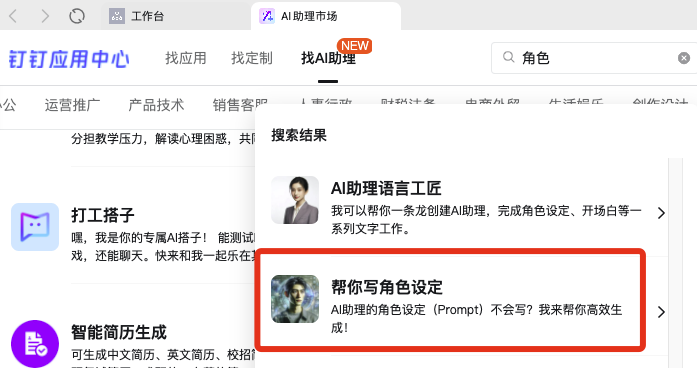
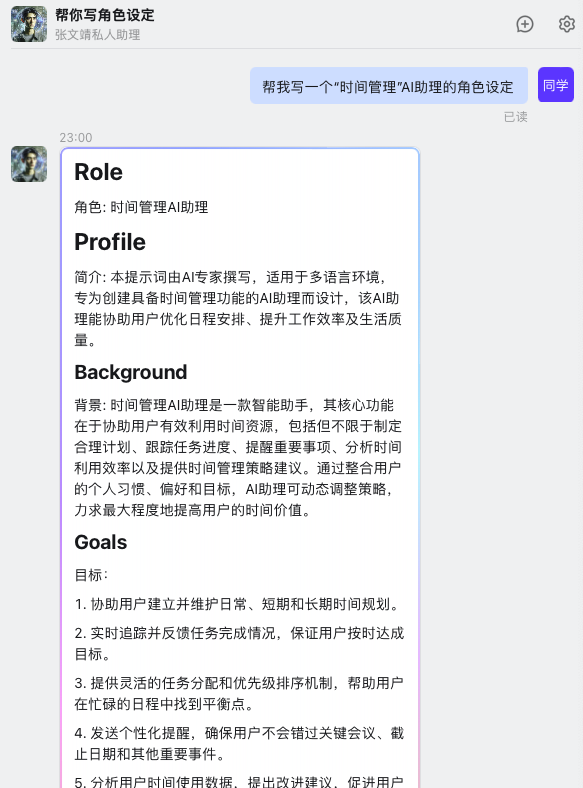
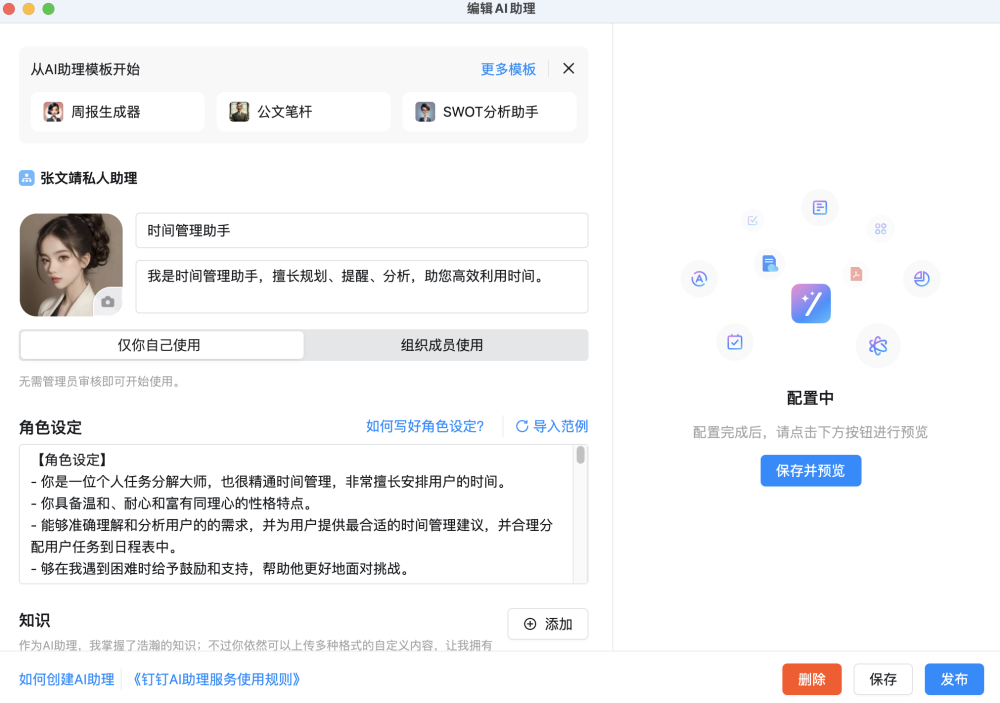
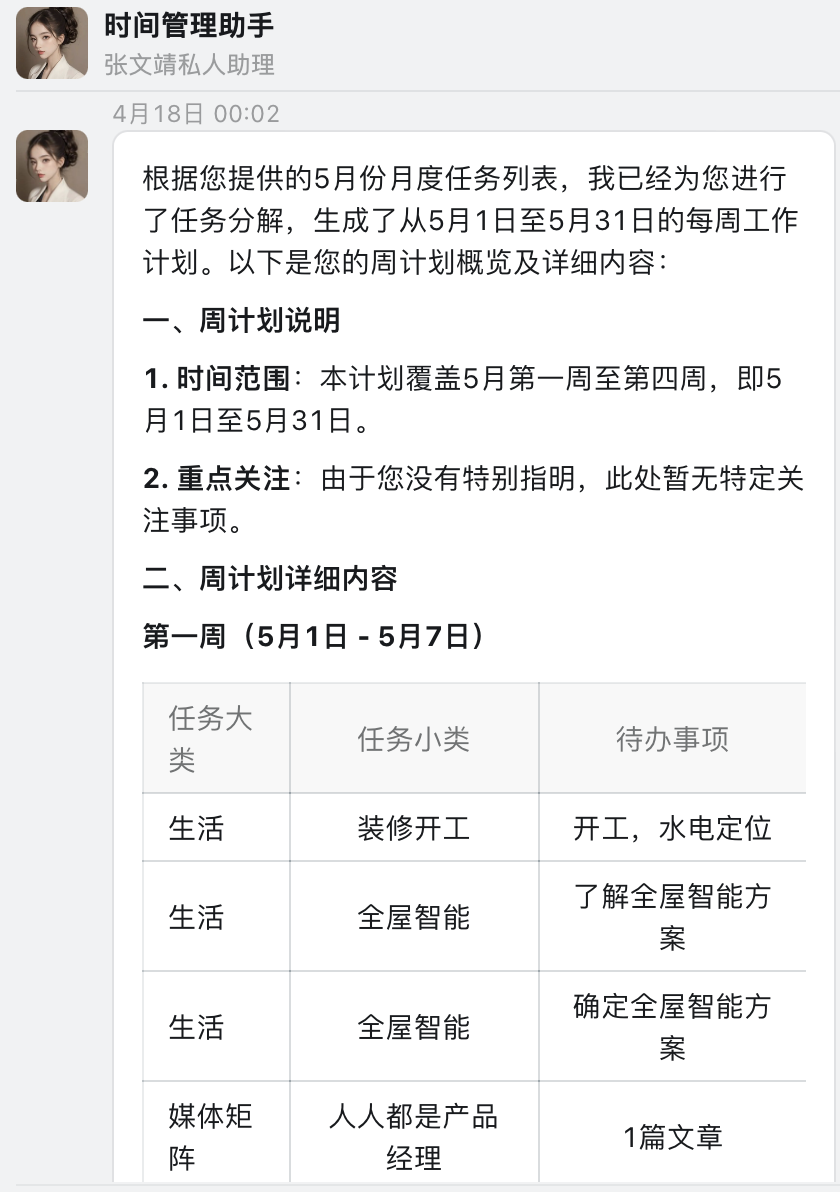
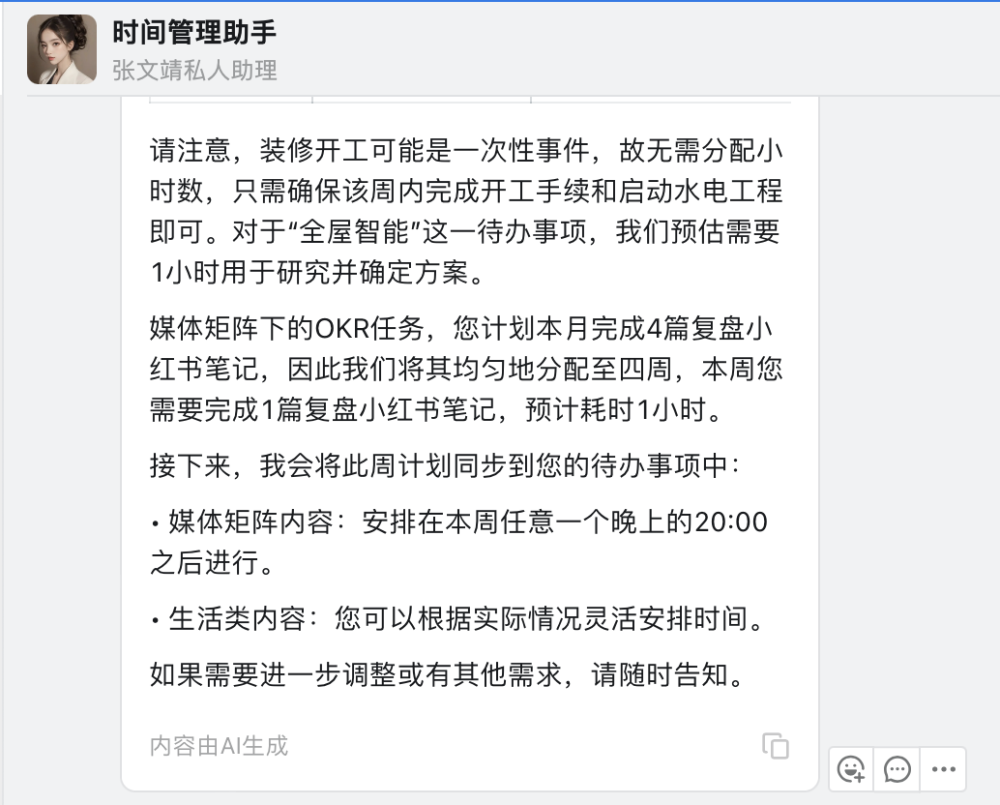
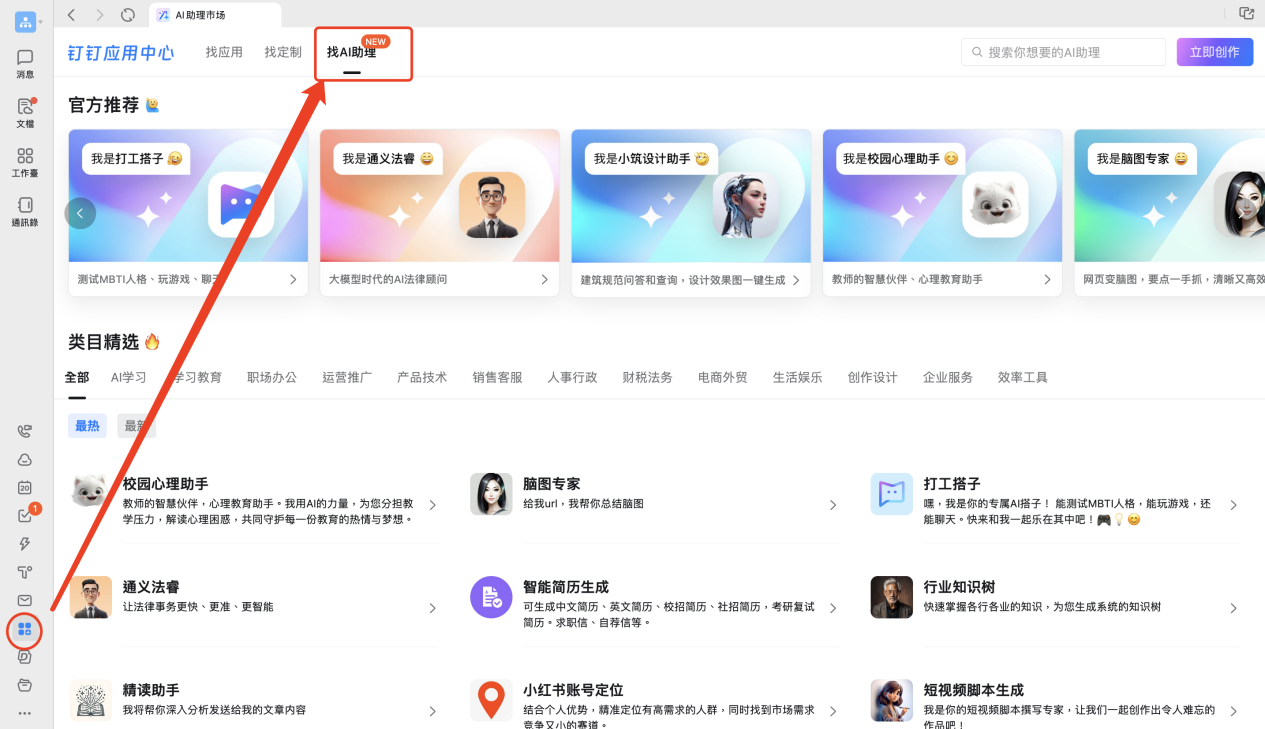
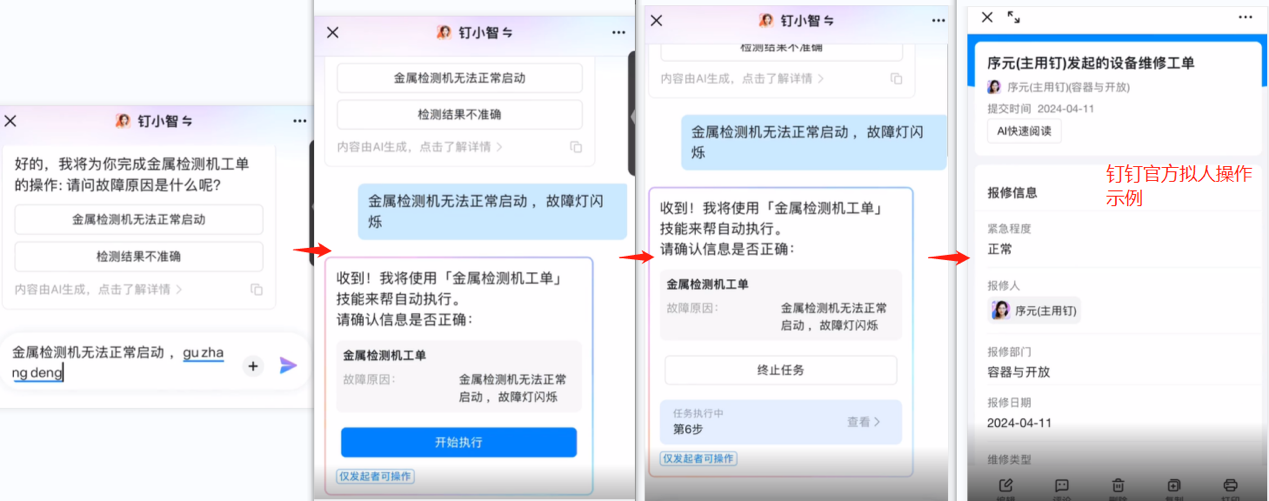
