这是我的AI应用系列第二篇,想谈谈“如何找个好场景”。场景找对了,那就成功一大半,这个道理放在AI大模型的应用上,再合适不过。
核心观点:
本轮AI革命,在企业应用还远未成熟,可奈何大家求AI心切,因此识别“好场景”至关重要
场景识别对了,大家投入才有回报;场景识别不好,折腾一圈,一地鸡毛
分享AI场景“12问”及其背后的思考逻辑
PS.观点不保证绝对正确,欢迎留言讨论,兼听则明。
01 为什么AI大模型这么“挑活儿”?
当我们站在企业内部看AI大模型落地场景时,很容易被两种情绪裹挟:要么AI无所不能,要么AI啥也不是。
当然,感谢业界的同行们一直不断推出新产品,最近听到的第二种声音越来越少了,更多是急迫地希望做些什么。
坦率讲,目前的企业AI大模型应用场景,如果挨个拉出来盘ROI,有正收益的是少数,特别是动辄几百上千张卡的场景,单纯看眼下收益,都是很难讲的。
但是,AI变革的浪潮已至,我们又必须要跟上,所以如何选择一个好场景,就至关重要了。
这里我想分享“AI场景12问”和其中的思考逻辑。
02 如何识别好场景:AI场景“12问”
整体上,希望通过三个维度来评估:
D1:商业价值
D2:场景成熟度
D3:持续运营
这三个方面,分别代表着是否值得做、是否能做、做了以后是否能持续演进。
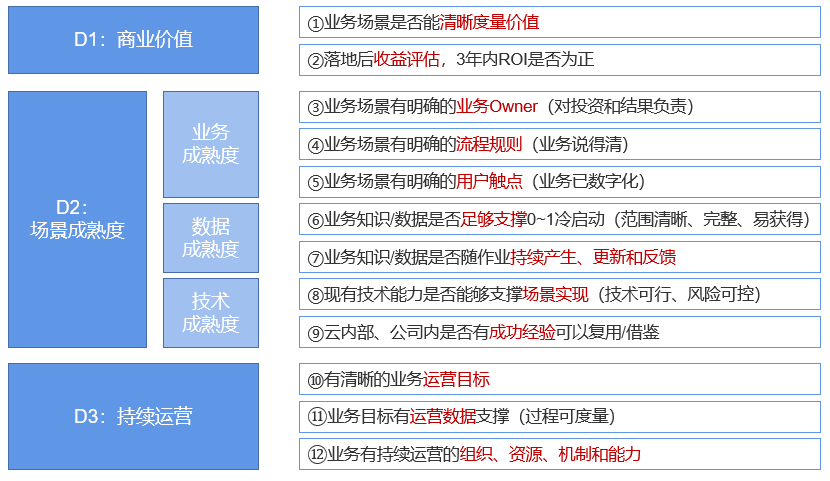
D1:商业价值
之前这个维度叫“业务价值”,为了更突出我们是商业组织,我特地改成了“商业价值”。
① 业务场景是否能清晰度量价值?
什么叫度量价值,无非是增收、降本、增效。能够直接带来收入增长或者成本降低,那是最好的,如果不能直接带来收入,那效率提升也是不错的。
举个最近的例子:
1.如果AI助手能直接跟客户打电话,并且成单,那这就是“增收”,这是可遇不可求的场景;
2.如果AI助手可以替代我们的一些资源(包括人和物),那这就是“降本”,这种场景次之;
3.如果AI助手可以在作业过程中起到部分替代或辅助作用,使得我们的现有人或物做事时,更快、质量更好、效果更加,这就是“增效”,这种场景最次。
这里关于场景价值评估,我经验也有限,总结了这么几个小技巧,可供参考:
1.重点关注“增收”和“降本”类场景,尽可能将“提效”类场景转换成这两种场景,具体给出计算逻辑,一旦逻辑清晰,计算和评估非常简单,价值显而易见。
2.“提效”类场景数量最多,但鱼龙混杂,是很需要花精力探讨和分析的。说实在的,每个人都有“提效”的诉求,我也恨不能找个AI帮我码字,这样对于我来说可以轻松愉快一些,但是这对于公司来说意义有限,这就是最大的矛盾点。
3.如果真的要做“提效”类场景,避免使用百分比。我们太多场景喜欢用“提效xx%”,年年做,年年提,挤挤总会有,这个游戏很容易玩儿,但是坏处是在业务侧很难形成真正的压力和动力,Nice to have,不做也无所谓,这样的后果就是战略资源被消耗掉了。如果要提,就把具体业务KPI的from和to拿出来,计算逻辑写清楚。
4.“降本”的收益计算要从“投资”角度来看。这里我举个“巡检”的小例子,在没有AI的时候,只能每天人工检查x次,有了AI,可以每分钟都检查一次,这么一算,看似节约了不少成本。实际上,这个事儿就搞反了,应该看业务上愿意投多少钱来增加人力做巡检,AI节约的只是这些投资。
② 落地后收益评估,3年期ROI是否为正?
