距离ChatGPT的诞生过去了近两年,期待中的AIGC时代不仅没能爆发,似乎还有了降温的趋势。
近期AI圈被热议的事件之一便是,有AI初创公司传出“不再大力度投入大模型,转做赚钱的AI应用产品”的消息。
目前大家对AI的探索大概分为三大类:一是做通用类基础大模型,二是做行业大模型,三是基于前两类大模型开发原生AI应用。前两类属于基础设施,后一类为大家看得见、摸得着的产品。例如,百度的AI产品文小言(原文心一言),是基于文心大模型提供AI能力;字节的豆包,是基于豆包大模型提供服务。
大厂基本都做了通用类大模型,并基于此开发AI原生应用,同时还将大模型开放,为客户提供API接口和服务。这就像是开了一座商场(平台),把场地、水电、设备等基础设施建设好,让商家(开发者、企业)进来开店,对商家提供服务并收费,同时,自己也开店赚钱。
今年,关于国内外大模型卷不动了的声音越来越大,甚至有国外公司被曝出正大幅缩减员工。在这样的背景下,技术储备充足、财力雄厚的大厂,在AI上的动作一定程度上代表着风向标。
我们综合AI圈资深从业者的真实感受和各大AI榜单上靠前的产品,选择了五家国内大厂,分别是百度、字节、阿里、腾讯、快手,试图通过它们近两年在AI上的布局,回答以下问题:五家大厂推出了哪些代表性AI产品?它们各自的AI的策略是什么?未来,爆款AI应用产品是否能出现?
一、大厂卷AI,哪些产品跑出来了?
去年,大模型还是一片热土,凡是有实力的公司都不愿错过,百度、字节、阿里、腾讯都发布了基础大模型,分别是文心通用大模型、豆包大模型、通义通用大模型、混元大语言模型,快手则推出了视频类的可灵视频生成大模型。此外,百度、字节、阿里还布局了垂类的行业大模型,基本都和自身业务紧密结合。而它们在AI产品的开发上,类型更加广泛。
根据公开信息,我们梳理出了近两年来,五家大厂各自具备代表性的toB、toC类AI应用产品。
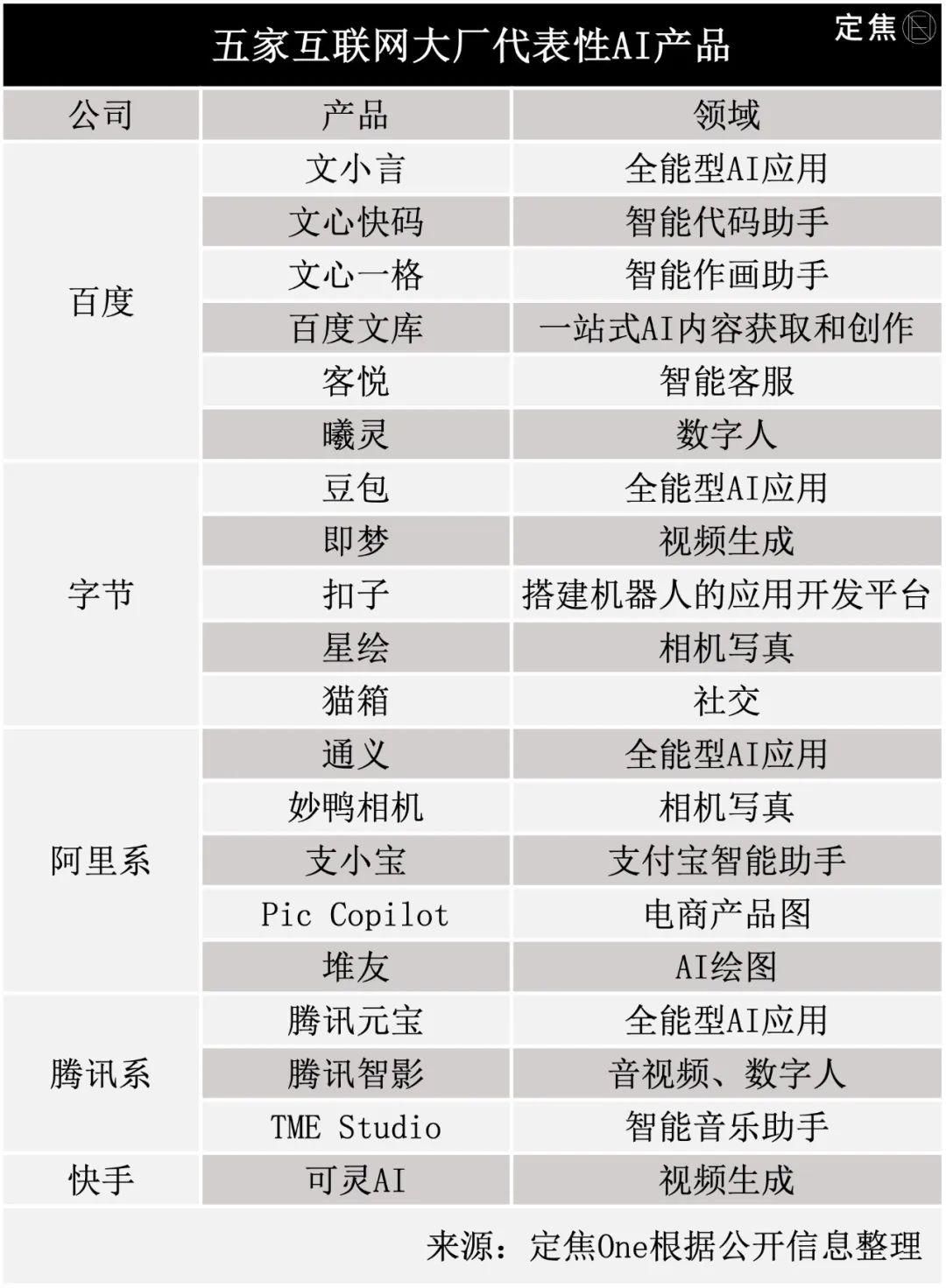