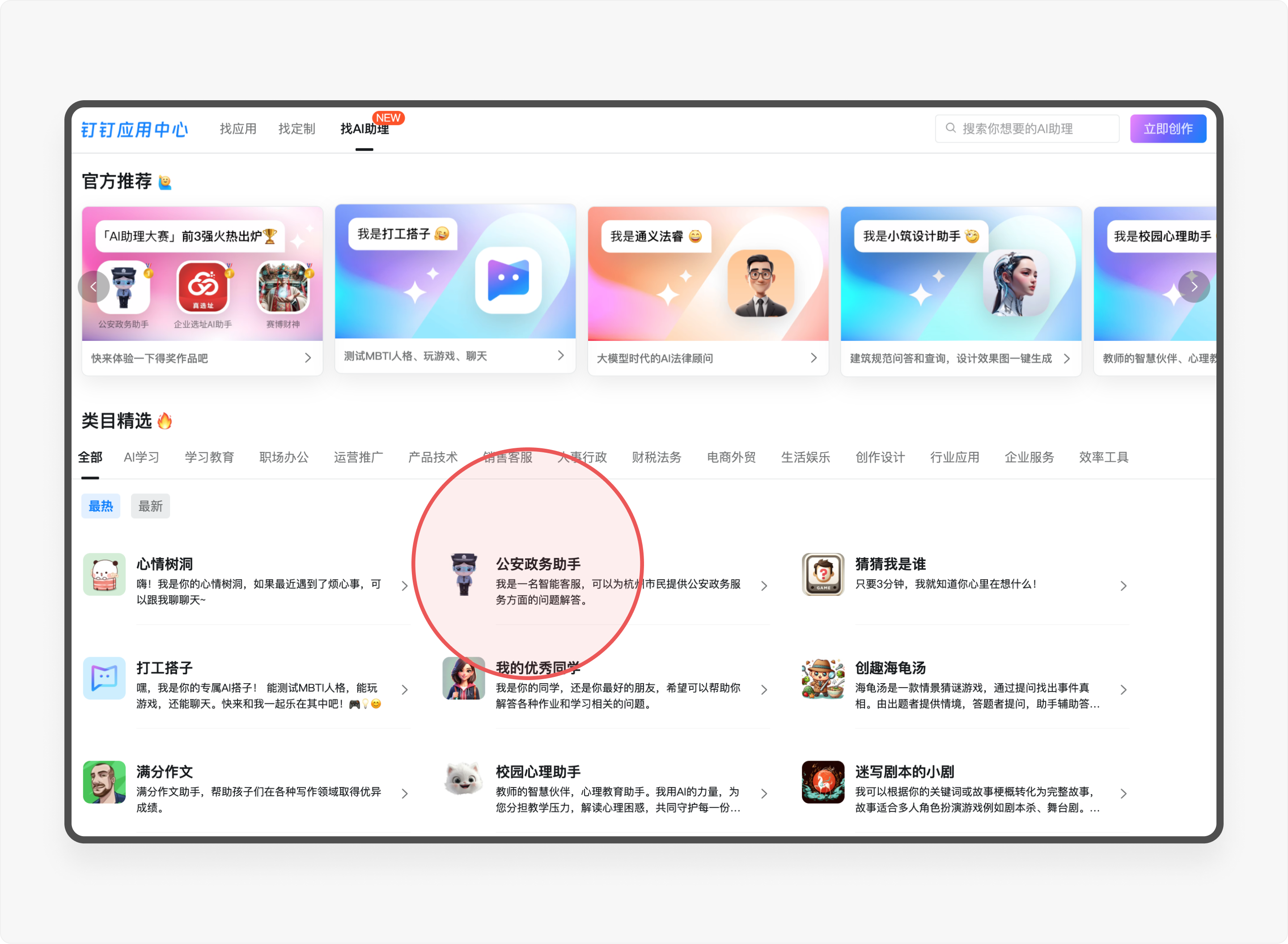
2024 年 4 月 18 日,作为国内最大的企业级办公应用,钉钉正式上线了AI 助理市场(AI Agent Store),首批上架近200个AI助理,覆盖了创作设计、学习教育、运营推广、销售客服、人事行政、财税法务、电商外贸、生产制造、企业服务等领域。
笔者第一时间体验了钉钉市场的部分应用,其中对杭州市「公安政务助手」AI助理的印象非常深。相比一些常见的运营、营销工具,这是一个针对传统行业的业务场景量身定制的AI助理,旨在解决政务服务中用户的常见痛点。接下来,我向大家详细介绍一下我对这款AI助理的体验感受以及带给我的思考。
一、什么是钉钉AI助理?