ROI评估这事儿非常重要,投资不看回报,那是非营利性组织,咱们不能这么搞。
这一条存在,是为了加强第一条的存在感,同时也避免为了一个小场景过度的投入资源。
这里其实我们给AI类的投资留了个buffer,就是“3年期ROI”,核心是因为AI大模型的应用太新了,能够上线即巅峰的场景又太少,大部分场景上线以后都不能直接形成价值,需要持续地喂养和优化,因此我们希望资源和人力的投入可以在中期形成真正的业务价值。至于为啥是3年,说实话,这个数是我自己预估的,可能不同领域情况会有差异。
D2:场景成熟度
场景成熟度包括业务成熟度、数据成熟度、技术成熟度。这三个成熟度,是从华为AI团队借鉴来的,从数据、业务、技术三个角度来审视。具体细节内容上,增加了一些自己的思考。
D2.1 业务成熟度
③ 业务场景有明确的业务Owner(对投资和结果负责)
Owner很重要,这个事儿可以倒着想,如果一个AI场景,没有业务Owner,会导致什么问题:
1.没有人投资,这是最直接的。虽然我们现在很多AI基建的投资都是IT空载,但是AI应用的落地,终究是要业务投的,业务要感知到这个投资;
2.没有人对结果负责,这个也很重要。一般业务Owner是业务流程Owner,也是业务部门主官。他能够对结果关切,一方面说明我们做的事儿对口,另一方面也是对业务团队的驱动力(AI场景落地能不能成,我越来越觉得跟IT有关系,但是很有限)。
④ 业务场景有明确的流程规则(业务说得清)
这个不过多赘述,是不是说得清这事儿,其实就是业务是不是成熟,还是很容易辨别的。一个还在不断调整、不断变化的业务,过早地搞AI,甚至数字化,对双方都是一种煎熬。
⑤ 业务场景有明确的用户触点(业务已数字化)
智能化的基础是数字化,业务数字化的程度,决定了AI能不能落地。这轮AI大模型的应用,和传统的IT应用最大的差异,就是AI大模型需要数据喂养。没有数字化,何来数据呢。(这里提到的数据,是全场景、全流程、全方位的知识数据,主打的就是“全”,越完整越好)
再一个,没有数字化,就意味着我们的AI落地以后,没有现成的触点接入,就意味着没有现成的流量继承,就意味着AI运营的成本会大大增加。
从另一个角度看,如果一个业务场景还没有数字化,或者数字化程度不高,以我的经验来看,一定是有隐情的,还是不碰的好,要碰也是要先把数字化补上再说。
D2.2 数据成熟度
先提一嘴,这里提到的数据,包含知识数据,且暂时以知识数据为主。另外,这两条,是从AI训练的两个阶段来看对数据的诉求,一个是冷启动,一个是持续运营。
⑥ 业务数据是否足够支撑0~1冷启动(范围清晰、完整、易获得)
足够支撑冷启动,就意味着能够达到上线标准。目前我们以AI答准率60%为基线,判定一个场景是否能够上线。当然,也不排除有一些非常通用的场景,不需要额外数据,基模型能力就能够支撑,不过,这种“天使”场景可遇不可求,不在后续讨论范围内。
具体落地时,还考虑要到业务是否能够清晰地说清楚需要哪些数据、是不是方便拿到这些数据。目前大部分知识类场景都是通过RAG(检索增强生成(RAG)是指对大型语言模型输出进行优化,使其能够在生成响应之前引用训练数据来源之外的权威知识库)来实现,R的本质就是搜索,搜索就要有个知识清单,这个清单包括哪些知识,要业务输出,然后IT来评估可行性。比如,我遇到有场景需要CSDN的技术博客,这类就很难获取。