百度是国内对AI热情度最高的大厂之一。百度董事长兼CEO李彦宏多次强调AI应用的重要性,他曾公开表示,“没有(AI)应用,基础模型一文不值。”
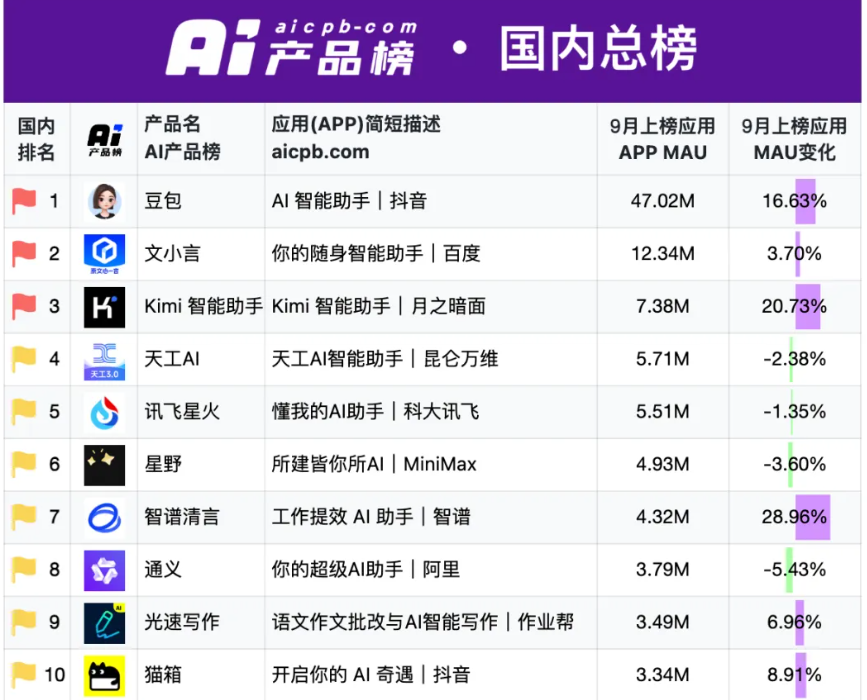
百度比较受关注的AI产品集中在搜索和文字领域,其中文小言被C端用户提及最多,从月活数据来看,它在多家国内综合类AI应用榜单上能排到前三。
文小言虽然是一款全能型AI应用,但最大的特色在于搜索。百度也一直强调其定位为“新搜索”,它区别于在网页里检索关键词得到海量资料的搜索方式,用户可以通过和文小言聊天得到答案。
文小言还具备畅聊、写作、求职、娱乐、办公等各式各样的智能体(可以理解为智能助手)。以办公场景为例,用户打开文小言办公智能体后,里面被细分成了PPT制作、面试、简历、公文写作等各式各样的对话工具,只需点击,便可通过对话的方式进行模拟面试等操作。
此外,百度的AI应用还涉及文生图、数字人、智能客服等。
字节推出的AI应用产品种类较多,其中豆包App表现最突出。QuestMobile显示,截至7月,豆包在国内综合类AI应用月活规模中排第一。
功能覆盖广且使用效果不错,是很多用户喜欢豆包的原因。它既有图片生成、作文批改、工作总结写手等学习、办公场景,也有姓名打分、MBTI性格测试等趣味性内容。它还非常拟人,打开APP便有豆包虚拟人跟用户打招呼,同时支持一边文字输出,一边语音播放。
AI从业者李精进最喜欢豆包的AI生成音乐功能,认为其这一能力处于国内领先水平。
阿里的通义也是整合了生成文字、图片、视频等众多功能,属于大而全的AI集合体。
李精进觉得通义对社会热点的跟进很及时。比如让机器人打球、小猫跳舞等网络上大火的场景,在通义里都能发现。近期诺贝尔奖颁给AI相关领域得主的消息刚出,通义便上线了“一键制作你的专属诺贝尔肖像”功能。
腾讯推出的腾讯元宝主打的也是AI搜索、AI对话等场景,但相比娱乐性更强的豆包,其更重视在学习、办公、创作等方面为用户提效。
相比其他大厂,快手推出的AI产品相对较少,比较有代表性的是主打视频生成的可灵AI。