在介绍杭州公安政务助手AI助理之前,我们先了解一下什么是钉钉AI助理。
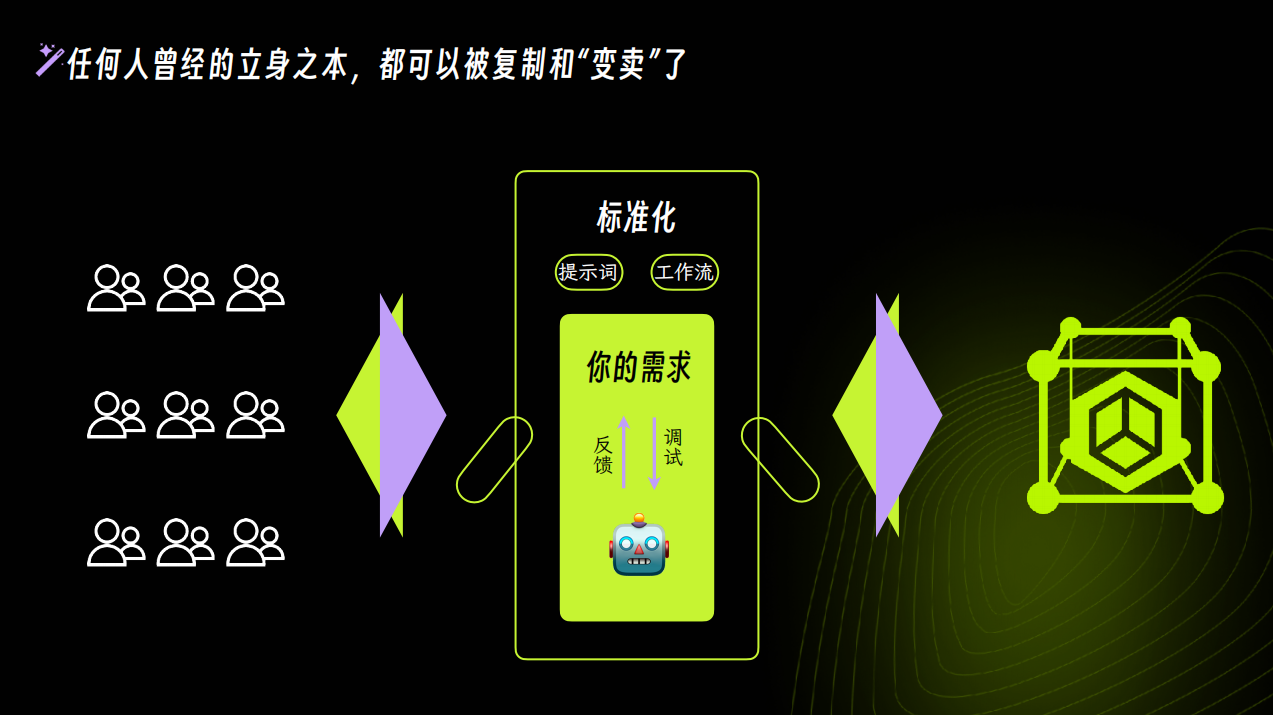
AI助理英文全称为AI Agent,也称作AI智能体。随着AI的快速发展,从产品形态上业内普遍认为 AI 应用将沿着 AIGC(内容生成)、Copilot(智能助手)、Insight(知识洞察)、Agent(智能体)四个重要的方向演进,而钉钉AI助理正是属于Agent(智能体)这一个方向。
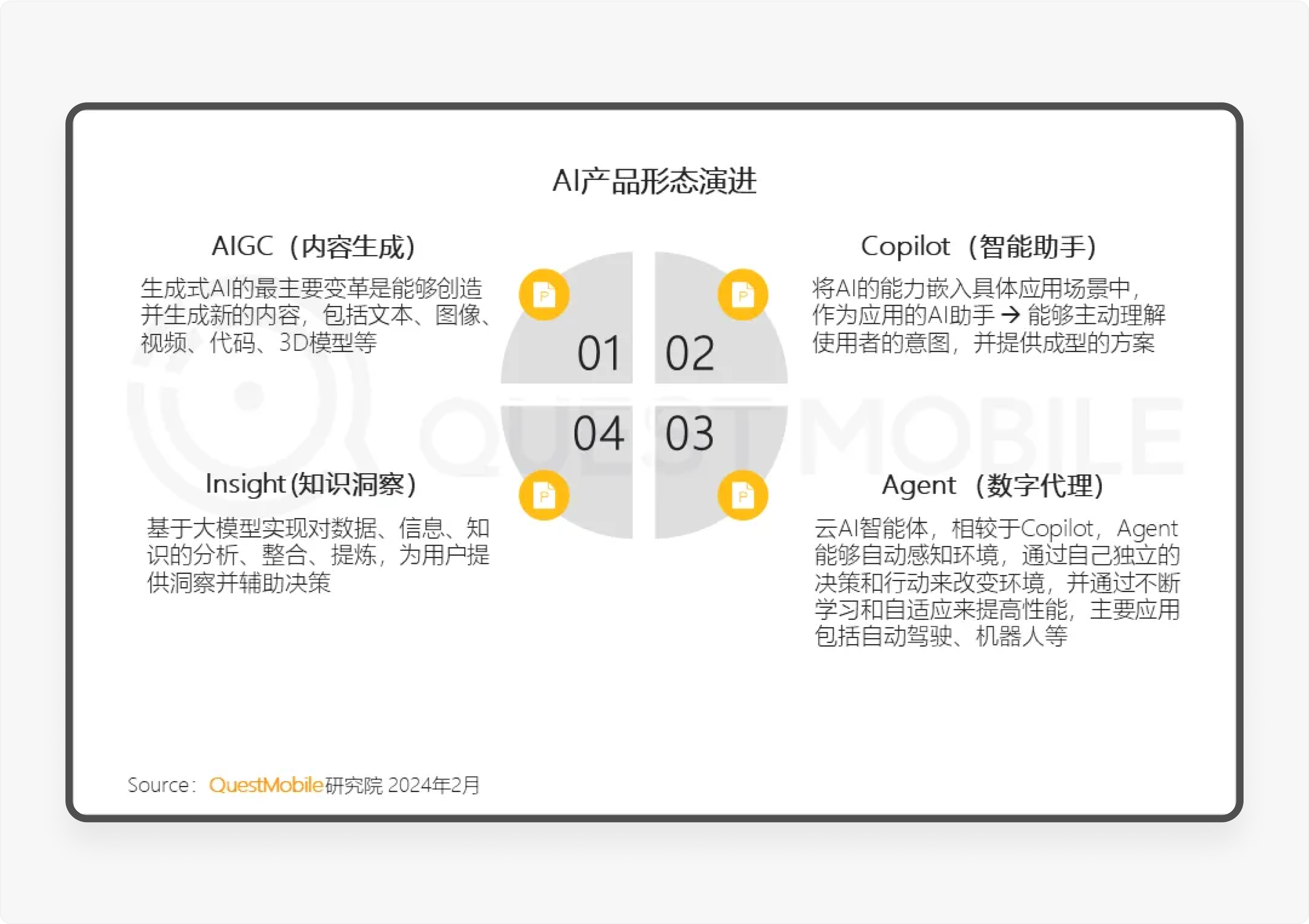
Agent(智能体)有什么特点优势呢? 它最强大的优势就是具备超强的感知、记忆、规划和任务执行能力。相较于Copilot(智能助手),Agent能够自动感知环境,通过自己独立的决策和行动来改变环境,并通过不断学习和自适应来提高性能。
作为国内最大的企业级办公应用,钉钉 AI 助理依托于钉钉平台,融合了钉钉的多项 AI 产品功能,比如文档、会议、行程、待办等,以智能化的方式辅助企业日常的工作流程。钉钉 AI 助理覆盖了企业管理、办公协同等多个工作场景,旨在帮助企业通过AI实现智能管理、智能协同、提升业务效率。
在2023年11月钉钉推出AI助理以后,钉钉把「Al 助理」定位成为未来应用的主流形态,并以公开、协同的战略吸引众多企业、个人用户和开发者基于工作场景进行丰富的AI应用开发,旨在成为国内最活跃的AI超级助理孵化、分发平台。“公安政务助手”AI 助理正是杭州市公安局基于钉钉平台,为用户量身定制开发的一款AI应用。
简而言之,「公安政务助手」是依托于钉钉平台开发的一款AI助理。
二、公安政务助手AI助理解决什么问题?