⑦ 业务数据是否随作业持续产生、更新和反馈
一个AI场景冷启动结束后,就到了持续运营阶段。这个阶段由于企业场景的用户基数极其有限,没办法获得海量的用户侧反馈(OpenAI的MAU有1亿,我们可能大部分场景不会超过1千),这就使得我们将不遗余力地挖掘和利用作业过程中的每一个反馈和留痕数据,确保最大化地从这些有限的数据中汲取价值。
这块扯远一点,我们后来探讨出一种玩法,叫“作业即标注”也就是说,每一次作业动作的过程中,都预埋了标注和反馈过程。这当然需要巧妙的设计,甚至略微改动原有IT的交互逻辑,更甚至通过牺牲一点点用户体验为代价。
D2.3 技术成熟度
⑧ 现有技术能力是否能够支撑场景实现(技术可行、风险可控)
前面整这么多,总体上都是在做业务场景的评估和分析,也就是业务侧的梳理和分析为主。基于前面评估OK的前提下,技术同学要开始工作了。
这里有个巨大的“陷阱”,或者是认知上的反差:AI大模型为什么POC(POC:Proof of Concept,为观点提供证据)这么简单,做好却这么难?
在传统IT开发的场景上,技术可行性是容易评估的,一般技术架构或者SE同学都能够胜任;但是针对AI大模型相关场景,很多时候是要评测的,也就是要试一下,做个POC。
不过,AI大模型的POC反倒是我见过最容易的,就是搞几句提示词拿基模型试一下。这轮AI创新的非常重要一环,就是引入了自然语言指令,使得人人都能操作AI大模型。
然而,企业垂域场景,大概率第一次试结果是不太好的(大概就是瞎猫碰见死耗子的概率,我印象非常深刻,不论是文本还是多模态,没有超过10%的)。
于是下一步就是要AI技术专家或者AI SE来判断下,这个场景是否可以改进。改进就分两块,要么是“等”,要么是“调”。
等,就是等AI基模型能力提升。
调,就是要看,这个场景是不是能做微调:针对典型任务(高频、规范、标准),准备几百上千条数据调一下是合适的,但是针对尚未从业务上收敛、抽象的任务,是没法调的,也就是用少量数据没法教会大模型干活。
另外还有一个,就是“风险可控”,当然这背后虽然可以建立一套AI安全的玩儿法,但是无论如何AI大模型的“幻觉”是一种不可消解的风险,只能做风险规避和一定程度的接纳。如果某个场景不能容忍任何不确定性,那就确实还不适合,至少当下不行。
⑨公司内是否有成功经验,可以复用/借鉴
这里我特地强调,是公司内部有成功经验,有三个意图:
1.正视自己的技术能力差距,无论是基模型还是模型应用。比如我们看到GPT4可以干啥、甚至微软office的copilot可以干啥,对于我们的参考意义有限。把有限的资源押注在这样一些不确定性上,是很有风险的,卡点会非常多。
2.公司内部的同学已经做成,已经拿出来分享的场景,反而是我们喜而乐见的,这意味着“触手可及”,拿来抄个作业很顺手,哪怕不能抄,交流交流学习讨论下也是不错的。
