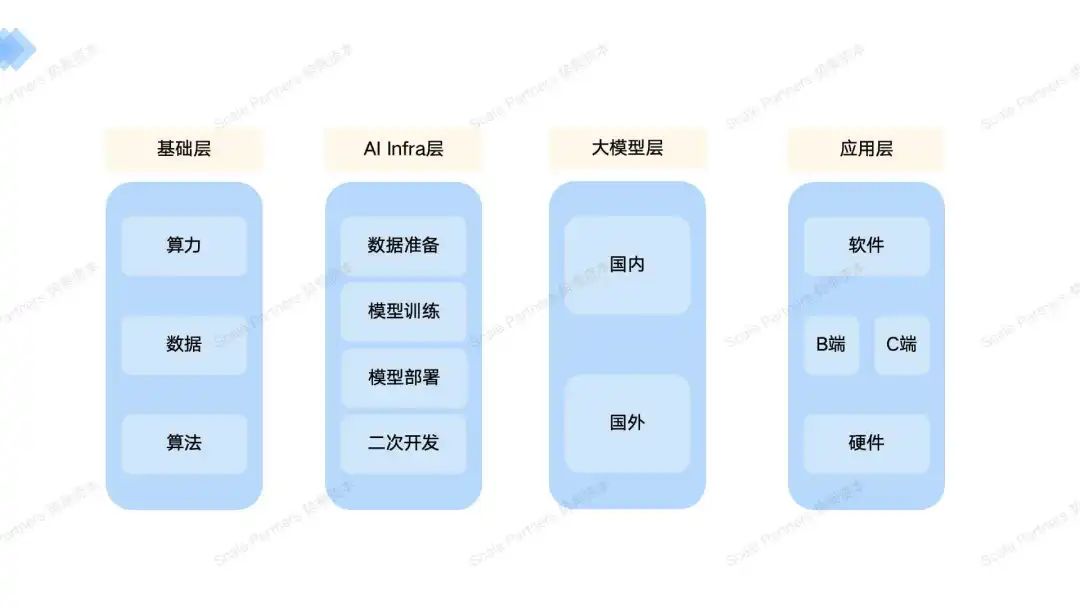
产业链的价值规则
框架根据具体的工作流尽可能的列出行业,有价值的笔者总结性多讲,没有变动的且基础的介绍一下。
关键的热点行业,笔者会综合讲述中美企业和商业环境的不同之处。
笔者对有价值的定义:
- 技术颠覆 — 先发的知识(人才)壁垒
- 商业模式颠覆 — 确保和大公司尽量在同一起跑线
- 有一定的市场规模的想象空间
五、基础层
算力
这里只讲述整装硬件层面的算力提供商以及基础的软件的趋势。不涉及芯片行业的上游。
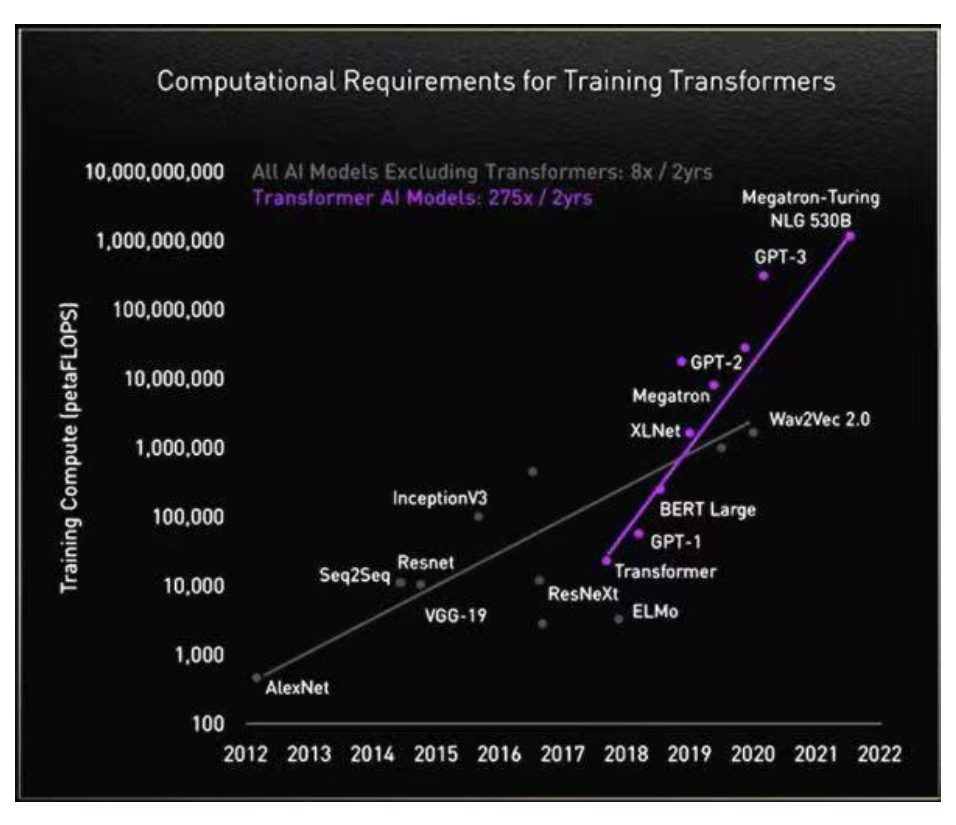
LLM对算力的需求飙升
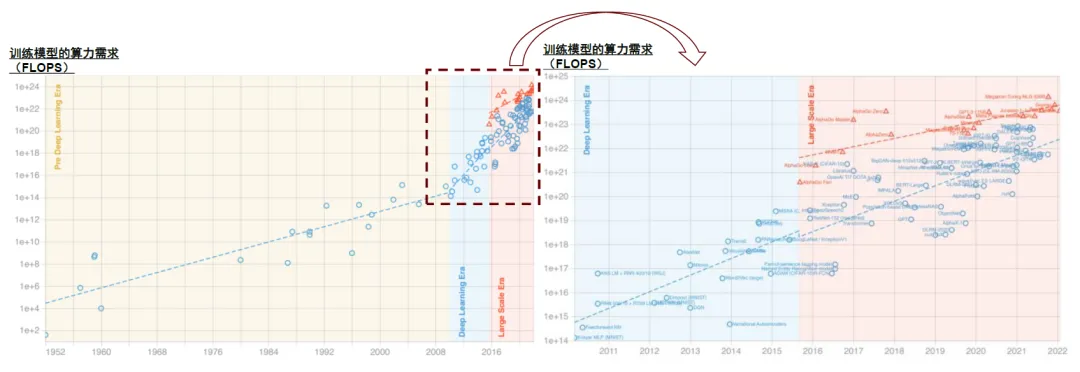
我们看到,为追求Scaling law带来的涌现效应,在位厂商模型训练的算力规模不断扩大,对AI算力基础设施的需求形成支撑。根据中国信通院《中国算力发展白皮书(2023)》,GPT-3的模型参数约为1,746亿个,训练一次需要的总算力约为3,640 PF-days,即以每秒一千万亿次计算,需要运行3,640天;2023年推出的GPT-4参数量可能达到1.8万亿个,训练算力需求上升至GPT-3的68倍,在2.5万个A100上需训练90-100天【49】。
针对LLM的新供应
通用芯片和专用芯片之争
按照芯片的设计理念及用途,AI算力芯片可分为通用芯片和专用芯片,二者各有特点。
通用芯片为解决通用任务而设计,主要包括CPU、GPU(含GPGPU)和FPGA。
专用芯片(ASIC)为执行特定运算而设计,具备算法固化特性,主要包括TPU(Tensor Processing Unit,张量处理器)、NPU(Neural Network Processing Unit,神经网络处理器)等。
在通用算力芯片当中,CPU内核数量有限,采用串行方式处理指令,适合于顺序执行的任务;GPU采用众核结构,最初开发用于图形处理,而后凭借其强大的并行计算能力适用于AI通用计算(GPGPU);FPGA是具备可编程硬件结构的集成电路,其可编程性和灵活性可快速适应AI领域的算法变化。与专用芯片相比,通用芯片主要优势在于灵活性及生态系统的完善性,可适应高速迭代的算法任务,同时GPU保留的渲染能力可适应大模型的多模态发展,而其主要劣势则在于较高的功耗水平和较低的算力利用率。
专用芯片的优势则在于通过算法固化实现了更高的利用率和能耗比,以及更低的器件成本,同时ASIC更适合大规模矩阵运算;其主要劣势是前期投入成本高、研发时间长,且只针对某个特殊场景,灵活性不及通用芯片【50】。
ASIC(Application Specific Integrated Circuit)是专用集成电路,针对用户对特定电子系统的需求,从根级设计、制造的专用应用程序芯片,其计算能力和效率根据算法需要进行定制,是固定算法最优化设计的产物。经过算法固化后,专用芯片与软件适配性较高,从而能够调动更多硬件资源,提高芯片利用率。而通用芯片由于算法不固定,其硬件往往会产生冗余,导致芯片利用率较低。
目前价值最大的仍然是GPU,它更适应高并发多分布式的训练,LLM训练和推理以它为主,95%的算力的都是由它提供。
就像工厂一样,一开始会去买标准的设备(通用芯片)进行生产,后续规模扩大了,更了解客户的需求后,产品变的差异化,这时候会去找产线集成商如西门子,定制化产线(专用芯片);本质上来说,背后就是需求和厂商供应的trade-off(成本等),但是需求是第一位,大规模量产和定制化的前提都是同质化的需求在支撑。
目前,我们对LLM的训练和推理算法皆有不同程度的优化,商业场景还在积极探索,甚至是算法本身都在快速变化,ASIC等专用芯片为时尚早。
GPU适应LLM大规模计算的新技术指标
深度神经网络对计算芯片的需求主要围绕解决两个问题展开:
(1)解决AI计算芯片和存储间数据通信需求,AI模型中,大量运算资源被消耗在数据搬运的过程。芯片内部到外部的带宽以及片上缓存空间限制了运算的效率。
(2)在控制功耗的同时不断提升专用计算能力,对AI芯片进行定制,在特定场景下实现AI芯片的高性能和低功耗,解决对卷积、残差网络等各类AI计算模型的大量计算需求。
算力不足如何解决?
众所周知的芯片断供原因,国内厂商无法在正常的渠道买到高端的芯片,如何弥补?
除了走私外,异构芯片的混训(国产芯片+国外芯片;本地计算+云计算)成为了主流,但随着算力的不断补充和IDC的建立,并且模型参数的变小,此类问题将快速解决。能看到的是A100芯片的租赁价格几经对折。
国外的算力中心如特斯拉、谷歌、亚马逊的万卡集群都将在近期建设完成。特斯拉的有10万块H100。
新AI算力市场推算
GPT-4的训练,推理算力成本拆解
训练成本
GPT-4的一次训练费用高达6300万美元,2.15e25 的 FLOPS,使用了约 25,000 个 A100 GPU,训练了 90 到 100 天,利用率(MFU)约为 32% 至 36%。这种极低的利用率部分是由于大量的故障导致需要重新启动检查点。如果他们在云端的每个 A100 GPU 的成本大约为每小时 1 美元,那么仅此次训练的成本将达到约 6300 万美元【51】。
推理成本高于训练成本
ChatGPT 每天在计算硬件成本方面的运营成本为 694,444 美元。OpenAI 需要约 3,617 台 HGX A100 服务器(28,936 个 GPU)来为 Chat GPT 提供服务。我们估计每次查询的成本为 0.36 美分。ChatGPT一年将花费至少2.5亿美元,而训练一个模型仅需一次性花费6300万美元。
训练芯片
在给定训练GPT-3模型所需运算操作数量的情况下,即便得知单卡算力,以及要求的训练时间,量化加速卡数量实际上也存在难度,因为数据集精度、数据集迭代次数,以及GPU的使用效率等等因素都是未知变量【51】。
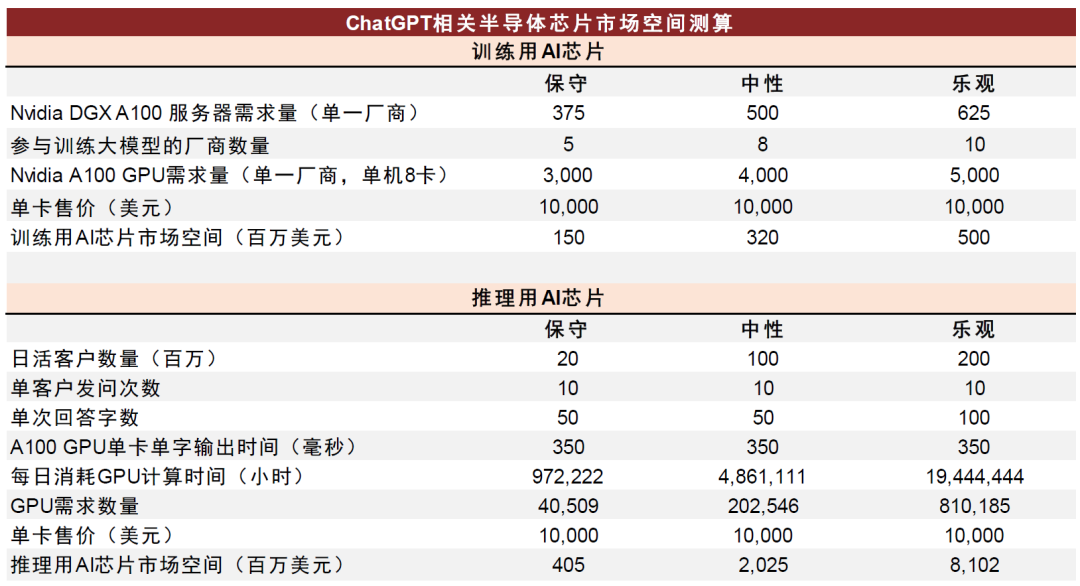
在此,我们直接采用OpenAI训练集群模型估算结果作为参考:标准大小的175亿参数GPT3模型大概需要375-625台8卡DGX A100服务器进行训练(耗费10天左右时间)。目前来看,训练大模型的硬件投入基本3,000张-5,000张A100 GPU来完成。那么,以单A100卡售价10,000美元来计算,生产大模型所需的训练用GPU一次性采购拉动在千万美元级别,具体金额决定于参与生产大模型的终端用户家数,中性情形下,我们假设8家厂商采购训练卡,单一厂商需求量500台DGX A100服务器,可带来的训练AI加速卡市场空间约为3.2亿美元。
推理芯片
推理应用和实际业务上线关系紧密,硬件需求要结合对效率要求来进行部署。以A100 GPU单卡单字输出需要350ms为基准计算,假设每日访问客户数量为2,000万人,单客户每日发问ChatGPT应用10次,单次需要50字回答,则每日消耗GPU的计算时间为972,222个运行小时(2*10^7*10*50*350ms = 3.5*10^12ms = 972,222h),因此,对应的GPU需求数量为40,509个。同样以单卡10,000美元的售价计算,2,000万用户上线在推理端所创造的AI芯片市场空间约4亿美元左右,但在中性情形下,假设日活用户数达到1亿用户,在单客户发问次数、单次回答字数不变的情况下,我们测算出推理相关用AI芯片市场空间有望达到20亿美元【51】。
GPU芯片&服务器提供商
国内外芯片市场
全球GPU市场竞争格局较为集中,当前NVIDIA处于市场领导地位,根据Verified Market Research数据,2022年在全球独立GPU市场当中占比约80%。

国产AI云端训练和推理芯片厂商参与者众多,大部分涌现于2017年以后。
(1)华为Atlas 300T训练卡(型号9000)基于昇腾910 AI芯片,单卡算力280TFLOPS FP16;
(2)寒武纪思元370单卡算力256TOPS INT8,是第二代产品思元270算力的2倍;
(3)百度昆仑芯2代AI芯片单卡算力为256TOPS INT8 / 128TFLOPS FP16;
(4)海光DCU的优势则体现在生态兼容性,其ROCm GPU的计算生态和英伟达CUDA[1]高度相似,被称为“类CUDA”,有利于用户可快速迁移,2022年海光深算一号DCU已商业化应用,深算二号正在研发中【52】。
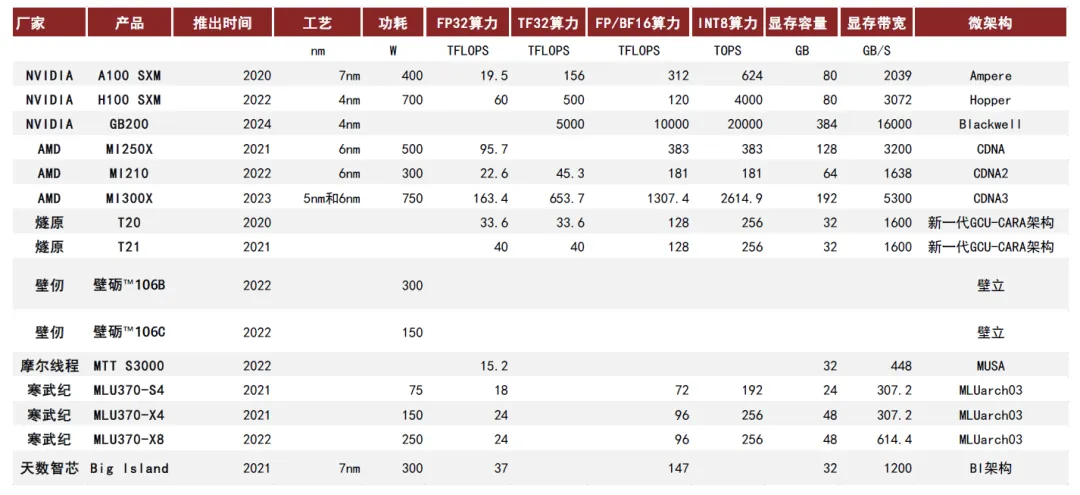
目前国产产品依然与全球领先水平存在2-3年的差距。
国产最强的AI芯片性能大约为512Tflops,不仅不如NVIDIA的A100,甚至只有H100的四分之一左右。例如,寒武纪的思元590在某些特定应用场景下接近A100 90%的性能,但综合性能仍只能达到A100的80%左右。
国产AI芯片企业虽作为后发者,依然拥有市场机会。一方面来看,摩尔定律的迭代放缓使得海外龙头企业开发新产品面临更大的挑战,中国企业有望以更快的速度向海外现有产品看齐,但供应链方面存在不确定性,对后发企业构成利好【53】。
CUDA
GPU的算法和生态系统构建也是GPU设计中的重要部分。GPU算法需要与硬件紧密结合,以提高GPU的性能和效率。同时,GPU的软件生态系统还需要支持各种开发工具和框架,以便开发人员可以更轻松地利用GPU进行高性能计算和机器学习。
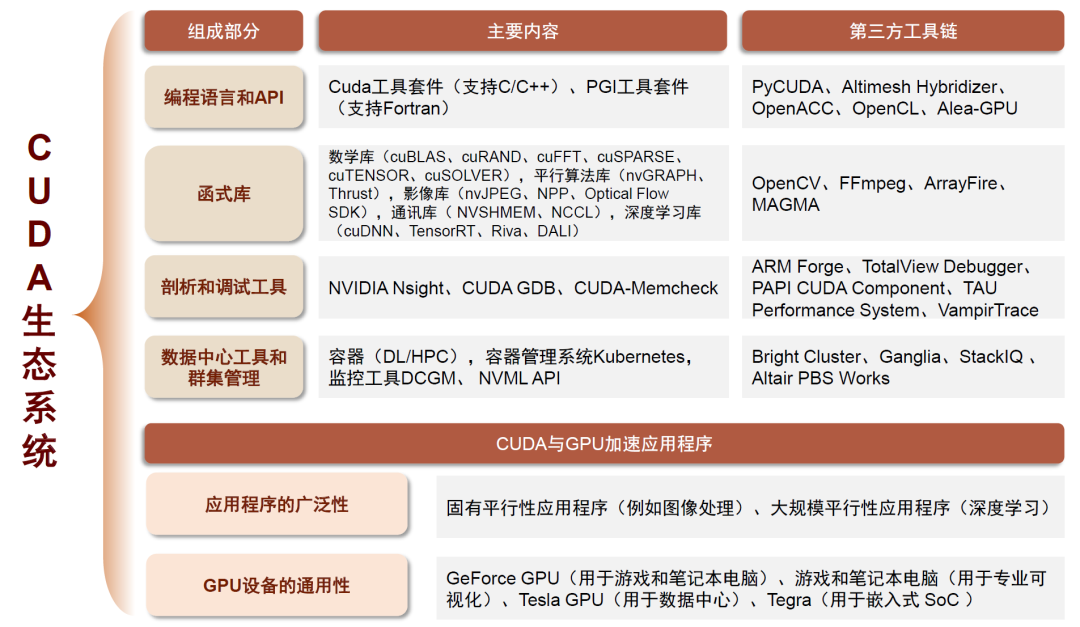
基于高层次抽象,英伟达通过CUDA统一编程平台提供了一套完整的开发工具链,包括编译器、调试器和性能分析工具,以及丰富的库函数(加速算子执行、实现卡间通信),为开发者提供了便利,降低使用成本。且CUDA统一编程平台可支持多个操作系统,且支持各类GPU(包括数据中心级产品、消费级产品);全球安装的CUDA兼容的NVIDIA GPU数量已经达到了数亿级别【50】。
由于硬件端AI领域的先发优势,大量的AI深度学习训练开源项目和框架如PyTorch、TensorFlow等与英伟达GPU后端实现了原生适配,且兼容DeepSpeed、Megatron-LM等分布式加速工具;推理端来看,英伟达同样拥有Tensor-RT引擎。总结来说,主流AI软件栈的最佳优化方案均与英伟达CUDA生态及GPU深度耦合。通过日积月累,英伟达硬件环境上的开发者数量众多,有庞大而活跃的社区以及大量可用的文档、教程、论文,开发人员对CUDA的熟悉程度和专业度更高,导致新人采用CUDA面临的时间成本更低。到2023年底,CUDA软件包已累计下载4800万次,证明其广泛的用户基础和开发者社区的活跃度。
英伟达对外部企业、学校、以及不同应用领域均有良好的解决方案,对不同类型客户进行深度绑定服务。
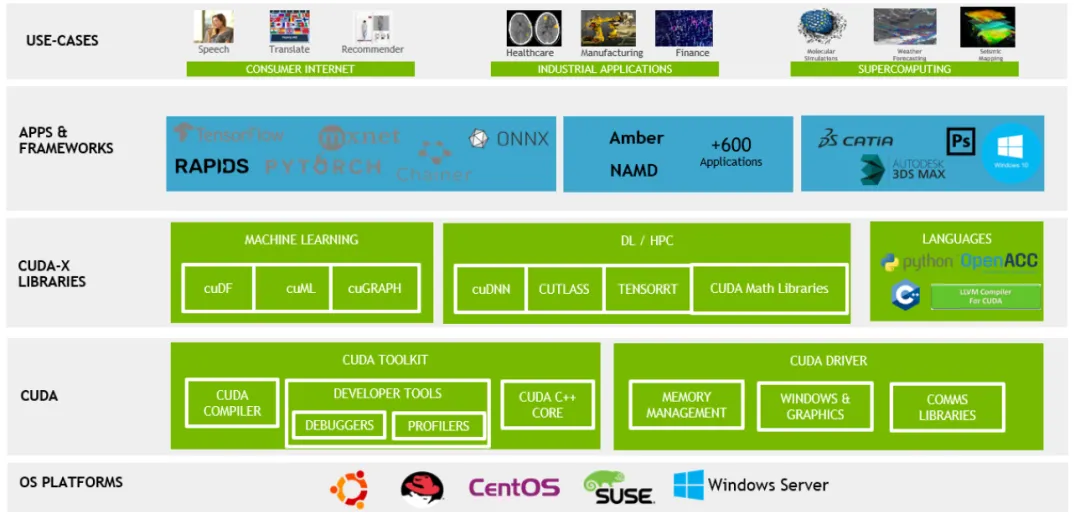
可以说其系统生态的繁荣为其GPU硬件平台提供了最大的开发生态护城河!
能和其英伟达一较高下的,恐怕只有同时掌握前后端并拥有独立开发生态的华为了。
其余的大部分做ai芯片的公司短暂的收入提升来源于国内IDC的建设,渠道为主,生态意识低。
集成算力提供商
AI服务器
一般来讲,服务器的定制化程度高,大厂的服务器是自己采购,自己搭建,中小企业购买会多一点。再加上云计算的趋势,保密单位的需求会硬一点,否则云计算性价比更高。
AI服务器(多个GPU等芯片集成)竞争格局方面,当前互联网云计算厂商的白牌服务器占主导,未来随着边缘侧应用的成熟,品牌服务器厂商份额也有望提升。AI服务器分为品牌和白牌两类。所谓白牌,是由互联网云计算大厂在云计算的规模效应下,与传统的服务器代工厂EMS企业合作开发定制化的“白牌”服务器;所谓品牌,是由专门的服务器厂商开发的面向企业、政府、运营商和金融等销售的通用型服务器【52】。