目前可灵AI在文生视频领域属于佼佼者,不少使用者都表示,可灵的文字理解力、生成秒数、视频清晰度等方面超过很多文生视频工具,甚至能达到商用水平。
“我接的企业宣传片、广告片,有时需要对局部画面精准控制,部分内容还要按照指定轨迹运动,用可灵的运动笔刷就能实现。”一位从业者表示 。
整体来看,各家大厂的最受欢迎的产品仍然集中在AI助手类,但功能差异化不大,且都可以免费使用。其他类型的产品例如“妙鸭相机”曾火过一阵,还有一些在刚推出时曾引发用户体验尝鲜,但能保持月活持续增长的并不多。
二、有人严防死守,有人静待时机
仔细比较这五家大厂在AI上的布局,能看出它们各自的不同策略,综合多位业内人士的观点,我们进行了总结概括。
推出AI产品最多的,当数字节。
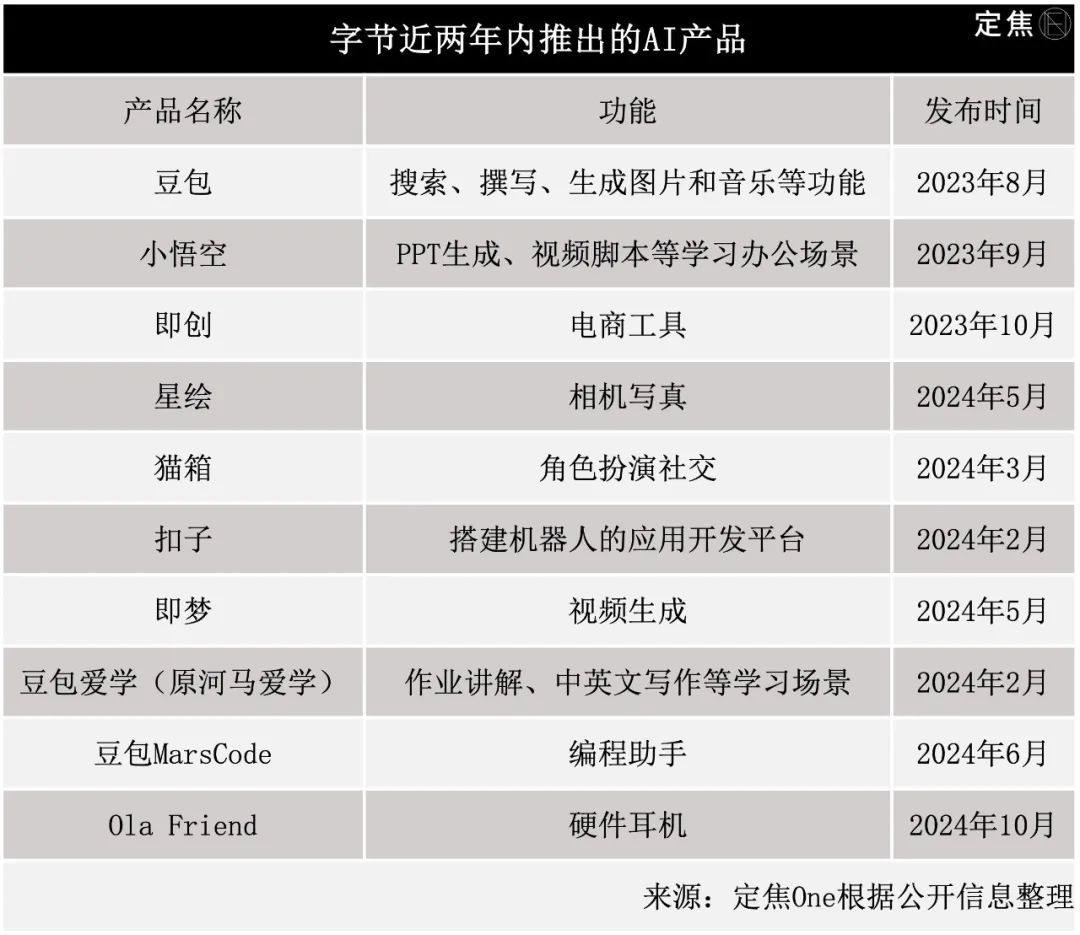
据不完全统计,近两年字节推出的AI产品涉及助手、社交、图像、视频、教育等多个领域。
有业内人士评价,字节用的是“人盯人防守”打法,只要是市场上具有一定知名度的AI产品,字节都不会错过。比如主打AI相机的星绘,对标的便是阿里系的妙鸭相机。
字节还在不断探索新场景,今年10月它又把注意力放到了硬件上,推出了AI耳机Ola Friend。
资深AI领域从业者连诗路分析,字节做AI的思路和它一贯做其他领域的思路一样,即多条线、多产品布局然后进行赛马。且相比其他大厂,字节做的toC类AI产品较多。
阿里在AI领域的一大动作是投资,近两年,它投资了智谱AI、零一万物、百川智能、MiniMax和月之暗面五家最有潜力的AI大模型初创公司。同时,它也有自研的通义大模型。
阿里的另一大思路是围绕自家生态做AI应用。
不止一位从业者表示,和其他四家大厂相比,阿里的AI产品和电商绑定得比较紧密,比如推出了Pic Copilot、堆友等AI产品图工具,都是为了辅助商家制作、提升电商营销效率。
在今年的云栖大会上,蚂蚁集团推出了支小宝(支付宝AI助手)、蚂小财(金融理财)和AI健康管家(医疗健康)三款AI产品,也都和自身业务强相关。