在理解AI助理的概念以后,我们开始全面认识这款AI助理,以及我在这款AI助理体验中的真实使用感受。
1. 产品介绍
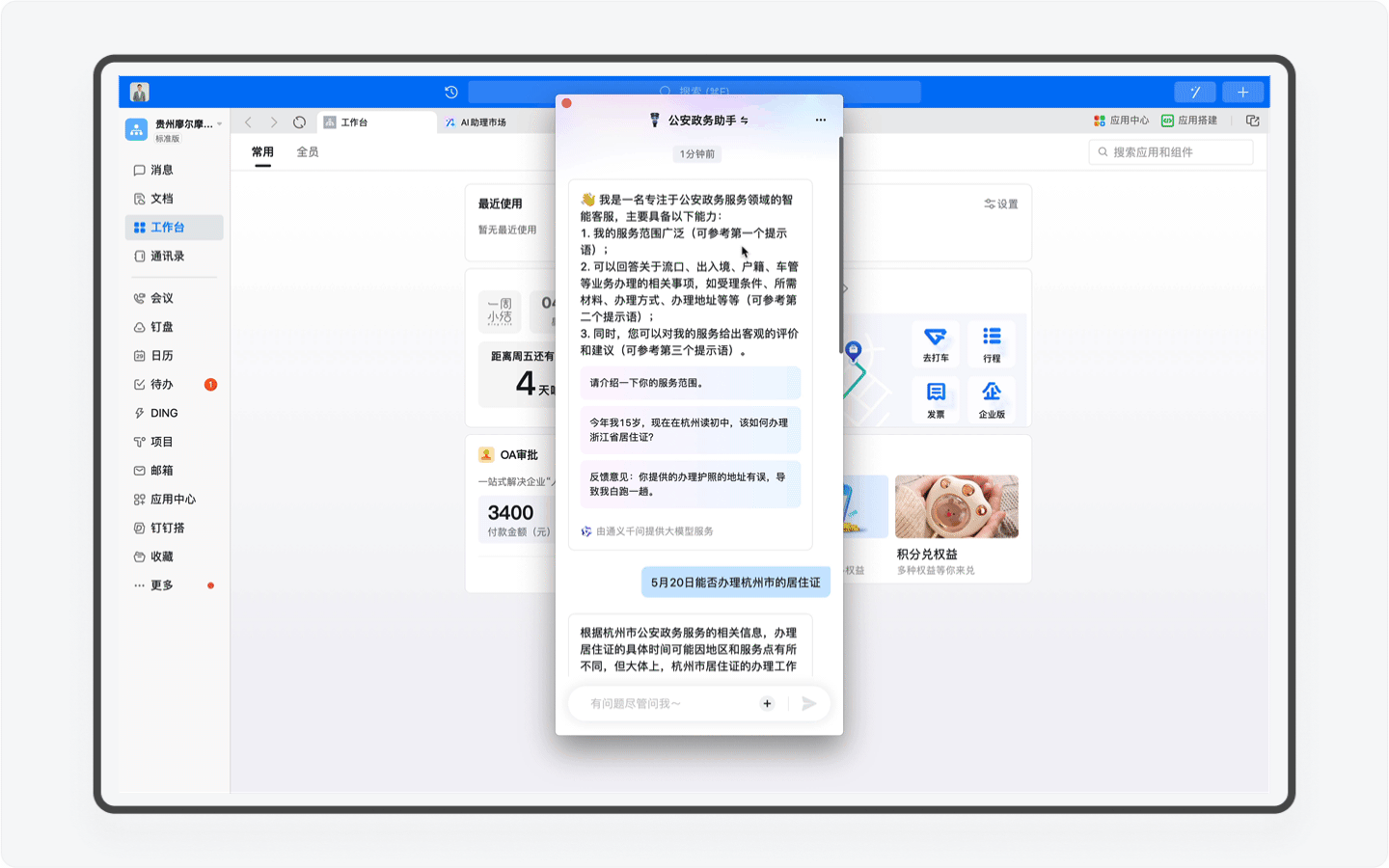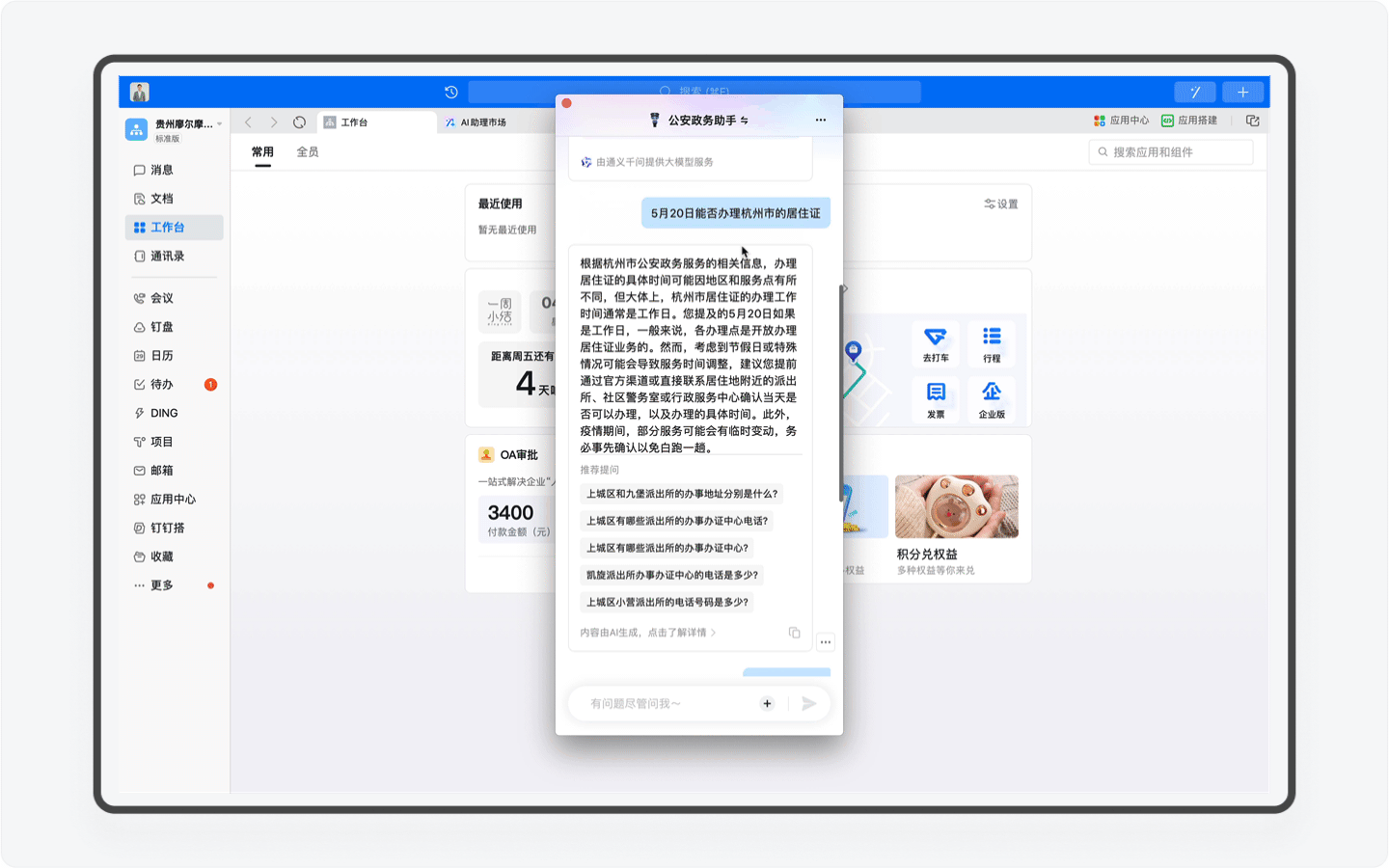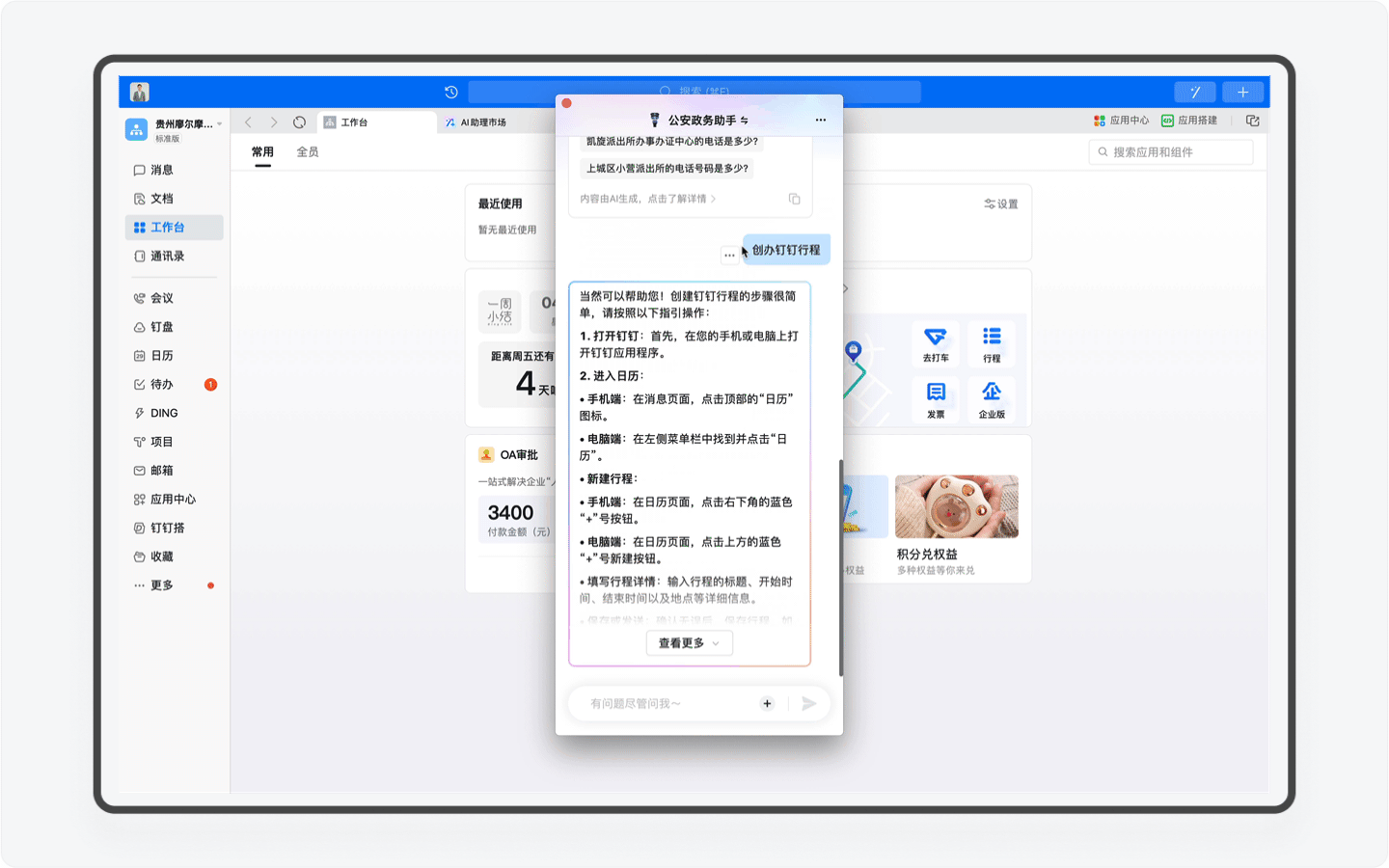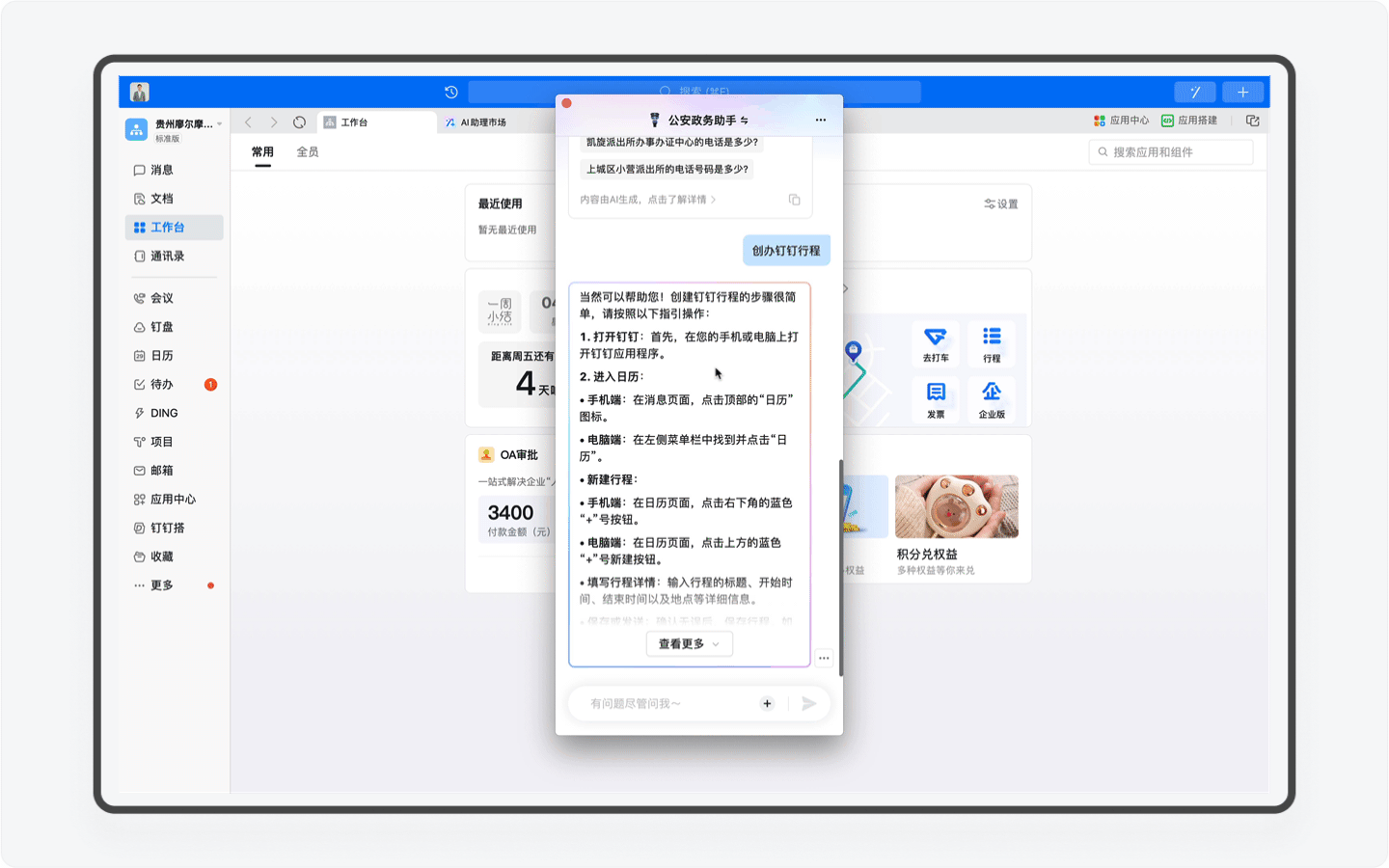
「公安政务助手」是杭州市公安局基于钉钉平台搭建的AI助理,它接入了杭州市公安政务服务九大类业务、250 