智算中心
政府
2023年以来,政府智算中心建设的规模与节奏均有显著提升。通过梳理各地政府官网信息,我们整理了2020年-2024年政府智算中心建设情况,发现:
1)2023年以来智算中心建设明显加速,各省市地方政府均在积极推进智算中心建设;
2)2020年-2023年间已投运政府智算中心单期算力建设规模一般在500P以下,而随着AI带动算力需求的提升,单个智算中心的体量提升,2023年下半年之后建设与投运的智算中心出现较多1000P以上的算力规模【49】。
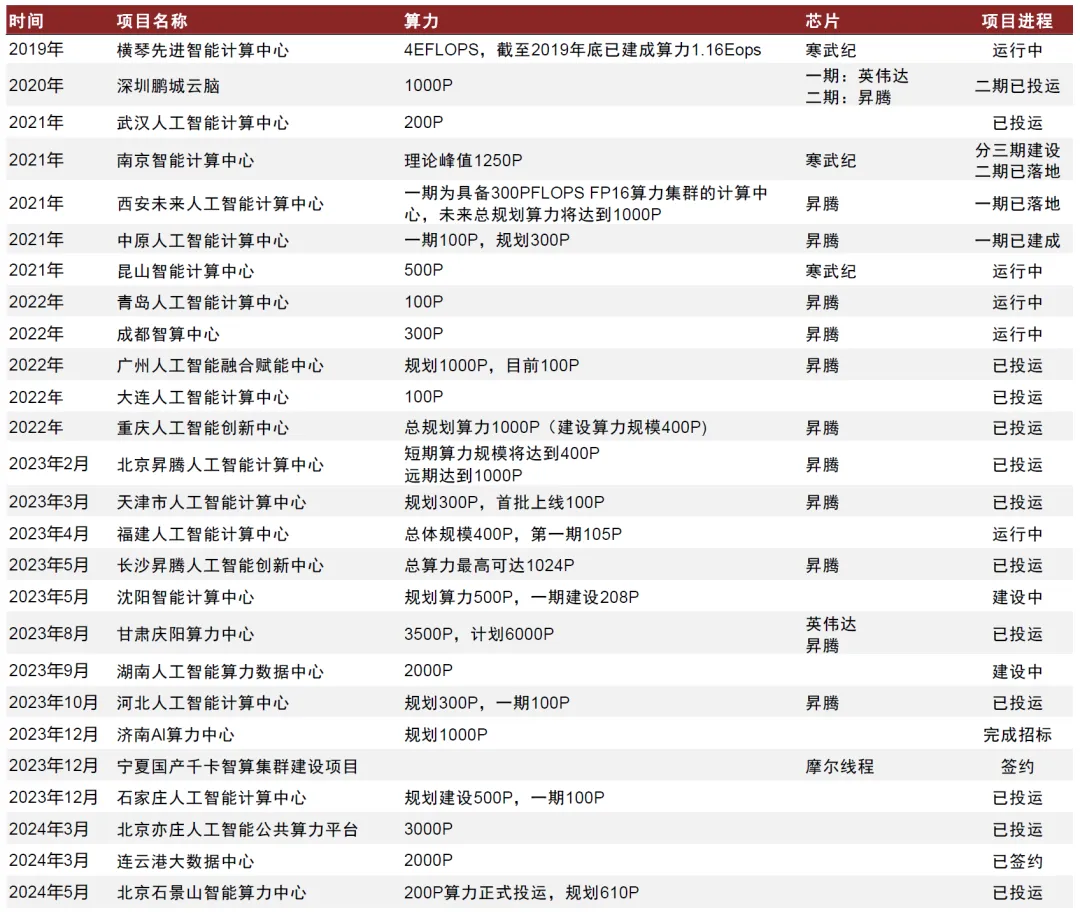
华为昇腾、寒武纪等国产AI算力芯片成为政府主导的智算中心的重要算力基座。北京昇腾人工智能计算中心利用“政府引导+市场化运作”平台建设模式,政府负责顶层设计、政策保障;中关村发展集团负责设施建设、配套服务、提供空间载体,最终使用华为自主研发的昇腾芯片,互利共赢。长沙昇腾人工智能创新中心由长沙市政府和湖南湘江新区共同出资建设,采用基于昇腾910处理器的兆瀚CA9900 AI集群硬件,总算力最高可达1024 PFLOPS(FP16)。政府智算中心建设提速,有望进一步拉动国产AI芯片的需求。
三大运营商
根据三大运营商2024年资本开支指引,运营商投资重心将继续向算力网络建设倾斜。具体来看,中国移动计划2024年在算力网络领域投资475亿元,占当期资本开支的27.5%,同比增长21.5%;中国电信资本开支在产业数字化方面的投资占比同比提升2.5ppt至38.5%,绝对额达到370亿元,其中公司计划在云/算力投入180亿元;中国联通则表示算网数智投资坚持适度超前、加快布局【49】。
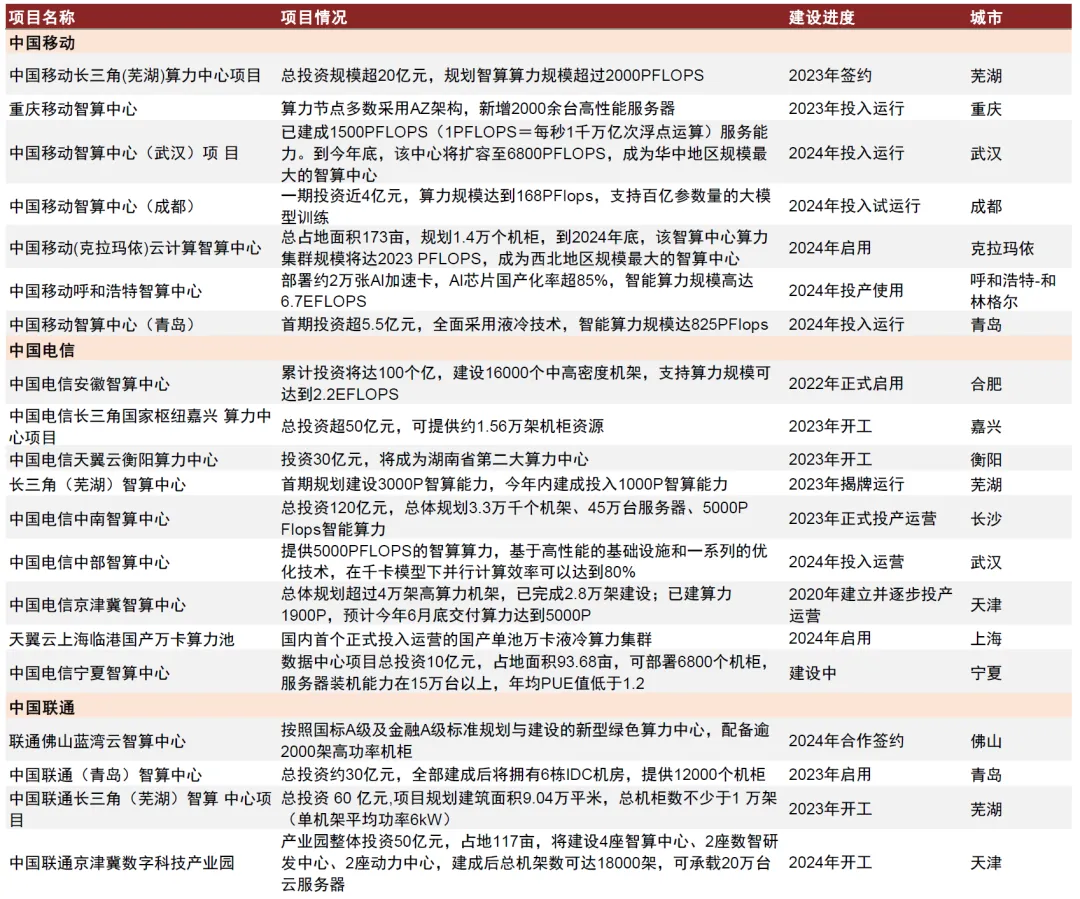
三大运营商智算中心建设持续推进。根据2023年度业绩发布会,中国移动计划2024年加快算力多元供给,累计智算规模规划超过17 EFLOPS,新部署智算增幅接近70%;中国电信持续推进智能算力建设,2023年公司智算算力新增8.1EFLOPS,增幅高达279.3%,累计规模达到11.0 EFLOPS,2024年公司预计智算规模将继续提升10 EFLOPS至21 EFLOPS(FP16);根据公司公告,中国联通算力中心已覆盖国家8大枢纽节点和31个省份,数据中心机架规模超40万架,完成29省千架资源布局,骨干云池城市覆盖超230城,MEC节点超600个。我们认为,运营商对智算场景投入的持续加码有望带动服务器、网络设备等算力基础设施需求节节攀升,在电信云网设备侧具备稳定供应能力的厂商有望充分受益。
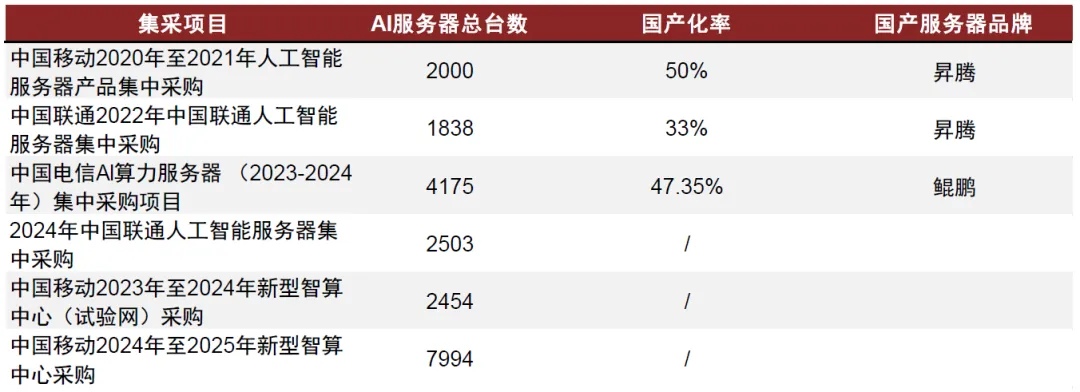
大型企业
腾讯、百度、阿里、字节、商汤等企业积极推进智算中心布局,阿里张北超级智算中心总建设规模达12000PFLOPS 百度与腾讯均已在全国多个地区建立了智算中心,包括广州、上海、北京等,字节跳动则依托于润泽科技等进行智算中心相关的IDC投资【49】。
互联网厂商当前算力构成仍以英伟达为主。根据TrendForce,中国云计算厂商目前使用的高端AI芯片中英伟达的芯片占比约为80%,当前的国产化率水平较低。考虑到贸易摩擦的影响,海外核心高端AI芯片难以进入大陆市场,国产替代需求迫切性高。
国内AI加速芯片厂商把握发展机遇,有望渗透进入互联网市场。根据TrendForce,2023年在全球AI服务器采购需求中,字节跳动/百度/腾讯/阿里等中国互联网厂商采购占比约8.5%,为AI服务器的重要需求方。我们认为随着AI大模型加速迭代,国内互联网厂商对于AI服务器需求有望进一步提升,国产AI芯片潜在市场空间广阔。
我们看到,互联网厂商积极推动与国产算力芯片的合作,根据公司公告,海光DCU支持包括文心一言在内的多个大模型的适配和应用;百度飞桨与海光DCU实现生态兼容性认证;而华为与百度合作推进昇腾AI上与飞桨+文心大模型的适配。我们认为,随着芯片的性能迭代及生态完善,国产算力芯片在互联网侧的应用有望逐步增加。

总而言之,由于断供的风险,国内芯片的国产化率逐渐提升,但在AI算力方面,主力军仍是英伟达。目前AI将会以通用芯片为主。
算法
这里的算法指的是流派、学习范式等AI底层知识和洞悉的集合,由稀缺的人才掌握,是产业链里的核心的核心,没有之一,算法决定了一切,主流算法的改变,可以改变所有的工作流和产业链行业的价值。
例如之前的CNN等算法的学习范式是监督学习,数据的输入和输出是pair的(匹配的),且需要标准的数据–大量的人工标注,催生了人力密集的数据标注行业,但是自回归的decoder-only transfomer算法下是自监督学习,数据不需要标注,请问新的大模型下,预训练还需要人工标注嘛?RLHF和微调的部分还会需要少量的人工,但也是大大减少了需求。
算法的产出来自于关键的实验室和大公司;可以关注其论文的产出,来跟进;一些跟踪的渠道将会在最后展示。
RVKW
最新RVKW-相比transfomer这种方法有效地捕获了序列中不同位置之间的依赖关系,同时减少了模型的计算复杂度和存储需求;它是RNN的一种,建议大家持续关注,目前该算法还在雏形中,为时尚早,有意思的是,发明该算法的人是中国人彭博。

数据
数据来源
AI公司获取语料数据一般有开源数据库、自有/自建数据–爬虫、购买数据产品授权–专业语料数据服务商处这三种方式。
以GPT-3为例,其训练时使用的语料库数据主要来源为Common Crawl爬虫(60%)、WebText2(22%)、Books1&2(各8%)和Wikipedia(3%)
拥有更高质量、相关的数据,可以更好的训练or微调模型;可获得的数据取决于行业和公司业务,是大模型产业链里最重要的壁垒之一;也往往是大公司的先发优势,初创公司出来公开的数据集,必须通过创新的商业模式来获取更多的数据。
不同国家的数据管理
当然避不开不同国家数据管控问题。
国外:欧盟将数据分割为“个人数据”和“非个人数据”,但个人数据严格属于自然人,企业数据使用权受到极大限制;美国的数据要素制度采取实用主义原则,回避了数据所有权问题,未对数据进行综合立法,只有针对跨境数据主权、行业隐私法、消费者隐私等分别立法。
国内:2022年12月,中共中央国务院《关于构建数据基础制度更好发挥数据要素作用的意见》(简称“数据二十条”)对外发布,提出构建中国特色的数据产权制度、流通交易制度、收益分配制度和数据要素治理制度,其中创新数据产权观念,淡化所有权、强调使用权,聚焦数据使用权流通,创造性提出建立数据资源持有权、数据加工使用权和数据产品经营权“三权分置”的数据产权制度框架。三权分置的产权制度,淡化所有权、强调使用权。