百度则是全力押注AI,重点发力B端。很多从业者认为它能否重返互联网第一梯队,AI将起到关键作用。
AI的重要性在财报中也体现了出来。今年Q2,百度智能云业务营收51亿元,同比增长14%,财报还重点提到了文心大模型的日均调用量超6亿次,半年来增长10倍。
据36kr报道,在最新的百度内部2024年第三季度总监会上,李彦宏表示会继续投入基础模型,并提及了搜索、数字人、智能体、大模型调用、萝卜快跑等业务。同时,他表示不会做Sora这类文生视频类应用,因为投入周期太长,10年、20年都可能拿不到业务收益。
相较之下,腾讯和快手淡定很多。
腾讯在大模型上的推出速度上便比其他大厂要晚,去年9月,其自研的混元大模型才正式上线。同时,腾讯也投资了智谱AI、MiniMax、深言科技等好几家AI大模型公司。
在AI产品端,腾讯主做各类数据库的B端应用,C端产品上除腾讯元宝还算被大众熟知外,其他声量不大。
但有从业者认为这是腾讯在憋大招。“现在AI还没有诞生新的应用场景,也没有产生一个超级大的应用主线,所以腾讯在等其他大厂寻找到更大的场景。”专门做AI产品数据研究的秦宇认为,几乎手握各种应用场景的腾讯,有着不着急抢AI的底气。
连诗路也觉得腾讯在等待一个时机,“一旦腾讯发现其他家找到了准确的AI产品方向,就可以快速操作,甚至将其超越。”
快手目前推出的AI应用产品较少,主要集中在垂直应用,比如文生图、文生视频、AI剪辑等音视频领域。
总结来看,百度、腾讯、阿里的B端AI产品发力较多,字节集中在C端,特别是社交娱乐。
从各家产品的使用反馈来看,和大厂基因相结合的AI产品,往往市场表现更好,比如百度的搜索助手文小言,快手的视频生成工具可灵AI都比较受欢迎,阿里的通义千问擅长电商优惠策略的设计、营销文案的撰写。
三、爆款AI应用产品,还在探索中
最近,AI圈不断传出有初创公司要放弃预训练模型(预训练即大模型基础数据训练)的消息。虽然有公司公开辟谣,但大家也意识到,大模型之战很难再卷下去,做AI应用或许是一条出路。