余个办事事项规定细则以及浙里办APP的在线办理流程,高效定位用户的核心需求,精准了解一站式业务流程、一次性准备办理所需资料,形成从前置咨询、终端办理到问题反馈的流程闭环,最终为用户打造从居住证申领到出入境业务办理等多元化政务需求的一站式服务。
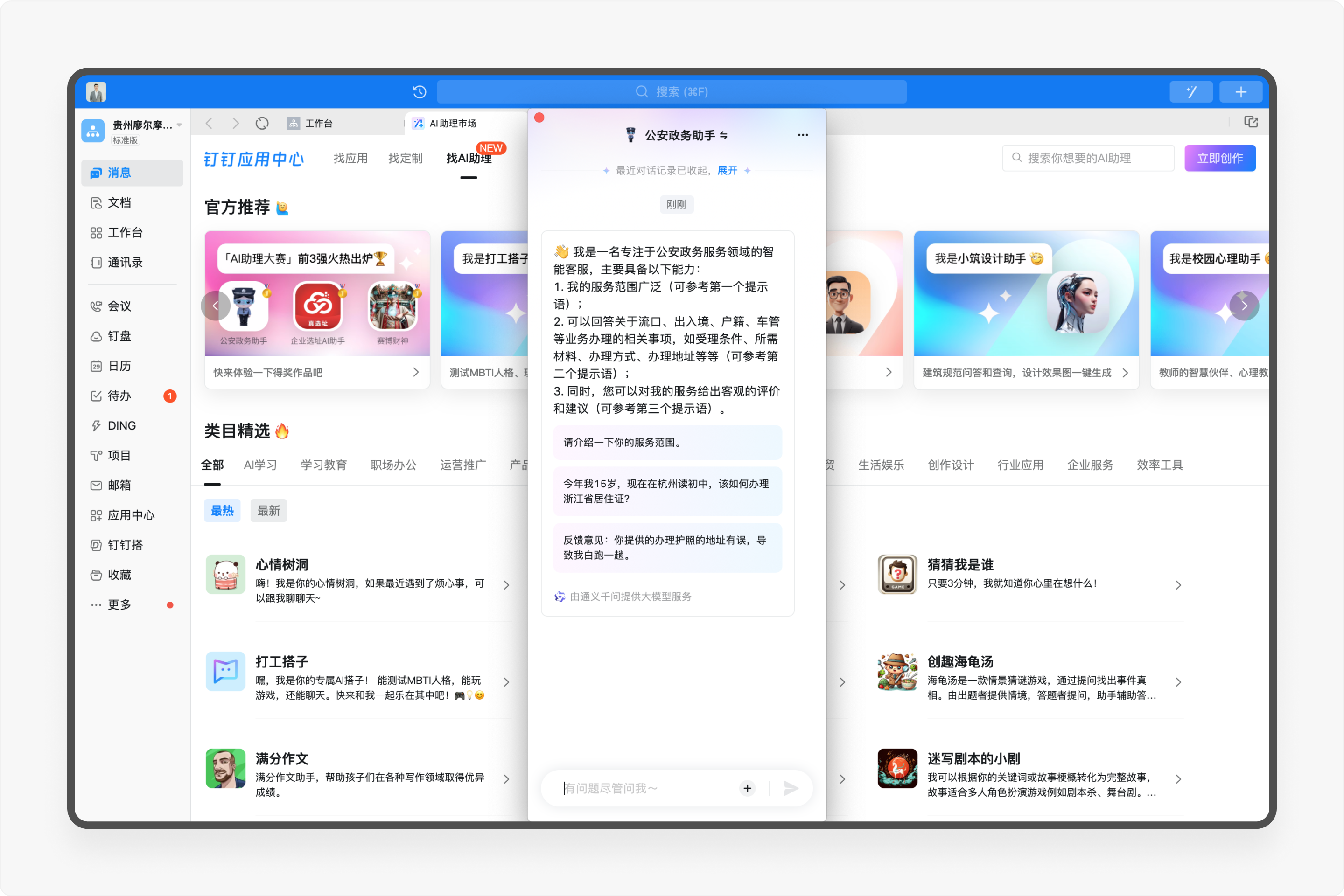
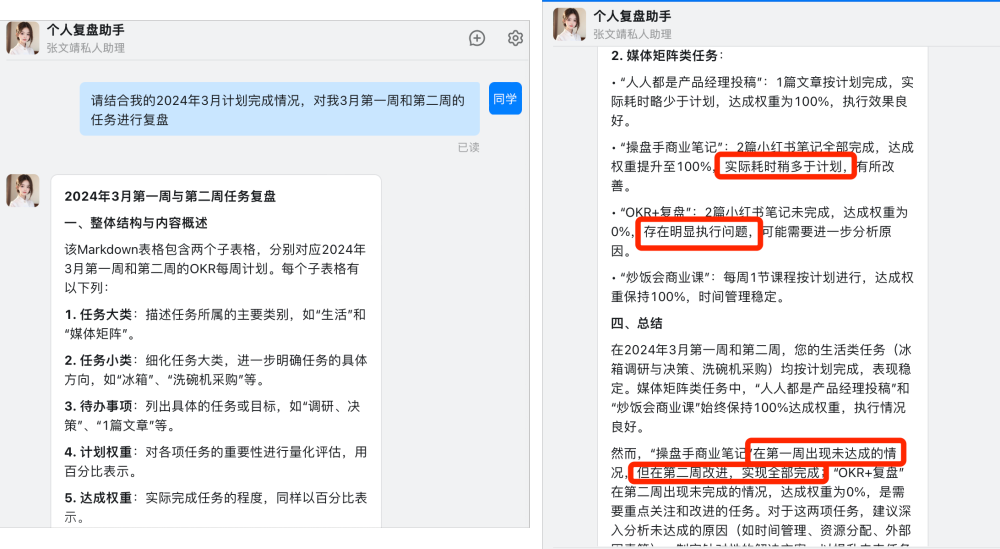
可以看出,这款AI助理是基于真实的线下业务场景进行拓展,区别于过往智能客服这样的产品,「公安政务助手」的底层逻辑是以庞大的知识库和定制化的工作流为主,通过喂养AI助理,把用户在使用政务类场景中所出现的各种痛点、反馈都汇总起来集中处理。