生成式数据的版权问题一直是AI发展的法律限制性因素,随着马斯克支持特朗普上台,向特朗普提议解绑前沿科技的法律限制,会是一变动因素。
数据不够?
关于数据量(Training Tokens)和模型大小(Parameters)对于模型的影响,OpenAI在2022年发表的论文有过讨论:在计算量增加10倍时,模型大小增加5倍,数据大小增加约2倍;而计算量再增加10倍时,模型大小增加25倍,数据大小仅增加4倍。
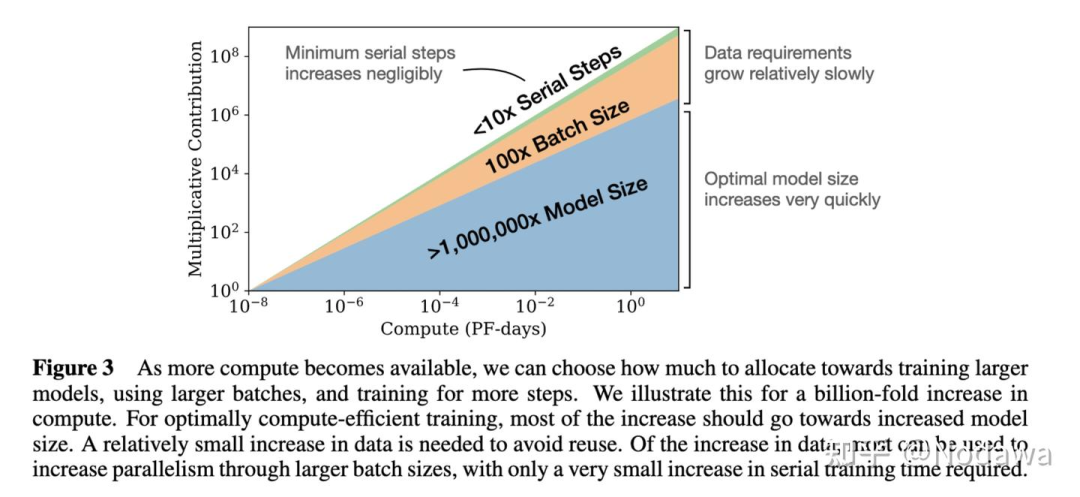
根据非营利研究机构Epoch AI的最新论文,大语言模型会在2028年耗尽互联网文本数据。
这里说的数据仅仅是真实数据,合成or仿真数据将会在AI Infra层详细讲述。
我的观点如上述章节一致,本质上是算法导致的学习效率低下的问题,不是数据规模问题。
六、AI Infra层
软件的市场演进规律
在正式进入介绍产业链前:我先对齐下大家对软件行业的规律:
先有一个breakthrough的应用程序,然后这个突破性的应用程序激发了一个创新阶段,在这个阶段建立基础设施,使类似的应用程序更容易建立,并且基础设施使得这些应用程序被消费者广泛使用【54】。
一家软件公司的成功,通常需要经历以下 4 个阶段【55】:
1. 由于行业、趋势、场景的变化,新的需求出现,这个时候有需求(刚性需求)但没有标准化产品,大型企业尤其是科技公司便在企业内部自建团队,靠几名高技术水平开发者从 0 到 1 手动搭建产品和框架,并在后续自主维护。
2. 技术和解决方案在实验室或企业内部运行一段时间后,开始有人试图抽象出相对通用的框架和产品,并向市场发布,有开源产品–营销、也有闭源产品,1争夺行业标准(技术)。当用户购买产品的 ROI 比使用“开源架构+内部自建团队+维护更新”的方案更高(要有技术开发壁垒)时,2 用户开始付费(商业模式创新切入)。
3. 随着需求的增长,越来越多的客户使用和筛选各类产品,经过一段时间的市场检验,最终收敛到 1-2 款产品(成功找到商业化产品的核心应用场景和 Product/Market Fit),行业标准形成。
4. 成为行业标准的产品和公司将基于现有的技术和产品,提供更多更有价值的功能和服务,提升产品和商业化能力,在商业化方面取得成功,注重防守–全栈解决方案,增加转换难度。
To C差不多,制胜的目标变成了利用生态截取大量流量,再转化。
流量的进出顺序为硬件终端(pc、手机等)> 软件(检索工具 > 社交软件 > 其他);所以依托硬件去做流量的转化有天然的优势,毕竟流量在前,软件公司只能听苹果or安卓终端公司生态摆布,著名的例子就是腾讯想通过微信小程序来躲过苹果商城的苹果税,结果被苹果起诉;当然中国可以没有苹果,但不能没有微信(支付、社交、出行等等的完全生态),唯一软件打得过硬件的反例。
苹果公司在2017年推出的应用服务条款,通过虚拟货币的打赏,应当被视为应用内购买,苹果将从中提取30%的分成,而且必须走苹果支付渠道。所以大家知道为什么国内女主播要求苹果手机用户打赏要走微信小程序打赏or其他非苹硬件了吧。还有ios的游戏充值也比正常渠道贵。
这也是为什么谷歌还自己做了手机等硬件,还有meta扎克伯格疯狂炒元宇宙,想用vr、眼镜等穿戴式设备其他硬件范式推翻移动互联网时代的手机生态,由于光学成像等等原因,很可惜还有很大的距离。
AI Infra产业链
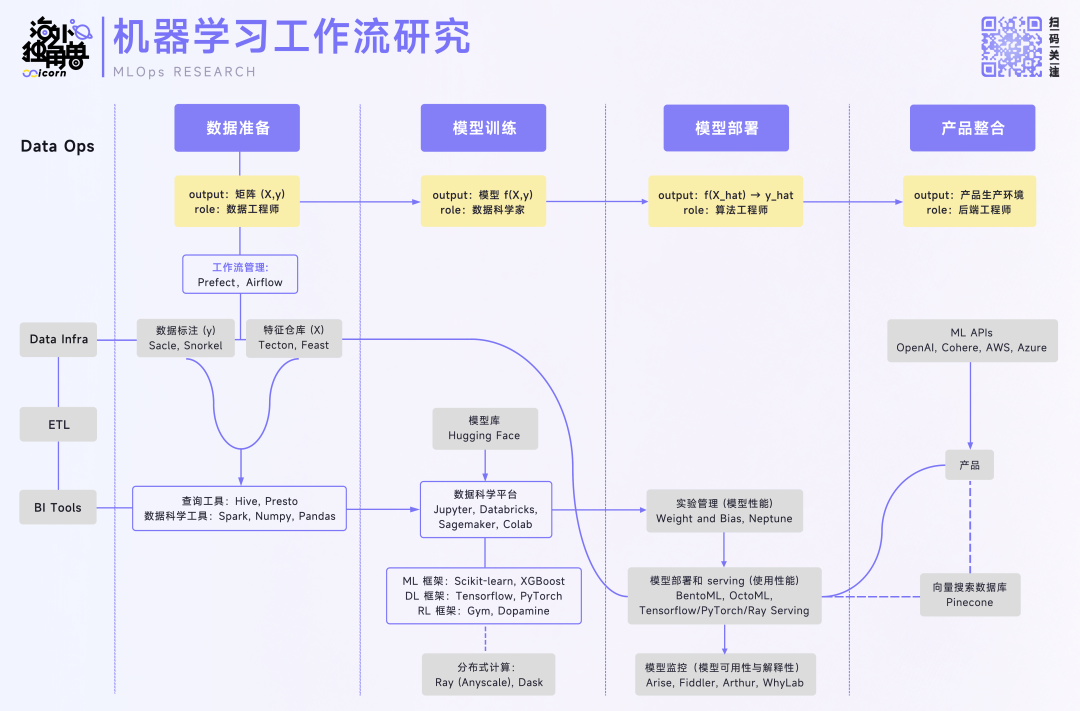
以下对 AI 工作流总体可以拆解成四个垂直模块:数据准备,模型训练,模型部署和产品整合。
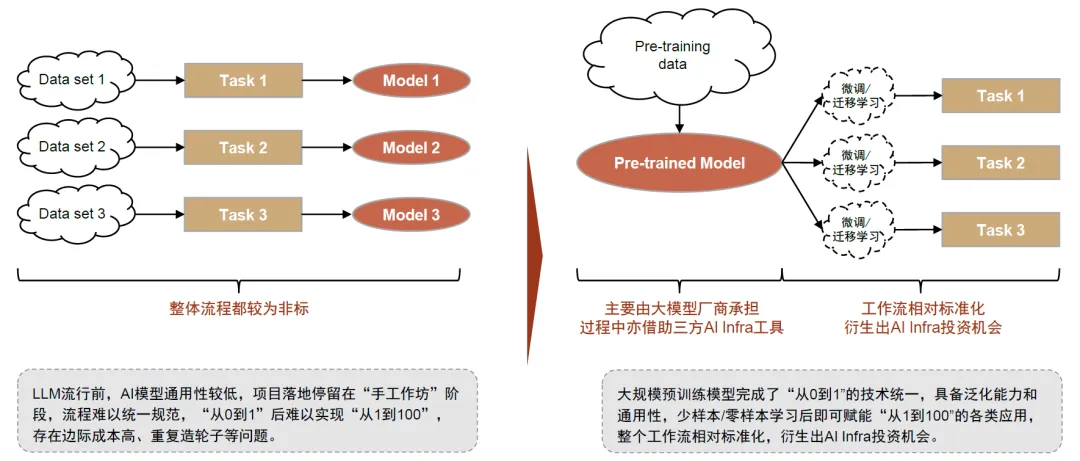
LLM流行前,AI模型通用性较低,项目落地停留在“手工作坊”阶段,流程难以统一规范。人工智能已有数十年的发展历史,尤其是2006年以来以深度学习为代表的训练方法的成熟推动第三波发展浪潮。
然而,由于传统的机器学习模型没有泛化能力,大部分AI应用落地以定制化项目的形式,包括需求、数据、算法设计、训练评估、部署和运维等阶段,其中,数据和训练评估阶段往往需要多次循环,较难形成一套标准化的端到端的流程和解决方案,也由此造成了边际成本高、重复造轮子等问题【56】。
大规模预训练模型完成了“从0到1”的技术统一,泛化能力和通用性释放出“从1到100”的落地需求,且存在相对标准化的流程,衍生出AI Infra投资机会。
总而言之,就是算法的变化导致了infra层的变化:有的工作流不需要了,也有新的工作流,且流程相对标准。
数据准备
数据标注
作用:标注机器学习输入 (X, y) 中的 y 部分,在一部分目标变量 y 缺失的业务场景为 AI 模型提供人类先验知识的输入。作为上一代 AI 兴起时最旺盛的需求,在计算视觉领域使用场景相对较多【56】。
重要公司:国外:Scale AI(人工数据标注供应商),Snorkel(使用模型对数据进行合成 / 标注)。国内:海天瑞声等。
商业价值评价:低
LLM无需求,LLM 本身具有很强的自监督属性,输入的数据和输出的数据并不是标准的pair的状态。
由于OpenAI和LLAMA 2的RLHF(Reinforcement Learning from Human Feedback)强调高质量数据对模型训练结果影响的表述;且在训练模型中参与科学家人数和工时最多参与数据反馈。对原来低质量数据标注方法的颠覆,LLM模型不再使用标注数据,而使用人类少量的高质量的反馈。
按照meta 2023年训练llama2购买3万条高质量人类反馈*预计市场参与者10家*一年4次训练模型=2023年美国市场需要120万条,再*10美元的单价=最多1200万美元市场规模。
竞争形式预测:没有大的改变,业务变高端了,邀请专家来反馈,提高单价增值;价值较低,资源壁垒随时可破。大模型公司自己都可以做,没必要外包。
特征仓库
作用:管理机器学习输入 (X, y) 中的 X 部分,离线特征工程,在训练时更灵活地调整需要使用的特征组合和加工方式;在线实时预测,将线上的数据流灵活地提供给 model serving;和线上数据监控,保障模型使用的数据分布与质量的安全性【56】。
在 LLM 大语言模型的场景下,训练和推理数据不以这种形式进行组织,故 Feature Store 在 LLMOps 下没有使用前景。
合成数据
作用:真实数据的补充。做真实数据的“平替”,用AIGC反哺AI。一项来自Epoch AI Research团队的研究预测存量的高质量语言数据将在2026年耗尽,低质量的语言和图像数据存量也将在未来的数十年间枯竭。
面对潜在的数据瓶颈,合成数据即运用计算机模拟生成的人造数据,提供了一种成本低、具有多样性、规避了潜在隐私安全风险的解决方法,生成式AI的逐渐成熟进一步提供技术支撑。
比如,自然语言修改图片的Instruct-Pix2Pix模型在训练的时候就用到GPT3和Stable Diffusion来合成需要的提示词和图像的配对数据集;Amazon也利用合成数据来训练智能助手Alexa,以避免用户隐私问题。合成数据市场参与者较多,独立公司/项目如gretel、MOSTLY AI、datagen、hazy等,数据标注厂商如Scale亦推出相关产品,此外主流科技公司英伟达、微软、亚马逊等均有不同场景的尝试。
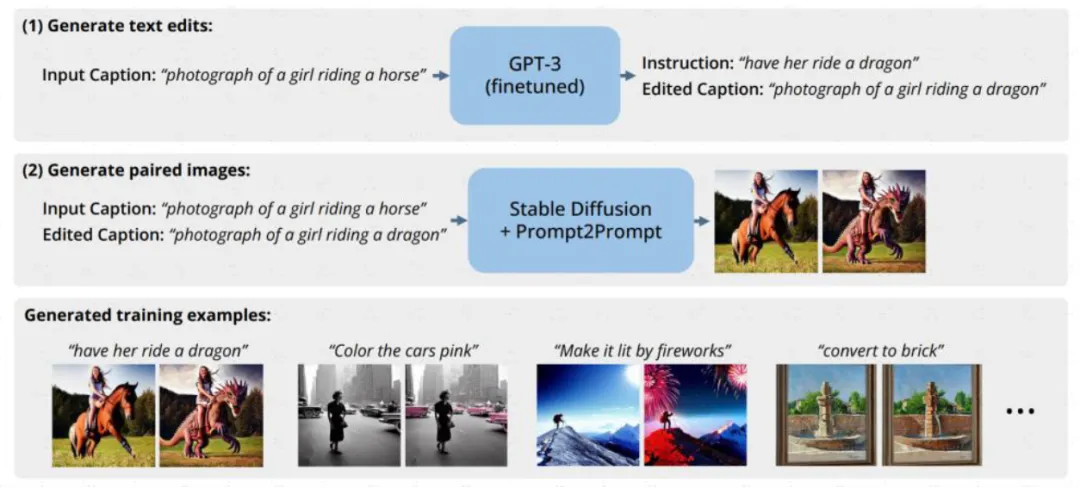
图:Instruct-Pix2Pix借助GPT-3、Stable Diffusion生成指令-图像训练数据集
商业价值评价:中
那么在LLM里,合成数据真的有效嘛?答案是否定的,合成数据提取了样本的特征,并进行相似性的替换,特征仍然无变化;且数据本身会和真实数据混合,导致真实的数据特征漂移,噪声变多,大模型过拟合。
但在以强化学习和模仿学习为主自动驾驶算法领域一级具身领域(神经网络端到端的FSD),算法无法覆盖到未曾见过的场景–强化学习的缺点,也就是所谓的coner case,这时候使用合成数据,在仿真平台中训练模型,确实可以提升其在coner case的性能,但仍然有限。
目前英伟达的sim saac等平台也可以做到仿真生成环境,解决coner case的市场规模较小再加上汽车企业的账期较长8-12个月,所以商业价值较中。
国内公司有光轮智能、智平方、Hillbot和银河通用。
查询工具&数据科学工具及平台
作用:广义的数据科学涵盖利用各类工具、算法理解数据蕴藏含义的全过程,机器学习可以视为其中的一种方式和手段;狭义的数据科学也可以仅指代机器学习的前置步骤,包括准备、预处理数据并进行探索性分析等【56】。
一般在开源框架上自研,无商业价值。
模型训练
模型库
作用:机器学习届的 Github,以更 AI-native 的方式组织 AI 开源社区,为 AI 研发提供安卓式的环境【56】。
重要公司:典型代表厂商包括海外的Hugging Face、Replicate,国内关注Gitee(开源中国推出的代码托管平台)和ModelScope(阿里达摩院推出的AI开源模型社区)OpenCSG等项目。
商业价值评价:低
占据着数据科学工作流的入口位置,用户数量较大;但其开源属性增大了其商业化难度,目前变现手段不多。
传统 ML 模型规模小,训练成本低,基本不依赖 Model Hub;大语言模型场景下许多科学家和工程师通过 Model Hub 调用开源的预训练模型和参数,来减少自己从头训练和定制化模型的成本。
小客户开发demo的场景更多!但做自己的模型肯定是脱离模型库的,可以理解为交流模型的论坛。已有龙头,且商业化机会对于专业开发客户小,仅作为营销平台(广告盈利)和做demo。
大模型训练框架
作用:AI 模型训练与推理的核心框架,使模型能够高效的实现计算。以深度学习框架为例,其内嵌实现了以下事情:可以绕开手写 CUDA 代码,直接简单地使用 GPU 搭建模型。这使得深度学习框架门槛变低很多,只需要定义神经网络的结构与损失函数,即可跑通一个基本的模型。可以理解为深度学习的开发软件。
重要产品:Tensorflow (Google), PyTorch (Meta), Jax。
Tensorflow 先发优势明显,早期占据了业界的主流。但其版本管理做得不好,易用性也略逊于 PyTorch,在学界被 PyTorch 后发超越。目前在业界使用 PyTorch 的公司也在变多,但由于迁移成本高,Tensorflow 也有一定公司在使用,况且 Tensorflow 是使用谷歌开发的 TPU 的主要选择。Paddlepaddle(百度)、Mindspore(华为)。大公司掌握,为其深度学习的生态之一,免费使用。
商业潜力:低
尽管这一领域没有显著的商业潜力,但还是在这里介绍一下这类框架,因为这是当前所有 AI 模型的基石,有着很强的生态意义。
训练和推理阶段的计算优化
作用:通过芯片层面或者算法层面优化开发成本和推理计算成本
由于LLM的算法的改变,所有之前的优化办法基本失效。在这里对LLM算法和计算机体系的全面的洞悉是稀缺性的,具有非常高的壁垒(又有大规模语言模型的训练经验,又有对计算机底层系统-存储、计算等的了解的人非常少)。
同时,降低模型的训练和推理成本,是大模型企业竞争的重点,目前价格和成本昂贵是导致大模型没有被大规模使用的头号问题;不管是大模型公司,还是使用大模型的公司付费意愿强,客户覆盖众多。
市场规模上来说:训练和推理的计算成本是大模型企业的最高占比成本。且推理优化的上限要比训练优化的上限更高,具体数字已在算力层表述。无论是采取订阅制还是API的盈利形式,市场规模都将是百亿甚至千亿美金的级别。
商业潜力:极高
目前主要是两种技术路线进行优化:两种一种是硬件层面的优化,一种是直接在AI算法上优化。但国内企业仍需要突破一体机的商业模式。
硬件层面的优化
目前国内硬件优化的公司为主,并且率先商业化,但在在硬件层面上,技术可创造的 margin(提升空间)不大了。比如硬件利用率,理论上最高是 60% 多,现在大家用英伟达的系统和软件已能做到 40%~50%,可提高的空间就是百分之十几。并且GPU优化技术面临着严重的同质化问题,各厂商之间的性能差异并不显著。
潞晨科技:
潞晨的产品重点在于训练与推理一体化解决方案,尤其侧重于训练领域,在推理技术路线上,潞晨仍然主要集中在GPU优化方面。
硅基流动:
硅基流动专注于MaaS模式,通过云端向用户提供Token服务。这一模式要求其具备广泛的模型兼容能力,以支持多种不同的模型和技术手段,并结合云计算管理等一系列增值服务。
清昴智能:
清昴团队源自清华大学计算机系媒体与网络实验室,专注于构建模型部署平台,在底层不同GPU芯片的适配及模型部署服务方面积累了丰富的工程实践经验。团队最近主要集中于与部署相关的MLOps算子以及对国产芯片兼容支持的算子开发。
无问芯穹:
无问团队主要成员来源于清华大学电子工程系。在技术路线的选择上,该团队主要聚焦于GPU利用率和通信的优化以及计算机集成系统优化。
总体而言,纯粹依赖于GPU优化的技术方案面临严重的同质化挑战,现有的开源框架已经达到了较高的性能,使得各厂商在性能表现上的差异化优势不再显著。
AI算法上优化
算法上优化的是没有上限的,潜力最高。
以存换算的推理算法优化+全系统协同优化的趋境科技是该行业的黑马:由清华系MADsys高性能计算机实验室团队组成。
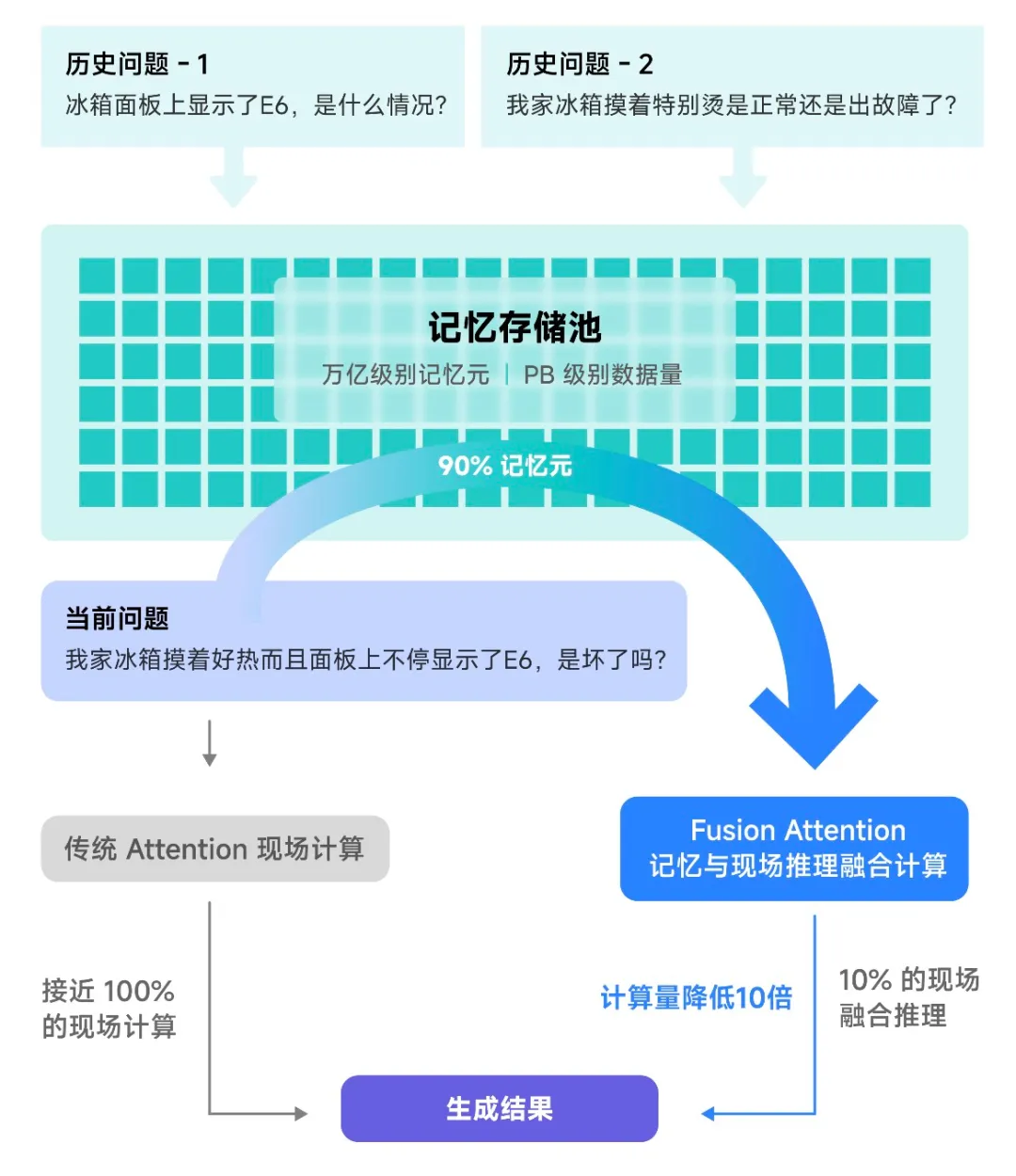
利用推理阶段的KVcache缓存,存储多次提问的相似的问题和答案,避免重复计算,特别是未来的CoT的长推理场景,需要重复推理,成本可以直线下降。
趋境科技创新性地设计了“融合推理(Fusion Attention)”思路来利用存储空间,即便是面对全新的问题也可以从历史相关信息中提取可复用的部分内容,与现场信息进行在线融合计算。这一技术显著提升了可复用的历史计算结果,进而降低了计算量。
尤其在RAG场景中,“以存换算”能够降低把响应延迟降低20倍,性能提升10倍。
在此基础上,趋境科技首创的“全系统异构协同”架构设计也成为重要技术支撑。该架构是首个允许在单GPU卡上支持1Million超长上下文的推理框架,以及首个单GPU上运行2000亿参数MoE超大模型等等。
目前,趋境科技已联合清华大学一起将异构协同推理框架的个人版,名为KTransformers的框架在GitHub开源,并在Hugging Face等开源社区引起广泛关注和讨论。行业合作伙伴也对此兴趣颇高,已有多家知名大模型公司主动抛出橄榄枝,与其共同发起大模型推理相关的项目建设。
模型部署
模型安全和监控
作用:保障线上模型可用性和可观测性,实时保持对模型输出结果和指标的监控。未来会是模型可解释性和安全的重要领域【56】。
重要公司:Fiddler, Arize, Arthur, Whylab。
商业价值评价:目前低
LLMOps 需求:增加,LLM 语境下的 AI 安全将成为重要命题。
LLM 大语言模型的性质比传统 ML 模型更为复杂,有包括 Prompt Engineering 等激活和微调方法存在。为了保障安全性和可解释性,随着 LLM 在软件中的深入落地,对模型的监控和后续管理会有着更高的要求。目前已经有新型公司,如 HumanLoop 在专注这个领域,之前的公司中 Whylab 也在做相应的尝试。
目前,大模型公司本身并不注重安全性,还是在追求性能上,安全问题是否会被大模型公司外包?目前以RLHF为主要对齐手段上,确实不需要外部公司参与模型微调。
模型部署和Serving
作用:模型部署是指把训练好的模型在特定环境中运行的过程。过程中需要最大化资源利用效率,且保证模型部署上线后在用户使用时有优异的性能。出色的部署工具能够解决模型框架兼容性差和模型运行速度慢这两大问题。具体使用场景可以参考下图:
重要公司:BentoML, OctoML【56】。
LLMOps 需求:增加
商业价值评价:目前低
基于 AI 的应用和产品会越来越多,优秀的模型部署能降低模型的推理成本并提高性能,模型部署和 serving 会在 LLMOps 重要的需求,且可能会衍生出模型剪枝、蒸馏等能压缩模型冗余的部署 serving 需求。但都是大模型公司本身在做。
二次开发
开发者工具
作用:为开发出agent工具,提供调用各种细分工具的平台,产出智力成果。
Agent作为最终的LLM产品形态,属于大模型的智能能力的关键一部分,一定会研发,且难度非常小。一方面LLM会将开发者和c端的流量卡在自己平台上,一定会提供不同程度的自定义开发平台(GPT2023年末已经推出agent开发工具商店以及GPTs:无代码的agent应用开发)。
商业价值取决于大模型公司是否会向后整合。
目前有两种商业模式:
1 提供开发工具的开发者平台
国内(Fabarta),模型开发者工具Langchain,Together AI。
2 无代码的agent开发
公司有CoLingo、AutoAgents.ai、Babel、Dify.AI。
向量数据库
作用:非结构化数据库,储存的数据形式为向量 embedding,在推荐系统、搜索引擎、异常检测、LLM、多模态等场景下都是数据输出、搜索、召回的重要形态【56】。
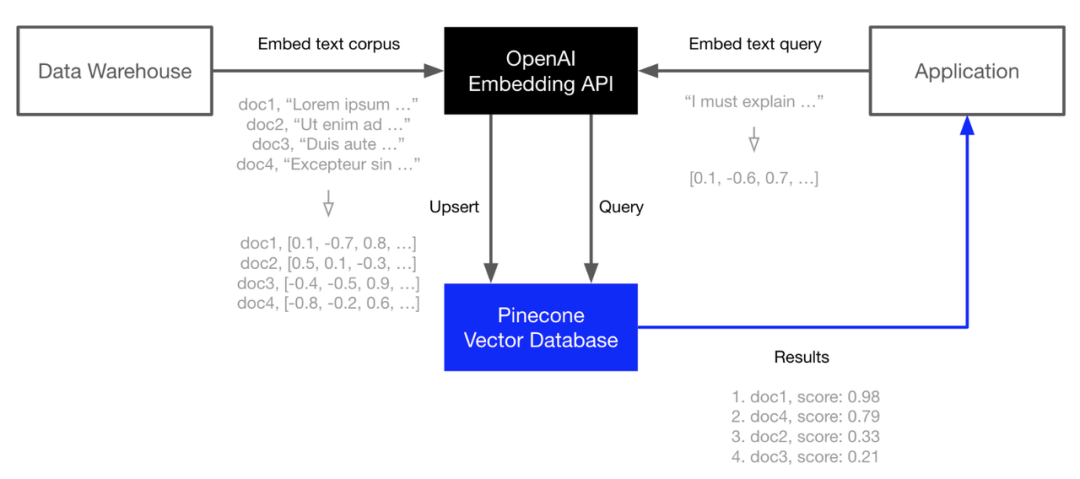
重要公司:Pinecone, Zilliz;国内英飞流/InfiniFlow等
LLM需求:增加,但商业潜力:较低
在 LLM 语境下,向量搜索和查询会在软件中扮演更重要的作用,而向量数据库则会成为这一方向中最重要的基础设施之一。
首先,向量数据库比较核心的技术就是索引(FLAT、HNSW、IVF)、相似度计算(余弦相似)、Embedding(将各种信息转化成向量,降低信息复杂性);这些技术在大模型火之前就有了,时至今日本质上没有显著变化。
其次,赛道进入门槛比较低。无论是大模型提供方,还是传统数据库厂商都可以转型进入这部分业务;这也就导致竞争会变得非常激烈。对于初创型公司来说,无论是拼财力还是拼客户都完全没有优势。
由于其降低成本和实现关键agent检索能力,模型大厂还有云计算厂商主动纳入其能力。
七、大模型层
大模型层,无论海外还是中国,竞争格局非常统一的都是初创公司和互联网企业。
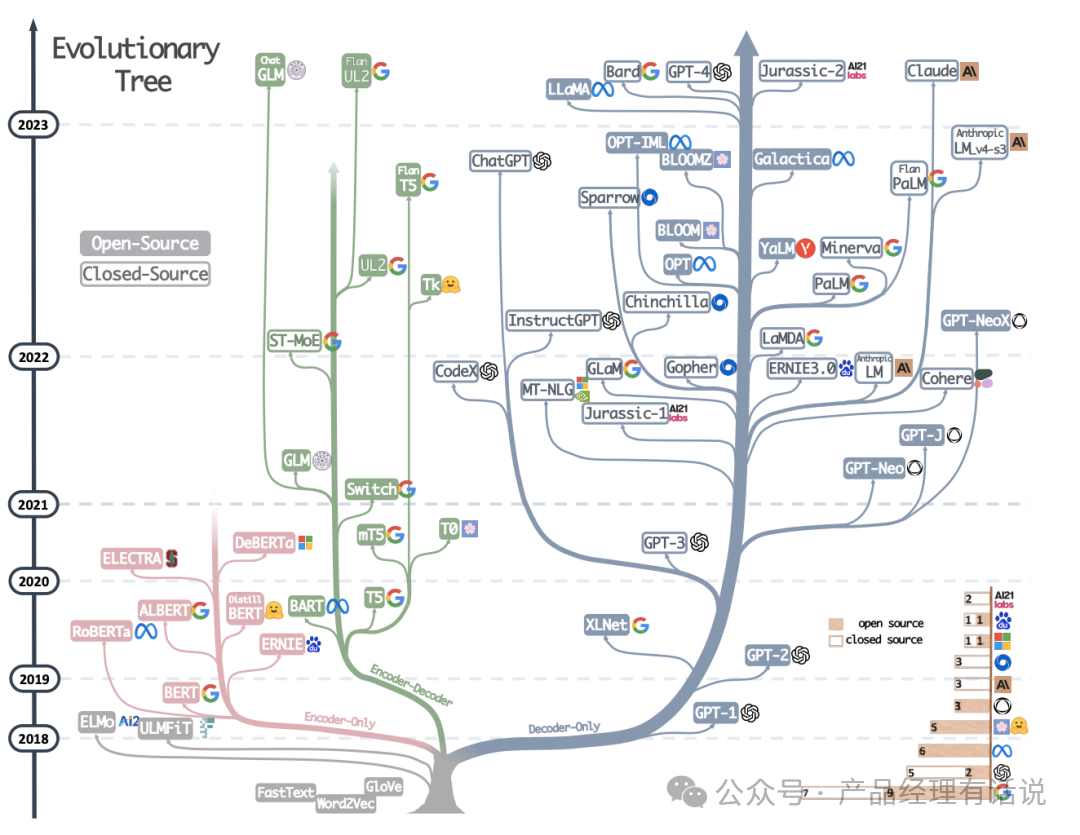
开源 vs 闭源
在生成式 AI 向前推进的过程中,围墙花园依然存在。OpenAI 并不 open 地仅开放商业化付费 API 作为 GPT-3 的使用方式,谷歌的大模型也并未开源。
下图展示了开源社区追赶 AI 模型的时间线,可以看到技术追赶速度正在逐渐变快。那么这个趋势是否会持续呢?如果差距持续缩小或较为稳定,AI 模型开发可能成为 iOS vs 安卓的格局;而还有另一种可能,则是差距逐渐放大,AI 研究所专业化地研发大模型,开源团队主要做中小模型的工作。这一判断的关键因素,会是各团队对 GPT 模仿与超越的进度。
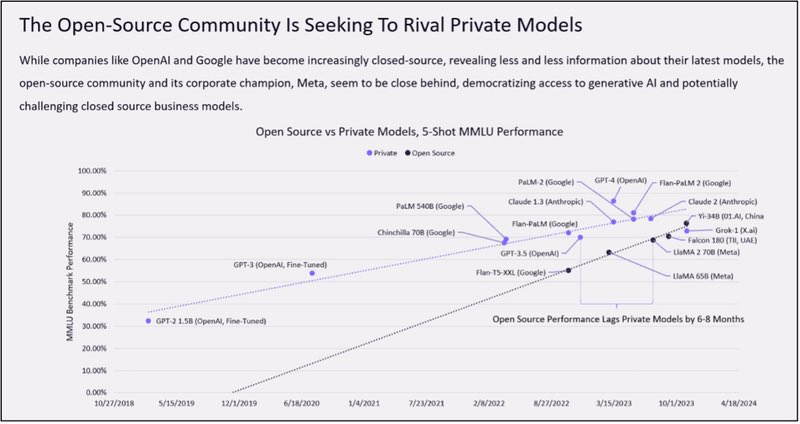
但总归而言:闭源比开源好!且公司一旦做出效果,也会闭源!
大公司采取完全闭源或者部分开源的方式(META开源-为了集中智慧,更好的优化模型;但是训练数据并不开放和输出限制,并不符合最新的开源标准)
1 闭源有数据飞轮,将模型训练的更好
2 开源的盈利模式,只能提供非标准的开发服务,没有规模效应
3 开源发展慢于闭源,但商业化的竞争已然开始,以开源模型为基础的软件,性能和商业化落后
4 软件类的历史,都是开源先,再做闭源产品,天下没有免费的午餐
开源没有但使用者多,生态建立快,使用者还可根据业务需求自行增减功能或进行模型迭代,但是企业开发成本过高,无法及时收回成本,后面只能做为他人开发模型的工作,不具备规模经济优势,注定盈利模式走不通,但可以做营销。
对于下游的应用层开发者来说:
模型选择的问题,企业可以先用好的开源模型开发,再等待闭源模型技术发展突破(也可以同时开发,比较效果),再跟上(大模型层公司一定会提供标准化的工具)。
LLM
LLM的大模型公司是行业里主导玩家,整个产业都会由于该行业的竞争行为而变化。
从公开测试来看,中国大模型与国外模型仍有不小的差距。不过在scaling law的边际效应减小的情况下,仍然可以在最多1年内追上。
海外
直接网站MAU数据说话,Chatgpt和借用OpenAI技术的微软的Bing断崖领先。还有app数据,考虑到大家使用都是通过网站入口进入,app的数据影响较少。
海外的商业化和技术进展整体快于国内市场,有非常好的借鉴意义。
初创企业
1 OpenAI
具有绝对优势地位!利用技术优势的时间差,正在快速商业化和防守!
团队:掏空硅谷人才的顶尖公司,但是由于众所周知的不再“open”和改变企业性质为盈利组织后,一次团队“政变后”,关键科学家伊利亚以及安全团队的出走,企业后续的顶层技术设计能力堪忧。CEO奥特曼是美国孵化器YC(国内奇绩创坛的前身)的总裁。
 事
事
事实上,近期OpenAI的人事变动颇为频繁,大量关键科研人才流动。此前在今年5月,OpenAI超级对齐团队负责人Jan Leike以及联合创始人、前首席科学家Ilya Sutskever在同一天宣布离职。此外有消息显示,OpenAI另一位联合创始人Andrej Karpathy也已在今年2月离职,并且去年加入该公司的产品负责人Peter Deng也已离职。
随后在8月初,OpenAI联合创始人John Schulman宣布离职,并表示将加入AI初创公司Anthropic。彼时OpenAI公司发言人曾透露,总裁Greg Brockman将休假至今年年底,并且Greg Brockman本人表示这是其自9年前创立OpenAI以来第一次放松。
今年9月OpenAI首席技术官Mira Murati也宣布离职,并表示,“经过深思熟虑,我做出了离开OpenAI这一艰难决定。离开这个深爱的地方从来没有一个理想的时间,但感觉此刻就是最好的选择”。
本月初OpenAI旗下Sora AI视频生成项目负责人Tim Brooks宣布离职,加入OpenAI的主要竞争对手谷歌DeepMind。近日,OpenAI高级研发人员、OpenAI o1推理模型负责人Luke Metz宣布即将从OpenAI离职。
目前OpenAI的招聘重点已经从基础研究转向产品开发和应用领域。
战略方向:根据开发者大会,可以确认OpenAI重点将在继续开发多模态大模型(寻找下一代的Scaling Law以及Cot等等)和寻找商业化(1为基于gpt的开发者提供全栈的开发工具和方案–免代码的GPTs和Assitant 2运营应用软件的平台-Store 3To C的搜索引擎以及Canvas工作台);向后向前整合关键能力。特别是C端,OpenAI一定会去尝试去做大市场的生意。
To C类(获取流量):提供Chatgpt,GPTs agent和GPT-store,奥特曼长期如果想要推翻谷歌,成为新的检索入口,必须要找到新商业模式和生态!(特别是找到和广告商收费,但又不破坏C端客户使用体验的商业模式)。
OpenAI确实在产品化上有所不足,目前OpenAI的招聘重点已经从基础研究转向产品开发和应用领域。此前在2021年,该公司发布的招聘职位中有23%属于一般研究类职位,但在2024年这个比例已降至4.4%。
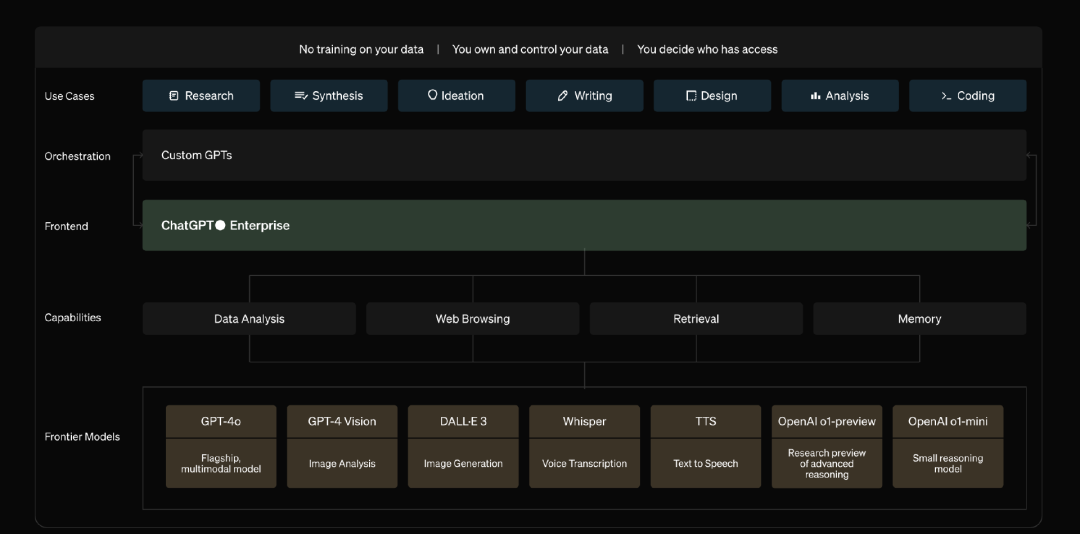
对于B端(ISV生态工具栈):短期内参考苹果生态(广泛吸引开发团队入住),市场上对C产品收取高额月费享受ai服务,可以短期收钱,但是目前来看大模型竞争随时赶上,赚钱的服务也将会被垂类公司赚走,如何获取和留存大流量;提供统一模型微调和训练工具。为了应对谷歌等大公司整体生态的竞争,必须要走出商业差异化!
与互联网大厂合作:微软占有49%的股份,引用至自己的终端(copolit agent–LLM版搜索引擎救活了微软无人问津的浏览器edge–两年内从8%的市场份额提升至15%!直接挑战谷歌chrome),同时也投资了另一家大模型公司,大公司都会使用大模型来对其企业产品进行agent化和云服务的协同工作!微软同时投资mistral和引入inflection ai的ceo,说明对OpenAI的掌控不强,所以才做的多手准备。BTW,微软云计算的azure上的GPT的api费用要低于OpenAI官网的价格。
对于OpenAI来说,一方面的投资有算力的加成,快速训练,一方面微软也对奥特曼的支持导致了伊利亚想把奥特曼踢出团队的失败。另外根据协议,OpenAI一旦开发出AGI(第五级-AI可以完成一个组织的工作),微软就将失去OpenAI的技术。
总而言之,OpenAI拿算力、数据;微软拿到OpenAI的技术作出产品,赋能业务。
2 Anthropic