3.我一直认为我们是AI技术应用团队,要以业务成功为唯一目标,把突破创新让给更专业的人,做好AI应用过程的学习、提炼、总结,是我们的“道”。不求高精尖,只求能落地,越简单、低成本、易复制,就说明把AI应用玩儿明白了。
D3:持续运营
这一章节是我们最后加的,并不是不重要,而是在早期易被忽视,很难充分意识到其重要性。
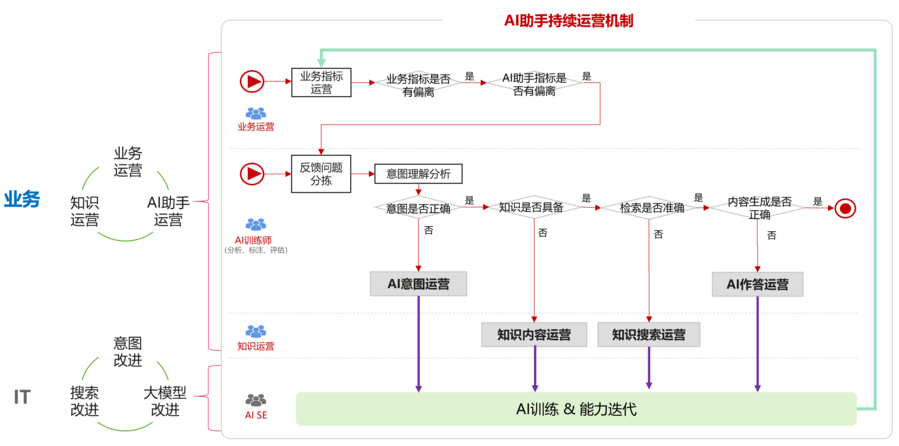
“持续运营”放在这里,是为了突出“生”和“养”同等重要,甚至“养好”比“生好”在项目成功、业务成功方面更重要,也是希望跟业务主管强调这方面的重要性。
上图是一个AI助手的持续运营示例,可供参考,核心是业务和IT的联合,且以业务侧为主(在业务运营、知识运营之外,新增了AI训练师角色)。
⑩ 有清晰的业务运营目标
一个AI场景,除了业务价值的指标之外,还需要很多过程指标,需要观测其分子分母、周边因素、关键依赖(比如知识)、副作用等等,业务运营是需要设计的。
⑪业务目标有运营数据支撑(过程可度量)
原则上一个相对成熟的业务,会有一套现成的业务运营体系,我们要做的是从其中摘到AI应用强相关的部分,再加入IT侧的过程指标,如AI应用情况(比如性能、并发、UV/PV、资源消耗)、反馈情况(比如答准率、搜准率)、NSS等等。
⑫业务有持续运营的组织、资源、机制和能力
运营要有流程和组织支撑,才能有生命力。我司的管理哲学就是把公司制度建筑在流程上,所以没有固定的模式在支撑,运营工作会变成“脚踩西瓜皮”,干到哪儿算哪儿,甚至有一搭没一搭地搞,哪怕搞看板、搞分析、搞预警,都没个啥用,最后生成一堆任务也没人执行。
当然,这一切背后,其实只有一个,就是要业务主管非常清楚地意识到,这里需要投入,而且需要持续投入。
以上这十二个问题,并不是我个人的经验,是华为的集体智慧。
最后,我还想说,目前业界关于AI应用有两种认知:
1.一种是“AI+”:真正的AI应用是没有AI就无法运行的。毕竟大家总用“汽车”和“马车”来类比AI和传统IT,给马车装个内燃机可能不是我们想做的。现在的很多创新类的AI产品,包括chatgpt就属于这种。
2.一种是“+AI”:就是在很多场景上,增加AI属性,一点点翻盘。这个观点一样有支撑,就像移动互联网来了之后,PC网站还在,线下门店也还在,但是互相支撑后,效果更好了。现在的copilot式操作,就是这么个玩法。
这里的核心,是你拿AI当什么。如果你认为这是生产力工具,那一定是all in,全换,过去不值得留恋。如果你认为这是基础设施,那一定是适用的先来,适配一个切换一个。
我自己内心是认可生产力工具的说法的,但是现实情况是企业要运转,运转逻辑是写好的,现在掀桌子就都没得吃。
所以,我一直有个观点,当下的AI大模型场景应用,是面向未来的一种蓄力和能力储备,从量变到质变的过程。比如我们从去年单独看客服AI,到现在可以看客户服务全流程,逐渐把售前、售中、售后都拉齐以后,一个AI+的雏形就有了,这个过程可能需要3~5年甚至更久,但非常值得。
























































 Sora提示词
Sora提示词