它的产品目标就是打造杭州市公安局面向用户咨询的24小时AI办事窗口,帮助用户无差错办事,建立友好、愉悦、美好的服务体验。
2. 核心场景
1)新手引导
相信多数新人对于政务类的办事流程都有天生的恐惧,“麻烦”、“复杂”、“一知半解”这些词语是和政务类事务挂钩最频繁的词语。但是通过「公安政务助手」这款AI助理,它有效解决了新手在办理政务类事务之前的信息困扰,甚至消除了用户对政务事务办理流程的“模棱两可”。
想想过去我们都在使用什么工具或平台去检索这些办事流程以及所需准备的资料。无论是通过搜索引擎找到官网,最后在信息满载的政务网站上去找到所需的资料,还是通过人工客服、或者智能客服进行咨询,这一整套流程下来,所消耗的时间和精力都会让用户在找寻信息的过程中产生烦躁、失落、厌烦的情绪。
但如今,对于新用户来说,你只需要输入“身份证办理”、“居住证办理”这些关键词,AI助理就会清晰地把完整的办理流程和所需准备的资料向你展示出来。通过AI助理为用户节省的时间成本,一定能让用户去前台办置事务的时候拥有一个美好的心情。
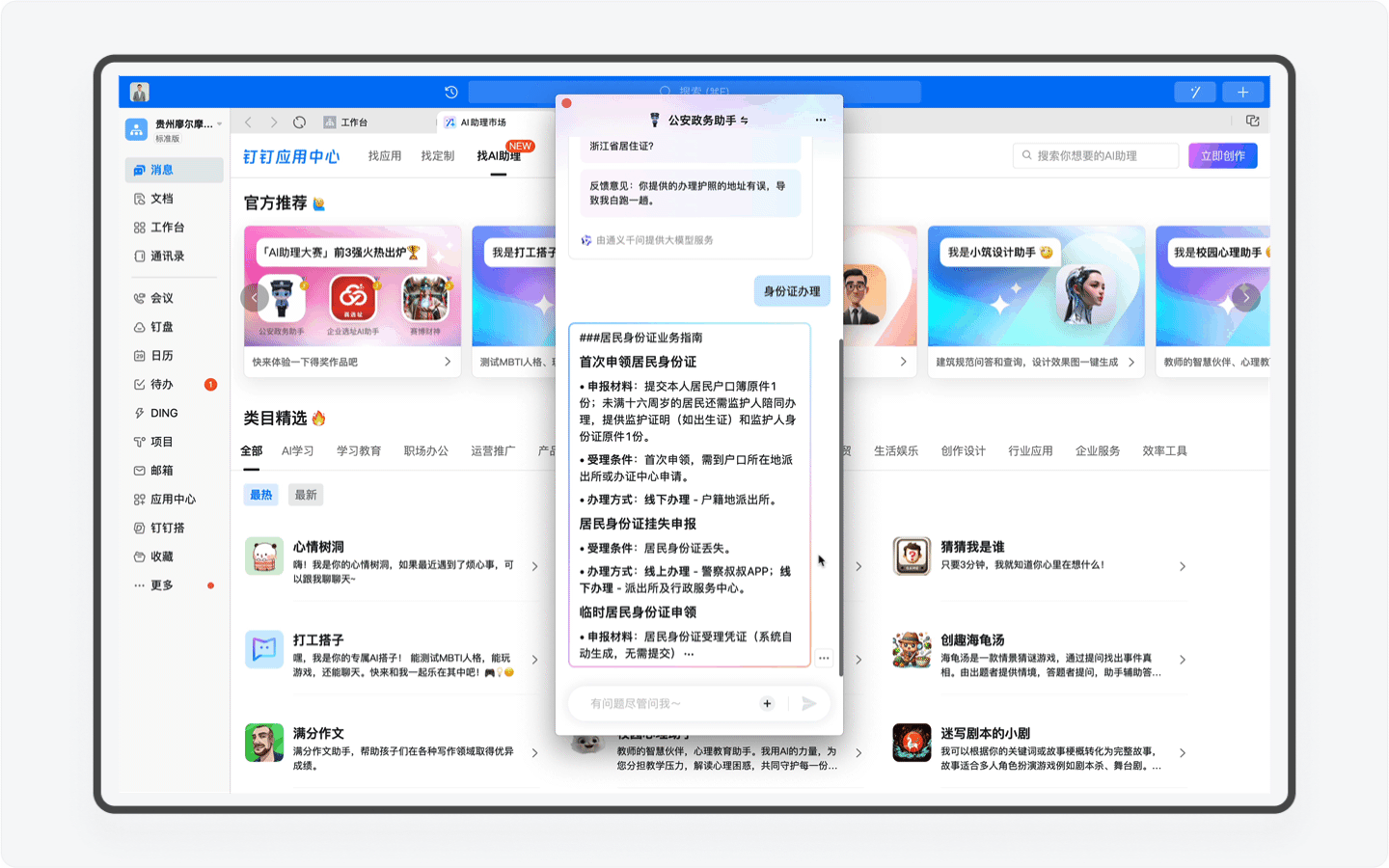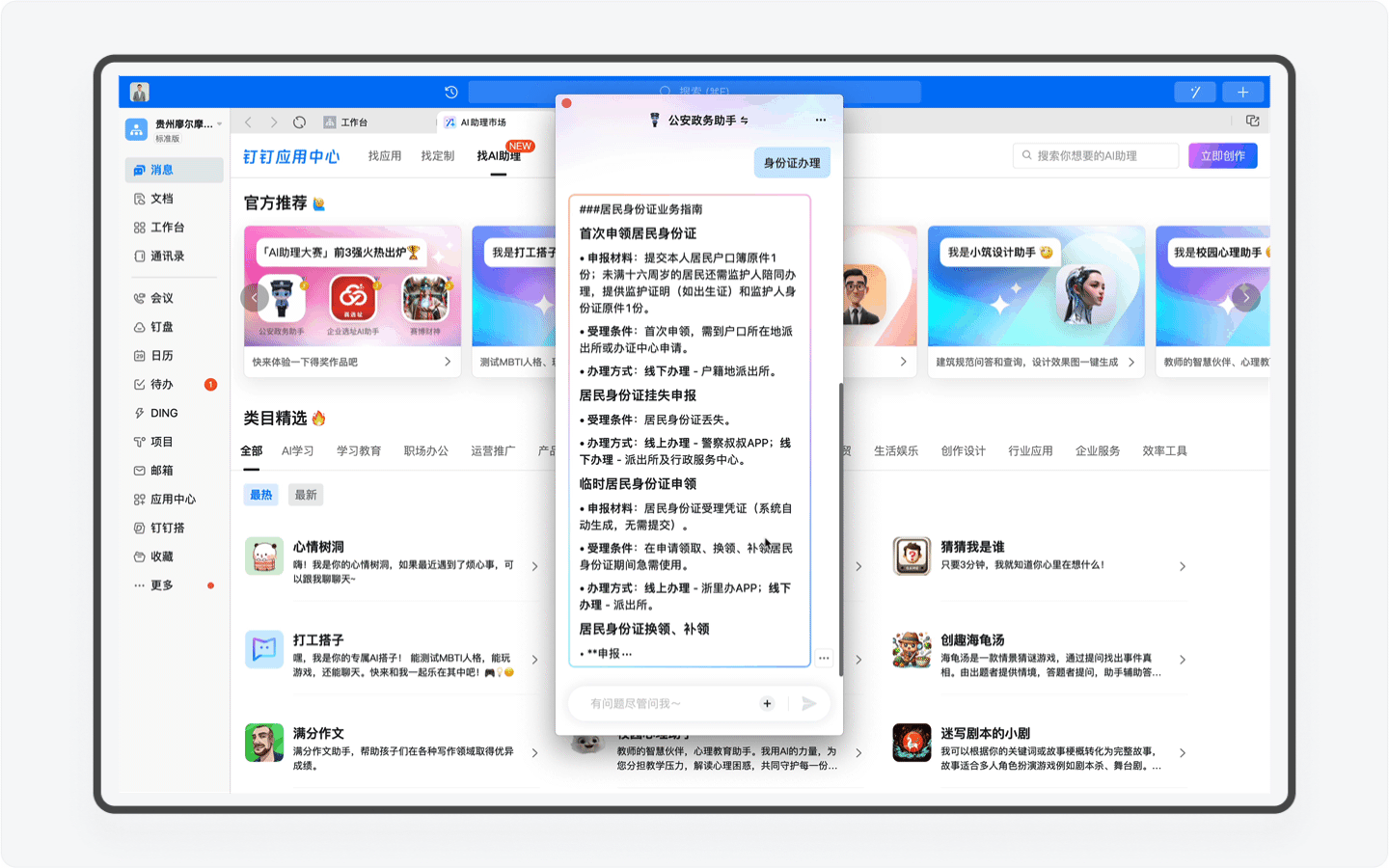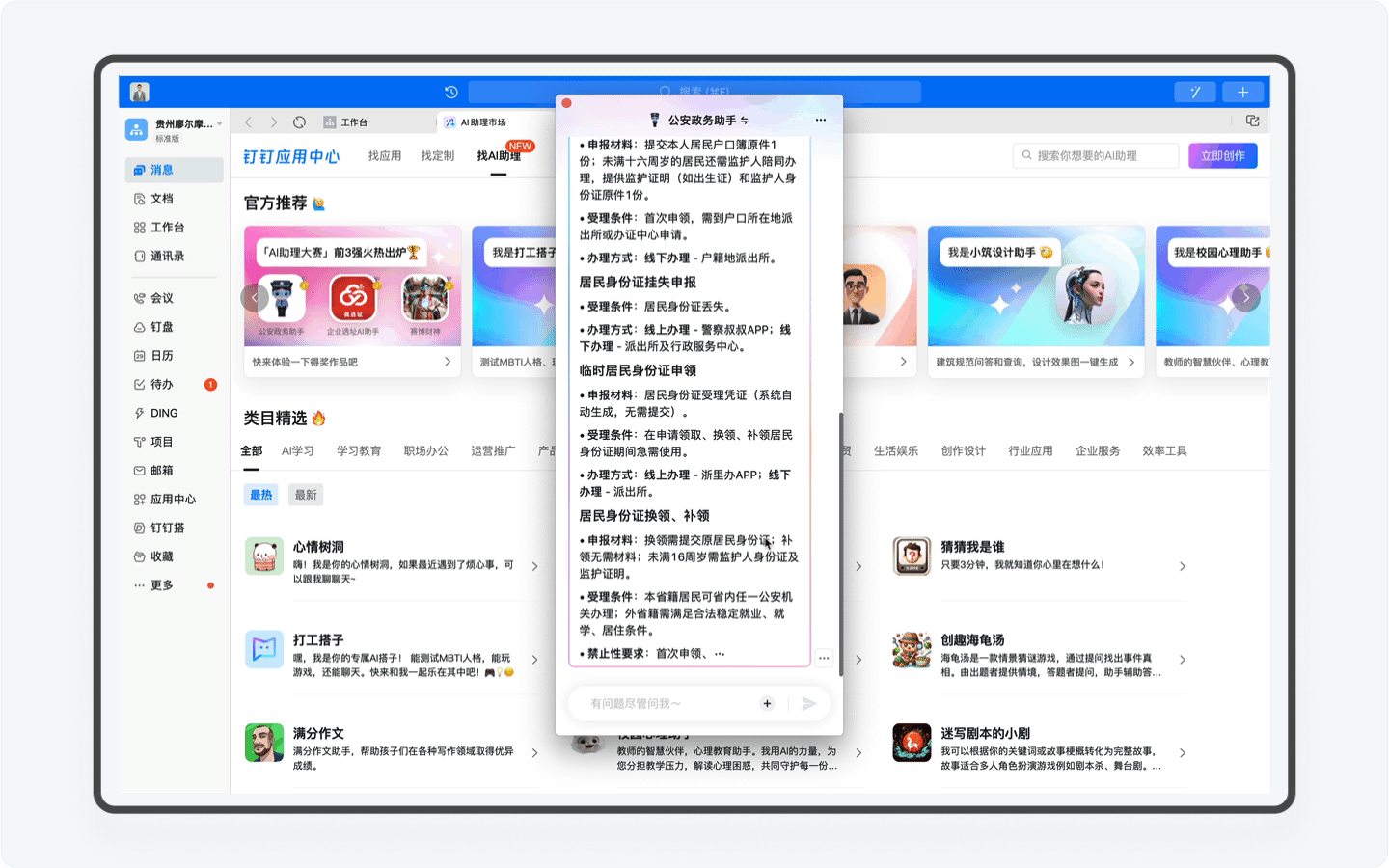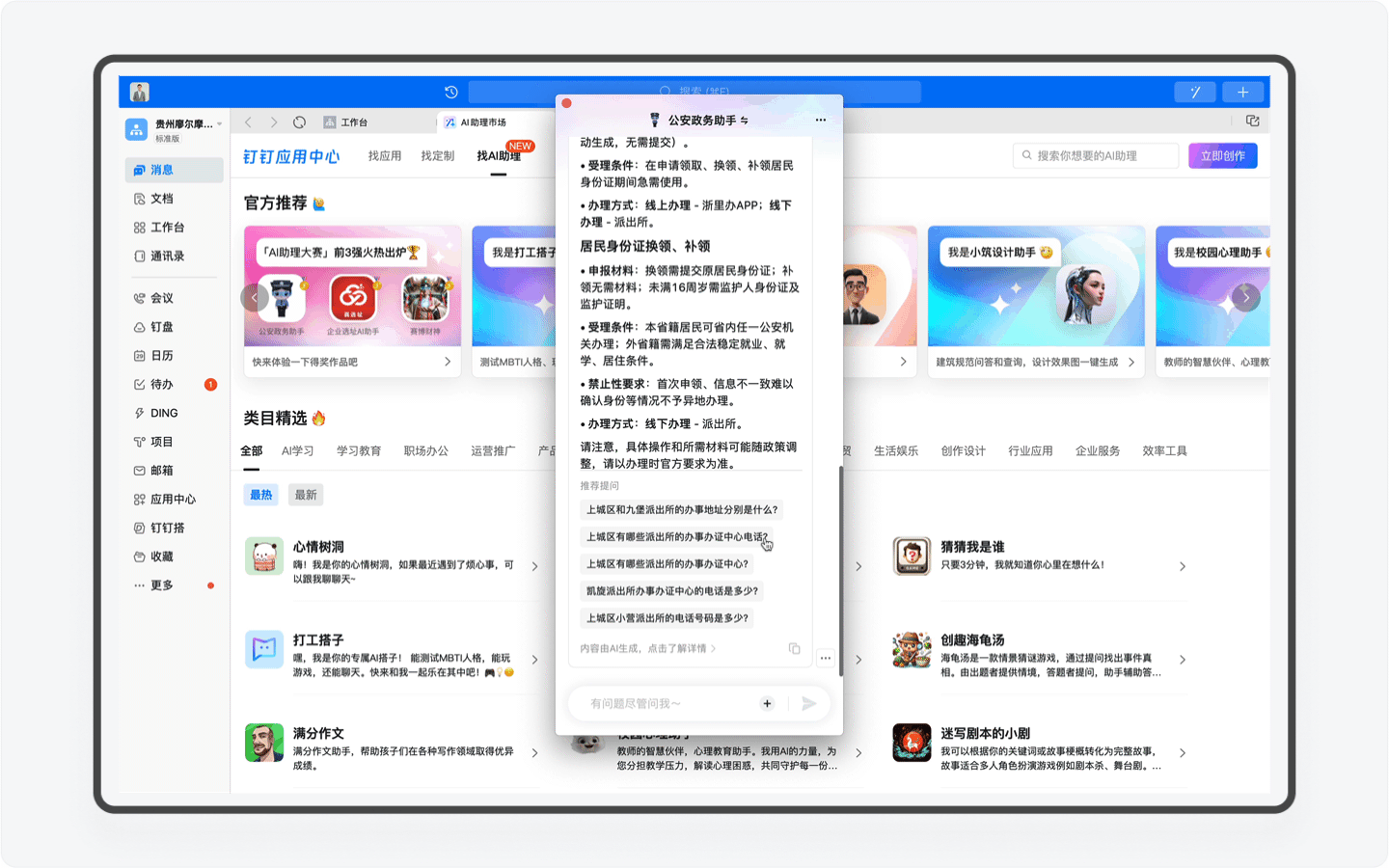