创始人达里奥是一个技术天才,在OpenAI的5年间,他先后带领团队开发了OpenAI的早期产品GPT-2和GPT-3,成为首批记录人工智能规模定律和规模化的技术大牛。
正是这段经历,达里奥逐渐意识到AI可能比想象中强大,它带来的安全问题也比想象中更严峻,然而,OpenAI似乎并不能解决他的顾虑。2020年6月,GPT-3问世,半年后他与妹妹丹妮拉决定一同辞职。
OpenAI核心团队出来创业,Anthropic 已经和 亚马逊、Google、Salesforce 达成了战略合作,使用 Google 提供的云服务,并且集成到 Slack 中;Anthropic也表示会进一步扩大与AWS的合作,提出将“从芯片到软件的技术基础,共同推动下一代人工智能研究和开发。”其中就包括合作开发AI芯片,以及AWS业务的进一步渗透。
Anthropic 的成功源于其独特的技术路线和商业策略。首先,Claude 3.5 Sonnet 模型在性能上实现了质的飞跃。根据 Anthropic 官方的数据,该模型在研究生水平推理能力(GPQA)、本科水平知识(MMLU)和编码能力(HumanEval)等多个基准测试中均表现出色,甚至超越了其前身 Claude 3 Opus。
基于Anthropic发布了一项革命性的技术——模型上下文协议(Model Context Protocol,MCP)目标是实现LLM应用程序与外部数据源和工具之间的无缝集成。
因为允许LLM访问和利用外部资源,它的功能性和实用性都会大大增强。解决LLM数据孤岛的问题。使得开发者更容易开发自己的产品。
无论是构建AI驱动的IDE、聊天界面,还是创建自定义的AI工作流,MCP都提供了一种标准化的方式,来连接LLM与它们所需的上下文。
Claude 3.5 Sonnet 引入了革命性的”计算机使用”功能。这项功能允许 AI 模型像人类一样与计算机图形用户界面交互,包括解释屏幕图像、移动鼠标指针、点击按钮,甚至通过虚拟键盘输入文本。这种创新大大拓展了 AI 的应用范围,为企业用户提供了前所未有的灵活性。
此外,Anthropic 还推出了”Artifacts”功能,允许用户直接在聊天界面中与模型输出进行交互和操作。这不仅提高了生产效率,还促进了人机协作的创新。
Anthropic 的成功也得益于其在安全性和道德方面的重视。公司率先提出了”宪法 AI”的概念,为其 AI 模型制定了一套道德准则和行为指南。这种做法不仅赢得了用户的信任,也为整个行业树立了标杆。模型与人类道德强对齐。
3 Mistral AI
Mistral AI成立于法国和2023年4月,由DeepMind和Meta的前科学家共同组建,专注于开源模型及企业级服务。公司成立之初,就获得了英伟达、微软和Salesforce等科技巨头的投资。Mistral AI被视为OpenAI在欧洲的主要竞争对手,据该公司介绍,其开源模型Mixtral 8x22B是市面上参数规模第二大的开源模型,仅次于马斯克的Grok-1。
不过,在与科技巨头的竞争中,Mistral AI面临很大的挑战。今年前三个月,Meta、Google和微软在数据中心建设和其他基础设施的投资总额超过了320亿美元。不过,Mistral AI已与微软建立了长期合作伙伴关系,利用Azure AI的超级计算基础设施训练模型,并共同为客户提供Mistral AI的模型服务。
互联网企业
还有meta、谷歌、亚马逊、推特等自研的模型!谷歌的Gemini和meta的Llama模型,性能都非常不错。且有流量的优势,agent产品化后搭载在自己硬件如谷歌手机,软件如Meta的app上。
关键是谁会赢?
在基础的算力和数据上,初创公司远远不如互联网企业,唯独在算法层面,或者更具体的说:AI算法认知领先,在智能工程上(数据、计算机系统)有一定的开发领先知识和经验。预计和大厂们有个最多8个月的技术优势。然而在scaling law大概率失效下,这个时间将会被快速拉短。
本身大厂们就是算法领域知识产出的主要来源(推荐算法、cv都是互联网厂商的深度学习的拿手好戏,适应新算法很快),本身的transformer算法也是由谷歌提出,且互联网大厂的业务就是cash cow,不缺利润,后期追上很快。只是现在为了市场的竞争,快速合作,ai化产品赋能业务增长,实际上都在自己做模型。
在这种博弈下,初创公司只能不断创造壁垒,保持技术上的领先的同时,找到一条可以挑战互联网企业的商业化路径(至少这里还有无限的可能),否则会被互联网初期免费的策略竞争(基本上互联网企业的模型都免费,或者api价格远低于初创企业,Llama都直接开源的)。所以初创企业和终端应用层的界限将会十分模糊,大模型企业除了提供MAAS的api等服务外,也会提供丰富的产品给到用户。
如果无法成功商业化,那么初创企业基本上就会和上一时代的CV公司一样:商汤、旷世依靠给互联网大厂卖人脸识别api起家,技术成熟后,同质化竞争,单次识别人脸的单价从几毛钱直接降到几厘钱,甚至更低;然后开始寻找二次增长曲线,各种行业(自动驾驶、医疗、to c等等),搞渠道,做非标总包定制化,毛利下降。。。。。
总而言之,初创企业必须找到自己的有壁垒的盈利池,特别是to c领域作为大头,拿到互联网算力和投资后,把握好关系避免过于深入参与业务,要充满想象力和勇敢挑战互联网大厂的业务,否则到头来就是个大厂外包研发团队,有业务能量和技术的等待并购or直接下牌桌。
那么这次的LLM浪潮到底是互联网大厂们的流量竞争的延续还是新时代的降临呢?
国内
初创企业
智谱ai:同时投资生数科技(美术类)和幂律智能(法律类),补充能力和应用层,商业化最成熟,主要面向to b;有语音、文本和图像,有开发平台;智谱 AI 已拥有超2000家生态合作伙伴、超1000个大模型规模化应用,另有200多家企业跟智谱AI进行了深度共创。
近期,在11月末智谱推出自己手机版的AutoGLM之前–可用语言操控手机的agent(LUI),下面应用层,会详细讲述,他的股东蚂蚁集团的著名app-支付宝,在9月份早早就推出了“支小宝”,人们可以和他对话,在支付宝上进行订外卖、订机票等等操作。
月之暗面:to c(主要定位)商业化最好:Kimi智能助手在2024年1月的访问量达142万,在大模型创业公司的“AI ChatBots”产品中居于首位,月环比增长率为94.1%,增长速度也在大模型创业公司中排名第一;技术优势,250ktokens的长文本输入,主打无损记忆;但只有文字,to c入手;最近又有了CoT能力,数字推理能力加强不少。
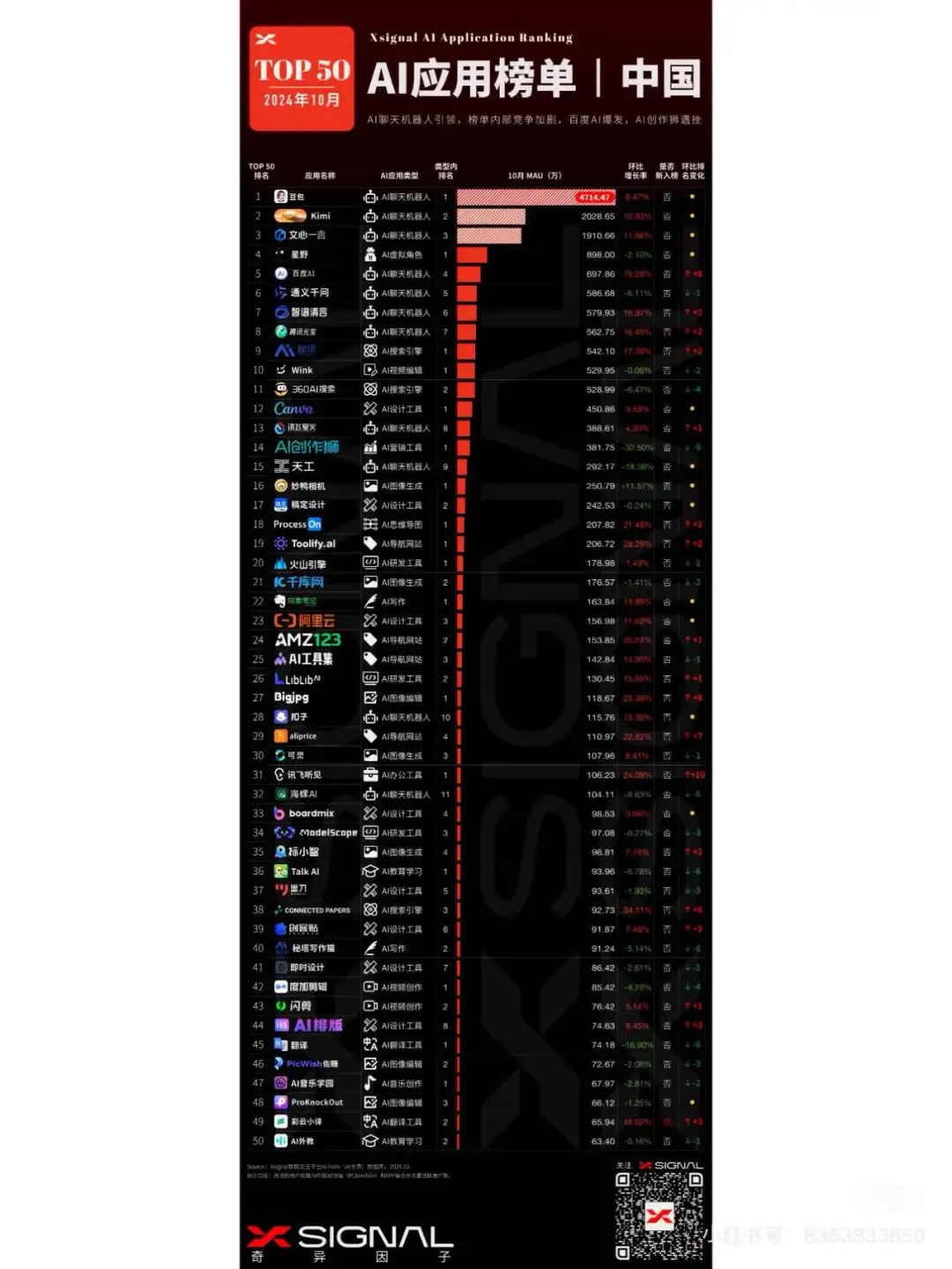
互联网企业
上述榜单为app使用榜单,非网页版,更符合大家对模型和应用层使用的市场认知。豆包的使用是断崖式的,和自己app业务的赋能,飞书等app内置豆包免费使用,加上宣发和教育板块的扩张。
字节的豆包、360、华为、百度、阿里、美团等等都在出自己的模型。这里面字节和360做的商业化和模型成果结合的不错,流量好。这里要说一句,幻方的deepssek模型通过优化注意力机制和量化的大量GPU(除了字节外,最大的英伟达算力方了),获得了非常好的效果,性能位居世界前列,但不商业化,不赚钱,只开源模型,模型的竞争实在过于强烈。
国内国外的竞争态势几乎一样。不再赘述。
八、应用层——软件
AI应用软件综述
目前应用层的问题在于,大家都是尝试在用,后续使用次数不多,无法利用好大模型的特性与需求贴合。
所以应用层的成功的关键是基于场景的深度理解,做出复用率高的产品!所以MAU、复购率等为关键指标。还是得回到应用场景的关键词:
刚需 长期 高频
应用层公司的模型选择路径
1 利用已有的闭源大模型用自己的数据微调模型:(但要找到合适的盈利模式,抵消流量费用)
训练费用和调用费用:OpenAI对训练和api调用收费。这通常基于使用的计算资源量和使用的模型。
- GPT-4v训练价格:$0.00800/1K tokens ,promt/输出价格:$0.00900/1K tokens 训练价格:$0.00800/1K tokens,1K tokens 大约750个英文单词,500个汉字,10个亿中文。
- 训练3次,仅花费35万人民币,关键在使用收费–交互2000次/1美元,大互联网公司一天估计有10亿次交互,每月要缴纳1500万美元,不如直接开发自己的大模型。
2 自研
3 开源大模型再训练
基本上应用层的公司还是微调模型,不自研,也就是所谓的“套壳”,所以他们的壁垒就在于对场景和LLM的理解从而开发出PMF的产品,而技术层面上来说,所有套壳公司要做的事情就是提示词工程-通过LLM偏好的语言习惯,引导LLM最优化的输出结果。
To B & To G–企业服务
海外龙头公司:Saleforce、SAP、Zoom、Adobe、云服务公司等
国内:钉钉、企业微信、飞书、金蝶、用友等
针对大模型的已有的创造和归纳推理能力,可以部分替代美术创意、文字推理归纳。
(一)信息管理类
CRM — AI客服
大型企业如 Salesforce、SAP 和 Workday 也推出自己的 AI Agent 产品。其中,Sales Agent 是目前 AI Agent 主要落地和商业化场景之一。硅谷 VC 围绕 Sales Agent 概念投资了很多 club deal,如完成了 5000 万美元的 B 轮融资,估值 3.5 亿美元的 AI SDR (Sales Development Representative,销售开发代表) 11X,Greenoaks Capital 领投新一轮的 Sierra 估值也达到了 40 亿美金【57】。
与此同时,Agent 公司从按 seats 数量收费的 SaaS 定价模式转向基于结果定价,带来了更大的市场空间和想象力。
目前的 Sales Agent Startup 大多专注于替代或优化销售流程中的某些环节。
AI客服历史
客服市场从上世纪 50 年代发展到今天,主要经历了四个阶段【58】:
传统电话客服(2000 年以前)—多渠道客服(2000 年-2010 年)—云客服(2010 年-2015 年)—AI 客服(2015年至今)。但是即使发展到今天,客服市场竞争格局仍然十分分散。在 LLM 之前,AI 客服依赖于自然语言理解(NLU) 和机器学习,不同的行业需要不同的语料库,客服公司通常仅能在一至两个垂直行业做深,难Scale。
第四阶段的 AI 客服也叫 “对话式 AI(Conversational AI)”,国际主要玩家包括 Kore.ai、Amelia 等。
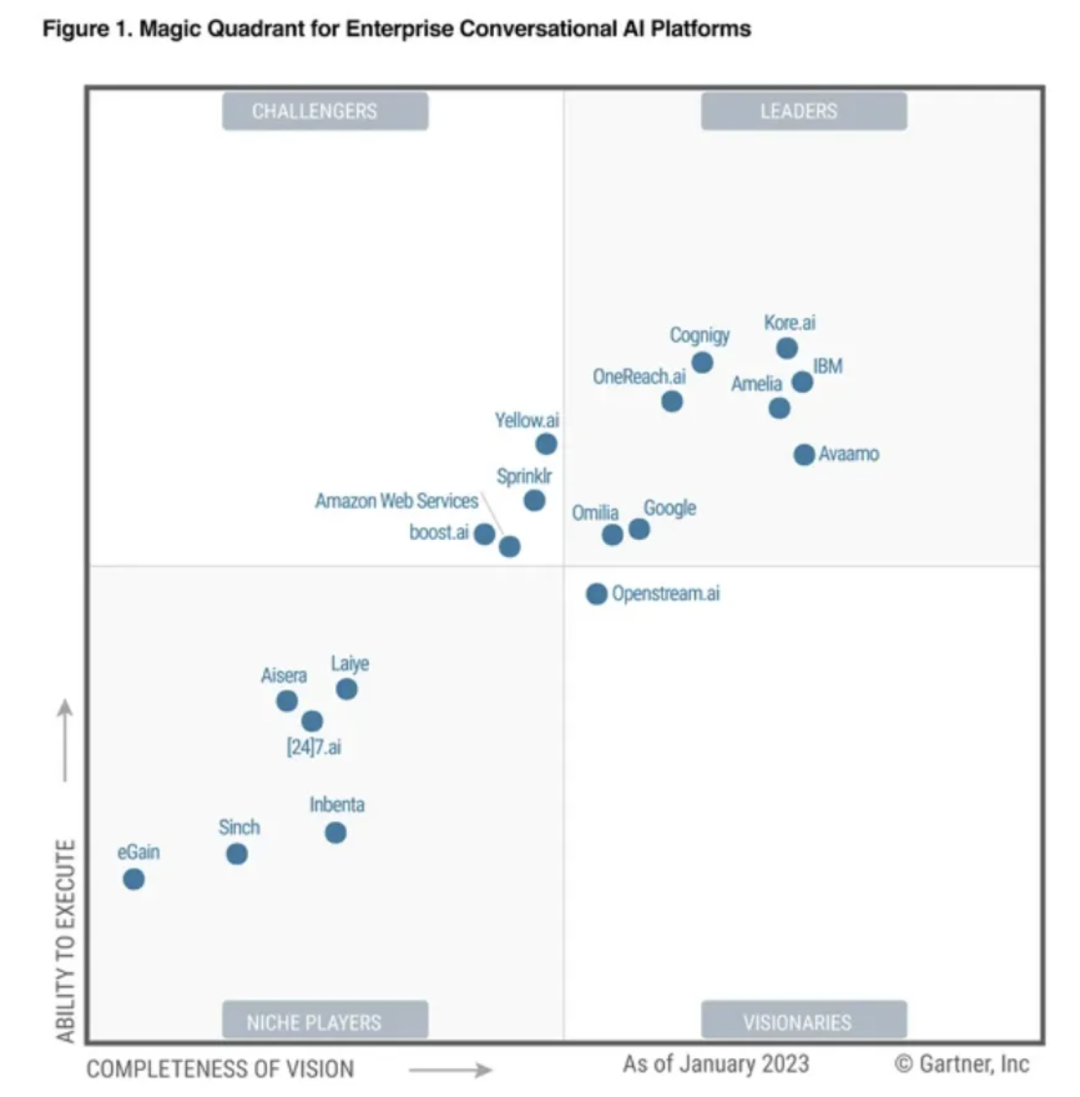
AI客服技术路径
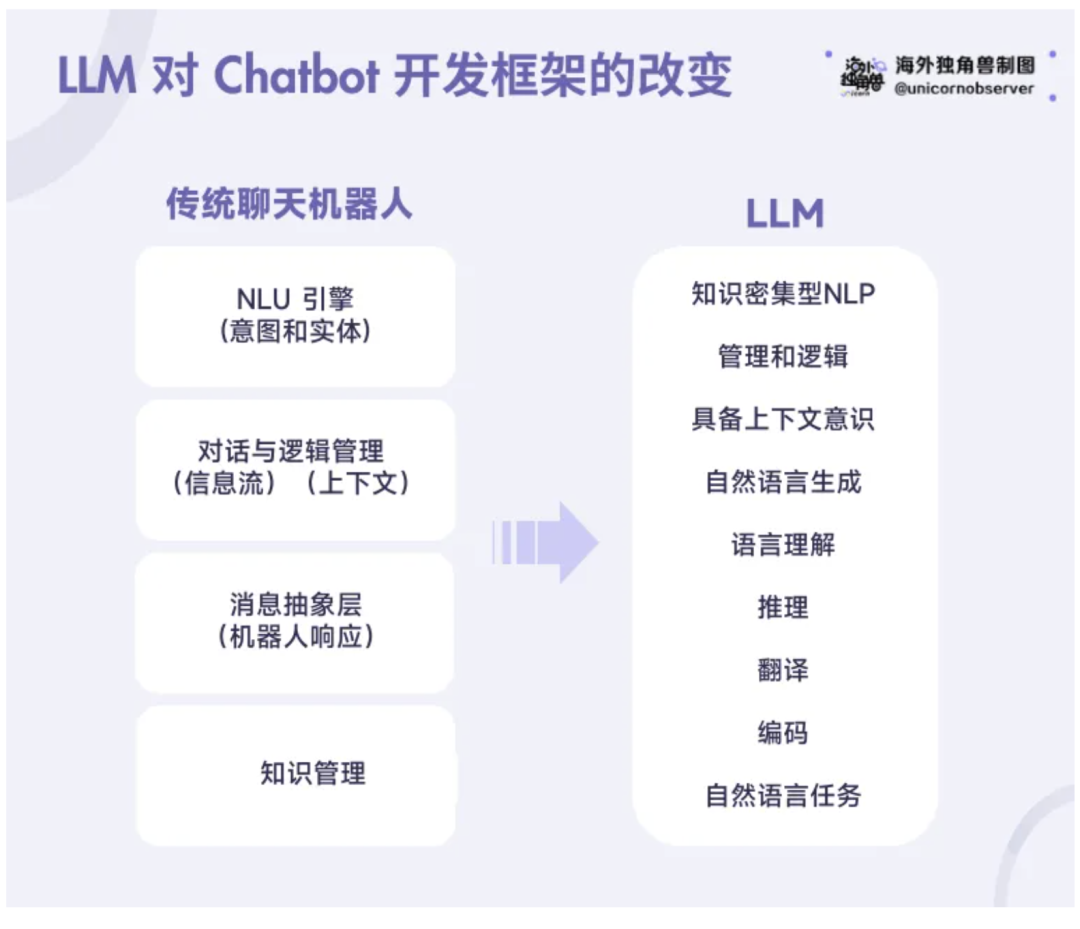
早期基于 Rule-Base 的 Chatbot 对答是可控、可预测、可重复的,但对话缺乏“人情味”,并且通常不保留已发生的响应,存在重复和循环对话的风险。传统 Chatbot 架构和工具非常成熟,主要包括四个部分:NLU 自然语言理解,对话流程管理(对话流和响应消息,基于固定和硬编码逻辑)、信息抽象(预定每个对话的机器人响应)、知识库检索(知识库和语义相似性搜索)。传统 Chatbot 唯一基于机器学习和 AI 模型的组件是 NLU 组件,负责根据模型预测意图和实体。这种 NLU 引擎的优点是:有众多开源模型、占用空间小/无需过多资源、存在大量的命名实体语料库、有大量垂直行业的数据。后来的 Chatbot 采用更复杂的算法,包括自然语言处理(NLP)和机器学习,来提供动态和上下文相关的交互,从而解决早期基于模板的方法的缺点。
Chatbot 发展到后期出现了 Voicebot。Voicebot 的基本方程式是:Voicebot = ASR(Automatic Speech Recognition) + Chatbot + TTS(Text To Speech)。这些变化增加了复杂性,提供更好的对话效果、更长的对话时间和更多的对话轮次,以及更复杂的对话元素(如自我纠正、背景噪音等)。然而,Voicebot 出现的同时也带来了一系列挑战:有延迟问题、需要更复杂的流程、需要加翻译层、容易出现对话离题、用户打断对话难以解决等。
因此,开发者依然在渴望一个灵活且真正智能的对话管理系统。LLM 的出现从开发到运行都颠覆了 Chatbot IDE 生态系统:不仅加速了 Chatbot 的开发设计,大大提高了Scalability;而且在对话运行中可以实现上下文交互、灵活且智能的回复。但缺点是稳定性、可预测性较差,以及在某种程度上的可重复性弱。
AI客服需求场景
根据销售工作流,可以将 AI 客服分为几类:
1)营销类外呼:售前场景因为对于模型的理解和智能能力要求较低,是目前比较好的落地场景。Voice agent可以带来更自然的对话体验,同时能够结合分析历史通话数据,实现营销转化的提高。如果遇到太难的问题,LLM 也可以检测后发给普通的客服。
2)销售中:目前LLM还比较少的被应用到直面leads,因为受能力限制,失败了损失过大。但被充分应用于客服培训中,一方面节省了因为电销频繁离职导致的过多培训时间成本;另一方面可以做到知识库实时对齐,成为电销的语音 copilot。
3)投诉/售后服务、客户回访(占比50%):AI 可以帮助客服收集客户投诉,解决简单的售后服务问题(不一定要使用LLM)。同时可以进行大规模的客户回访,也开始被企业广泛的采用。
市场规模
根据 Morgan Stanley 的报告,目前全球大约有 1700 万名客服代理人员,代表着大约 2000 亿美元的全球劳动力市场。随着多渠道协调响应的需求增加(例如电子邮件、社交媒体、聊天),这个市场从传统的客服中心向云服务转型。根据 Morgan Stanley 估计,目前高达 50 % 的客服互动都属于简单直接的类型(例如密码重置、包裹查询、需要退货),随着 AI 解决方案的改进,这些互动未来可能不需要人工客服的参与。但是考虑到客户强烈希望与真人客服交谈的偏好,在保守情况下,未来 5 年内,可由 AI 处理的客服业务将占 10-20 %,并且这一比例预期将增长。因此,Morgan Stanley 认为在未来 5 年内,Contact Center 市场(包括 CCaaS 和 对话式 AI )2027 年市场规模可达约 260 亿美元。
市场格局推测
Sales AI 领域非常Crowded,主要竞争对手可分为三大类:大型公司的销售自动化产品、同类 Gen AI 初创公司、以及上一代 AI 销售软件。
垂直行业的语料库和客户资源在客服 NLU 时代是玩家的竞争壁垒(数据、行业认知和客户资源),所以客户在选择供应商时更看重供应商在垂直行业的经验,因此截至目前 AI 客服市场格局仍然较分散。根据专家访谈,AI 客服市场未来很可能有 20-30 位玩家同时留在场上,重要玩家的收入体量大约可达到 10-30 亿美元。假设 LLM 落地成熟,考虑到 LLM 的通用性,市场格局有可能由分散变为更加集中,更利好头部公司。
众所周知的原因-中国市场的暂未接受订阅制导致软件公司无法像国外企业一样,获得高额的收入。但这也是商业进程问题,美国经历了软硬件一体机的IBM垄断,到Oracle等软硬分离的订阅制挑战,再到目前大模型的API-用多少买多少;每次盈利模式背后都是市场受够了被生产者垄断的剩余剥削,选择了更加平等的盈利模式;中国市场还需要时间。
所以即使收入增长很快,国内企业服务目前在融资低谷(大家更希望看到并购整合,只为活出资本寒冬)。但是原有的AI客服公司明显在新浪潮下,具有更大的先发优势:技术上-只需微调模型;但有大量的数据和场景理解;商业上有固定的渠道客户,新的盈利模式带来进行溢价的升级。期待商业模式的转折,重新将软件类估值抬回应有的水平。
LLM 对 AI 客服市场的技术风险
真正到了落地阶段客户仍更多采用传统机器学习/NLP 的解决方案(客户有定制化和垂直行业解决方案的需求,LLM 对垂直行业的理解和准确性反而不如传统方案),需要限制LLM的幻觉。需要因此目前主要是成立年限较长、有一定行业经验和客户积累的传统公司受益。但传统方案基于关键词进行回答,灵活度较差,用户体验也不够真实,因此该情况有可能仅是过渡阶段。
国内公司有:句子互动、斑头雁、追一科技、百应科技、Stepone等
ERP — 企业搜索
根据 ReportLinker 预测,2028 年,全球企业搜索市场规模将达到$6.9B,2022-2028年 CAGR 为 8.3%【59】。
供需:企业搜索产品的目标用户主要为知识工作者,企业客户覆盖大、中、小型公司,但以大型企业和中等规模公司为主,因为随着企业越来越庞大,积累的结构化、非结构化数据越来越多,员工与员工之间沟通也越来越低效,因此企业越大对企业搜索的需求就越大。
海外企业搜索大致经历了三个阶段:
1. 第一阶段是基于关键词的搜索,用户需要输入关键词或关键词组合进行搜索;
2. 第二阶段是基于语义的搜索,用户可以输入自然语言完成搜索,且搜索的相关性和准确性和第一阶段相比有很大提升。
前面两个阶段的共同特点是,均为用户输入关键词或自然语言,搜索引擎根据相关性对搜索结果进行排序,且搜索结果为网站;
3.第三阶段,也就是现在,搜索出现了新的玩法,ChatGPT 或 Bard 等搜索的结果不再是一条条网站,而是直接提供问题的答案。Glean 属于比较积极拥抱搜索行业的变化的玩家,技术上同时提供语义搜索和关键词搜索的能力,产品上同时提供答案生成和网页排序两种形式。
企业搜索的需求非常明显和稳定,因此该赛道一直比较拥挤,主要玩家包括微软、Google、Amazon、IBM、Oracle 等大型科技企业,以及专注做企业搜索的公司,如 Coveo、Lucidworks、Glean、Mindbreeze 等,这其中有像 Glean 这样新成立的公司,也有像 Coveo 这样已经成立十几年的公司。
与企业服务公司产品为互补品,可拆分,客户离不开原有的企业服务产品,且数据均在原公司,企业检索为增值服务,可短时间内自研。
Glean(谷歌搜索团队创业)
客户:Glean 早期将科技公司视为目标客户,后来更聚焦于成长期科技公司,这些公司的员工数量通常是 500-2,000 人,公司处于高速发展之中,愿意尝试新事物且快速行动。
技术:Glean 利用多维方法将矢量搜索、传统关键字搜索和个性化结合到了一个混合搜索系统中,从而提高了搜索的相关性和准确性。
核心功能是搜索;亮点是个性化和跨应用。
商业价值:Glean 的跨应用搜索相当于在所有 SaaS 产品之上架了一层,用户不需要再逐一打开 SaaS 应用,在 Glean 上就可以查到企业数据,并完成部分高频工作;流量进入入口,并且还能直接有生产力,目前最多的还是员工入职场景(培养使用习惯!)。
商业模式:纯 to B 的模式,未向个人用户开放。Glean 通常为企业提供两种定价模型,一是 Per-Seat 的定价模型,每个 Seat 每月 100 美金以内;二是针对企业级解决方案的个性化定价模型。
竞争优势:1易用性(链接多个SaaS合作),冷启动快(3天)2搜索能力的数据飞轮,形成个性化 3员工的网络效应。
但是无法沉淀业务数据,数据都在SaaS,有搜索数据沉淀,提供企服的公司一般也提供(并购逻辑),国外使用SaaS较多,所以需要企业搜索来使其串联,不像国内统一化。
未来的期待:想办法有一定的数据沉淀,未来要成为中心平台,需要再多做一些高价值工作替代or形成行业工作流的替代,让使用者继续使用。
国内
主要是大模型层公司在做,一种是帮助企业员工进行企业内部知识搜索和总结-私有化部署(项目制,商业潜力弱);一种是ERP公司使用大模型进行搜索并进行SaaS调用。
关注数据获取留存以及如何商业化,是否考虑垂直行业工作流的agent化!泛化能力不强,先抓住垂直客户的高价值需求,先商业化。感觉业务有些迷茫,目前客服和数据预处理都有大量玩家参与,大的ERP公司例如金蝶、用友等可以尝试调用大模型复制Glean,完善自己的企业软件使用入口,进行优化,通过大模型调用各类SaaS。
国内ERP公司目前的超万级的ISV和生态完整的工具栈壁垒是模型层完全无法竞争的,大概率做个内部技术支持。
HCM — 数字人面试&员工培训
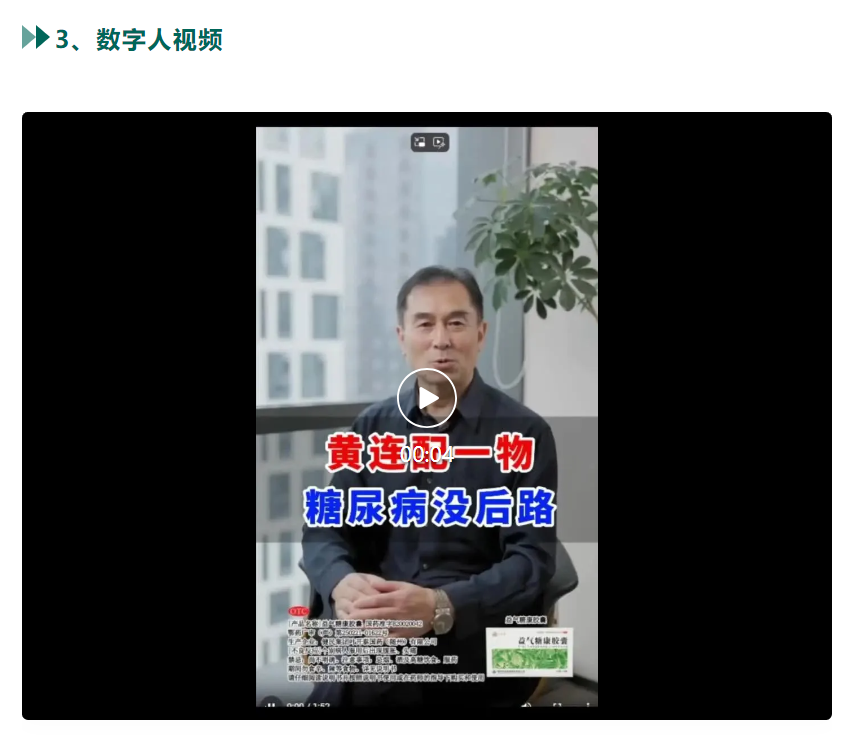
主要是数字人视频来代替面试(企业减少招聘投入并提供面试者之前机器面试的体验感)和新员工的入职培训视频。