连诗路认为,目前大厂在AI上的整体策略是,在基础大模型上等一等,但不会放弃,更多发力AI应用。
这主要源于两方面。
一是国内基础大模型已经进入到相对稳定期。
AI从业者李思熠解释,去年大厂卷大模型是认为大模型有上升空间,各家也都是从0开始先搞基建,现在基建基本完成,其训练更多的是在调优。
大模型非常烧钱,红杉资本的数据显示,在2023年,AI行业仅在英伟达芯片上的成本就达到了500亿美元,但整体产生的收益只有30亿美元。
秦宇表示,对于大模型训练要到何种程度,到底还要花多少钱做预训练,各大厂也拿不准。
换句话说,此刻再卷大模型的性价比不高,各家目前在基础大模型上的技术上也很难再拉开太大差距。
连诗路从大模型底层架构、硬件、人才三方面分析,五家大厂的基础架构一样,算力层面都在1万张卡左右,可能阿里会相对多一点。至于人员构成,这几家的核心AI科学家团队没有太大变动。目前大厂间的主要区别是各自积累的训练数据。
另一方面,经历了去年的野蛮生长后,大家逐渐回归理性。
不止一位从业者表示,今年AI行业淘汰了很多凑热闹的人和资金,现在留在行业里的,多为真玩家,大家认可做大模型最终是为了做产品,因为产品才能解决企业和用户的根本问题。
但应用这条路也不好走。
首先是场景探索没有进一步突破,这可以从各类AI榜单中发现。
秦宇通过梳理AI榜单发现,目前AI产品的类型集中在搜索、角色扮演、聊天机器人上,没有太多新的使用场景。近两个月AI产品的月活靠前的还是豆包、文小言、Kimi这些老产品,很难看到新应用跑出来。
其次,AI产品的活跃度和营销投入关系很大。
秦宇透露,虽然近两个月榜单前几名的AI产品没有太大变化,但月活用户会出现波动,“谁当月投的广告多了,产品的月活就会提高,抖音是最大的广告投放渠道。”也有AI公司工作人员曾对媒体表示,自家产品的获客人数和广告投放联系很大,AI产品的获客和用户留存,主要靠营销。
不过,无论是大模型还是AI应用,无论难度如何,AI这块蛋糕,大厂都会想尽办法拿下。