数字人互动直播与录播有点类似,只是录播少了互动。在录播时会先把视频录制好,然后通过OBS推流,推到直播平台就可以了。如果需要互动流程时,要获取直播弹幕,判断弹幕是否满足回答条件,如果需要回答则生成答案,然后在走一遍视频制作流程,然后推流。
技术上无壁垒,商业上直播不允许用录制的视频,作用只能在短视频平台进行视频成本的下降。大厂都有在做。
目前对于可重复性多的视频生成场景,有较高的价值,例如网课、入职培训等教育和营销领域。看好出海,收入增长快的公司。特别是出海,详细分析请看下述的视频生成赛道。
初创公司代表:硅基智能、Fancytech、Heygen等,其他数字人中小公司也很多。
法律
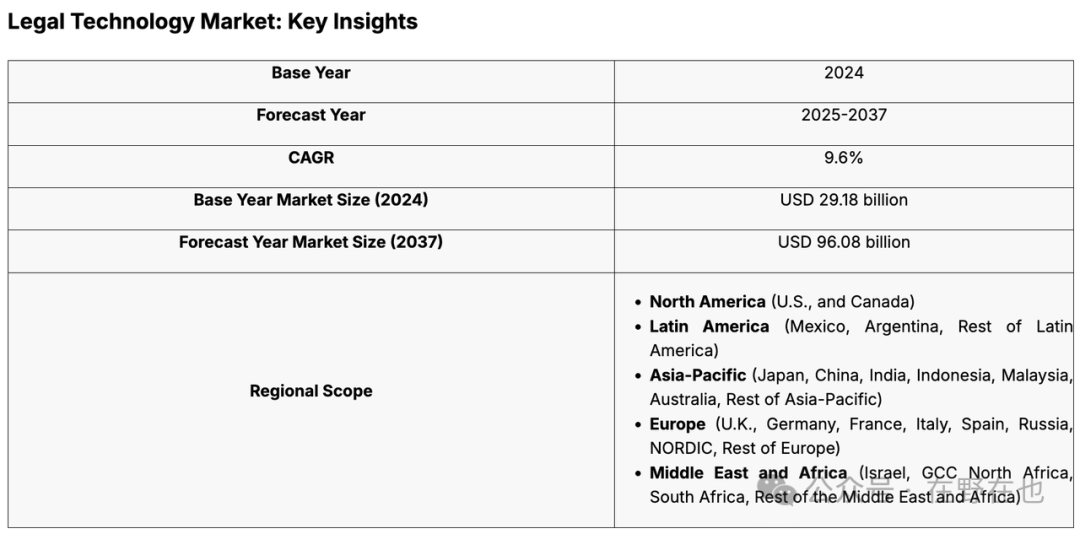
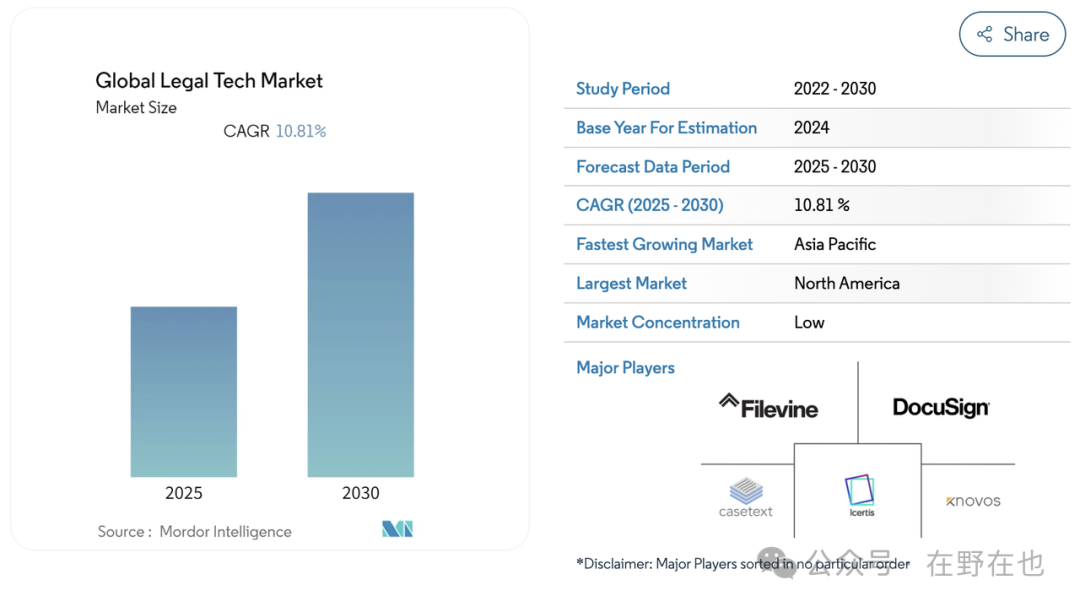
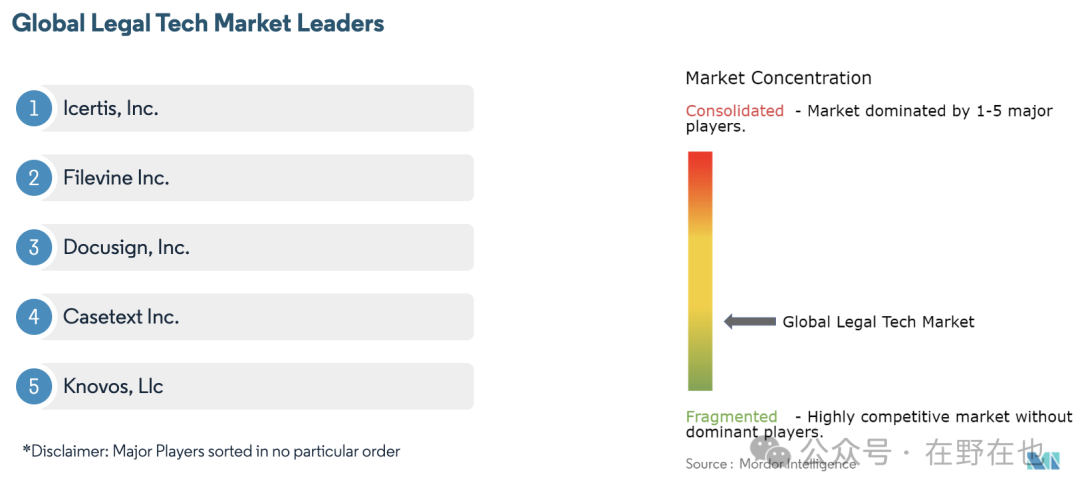
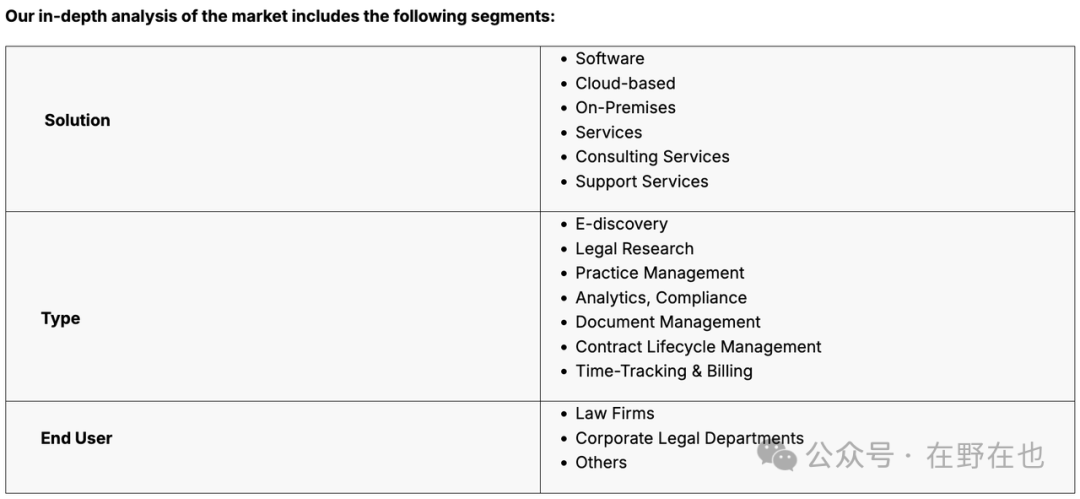
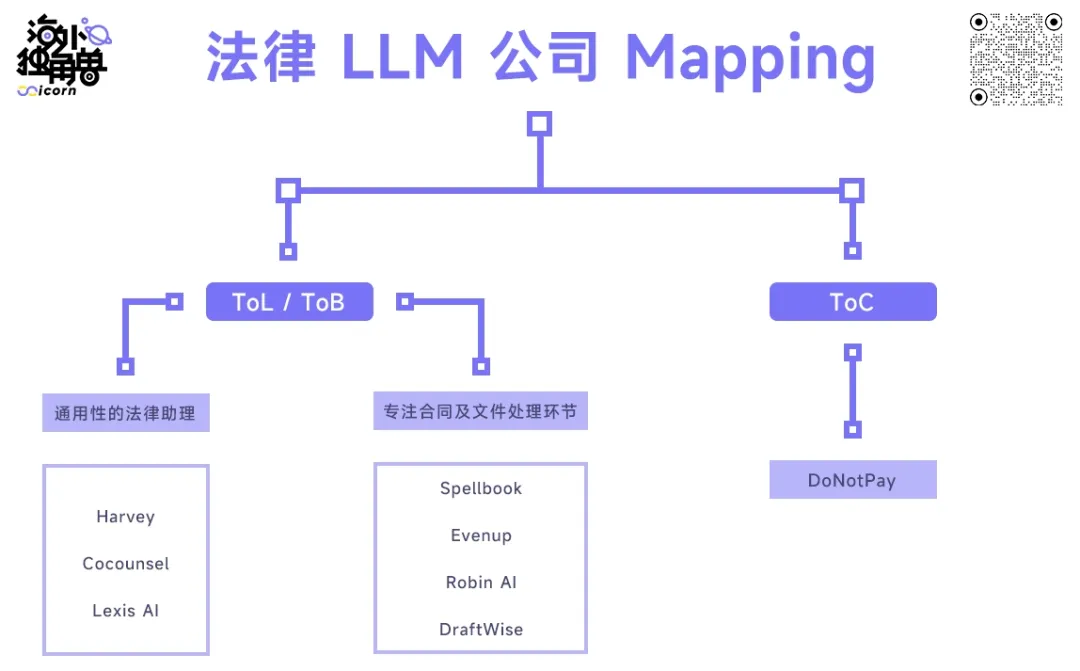
根据服务对象划分,Legal Tech 的种类可以分为 ToL 服务律师事务所、ToB 服务企业法务部门及 ToC 服务消费者。但值得注意的是,无论是 ToL 还是 ToB,企业才是最终付费方。即便产品的客户是律师事务所,由于律师事务所是为企业服务的,律师事务所会把 Legal Tech 工具转交给客户报销【60】。
LLM 出现前的法律 AI (以 NLP 为主)主要运用于合同管理,但这些工具以信息检索为主,很难对信息进行深度的处理与分析!
产品:
- 法律写作:撰写长篇、格式化的法律文件,帮助起草合同,撰写客户备忘录,作为工作起点
- 掌握专业法律知识,可以回答复杂的法律问题
- 进行合同及文件的理解与处理
- 定制公司特有的模型:使用客户特有工作产品和模板训练,以嵌入工作流,类似新员工加入律师事务所时的入职培训等
- 律所工作流:客户诉求的沟通与拆分、法律研究(法条检索和判例研究)、客户方案设计、合同、诉讼文书或其他法律文件的处理,以及其他涉及到法律适用问题的工作
模型层:
法律 LLM 创业公司主要直接接入 API 或 finetune 大模型,不同公司选择了不同的供应商,Harvey、CoCounsel、Spellbook 接了 GPT4,其中 Harvey 和 CoCounsel 2022 年下半年就获得了 GPT4 的优先使用权,Robin AI 则选择了与 Anthropic 的 Claude 合作;公司多采取多个模型组合去完成不同细分任务。
数据层:
不同公司能获得的优质数据不同,这对于 LLM 的表现会产生较大影响。CoCounsel 因具有 Casetext 多年的数据积累,并被汤森路透收购,可以使用其世界级法律内容库,在数据维度具有较大优势;Lexis AI 背靠 LexisNexis 也有类似的优势。而 Harvey、Robin AI 等新兴创业公司选择与头部律师事务所、四大审计公司绑定的方式获得优质训练数据。
看好有大模型训练能力、行业专业数据库、深入大客户工作流的切入团队是关键。
市场规模:
中国机会更大,2023年中国各类案件接受3200万件,400万件未处理,还有1400万调解(每年还以30%速度增长,这些都是强制未上升至受理案件的!中国法律服务能力缺口极大!),还有各类监管审查工作,ai的出现可以极大缓解公检法的极大压力!中国律师事务所4万家,每年增加2000家,中国约 57 万名律师。保底110 美元/月/人+超量使用+定制开发,目前市场规模60个亿元,且将会不断快速增长30%!
在中国to b法律领域有个重要问题就是,律师普遍工资不高,实现替换意愿不强,目前商业化进展缓慢。但需要持续关注。
笔者更关注庞大的C端市场!中国人需要一款专业的法律询问APP,依法治国的前提。
美国Harvey(openai投资),CoCounsel
中国:幂律智能(有数据、模型开发已完成)智普AI和北大的Chatlaw
审计合规
需求:国家和行业合规要求–GDPR,PCI-DSS,HIPAA,SOC 2,避免罚款和停止运营;合规和审计成本高–大型企业完成SOC2审计的单次成本超过100万元;工作量巨大,只能通过抽查来减少工作量,跨多部门,工作协调困难,数据隐私保护缺失,通过海量数据的采集和分析做到高效证据获取,最终生成可支持审计目标的合规报告。大大降低合规的成本(预计提升效率40倍)–人工审查+审计;同行检举过多,罚钱多。
两大业务:审计(出海大公司)和数据合规(出海公司)
工作流:1理解当地法律法规 2梳理业务场景 3找到敏感违规业务流 4合理规避法律风险 5定期人工检查 6生成报告
市场测算:
数据合规(出海的中小型公司)
2027年,出海企业72万家,每年新增5万家,所有的涉及数据获取的企业都要符合当地规定,会遭同行举报,有天价罚款。假设渗透率20%,10万一年,中小型增量就有150亿人民币。大型公司将根据用量收款。
还有审计(出海大公司),想象空间大
发展趋势:IT合规自动化平台在国内尚无明显领先者–主要是法律新规,美国欧洲很成熟,中国刚刚起步,没有竞争对手,出海和国外上市公司需要。
(二)研发设计类
从技术来说,LLM+Diffusion的生成技术就是完美契合该类行业,甚至幻想本身就是一种创造力。从商业价值上来说,创造是最好的切入工作流的入口!先创造后修改!
美术类工具
在讲美术生成式的行业之前,笔者先讲下国外几家在做的事情以及思考,方便大家理解整体市场。
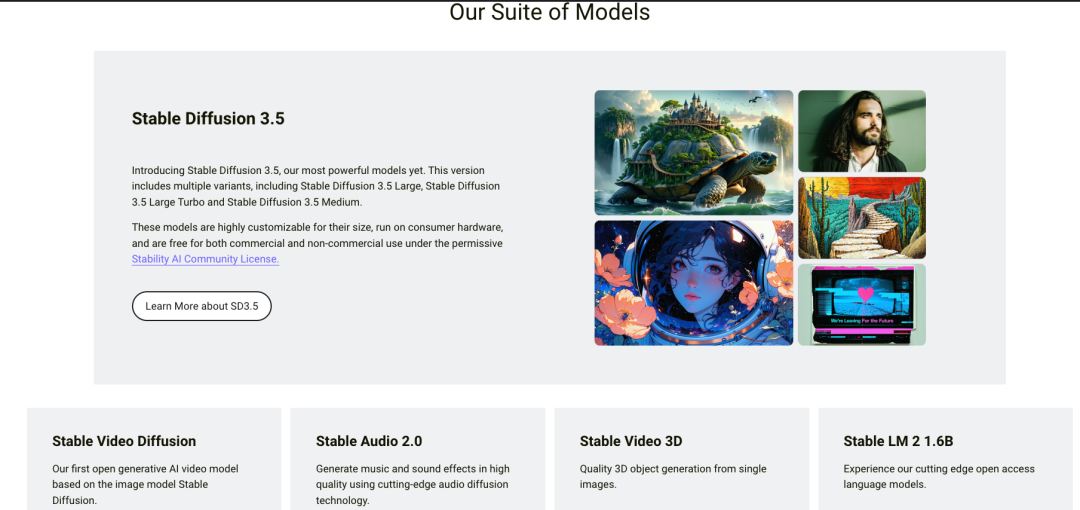
Stability AI
基于 Diffusion Model的Open model + Private Data,主要是针对B,G端的用户
战略:针对B端用户做模型的开发,支持开源为了证明技术、模型可控性和低成本技术外包!C端用户顺便收取费用。但是哪款产品都不是爆款,缺乏规划。目前团队商业化和管理能力弱。
技术:Diffusion开源模型(Stable Diffusion 由开源社区、Stability AI 及 Runway 研究员合作完成,Stability AI 并不独立拥有该模型的知识产权,Stable Diffusion 生成的作品版权遵循 CC0 协议,不归属于任何个人和公司,但可以用于商业用途):使用门槛低、模型调优灵活度高、生成效果好,加上 Stability AI 出色的运营能力,Stable Diffusion 成为了第一个拥有极强生态的开源模型(提供算力和资金支持–外包团队)。但是Stable Diffusion 中大量的数据反馈由于其开源属性无法形成优化模型的反馈回路,在更新模型上速度缓慢。
Diffusion的技术要解决精细化的问题!
LLM:StableLM 看起来又是一个营销胜于实际工作的例子。根据用户测评,与其他开源模型相比结果相当平庸,与 GPT 也相差甚远。
产品:付费应用 DreamStudio,大公司的api Plug-in,定制化咨询和大模型开发服务;通过开源,与生态合作,快速成长。
客户:常见的 B 端客户,还会为发展中国家的 G 端提供服务。
盈利模式:
1)服务大公司,提供定制模型和咨询服务:Stability AI 的核心业务是为大公司建立专门的团队,形成合作伙伴关系,出售模型(扩展和定制 Stable Diffusion 或其他大型生成模型,每个模型的报价约几千万美元),并为企业提供咨询服务,帮助大型公司和政府对 AI 模型的采用。
2)付费应用:孵化社区生态中的技术与应用,推出商业化版本,如以 Stable Diffusion 为基础的 DreamStudio,上线第一个月,收入就达到数百万美金,用户数量达到 180 万。
3)API:通过提供开源模型的 API 收费,并提供增值服务。Photoshop等公司的插件。
成本:Stability AI 作为开源生态的基础设施,为开源社区提供算力及资金支持是一笔极大的开支。
据说目前 Stability AI 拥有在 AWS 运行的、由 4000 多个 Nvidia A100 GPU 组成的集群,用于训练包括 Stable Diffusion 的 AI 系统,导致其运营和云服务方面的支出超过了 5000 万美元。
团队:创始人为印度人,无AI经历,团队来自世界各地,管理风格自由,这增加了成本,减缓了产品开发,没有总体的规划。
图片生成的竞对Midjourney进化之快得益于其出色的产品设计和闭源属性带来的的数据飞轮。MJ 做了较强的风格化处理,使得 to C 用户体感更好,但是我们注意到,SD 开源社区的 Finetune、Alignment 模型风格化后也能达到较好的效果,所以不排除 Stability AI 也有能力做到,只是重心不同。
除了 Midjourney 等通用型文生图软件,垂直类应用也层出不穷。不同行业对生成图片有着不同的要求,需要使用特定数据集训练,这给垂类赛道的创业企业提供了机会。如专注于 Logo 与网站设计的 looka,专注二次元形象生成的 NovelAI,专注游戏资产生成的 Scenario,以及专注头像生成的 Lensa。这些垂类应用目前来看很难成长为大体量公司,但盈利能力强,如 Lensa 在发售后的短短几周就赚了 4000 – 5000 万美元。
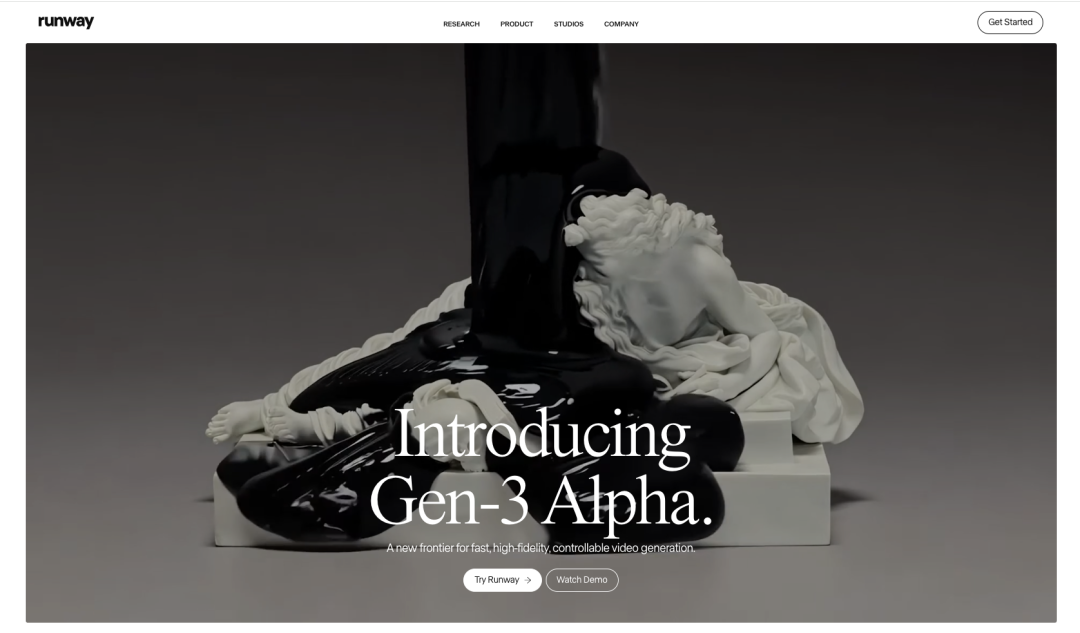
目前Runway/Pika的定位是Video Making Interface,AI native tools,图像视频编辑工具,关键是能从好用的单点工具闭环成用户不可或缺的工作流产品!视频生成是编辑的一部分。
目前Runway/Pika产品跟Adobe-Premiere和抖音-剪映比,只是AI增值性的提升,而没有颠覆整体的工作流,也很难颠覆他们的产品生态;同时大公司也在进行AI的研发;Sora的出现有新解法,仅作为视频创作源,不入侵到视频编辑本身,但这两个公司没有那么钱和资源去竞争一家微软的子公司。

在专业视频编辑场景,Runway 难以撼动 Adobe 的护城河,其编辑工具目前无法应对专业精细化的要求,同时专业编辑软件 Adobe 和达芬奇(Davinci Reslove)也在 Runway 发布的新功能半年后就更新 AI 工具插件。在轻量化视频制作场景,Runway 面对高度嵌入抖音(TikTok)工作流体系的剪映。目前仅作为补充品存在。
Midjourney(专注文生图)
壁垒:设计师风格–差异化!高质量数据和模型(后期可加入tansformer现实世界模型)
技术:构建了自己的闭源模型,数据质量及数据标注质量的重要性远远超过模型本身,迭代非常快。
产品:艺术风格在市场上具有差异化优势。产品搭载在 Discord 中,用户通过与 Midjourney bot 进行对话式交互,提交 非常短的Prompt(文本提示词)来快速获得想要的图片。
客户:创意设计人群、工业设计人群、Web3 & NFT 从业者以及个人爱好者。若对标 Canva 的用户群,以 Midjourney 目前订阅价格计算,未来收入能达到约 23 亿美元。目前1000万用户量。
盈利模式:
目前采取 SaaS 订阅制模式,价格为 10 – 60 美元/月。虽未公布具体付费用户数量,但根据客户访谈可知用户付费意愿较强。以目前用户数量保守估计,年营收能到达约 1 亿美元。
Midjourney 采取 SaaS 订阅制模式。最初使用时,用户可以免费生成 25 张照片。之后按照订阅制收费。月付制为 10、30、60 美元,或者使用年付制,价格为 8、24、48 美元/月。值得注意的是,用户只有在订阅之后,才能拥有使用 Midjourney 创作的图片的版权。
成本:目前来看,Midjourney 的毛利率约为 80%。Midjourney 搭建在 Discord 上,Discord 会收取约 10% 的手续费。虽不清楚 Midjourney 的模型训练成本,但 Stable Diffusion 的训练共使用了 256 张 Nvidia A100,耗时 15 万小时,成本为 60 万美元。每次生成图像的推理在云端的 GPU 上完成,生成一张图片的成本约 0.5 美分一张,且未来成本会不断压缩。相对于订阅收入,生成图片的成本可以逐渐忽略不计。
中美的主要不同在于,中国式电商场景更多,生成式的商业化也会有所不同。
专业编辑
总体市场规模测算:
图片:Adobe,短视频:剪映,长视频:Adobe等专业软件
仅短视频:Instagram 月活用户为 20 亿,而 Tiktok 用户为 20 亿
目前数字媒体领域市场规模达到1500亿美元,由于短视频的快速增长(渗透率20&假设,增量将达到400亿),(非专业的客户也能使用ai和集成工具)增速极快。
专业编辑赛道工作流:视频制作过程,视频制作的后期则包括了逻辑剪辑、音乐制作、粗调成片、细调和字幕添加等工作,它们占据了专业视频编辑工作的 80%,Runway 有提供音频去噪、自动风格变换等功能。不仅如此,许多专业视频还要包括视觉特效的制作,而在特效制作过程中,最费力的工作便是 Green Screen(绿幕抠图)及 Inpainting(图像修复)。
竞争情况:
短视频领域要突破抖音生态!
但在专业美术领域有机会:Adobe采用的是Stable Diffusion的技术,而Stable Diffusion是开源,不具备长期优势;Adobe对新技术和新商业模式反应缓慢,即使推出Express对标Canva,也无法与其竞争,专注于专业领域的打磨产品。
国内竞争对手较多像素蛋糕,剪映等.
切入机会:关键工作流切入,但是要有自己的大模型和艺术风格等各工作流差异化–原工作流比较固定,并赶上1精细化的技术壁垒!可以先从垂类赛道和c端切入,积累数据和商业化。形成2完善的工具和3素材库+4云协作5独特艺术风格差异化!
国内无初创企业切入专业领域,持续关注。
美术设计生成
场景:游戏开发/建筑/工业设计美术生成,主要还是游戏领域。
市场规模测算:游戏全球3000亿美元,中国增速较快;分为IP/版权方、游戏发行方和开发(50%),其中美术占了50%的市场–750亿美元(20%软件+80%人工),假设去掉50%的人工和增加100%的软件费用,美术市场(主要是图片+3d模型的设计)将有600亿美元,全球增速6%,中国14%。
工作流:其中开发又分为
- 策划:负责游戏的数值、系统、剧情、战斗和关卡设计等。
- 程序:负责编写使游戏运行的代码。这可能包括引擎编程、AI编程、网络编程等。
- 美术:负责游戏的视觉效果,包括角色设计、场景设计、UI设计等。
- 音效:负责游戏的音乐和声音效果。
- QA(测试):负责在开发过程中找出和报告游戏中的错误和问题。
游戏核心在:故事讲述、游戏性上!AI长期内没有替换的能力!
竞争情况:目前龙头大公司还不具备AI研发的能力,都用的其他家的AI公司功能进行嵌入!
切入机会:在角色美术设计,3D建模,关卡设计等工作流实现创作!但是3D建模是根据美术概念来的(图片+文字),需要多模态的能力和大量设计数据,要求高。
挑战企业:
国外:
- Midjounry,Stable-Diffusion,Pika,Runway;国外新游戏引擎Jabali
国内:
- 图片:TIAMAT、 LiblibAI奇点星宇、nolibox计算美学、智象未来 HiDream.ai
- 图片+视频:右脑科技、生数科技、爱诗科技
- 3D生成:空间直觉Microfeel、Vast
营销设计
即使在经济不好的时候,企业也较少削减营销预算,缩减品牌营销相关投入会引发市场份额下降、销售额滑坡、品牌重建的长期成本上升等问题,反而得不偿失。
工作流:策略规划、内容创作、内容发布、效果反馈和优化这四个环节
市场规模:BtoC平均营销占收入15% /BtoB平均营销占收入10%,其中50%用来内容创作,TAM可达千亿美元,根据statia,全球内容营销行业市场规模为720亿美元;市场够大。
针对的客户:品牌企业或大型企业关注品牌效益和经济效益(目前AI还无法到达此水准),中小企业受限于营销预算,则更关注成本。
后续发展:要试图切入CRM赛道!抓住出海趋势(中国72万家公司出海,每年新增4万家)!
海外初创公司:Typeface
国内企业:衔远科技、FancyTech、WorkMagic、奥创光年
工业建模工具
竞争情况:国外龙头AutoCAD、SolidWork和达索;且需要数据和经验积累!
总结:中国市场较小100亿,有专业团队深耕可以;目前Diffusion技术不达标(图片集成效果不好和精细化不足)。
文字类
Devops-代码生成
总结:Visual Studio一家独大(还和copoilt-openai联盟),新公司产品差异化(仅在ui/ux)不明显,未看到颠覆其商业模式和技术。
切入IDE(Integrated Development Environment)不仅是开发者的超级入口,也有机会完整地收集到测试、环境配置和 Debug 等环节的复杂推理过程的重要数据信息,因此,是最有机会、最早能够出现 Coding Agent 的场景。
工作流:环境搭建、需求、代码编写、测试、代码scanning、代码重构、debug、部署
Copilot 用户已有 46% 的代码由模型生成,能让这些用户节省 55% 的开发时间;Copilot 建议代码接受率在 30%以上 ,并在用户上手半年后能提高到 36% 左右。
市场规模:2022 年,全球 DevOps 总收入规模在 80-100 亿美元左右,并正以每年 20-30% 的增速增长
竞争情况:因为流量和产品先发优势,IDE 目前几乎是被微软的 Visual Studio(免费)和 Github Copolit 联盟(18个月1亿ARR)所垄断还有Jetbrain 吃下了 IDE 市场 18% 份额(IDE 工具及商店抽成),Tabnine 、Codeium、Cursor 以及 CodeWhisperer 等 LLM-first IDE 团队则试图基于 LLM 提供更具差异化的用户体验挑战,模型能力相当,短期内收入可以。
写作类
市场长期PMF待验证,目前看下来,大模型性能好,也可以做,界限模糊。
波形智能-已被oppo收购、写作工具–深言科技。
音乐类
AI 生成音乐是一个发展了很长时间的研究领域,但之前生成的作品还停留在“人工智障”的阶段,Transformer 架构为音乐生成体验带来了 10x 的提升,2023 年出现的一系列基于 Transformer 的模型,包括 Google 的 MusicLM、Meta 的 MusicGen 以及 Suno 的 Bark,让 AI 生成的歌曲变成了可欣赏内容【61】。
技术变化
声音领域在 2015 年左右由于 Seq2Seq 的成熟曾有过识别技术的突破,但在生成方向的成熟比图像和文字更晚一些。其背后的原因主要是声音领域的信息密度更低:一个文字,一句歌词可以对应着很多种声音的表达形式,且生成的声音比文字本身的数据量要大很多。
直到去年,技术路线基本收敛到 Autoregressive Transformer 和 Diffusion model 并存的模型结构。Transformer 架构对音乐生成的质量提升帮助很大,因为音乐是一个有长距离结构(多次主歌+副歌,且有呼应)的内容形态。Diffusion model 的加入,能有效避免避免了自回归模型容易产生的韵律/节奏不稳定、词语重复/遗漏等问题。
2023 年 Google 团队提出了 MusicLM 使用了 Autoregressive 结构,实现了从文本描述生成高保真音乐片段,并支持对音高、速度等的精细控制。同一年 Stability 团队的 Stable Audio 工作中也开始有 Diffusion model 的加入,使音乐生成的效果更加稳定,Stable Audio V2 中使用了和 Sora 一样结合 Transformer 和 Diffusion 的 DiT(Diffusion Transformer 结构)。
Suno AI 音乐生成对语义有着很好的理解能力,对不同风格的规律、长距离的结构都能比较好地捕捉,我们判断 Suno 一定用了 Transformer 结构,带来了能 scale up 的智能。同时,Suno 生成的稳定性也远好于其他模型,Diffusion 模型架构应该在其中使用。音乐生成的模型结构会与 Sora 的 DiT 结构比较接近,由几个部分组成:

这个模型结构看起来很简单,和 LLM 和视频生成有很多相似之处,这可以被 Suno 创始人在访谈中的一个分享验证:Suno 团队在训练模型的时候,尽量不让模型中融入关于音乐或音频的先验知识,比如融入声素等元素,而是让模型自主学习。这种方法起初优势并不明显,但随着 scaling up 的推移优势开始显现。
谈到 scale,根据其他 TTS 模型参数量和目前的定价预估, Suno AI 的音乐生成模型的预估参数最大不超过 5-10b。音乐生成模型在数十亿参数量级就能做好很不错的效果了,与参数量相比同样重要的还有数据。
如果优秀人类的作品为 10 分,我们认为 Suno 可以到达 7 分普通歌手、“抖音网红歌”的水平:拥有多风格的作曲能力,可以创作出吸引人的旋律和节奏,但在音质、创新度上达不到专业作曲家的要求。但是已经可以为专业音乐玩家–Pro C,提供创意idea。
音乐市场
音乐的应用广泛,除了音乐专业制作,广告、影视、游戏、动漫、企业宣传都会用到音乐。音乐专业制作市场(the recording industry)的产业链主要分为以下环节:
- 上游 – 音乐创作与录制:包括进行词曲创作、编曲、录音、混音等制作环节。参与的人有作曲家、编曲家、录音工程师、音频编辑师、混音师、母带制作师等。
- 中游 – 音乐的出版运营、宣传推广:发行人会对音乐作品进行版权运营、数字分销。在宣传推广环节,通常会制作音乐 MV,通过各类媒体进行音乐推广。
- 下游 – C 端用户消费音乐:主要通过流媒体平台等渠道向听众传播音乐,同时开办演唱会、制作文创产品等,实现音乐 IP 的商业化。经纪公司也会对艺人进行宣传,组织演出等。
AI 生成音乐的应用机会不仅在为上游为音乐的制作环节降本增效,而且有机会将多个音乐制作参与角色合一,让每个创作者成为“全栈音乐人”,同时打通上游、下游,再造创作、消费一体化的 AI 音乐平台,也是我们期待的 Suno 的未来形态。下文针对受到 AI 生成音乐影响的上游和下游市场展开分析。
音乐制作市场
音乐制作为音乐产业链的上游环节,涵盖创作、编曲、录音和混音等环节,需要使用的工具包括 DAW、虚拟乐器、录音设备、音频效果器、MIDI 键盘、混音设备等,目前部署一套基础的设备需要约几千美元,更早期需要的投资更多。制作周期取决于音乐类型和规模,从几天~几个月不等,成本从几千~几十万美金不等。根据多家咨询公司的估算,市场空间大致为 $5-10B 左右,主要业务包括销售软件许可证、插件、硬件设备以及提供相关服务。
AI 有望进一步降低成本、缩短制作周期,将多个音乐制作参与角色合一,让每个创作者成为“全栈音乐人”。Suno 已经可以帮助用户生成音轨等组件,加速音乐创作流程。但本身该市场空间并不大,且比较分散,引入 AI 可能会导致 ToB 音乐制作市场的进一步缩水。
根据 A16Z 的判断,还有可能出现基于 AI 技术自动生成音乐的“生成性乐器”。硬件设备有可能与 AI 模型交互。例如,一个 DJ 控制器可能能够根据现场的氛围和节奏,自动生成鼓点或旋律,辅助 DJ 进行即兴创作。
To C 消费市场趋势
根据国际唱片业协会联合会(IFPI)统计,2022 年全球音乐市场规模达到 262 亿美元,增长 9%,其中流媒体收入占 67%,增长 10.3%。包括两块业务,一块是广告支持流媒体(Ad-supported streams),占 18.7%,通过展示广告来为用户提供免费的音乐流媒体服务,一块是订阅音频流媒体(Subscription audio streams),如 Spotify Premium、Apple Music 订阅,占 48.3%,约 130 亿美元。全球有 5.89 亿流媒体付费订阅用户,占全球总人口 7.5%。根据市场格局可以看出,流媒体音乐平台是音乐市场中最大的组成部分。
近十年音乐市场增长的另一个重要趋势来自于短视频。国际唱片业协会(IFPI)调研发现用户听音乐的时间显著增长,每周聆听音乐的时间从 2021 年的 18.4 小时增加到 20.1 小时,个性化需求也日益明显。国际唱片业协会(IFPI)也统计了用户听音乐的方式,发现人们在听音乐的时候,经常会和视觉相结合,很多情况下带有社交属性。
尽管分发渠道和用户消费形式出现了变化,但生产制作侧的垄断趋势还是比较明显:在 2022 年财报中,向索尼、环球等 record label companies 支付的版权费用占了 Spotify 收入的七成左右,因此流媒体平台当前还很难直接盈利。而当 AI 音乐生成降低了生产的制作与成本,是否能带来生产关系的变化呢?我们能期待 AI 有可能让版权优势不只被大公司垄断,而来自更多长尾、个性化的创作者。大众创作的时代。
市场竞争
Suno 最大的竞争来自于两个方面,一是 OpenAI 发布音乐生成领域的“Sora”,直接在产品效果上的碾压;一是版权公司和 Youtube、Spotify 等音乐平台公司,利用其数据和流量优势推出竞争产品,但他们面临更高的数据版权风险。同时,Suno 还面临着其他创业公司及开源体验的竞争。
OpenAI 是否会重现音乐生成的 “Sora”?
音乐生成模型的效果很大程度上是由数据质量决定的,这一方面取决于团队是否能拥有充足的数据源,懂得处理数据的方式,另一方面是否有充足的 GPU 进行训练。OpenAI “大力出奇迹” 的 Sora 一推出,对其他视频生成公司的打击有目共睹。OpenAI 目前已经注册了商标 Voice Engine™,包括”基于自然语言提示、文本、语音、视觉提示、图像和/或视频创建和生成语音和音频输出”,很可能包括了音乐生成产品。
如果 OpenAI 在音乐生成领域重现“Sora”将是 Suno 很大的竞争威胁。但我觉得细分市场的壁垒在于对场景的理解,提供丰富的工具,而且个性化的曲风的数据也是竞争的壁垒,不只是技术。
来自版权公司和音乐音乐平台的竞争
现有音乐公司对 AI 进行了积极的尝试,也采取了很多防御性的策略,包括 Spotify 刚刚推出的 Gen-Playlist,以及 QQ 音乐推出了 Suno 专区,但目前并没有出现类似 Suno 的出圈产品。一方面是 Suno 的产品具有一定技术壁垒,大公司的行动速度远慢于创业公司;另一方面大公司受限更多,会有更多版权、伦理上的限制。以及,我们所认为的平台、版权公司拥有的数据积累优势可能并不成立。生成高质量的 AI 音乐需要歌曲原始的分轨数据,但这是音乐平台也不拥有的,而原始分轨数据分散在各个版权公司和明星演艺公司,获得大量的数据很困难,购买成本也非常高。
音乐市场本身头部效应明显,有成熟的版权公司和流媒体公司;且音乐是一个反复收听次数最多的内容形态,因为这需要大众的情感共鸣,造成用户消费心智对新歌的需求频次低,对老歌的反复收听次数高。长尾、个性化的 AI 创作市场比较难以验证。
长期来看,我们认为 Spotify、Youtube 等现有大公司将对 Suno 产生更大的挑战。如用户在 Youtube 可以实现多模态音乐创作→发布的一体化,这其实与我们对视频生成格局的判断类似。Suno 的取胜关键是持续保持最好的生成效果、以及找到自己独特的产品形态。
总而言之,笔者非常看好音乐生成市场,可以先从to Pro C和to B层赚取创意费用,丰富编辑工具的同时,大步迈向to C市场,颠覆流媒体和ip拥有者的生态,将创作的能力、权力和收益给到热爱音乐的每一人。时间的尺度上一定是长期的,团队必须对此保持极大的热情。
SUNO

Suno 团队由音乐家和 AI 专家组成,目前仅有约 12 名员工。Suno 官网上写道公司文化以音乐为核心,鼓励声音的实验和创新,在办公环境中音乐无处不在。联合创始人包括 Mikey Shulman、Georg Kucsko、Martin Camacho 和 Keenan Freyberg,四人此前共同在被收购的金融数据 AI 科技创业公司 Kensho 工作。其中 Shulman 和 Camacho 是音乐爱好者,他们在 Kensho 工作时常常一起即兴演奏。
从经历来看,创始人有成功的创业退出经历,并且在物理、科学领域有极强的造诣。创始成员还有在 Tiktok、Meta 等互联网公司的从业经验。AI、物理领域的造诣以及对音乐的热爱,使得团队对开发 AI 音乐生成产品具有很强的适配性。
团队以自己训练的开源语音生成模型 Bark 为基础,开发了SOTA 的 AI 音乐生成产品。Suno 团队认为目前音乐听众数量远远超过音乐制作者是“失衡”的,期待用 Suno 让每个人都能将自己的想法转化成音乐,打破普通人与想象中音乐之间的障碍。
类似 Midjourney 让人人都可作画,Suno AI 作为第一款普通人可用、带有人声、歌曲生成效果接近商业化水平的产品,为全球 5.89 亿音乐流媒体付费订阅用户提供了创作工具,开辟了增量市场。
音乐制作效果被用户称为 “the next level of music generation”,在硅谷核心圈得到了广泛的流传,实现了用户的持续增长,根据 Similarweb 的数据,目前已经达到了约 220 万 MAU。
Suno 团队从开源 TTS 模型 Bark 开始,转型做音乐模型,从 Discord 服务器到自己的 UX 交互流媒体播放器,都行动非常快在半年内发布了成熟的产品。
Suno 网页版本的产品形态很简单,远没有到达 Spotify 等产品的复杂度。主要由 Explore、Create、Library 组成。Microsoft copilot 也集成了 suno,用户可以通过 chat 的方式来进行音乐创作。
Explore 界面,会展示歌曲创作的 prompt 指引,以及用户创作的最火、或最新的 AI 歌曲。暂不清楚推荐逻辑,但不同用户登录后看到的歌曲是一样的,可见还没有针对用户偏好进行个性化推荐。
但是目前还无法做到对于生成音乐的精细化控制。期待“未来几年能够利用技术从各个方面对音乐的生成进行控制”。
通过追踪 Discord 社区,我们发现 Suno 用户大致分为:
- 音乐爱好者,他们本不会写歌,Suno 带给他们创作歌曲的能力。这类用户希望通过 AI 辅助创作出有趣的音乐作品,用于个人娱乐或社交媒体分享。他们的需求常常类似于,为自己的猫写一首 Taylor Swift 风格的歌。
- 专业音乐制作人,他们将 Suno 作为创作的灵感来源,或生成音乐素材,结合自己的专业知识进行后期制作。Suno 帮助专业音乐人更高效的输出作品,他们也开始将 Suno 应用在商业场景。
- AI 创作工具探索者,对音乐生成的技术感兴趣,尝试使用 Suno 进行实验性创作。
在与用户的交流过程中,我们发现部分用户对于 Suno 非常沉迷,Discord 社区中也保持了持续的高活跃。根据 Smiliarweb,Suno AI 的 MAU 持续增长,2024 年 2 月 MAU 已经达到约 220 万,Suno 的国家分布并不集中,其中美国、波兰的用户最多,各占约 10%。以男性用户居多,占据了约 68%,在年龄以 18-34 岁的年轻人为主。
具体使用场景较为广泛,并不仅仅局限在专业音乐作曲,可以做如下划分

商业模式上,Suno 采取订阅付费的模式,Suno 目前更像一个创作工具,参考工具类产品的订阅比例,简单假设目前 Suno 约 220 万的 MAU 有 10% 是付费用户,其中 8% 为 Pro Plan、2% 为 Premier Plan,Suno 的月收入大致估算为 250 万美金。创作生态的丰富,Suno 平台也有机会出现广告和内容订阅价值,为 UGC 提供收入渠道;或为音乐创作提供增值服务,比如提供一站式的音乐创作和分发解决方案。
国内公司:DeepMusic灵动音(清华音乐制作人),致力于通过AI词曲编录混技术,全方位降低音乐创作制作门槛并提升效率,为音乐行业提供新的产品体验和解决方案;音乐生成加轻量编辑工作站。
DeepMusic是一家基于人工智能技术的音乐创作服务商,该公司主要运用神经网络学习现存的音乐作品,并从中寻找规律,从而进行音乐创作,其创作的音乐作品可用于短视频配乐等方面。
但商业模式只是停留在Pro C层面。
AI4S
AI for Science(AI4S),是让人工智能利用自身强大的数据归纳和分析能力去学习科学规律和原理,得出模型,生成式的来解决实际的科研问题,辅助科学家在不同的假设条件下进行大量重复的验证和试错,加速科研探索的进程。
主要在生物结构预测;其余在化学、材料上,整体市场规模由于过于细分不会太大,也比较难判断项目,需要对其研发设计的工作流有相当程度的了解。
关注生成式的大模型在工业领域的扩展:例如工艺的生成等,不过基于设计产线等频率低,市场不会太大。颠覆掉原来研发工具例如CAD、Solidwork等,还是会在设计数据、工作流理解上以及设计工具生态上有不小的困难。
(三)生产控制类
MES、SCM
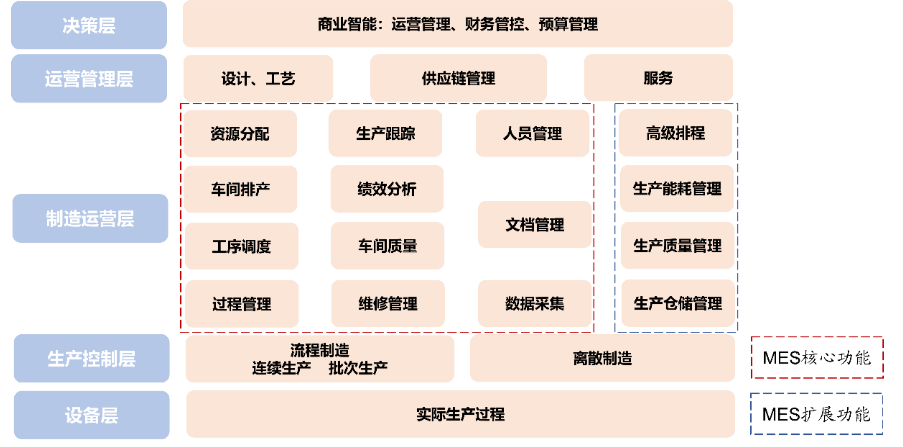
业务对应工业生产控制类服务软件-资产管理:ERPMRP、供应链管理:SRM、生产管理:MESAPS、物流管理:WMS、研发管理:PLM

图:工业生产场景工作流及对应软件
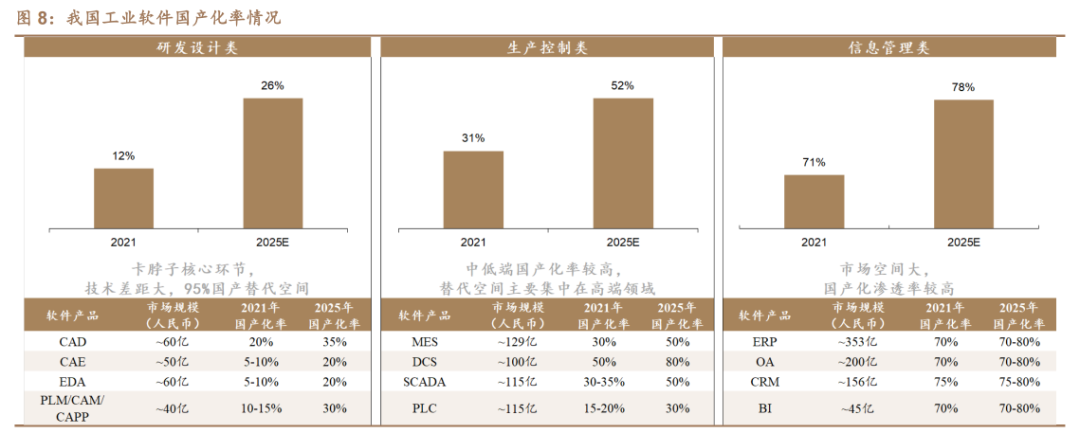
目前我国工业软件整体面临“管理软件强、工程软件弱,低端软件多、高端软件少”问题,研发设计类国产化替代空间较大。
MES:计划下达+生产调度。MES(制造执行系统)是从生产计划下达到生产调度、组织、执行、控制,直至生产出合格产品全过程的信息化管理系统。MES 主要集中在制造运营层,位于生产控制层和运营管理层之间,核心功能包括资源分配、车间排产、工序调度、过程管理等,扩展功能包括能源管理、质量管理、仓储管理等。
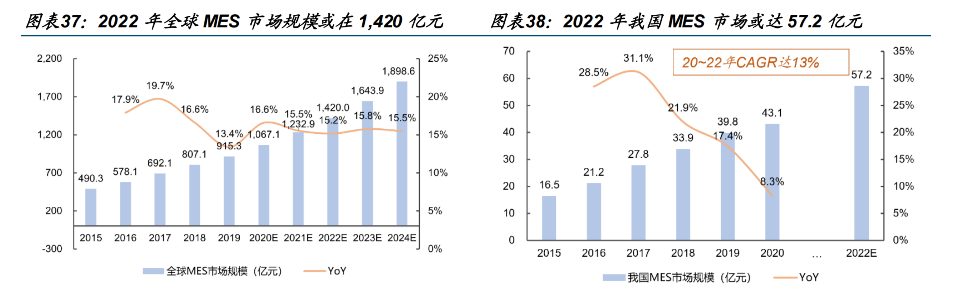
全球 MES 市场规模或在 1,420 亿元。据华经产业研究院,2022 年全球 MES 市场规模或达 1,420 亿元,同比增长 15.2%。2017~2022 年 CAGR 达 15.5%,2024 年市场规模或达1898.6 亿元。我国 MES 市场规模或达 57.2 亿元。据华经情报网,2022 年我国 MES 市场规模或达 57.2亿元,2020~2022 年 CAGR 达 13%。
MES 市场高度分散,参与厂商众多。MES 软件市场中的 SaaS 子市场,以及航空航天船舶、整车及汽车零部件、装备制造等六个细分行业 MES 解决方案市场空间及厂商份额都在市场中占有较大份额。各细分行业呈现出不同的特点,但与 MES 软件总市场相比,细分行业解决方案市场碎片化更加明显,仅有石化化工、钢铁及有色金属等行业保持较高的服务商集中度。
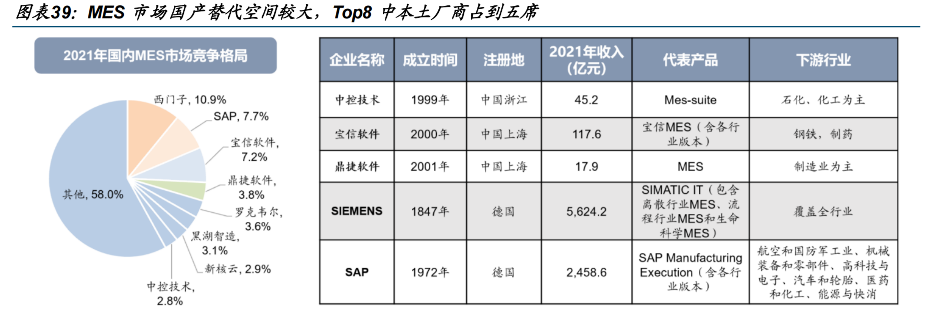
MES 国产替代空间较大,Top8 中本土厂商占到五席。2021 年我国 MES 市占率 Top8 分别为西门子、SAP、宝信软件、鼎捷软件、罗克韦尔、黑湖制造、新核云及中控技术,其中,海外大厂居于前两位,仍处于相对主导地位,本土厂商占到五席,加速国产替代势在必行。与国际大厂相比,我国本土厂商 MES 覆盖行业相对较少,未来或需在多行业多点发力推进自主可控进程。
竞争对手主要为传统MES厂商、涉及工业的大模型公司、初创AI工业软件公司
- 传统厂商为:西门子、SAP、宝信软件、鼎捷软件、罗克韦尔、黑湖制造、新核云及中控技术等
- 涉及工业的大模型公司:百度、华为等
- 初创企业为:剑及智能和Evergine等
持续关注由LLM带来柔性生产的实现(不一定要软件、生产线、机器人都行),由规模经济生产转向范围经济范式(一条产线生产多种物品),由此提供低成本提供多元化定制化的产品,价值潜力大。
To C
日常Agent
对标大厂的Siri、小爱同学等等,通过agent来完成对软硬件的操作。GUI-图像用户交互转向LUI-语言用户交互,下方ai硬件会详细讲述,这里是软件。
硬件、互联网大厂和大模型公司的竞争流量的高地!不再详细讲述。
教育
多轮对话的LLM,必然也天然的适合教育场景。
目前教育市场分为:
1)基于录播课的异步学习公开资源和工具(如 Youtube 视频、google 翻译、慕课等免费录播课)
2)工具类服务,将学习中的某类需求或学习过程抽象为标准化产品,例如Chegg、Duolingo 等
3)真人老师的实时授课,包括线上、线下的大班课和1对1私教。(效果最好,国内知道200-300/小时,但AI是一个月)
AI的领域从错题解释扩展到了对话练习的role扮演:
工作流:特别是在语言学习上,依赖和人对话的训练,听说读写,都可以实现ai对人的替代,实现多场景人群的教育(k-12、海外工作、移民、旅游、兴趣等)。
市场规模:国内需要学习语言的人太多,TAM难以估算–2亿人,以Duolingo、Speak的700一年标准计算,就是1400亿元的大市场
壁垒:课程设计、对话等教育数据、微调技术
龙头:Duolingo和Speak
国外的语言教育的AI应用非常火,为出国旅游和移民群体提供多轮对话场景,但是这种教学方式,对于国内水土不服,国内是应试教育为主。
国内新AI教育场景会更适合学龄前儿童的教育场景(新的交互寓教于乐的方法-具体看ai硬件),短期内小学及以上场景教育国内格局不会变动,用AI也只是,增强体验和溢价。
游戏
目前游戏主流是聊天陪伴类(具有情感的人物切入,完成一定的情绪价值提供任务)
市场:模型质量高且完全虚拟的场景,并不追求准确!但是是为行业切入的入口,寻求正确的解决方案。
国外:Character.ai,Replika、ChAI
国内:LynkSoulAI心影随形,Glow,星野(国内外基本上都是搞擦边起家)
Character.AI
产品:Character.AI 搭建了用户创建 AI 角色并与之聊天的平台及社区。AI 角色有官方创建、社区成员 UGC 两大类。用户自行训练的、深度个性化的 AI 聊天机器人能够与人们建立真正的关系,拥有更大的想象空间和更多的使用场景。
客户:粘性强,所有用户的平均活跃时长为 24 分钟/天,18岁至24岁的用户,他们贡献了约60%的网站流量,9 月的总 DAU 约为 350 万,MAU 约为 1400 万。
通过幻想满足客户的情感诉求,45% 的用户主要和恋爱、浪漫类角色交流,22% 和游戏角色交流,17% 的用户和安慰、心理疗愈类角色交流。
盈利模式:每月收费9.99美元–可以与多个AI互动,玩场景游戏。
技术:底层模型以包含解码器的神经语言模型(Neural language models)为基础,类似 GPT 和 LaMDA,对话效果质量和推理成本好于GPT3。技术不足:记忆和幻觉,但不需要智力水平极高的模型来做情感,角色是否能表达连贯的情感可能也不像人们想象的那么重要。
团队:创始人 Noam Shazeer 是前 Google 首席软件工程师,Transformer 作者之一,并开创了大规模预训练(Large-scale pretraining);联合创始人 Daniel de Freitas 领导了 Meena 和 LaMDA 的开发。(自研能力)
战略方向总结:正与谷歌讨论融资,准备训练其大模型,深度绑定的合作伙伴,承担模型训练成本;防守壁垒大,增长速度快,需要正确选择攻击方向。
优势–1 情感交互,获得极高粘性流量且转换成本大,从而可以切入相关领域;2 全栈能力壁垒-且低训练和推理成本;3 高质量数据-模型的飞轮效应。
未来突破点:
1 需要考虑聊天机器人无需用户点击将挑战优质内容-点击-广告 内容平台商业模式飞轮,如何加入广告!
2 技术上导致的使用体验有限:有限的上下文容量,幻觉,在逻辑、规划、使用仍然有不准确性。最主要的是与人类的记忆不对齐,聊天容易丢失上下文,没有对的记忆,如何培养感情?
3 站住虚拟聊天市场,提供更沉浸式虚拟体验-UI、图片、语音等,把握互联网。
成本:自研模型(模型更加精致),每个 Query 的成本是 ChatGPT 的 1/3,训练仅花费60万美元。同时通过积累用户数据形成飞轮,能够不断提升用户的个性化体验。
整体竞争非常激烈,国内外要有20多家公司在做,如何针对需求,提高粘性是主要的指标。
虚拟聊天机器人代表公司包括 Replika、ChAI;国内类似创业企业有 Glow、聆心智能、彩云小梦;垂直领域也存在业务交叉,如心理疗愈机器人 Woebot;游戏领域的 NPC 在线交互平台 AI Dungeon,AI 角色驱动的元宇宙平台 Inworld.AI。
以及最近在测试阶段的自然选择AI-针对恋爱场景设计的“超级对齐”。
Character.AI在对话质量上完胜一筹,推理成本也更低,其他公司均采用微调的大模型。
模型本身技术壁垒跨越还需要时间。
检索类
使用大模型进行网页搜索。国外:Pelexity、大模型和大厂等
短期收现金可以,这个地方是搜索引擎和大模型公司会做的事情。重塑搜索引擎的工作流,关键是通过更好的生成来提升用户的搜索体验,并引入广告等创新商业模式。
九、应用层——硬件AI应用硬件
综述
ChatGPT 推出以后,AI 硬件就成为了热门赛道【62】。
AI Pin、Rabbit R1、以及 Meta 的雷朋眼镜,还有豆包推出的智能耳机,有成功的,也有不少失败的。
在大模型热潮持续一年之后,或许可以看一下,AI 硬件未来的机会到底在哪里。
硬件虽是中国的主场,但仍然软件才是核心。
回顾移动互联网时代,4G/5G的成熟在底层技术架构上为短视频等高信息密度应用的新形态打下了基础,而iPhone开创的触控交互体验真正为应用的繁荣打开了大门。
苹果也因为在交互模式上的创新获得了移动互联网时代最大的红利,时至今日依然可以向软件生态征收“苹果税”。强如Meta,几乎盘踞了海外C端流量和广告收入,也因为缺乏硬件设备而如鲠在喉。Zuckerberg近年来在Reality Labs上的激进投入,狂烧500亿美金就是为了占据下一个时代的硬件入口/计算中心。

在当前格局下, Google ,Meta,苹果和字节跳动等移动互联网巨头从硬件到软件牢牢把持了用户生态,并基于计算中心/物理空间、流量/网络效应、时间/用户习惯这几个核心要素形成了深厚的壁垒。如果这个局面不被打破,AI大模型技术将停留在更先进的生产工具(”enabler”)定位,从结果上丰富了移动互联网生态的内容供给和用户体验,“为他人做嫁衣”。科技巨头依然是最大受益者,过去5年强者恒强的局面将会延续。
因此针对AI大模型重新设计的硬件和交互将是GenAI时代挑战者必须攻克的堡垒。这也是为什么Sam Altman很早就联系传奇设计师Jony Ive开始在硬件方向进行探索。
软件带来的变量主要体现在以下两个方面
AI硬件的三层架构
在原生多模态AI大模型出现后,结合硬件会出现新的信息交互和处理模式,大体上可以分为三个层次:
- 多模态信号输入 -> 传感器
- 模型处理和计算 -> 计算中心
- 交互方式 -> UIUX设计
在这三层架构中,计算中心(如手机)将为AI大模型提供端侧和云端运行能力,而AI大模型技术的能力进步驱动整个闭环用户体验的提升,具体表现为让硬件在原有功能的基础上拓展能力边界,在第三层输出更好的效果。反过来中间层需要硬件作为传感器获得更多context来更好地输出模型运算结果。
LUI是否能成为下一代交互方式
「The UI of AGI」是AI硬件从业者需要思考的圣杯问题。
“套壳”其实就是一种最直接的尝试,Arc浏览器,Perplexity,Monica.im都在各个方向积极探索。但LUI(Language User Interface)或者基于语音的交互方式(Voice-first UI)是否能取代触控时代主流的GUI(Graphical User Interface)是在行业内被讨论最多的问题。
我认为GPT4o为代表的低延迟、多情感、高智能原生多模态模型虽然为LUI的落地提供了技术支持,并在某些特定场景有较好的体验,但现在看起来LUI并不能独立成为最主流的交互方式。我认为思考这个问题的关键因素是I/O密度。I即input,指在人机交互中用户向系统输入信息。O即output,指系统向用户反馈信息。
在I端,LUI能很好地解决当下信息输入门槛过高的问题,阵列麦克风技术的发展配合AI大模型的多语言识别和总结能力,让用户在I端更加轻松自如(flowvoice.ai等公司已经有产品落地)。
但在O端,LUI的信息密度有很大的局限,特别是与GUI相比。Vela在「Voice-first,闭关做一款语音产品的思考」中做了详细的解析。
声音在交互上的局限性主要表现在:
1. 输出线性
很难实现多线程多任务操作
用户很难通过前进倒退精准定位碎片化信息点
2. 记不住
LUI是线性的而思维是树/图结构,语音无法单独呈现人脑所需要的信息组织形式
结果需要简单明确,最好用最小来回对话解决

在音频自身限制和AI大模型现阶段长程推理能力缺失的情况下,LUI目前只适合做目标明确的单点任务,且输出结果信息密度不宜过高。从数据上看,天猫精灵使用最多的场景是询问天气和设定闹钟。
因此,LUI配合GUI结合使用我认为是能将I/O密度最大化的交互体验。
与大厂的竞争
手机短期内依然是生态位核心。
手机在AI硬件三层架构可以在一定程度上覆盖所有三个维度,并占据计算中心的核心价值位。现阶段对其他硬件设备的主要机会在于成为手机的传感器,收集手机目前尚不能覆盖的细分场景信息 – 主要是息屏、用户双手被占用无法拿起手机、无法快速开启手机内置传感器(为描述方便,下文统称“手机空白场景”)- 并尝试探索新的交互体验。
对AI硬件团队来说,市场足够大的品类依次是耳机、智能手表、眼镜和配饰类设备。
整个智能穿戴设备生态都脱离不了一个主题:Survival is the name of the game
手机厂商因为占住了核心生态位,穿戴设备的新机会都在其射程之内,我们讨论的所有穿戴设备品类都逃脱不了激烈的竞争。对新玩家来说有两种现实的选择:
1) 在市场足够大的赛道,争取成为小米华为苹果身后的第三/四名;
2)在大厂看不上,小公司搞不定的赛道做差异化竞争。
第一种路线考验的是团队的执行力,需要面对的竞争包括:
1 硬件玩家
第一梯队:华为,小米,苹果;优势无需赘述,且已经有手机、耳机、眼镜等成熟产品线,用户基数大
第二梯队:Oppo/Vivo,大疆,安克等;有成熟的供应链资源和分销渠道,成熟业务可以产生稳定现金流
第三梯队:科大讯飞、韶音、雷鸟、Rokid等;在垂类中有领先市场份额
2 互联网公司:字节跳动、阿里、腾讯等;拥有大量承接UIUX的场景
竞争确实激烈,但也并不是全无机会。AI硬件时代的一个重要变量是对团队的复合型要求:即软硬件结合的能力。正如文初提到的,这一轮AI硬件本质上是软件驱动的,与硬件龙头竞争,新团队需要具备更强的软件能力,努力将产品向AI硬件三层架构的后两层做价值延伸。而互联网公司,强如字节跳动和meta都将一起竞争。无论怎样,资本价值都比较大。
当然,也可以选择第二条路线。这就要求团队对消费者需求有深度的洞察和提前的预判。一个可以参考的思路是将软件功能硬件化。核心是找到一个软件端有需求的场景,并通过极简的设计,将多步操作压缩到一步。Plaud就是看到Live Transcribe这个app巨大的用户基础,将录音这个本来可以在app端完成的场景硬件化。将原本需要掏出手机,解锁,找到app,打开app,开启录音的一系列操作融合到简单的一键到位。
目前主流的AI硬件有:智能眼镜、智能陪伴和录音
智能眼镜
Rayban Meta

近期Rayban Meta意外大卖,增强了Zuckerberg对智能眼镜这个形态的信心。小扎对此如此笃定不无道理,因为眼镜作为传感器定位的智能穿戴设备确实有得天独厚的优势。

一个具有对话功能,识别物体,录像的眼镜。通过“hey,meta唤醒”。
信息密度最大:眼睛是人类的窗户,因为视觉是人类获取信息密度最大的渠道;同理眼镜同样可以便捷地获取视觉和音频信息;目前手机做不到。
第一视角POV:“see what you see” + “hear what your hear”,POV视角不但可以提供了模型最需要的用户视角的context;解放双手的设定也适配手机空白场景。
在现有形态上创新空间相对最大:相比耳机和智能手表(叠加AI功能对本身形态改变不大),带摄像头的智能眼镜相对是新的形态,为新玩家提供空间。
此外,摄像眼镜在传播上也有天生的优势,从目前用户的行为来看,摄影摄像是主要的使用场景。Rayban Meta在内容创作者和大V中非常受欢迎,他们创作的POV视角的内容在社交媒体传播容易形成潮流效应,从而形成自传播,摄像头。
在Rayban Meta取得成功后,海外大厂已经形成共识:Google决定与硬件合作伙伴三星探索类似形态,落地在Google I/O上惊鸿一瞥的Project Astra,苹果也开始重新审视自己的Vision产品线。
智能眼镜形态的主要划分和优劣势
智能眼镜根据功能组合和视场角(“FOV”)大致可以分为以下几类:
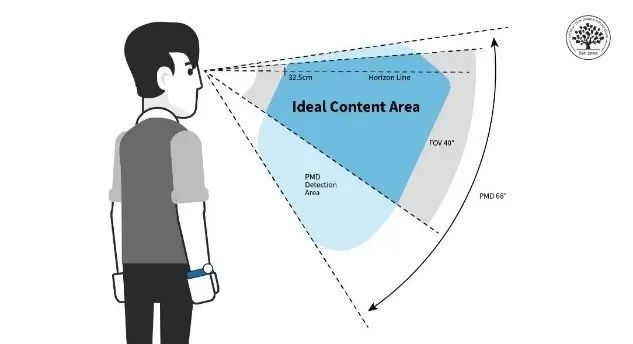
1. 不带显示的智能眼镜(已经能将重量控制在50g以内,符合轻量化要求)
音频眼镜:因为前文分析LUI的局限性,在用户端提供的功能非常有限
摄像+音频眼镜:Rayban Meta取得阶段性成功,价位$300
2. 带显示的智能眼镜(能控制在100g以内,但在轻量化上还有提升空间)
40-50度FOV(雷鸟X2):轻显示,价位$500-1,000
50-70度FOV(Orion):现实增强,有原型机,无法量产
100度FOV:接近VR视觉体验,但采用OST方案;在目前技术边界之外
不带显示的智能眼镜在轻量化和成本控制上已经相对成熟。但目前只覆盖AI硬件三层架构的第一层,并通过LUI提供有限的交互。纯音频眼镜收集信号密度有限,同时受制于系统权限,产品功能单薄,且与TWS耳机重合度高。另外电子消费品追求标准化的模式,并不能满足消费者对眼镜个性化多SKU的需求。从华为和小米的实际销量上看,只搭载音频带来的功能增强并没有提供足够强的说服力。
而带有摄像头的智能眼镜,在保留音频功能的同时,通过与手机配合使用,能解锁更多延伸场景,提供较好的基础体验。
在带显示方案的眼镜产品中,现有的成熟量产方案只能提供40-50度FOV的轻显示,定位鸡肋。一方面需要搭载光机带来额外的重量和成本,另一方面视场角有限,实际上只起到了通知中心(push center)和widget看板的功能。运用新一代技术的Even Realities G1等产品,虽然在轻量化上更进一步,但这类产品的落地场景目前集中于:实时翻译、导航、提词器等场景。这些场景中确实有不错的体验,但可以试想一下普通人使用上述三个场景的频次。
AI功能目前也仅限基于识图的任务延伸(类似Apple 16展示的功能)。除此之外,不少人幻想的使用场景,在OST方案中都在目前的技术边界之外。Orion也只能勉强提供几个鸡肋的场景。在某种程度上智能眼镜除摄影摄像和音频之外的功能都可以被智能手表覆盖。
选择比努力重要。对试错成本更高的硬件创业公司来说更是如此,虽然上海显耀等Micro LED公司近年取得一些技术突破,但显示方案受制于FOV,即使落地也无法独立支撑太多的应用场景,现在看来并不是最优的技术路线。
而Rayban Meta则为智能眼镜指明了方向,短期内取代不了手机,但眼镜保有量大,若出现类似汽车电动化的眼镜智能化趋势,市场体量也相当可观。但目前的主要缺陷是因为轻量化无法搭载高容量电池的情况下,如何控制芯片功耗从而实现更长续航。
期待更多爆款的功能,提高Pro C的粘性。
智能陪伴
AI 玩具
玩具是搭载LUI的理想硬件载体。一方面,小朋友需要的信息密度和精度要求相对不高,且语音的流式交互也可以被硬件一部分承载。另一方面,相比于纯软件的形态,通过硬件具象化也更方便用户代入情感寄托,提供更高的情绪价值。这个品类也符合“熟悉的陌生感”逻辑,用户教育门槛低,基本上手即可使用。
需要注意的是AI教育的使用者和购买决策者分离,团队需要在软件后台针对家长的诉求(主要是安全控制和成长记录)有相对应的设计。
2024年OpenAI引入了Coursera前高管并重点发展AI教育,国内的学而思、小猿学练都陆续推出了AI在教育领域的产品,主要是面向课内应试教育场景。不同于AI玩具,学伴切入的是更广义、更刚需的教育成长,关键还是得对孩子成长和教育文化有深度理解的,做出和孩子成长高粘性的产品。
该行业出色的公司众多,我们以灵宇宙为例:
凭借卓越的软件和算法平台能力,以及对大模型计算的深刻理解,灵宇宙打造了一系列AI-Agent 终端产品,通过学伴进入家庭,未来在深刻理解家庭场景和空间数据的基础上,将拓展至4D空间交互的OS层领域,首款产品即将在2025年CES大会产品面向全球发布。
创始人顾嘉唯,前百度人工智能研究院IDL人机交互负责人、百度少帅、微软研究院HCI科学家,MIT TR35(2016年唯一入选企业家),曾是物灵科技的创始人兼CEO (儿童绘本阅读机器人Luka卢卡全球销量近千万台)。联合创始人徐持衡是商汤科技 001号联合创始人兼 CTO。
产品经验丰富:团队深耕硬件赛道超十年,历史上经手数十款AI硬件产品,包括曾登上时代杂志封面的家用机器人 Jibo、百度小度机器人、百度无人车、随身硬件百度BaiduEye、度秘等,无论在大厂还是创业阶段产品力都已验证,产品定义经验丰富。核心团队均为从0到1厮杀的胜利者,做过的互联网及AI产品累计覆盖9亿用户。团队对儿童教育场景的深度理解,凭借产品数百万量级销量的成功经验,在产品逻辑上具有巨大的优势。
技术实力雄厚:来自微软、谷歌、百度、商汤以及国际知名学者的核心技术团队,持续在交互智能智能领域深耕,将通过自有产品的数据闭环,做4D空间智能OS。获得来自商汤等八家战略或市场化机构的投资、以及国家级的上海浦江实验室和鹏城实验室的算力及底层基础模型技术支持,在软硬件技术方面均突出。

录音
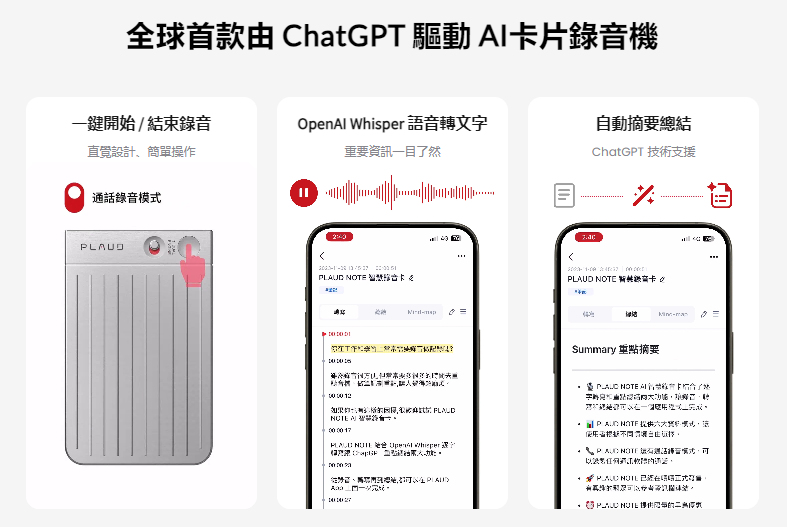

PLAUD NOTE是一款由GPT驱动的AI智能录音设备,提供录音、语音转文字和内容总结的一站式解决方案,凭借其精准的PMF和技术优势,不到1年时间已在全球范围内积累了几十万的用户数量,在全球所有AI硬件中名列前茅,为中国出海AI硬件第一。未来,录音这个场景,科大讯飞也会去做。
先看看Plaud长啥样:
卡片式,差不多身份证大小,挺薄(0.29cm),可以磁吸在手机机身背后。
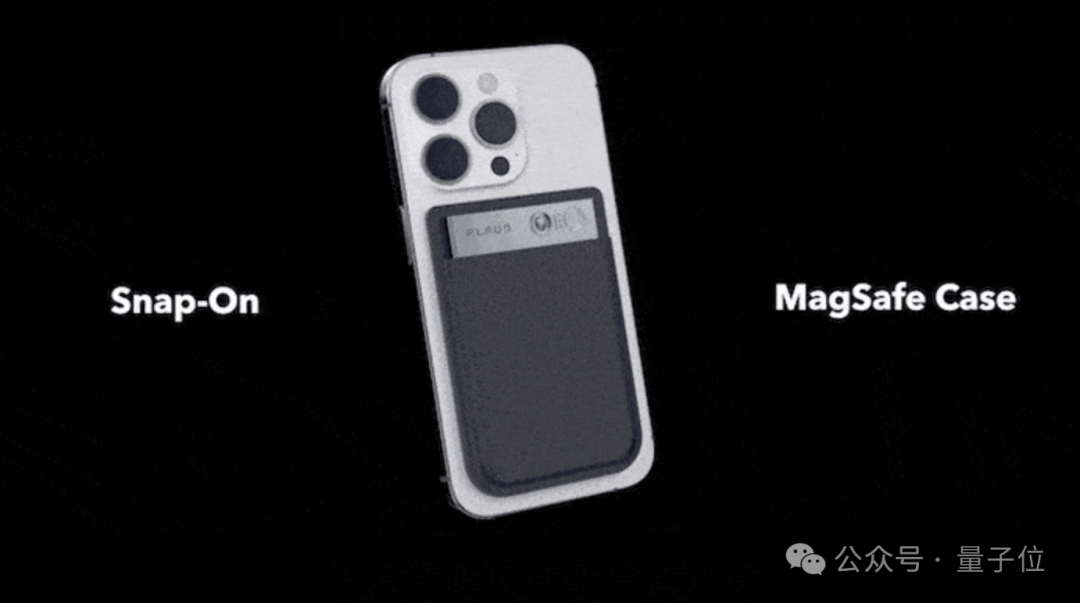
吸在手机上后,最重要的功能就是录音。
官方资料显示,Plaud电池容量为400mAh,满电Plaud可以连续录音30个小时,可录制和存储约480个小时的音频资料。
Plaud身上有3个麦克风,其中1个是震动传导传感器(VCS),另外2个则是用来采集外部环境音的空气传导传感器。
震动传导传感器支持Plaud的通话录音模式,利用固体传导振动,进行录音。
根本不需要系统内安装新App,或者获取授权。
非常外挂式地解决了“iPhone手机通话不能录音”的情况。但是现在可以了,但会通知对方,现在正在录音;但是微信等还是不可以。是一个非常好的统一录音硬件。
加上AI的转录和云端,直接成了爆品。但未来会面临大厂例如科大讯飞的竞争。
具身智能
核心:只有软件的性能完善,才会带来本体的放量和标准,才会带来上游电机、材料等标准。
本体
对于硬件厂商的投资逻辑主要为:
1 基本的收入支撑:之前有四足等相关机器人的业务量
2 人形机器人的成本控制:自研电机、结构设计等等
3 人形机器人可实现的运动效果:折叠、翻滚、走路等
4 软件:开发者友好的开发生态;成熟的电机以及运控集成算法
该行业出色的公司众多,以云深处为例:
2024年11月,云深处推出的“山猫”四足机器人,收获了国内外不少关注和认可,不仅在B站、视频号、Youtube等平台全网刷爆、新华每日电讯官方账号数万人点赞评论、Figure AI创始人也在X平台转发并点赞了这条视频。
在惊艳的产品能力背后,我们了解到云深处有着深厚的软硬件技术储备:
硬件方面:在四足领域目前已推出绝影X30、Lite3等平台、在轮足领域已推出“山猫”机器人平台、在人形机器人领域今年下半年已推出DR01平台、在零部件方面已推出J系列一体化关节产品,构筑了丰富、高性能的产品矩阵。
软件方面:云深处创始团队在人形机器人运动控制、强化学习RL等技术上是国内最早一批研究者,2019年起便与国外学者合作开展RL相关研究,2020年研究成果已登上机器人顶刊《Science Robotics》的封面,长期的研发积累是云深处能够在四足、人形领域不断突破产品力极限的关键。

大脑
目前物理大模型的属性主要分为:
LLM/VLM模型驱动和扩散模型为主要驱动的模型,两者可以统一

原生 VS 组装式开源微调

分层化端到端 VS 整体端到端
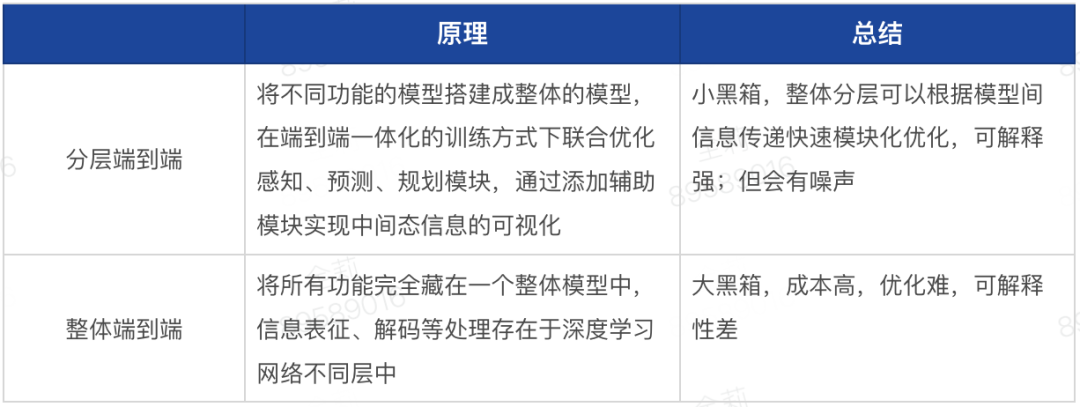
除此之外,学习范式、数据和训练环境也是次要需考虑的方向重点。
(3)学习范式
模仿学习+强化学习 VS 监督/无监督学习+强化学习
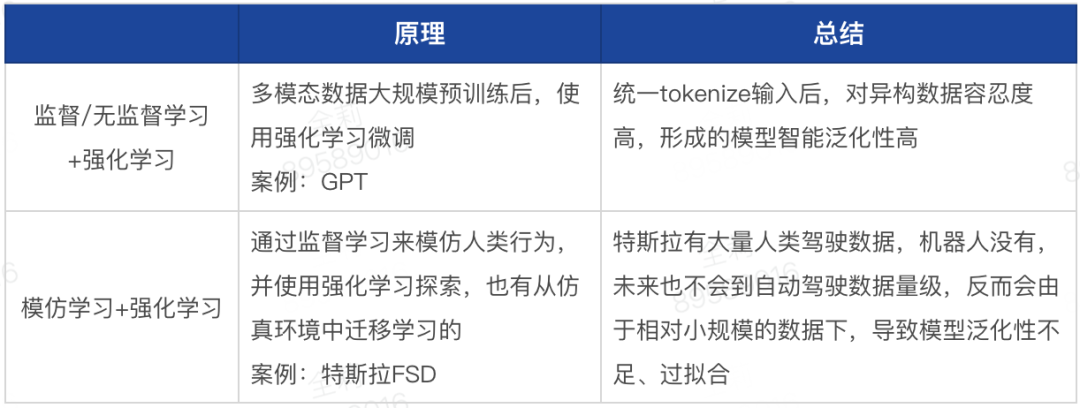
(4)数据
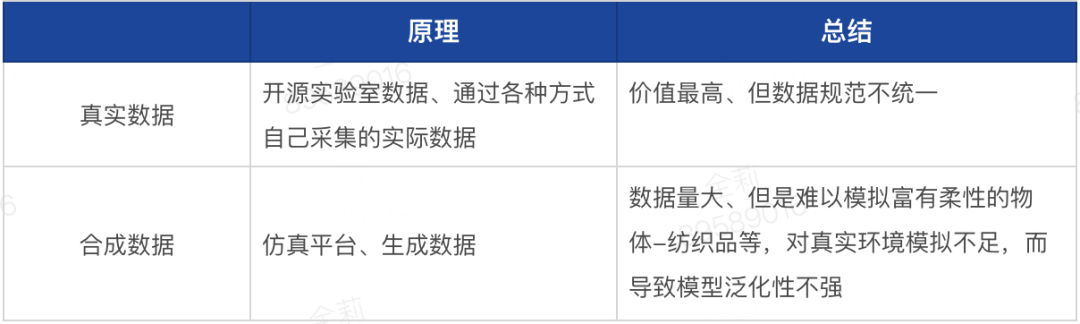
就像在之前具身部分解释的一样,快速收敛模型和算法是主要目前的竞争,如何Scale out可以在各个模型选择上看出一二,无论怎样就像GPT一样,在大规模算力和数据输入前,模型需要几个基本特质:
相信同时具有大模型训练和商业化能力的团队。
1 原生模型,自研设计并训练,相比于调用别人LLM或者VLM模型微调,可以底层优化算法,进行改动。
2 最大化容纳数据的种类,来弥补机器人数据的不足。
3 极度精简的模型结构,减少数据压缩的损失。
4 低成本的学习范式:无监督学习最优,模仿和强化都需要大量数据和仿真(小脑路径不在此范围)。
最近优秀的大脑公司众多,这里我们以智澄AI为例:
颠覆式AI原生机器人技术:完全自研大小脑融合模型,区别于任何一家大脑公司的架构;空间感知,物理世界理解推理和执行all in端到端具身智能大模型的神经网络:鲁棒性高,泛化性强,GPT时刻前夕-展现出的强大的可Scale out和Zero-shot能力。
领先的智能工程化能力:区别于前沿实验室的组装式开源大模型,智澄AI在前沿技术融合应用、异构数据搭建、空间感知、简洁模型架构、安全可靠性等方面拥有多项独到模块创新,能够更低成本、更高效率实现Best Practice学习范式的收敛。
硬软件快速迭代能力:2024年6-8月相继完成产品原型TR1、TR2,人形本体将在2025年初下线,已有数家场景客户合作方,伴随技术研发产品逐步落地。
多位国际AI大厂资深科学家及高管领衔:平均拥有20年AI经验积累,CEO曾任Meta首席工程负责人,在Meta对于感知世界和物理世界模型有最新的认识;联创包括Meta首席AI研究科学家和微软大中华区CTO,Meta、亚马逊、蚂蚁、华为资深AI专家及海外顶级高校机器人、AI大模型背景人才梯队。
产业、政府、高校顶级合作与资源:已获得杭州市政府、产业方在资金、算力方面大力支持,合作伙伴包括华为、菜鸟、欧琳、清华、浙大、北大、哈佛、斯坦福等顶级高校。
参考资料
再次感谢各位的知识分享,在此之上我们做了更进一步的研究,并将之“开源”!
【1】来源:知乎,作者:瞻云,回答问题:大脑为什么自己不明白自己的工作机理呢?链接:https://www.zhihu.com/question/490949334/answer/2161395464
【2】来源:知乎,作者:bird,文章:人脑工作机制分析和猜想(01):关于人脑——脑的演变过程及当前的系统架构,链接:https://zhuanlan.zhihu.com/p/414408970
【3】来源:知乎,作者:花卷神经科学,回答问题:脑科学进展为何如此缓慢?链接:https://www.zhihu.com/question/34936606/answer/3300145691
【4】来源:知乎,作者:bird,回答问题:脑科学进展为何如此缓慢?链接:https://www.zhihu.com/question/34936606/answer/3300145691
【5】来源:知乎,作者:神经美学 茂森,回答问题:大脑神经元的的建立过程是怎样的?链接:https://www.zhihu.com/question/268720152/answer/3546965051
【6】来源:知乎,作者:一起读PCB,回答问题:神经元的工作原理是怎样的?链接:https://www.zhihu.com/question/408206230/answer/3426676360
【7】来源:知乎,作者:Liang Shi,回答问题:神经细胞有哪些细胞种类&各种类的功能分别有哪些?链接:https://www.zhihu.com/question/457254607/answer/1921579805
【8】来源:知乎,作者:Liang Shi,回答问题:抑制神经元和兴奋神经元是怎么区别的,或者说抑制神经元产生抑制递质,兴奋神经元产生兴奋递质?链接:https://www.zhihu.com/question/392758414/answer/1202650268
【9】来源:知乎,作者:赛壳学习笔记,文章:神经元的工作原理——电信号和化学信号的紧密合作,链接:https://zhuanlan.zhihu.com/p/361601594
【10】来源:知乎,作者:东单情感,回答问题:神经元的工作原理是怎样的?链接:https://www.zhihu.com/question/408206230/answer/1614246705
【11】“Architectures of neuronal circuits”,Liqun Luo,Science,3 Sep 2021, Vol 373, Issue 6559,DOI: 10.1126/science.abg7285
【12】来源:知乎,作者:林文丰 Jason,文章:认知神经科学 第三版,链接:https://zhuanlan.zhihu.com/p/709723778
【13】来源:知乎,作者:呸PER无一郎,回答问题:人的大脑是如何识别某一物体并检测到运动的?链接:https://www.zhihu.com/question/26430414/answer/3115980831
【14】来源:知乎,作者:赵思家,回答问题:注意力的认知神经机制是什么?链接:https://www.zhihu.com/question/33183603/answer/71783580
【15】来源:知乎,作者:OwlLite,回答问题:人类是通过语言介质进行思考的吗?链接:https://www.zhihu.com/question/483263643/answer/2163239073
【16】来源:科技日报,文章:识别情绪的大脑回路发现,链接:https://www.hfnl.ustc.edu.cn/detail?id=22115
【17】来源:知乎,作者:林文丰 Jason,文章:《智能简史:进化、人工智能和造就我们大脑的五大突破》,链接:https://zhuanlan.zhihu.com/p/714025058
【18】来源:知乎,作者:蔡叫兽,回答问题:如何看待饶毅的「人工智能还是伪智能」命题?链接:https://www.zhihu.com/question/27716888/answer/37866993
【19】来源:知乎,作者:周鹏程,文章:一场twitter争论:人工智能是否需要神经科学,链接:https://zhuanlan.zhihu.com/p/576570463
【20】来源:知乎,作者:泳鱼,文章:一文概览人工智能(AI)发展历程,链接:https://zhuanlan.zhihu.com/p/375549477
【21】来源:知乎,作者:ZOMI酱,文章:【AI系统】AI 发展驱动力,链接:https://zhuanlan.zhihu.com/p/914397847
【22】来源:知乎,作者:机器之心,文章:一文简述深度学习优化方法——梯度下降,链接:https://zhuanlan.zhihu.com/p/39842768
【23】来源:知乎,作者:我勒个矗,文章:模仿学习(Imitation Learning)介绍,链接:https://zhuanlan.zhihu.com/p/25688750
【24】来源:知乎,作者:泳鱼,文章:通俗讲解强化学习!,链接:https://zhuanlan.zhihu.com/p/459993357
【25】来源:知乎,作者:IT胖熊猫,文章:AI知识体系概述,链接:https://zhuanlan.zhihu.com/p/706229733
【26】来源:知乎,作者:DoubleV,文章:详解深度学习中的梯度消失、爆炸原因及其解决方法,链接:https://zhuanlan.zhihu.com/p/33006526
【27】来源:知乎,作者:普适极客,回答问题:怎么形象理解embedding这个概念?链接:https://www.zhihu.com/question/38002635/answer/1364549217
【28】来源:知乎,作者:猛猿,回答问题:如何理解 Transformer 论文中的 positional encoding,和三角函数有什么关系?链接:https://www.zhihu.com/question/347678607/answer/2301693596
【29】来源:知乎,作者:北方的郎,回答问题:对人工智能毫无了解,导师让看transformer和BERT的两篇论文。好几天了,基本没看懂,何解?链接:https://www.zhihu.com/question/568969384/answer/3390204563
【30】来源:知乎,作者:猛猿,回答问题:如何理解attention中的Q,K,V?链接:https://www.zhihu.com/question/298810062/answer/2320779536
【31】来源:知乎,作者:书中有李,文章:GPT 理解:关于 transform attention 中的 QKV,链接:https://zhuanlan.zhihu.com/p/636889198
【32】来源:知乎,作者:猛猿,文章:Transformer学习笔记二:Self-Attention(自注意力机制),链接:https://zhuanlan.zhihu.com/p/455399791
【33】来源:知乎,作者:佳人李大花,回答问题:为什么现在的LLM都是Decoder only的架构?链接:https://www.zhihu.com/question/588325646/answer/3383505083
【34】“Scaling Laws for Neural Language Models”,Jared Kaplan,arXiv,23 Jan 2020,cited as arXiv:2001.08361
【35】来源:知乎,作者:玖歌,文章:LLM Scaling Laws,链接:https://zhuanlan.zhihu.com/p/694664603
【36】来源:知乎,作者:程序猿阿三,回答问题:能大致讲一下ChatGPT的原理吗?链接:https://www.zhihu.com/question/598243591/answer/3446096328
【37】来源:知乎,作者:程序锅,文章:OpenAI首次揭秘GPT训练细节,链接:https://zhuanlan.zhihu.com/p/633202668
【38】来源:知乎,作者:猛猿,回答问题:谁能讲解下扩散模型中Unet的注意力机制?链接:https://www.zhihu.com/question/597701864/answer/3080511687
【39】白辰甲,许华哲,李学龙;《大模型驱动的具身智能: 发展与挑战》;中国科学 : 信息科学 2024 年 第 54 卷 第 9 期: 2035–2082
【40】来源:知乎,作者:lijun,文章:MPC(模型预测控制) 原理及理论推导,链接:https://zhuanlan.zhihu.com/p/698526965
【41】来源:知乎,作者:王建明,文章:对话罗剑岚:强化学习+真机操作可以很Work,链接:https://zhuanlan.zhihu.com/p/6329634561
【42】来源:知乎,作者:高乐,文章:基于扩散基础模型RDT(Robotics Diffusion Transformer)的人形机器人双臂操作,链接:https://zhuanlan.zhihu.com/p/2020035331
【43】来源:知乎,作者:善与净,文章:大模型评测的几个榜单,链接:https://zhuanlan.zhihu.com/p/713849119
【44】来源:知乎,作者:爱生活Ai工作,文章:全球AI大比拼!GPT-4o稳居第一,阿里Qwen2为何跌至第八?,链接:https://zhuanlan.zhihu.com/p/703544557
【45】来源:海外独角兽公众号,作者:Cage,文章:LLM的范式转移:RL带来新的 Scaling Law,链接:https://mp.weixin.qq.com/s/JPfgF6UtgIYwWXwNQHOoqQ
【46】来源:知乎,作者:白老师AI学堂,文章:预测即压缩, 压缩即智能?——从信息论视角看大语言模型的本质与未来,链接:https://zhuanlan.zhihu.com/p/702188556
【47】来源:知乎,作者:DeepTech深科技,文章:争鸣:OpenAI奥特曼、Hinton、杨立昆的AI观点到底有何不同?,链接:https://zhuanlan.zhihu.com/p/636522807
【48】来源:知乎,作者:安晓心,回答问题:如何评价Yann LeCun的 世界模型?链接:https://www.zhihu.com/question/632009707/answer/3422307013
【49】智算未来系列十:智算中心加码,国产算力提速;中金点睛,链接:https://mp.weixin.qq.com/s/sfRIUaMY0iua0ediPzUppQ
【50】AI浪潮之巅系列:云端算力芯片,科技石油;中金点睛,链接:https://mp.weixin.qq.com/s/RHgYjrhvqRoqVqLoUPvVzg
【51】ChatGPT启新章,AIGC引领云硬件新时代;中金点睛,链接:https://mp.weixin.qq.com/s/V0Jch3MS-ch4azwMwIXDLQ
【52】AI浪潮之巅系列:服务器,算力发动机;中金点睛,链接:https://mp.weixin.qq.com/s/W2AwPTsOfvsGOeLhCYo7Nw
【53】智算未来系列七:国产云端AI芯片破局,路在何方?;中金点睛,链接:https://mp.weixin.qq.com/s/ptGlPPdIzfGzw4X7SVqRiw
【54】来源:知乎,作者:Na Liu,文章:科技演变的规律和投资方法论小感,链接:https://zhuanlan.zhihu.com/p/445923243
【55】来源:海外独角兽公众号,作者:Cage,文章:Anyscale:Databricks 创始人再下场,ML 领域最值得期待的公司?,链接:https://mp.weixin.qq.com/s/lKaEJsRkKnRkdDE9C2uOiQ
【56】来源:海外独角兽公众号,作者:Cage,文章:拾象AI投资图谱:大浪已至,展望Infra百亿美金公司机遇,链接:https://mp.weixin.qq.com/s/uBIpXFloAoda5lrquzyvDg
【57】来源:海外独角兽公众号,作者:haina,文章:Sales Agent 接管企业销售,11x.ai 是企业数字员工的雏形吗?,链接:https://mp.weixin.qq.com/s/IuJlFuZMNBaKQne6Kn2r5Q
【58】来源:海外独角兽公众号,作者:kefei,文章:Kore.ai:LLM能否为AI客服带来新一轮洗牌与机遇,链接:https://mp.weixin.qq.com/s/IsS-xeh63ul82yw14EZOSA
【59】来源:海外独角兽公众号,作者:kefei,文章:Glean:大模型时代的企业内入口级产品,最了解员工的“AI同事”,链接:https://mp.weixin.qq.com/s/ibqKqUJJ1uZ0rAHx34yqGQ
【60】来源:海外独角兽公众号,作者:程天一,文章:AI重塑法律行业:为80%的工作带来10x提升,链接:https://mp.weixin.qq.com/s/fmMuAcrSH9UH7svml4LlUg
【61】来源:海外独角兽公众号,作者:程天一,文章:Suno AI:音乐生成迎来MidJourney时刻,Suno能否挑战Spotify?,链接:https://mp.weixin.qq.com/s/fmMuAcrSH9UH7svml4LlUg
【62】来源: 鹿其鹿粦Chilling公众号,作者:Aaron Qian,文章:EP.3 | 一年之后:AI大模型航海我们身在何处 将驶向何方 (II) – 硬件篇,链接:https://mp.weixin.qq.com/s/9ra-9iQ_HjAfsethunVOrA