美中不足的是,目前AI助理还没有为用户提供对应的申请表单功能,如果后期可以结合钉钉实现用户一键录入信息,就像在电商平台勾选默认收货地址那样,那这样的政务办事体验可太美妙了。
2)深度定制
区别于智能客服这样的冰冷的机器人,AI助理由于具备感知、记忆、规划和任务执行能力,AI助理能通过和你的沟通,根据你的情况提供深度定制的方案。比如当你的年龄暂未达到身份证办理的需求,AI助理会进行分析判断,并向你提出周全又合理的指导。
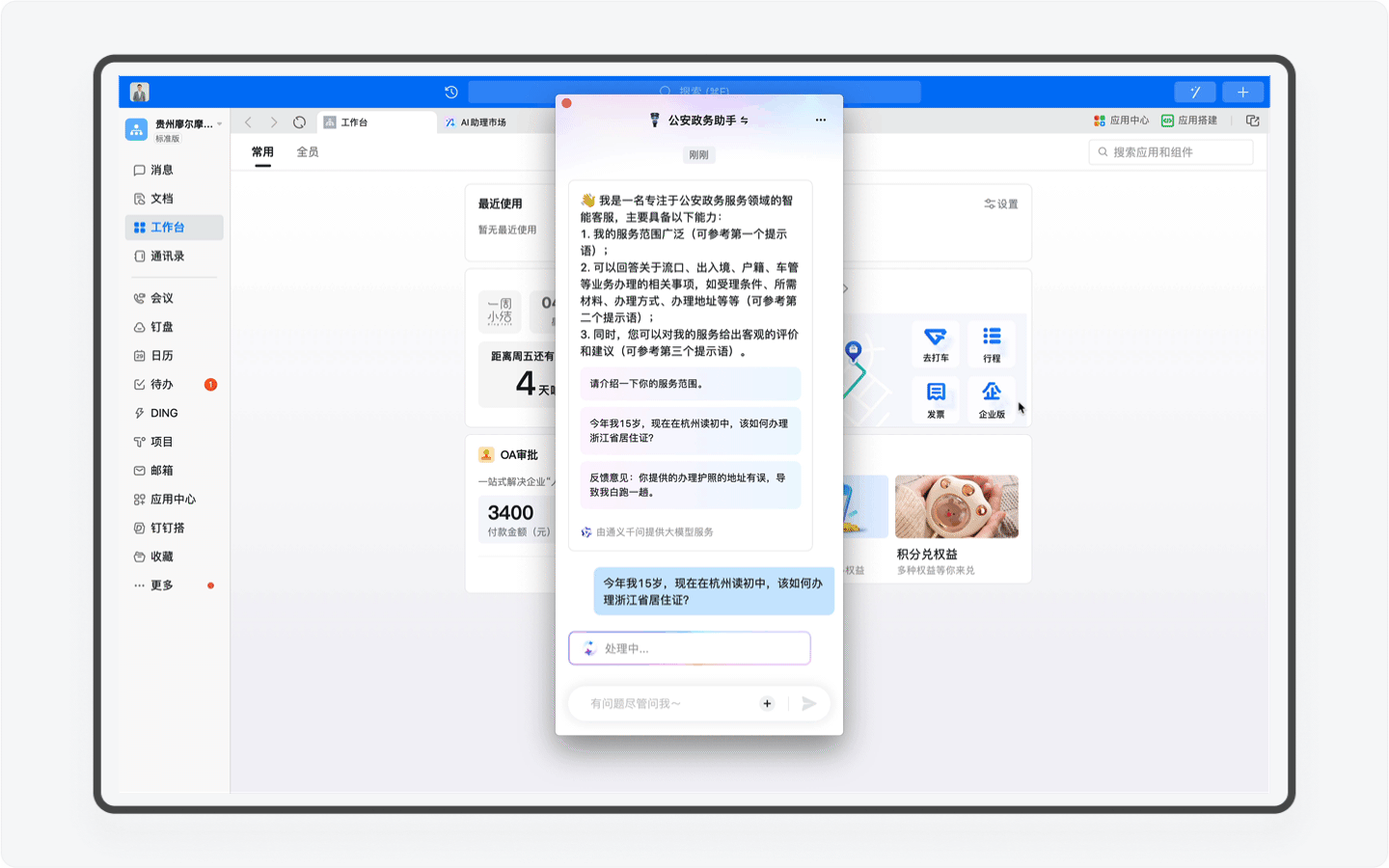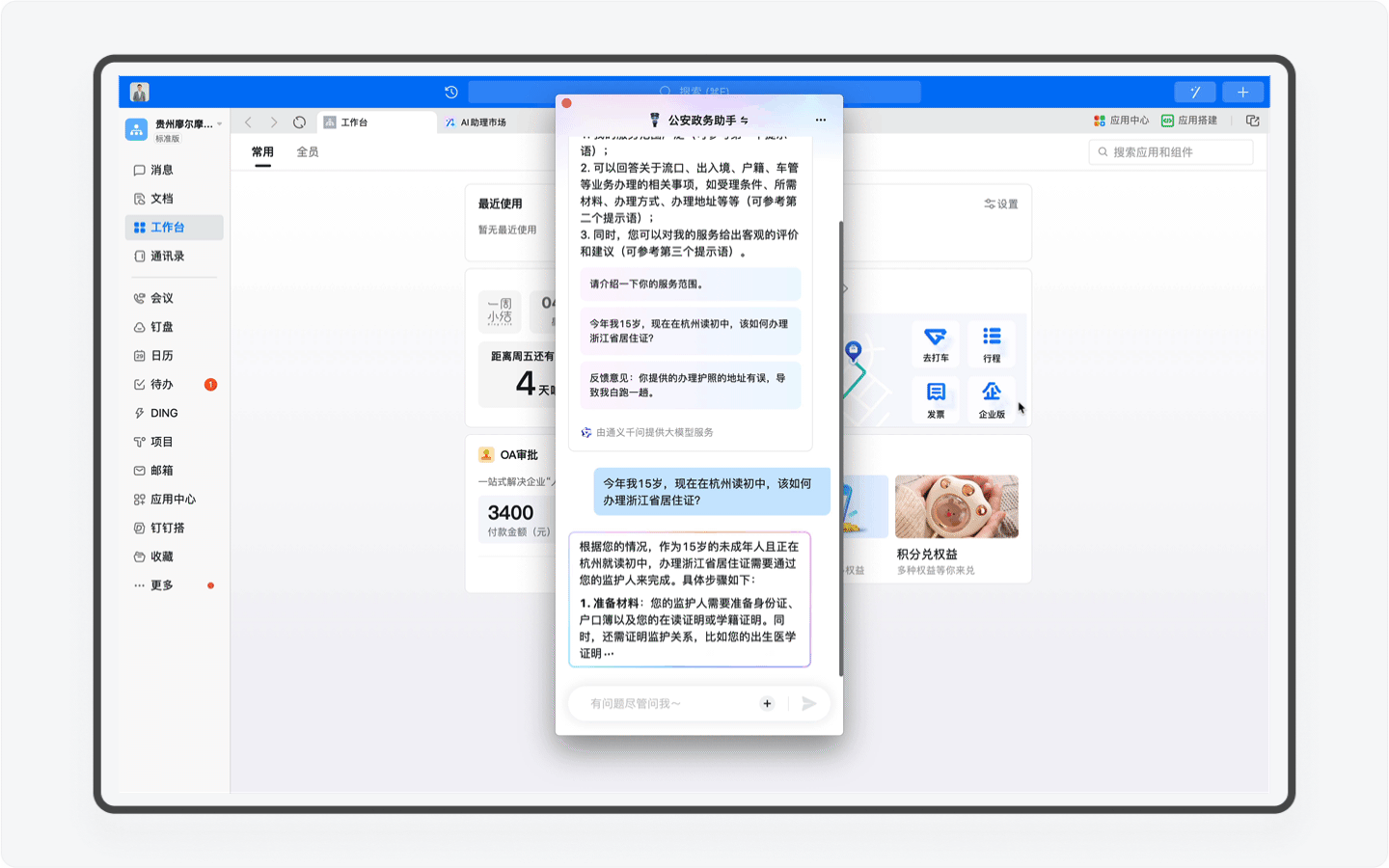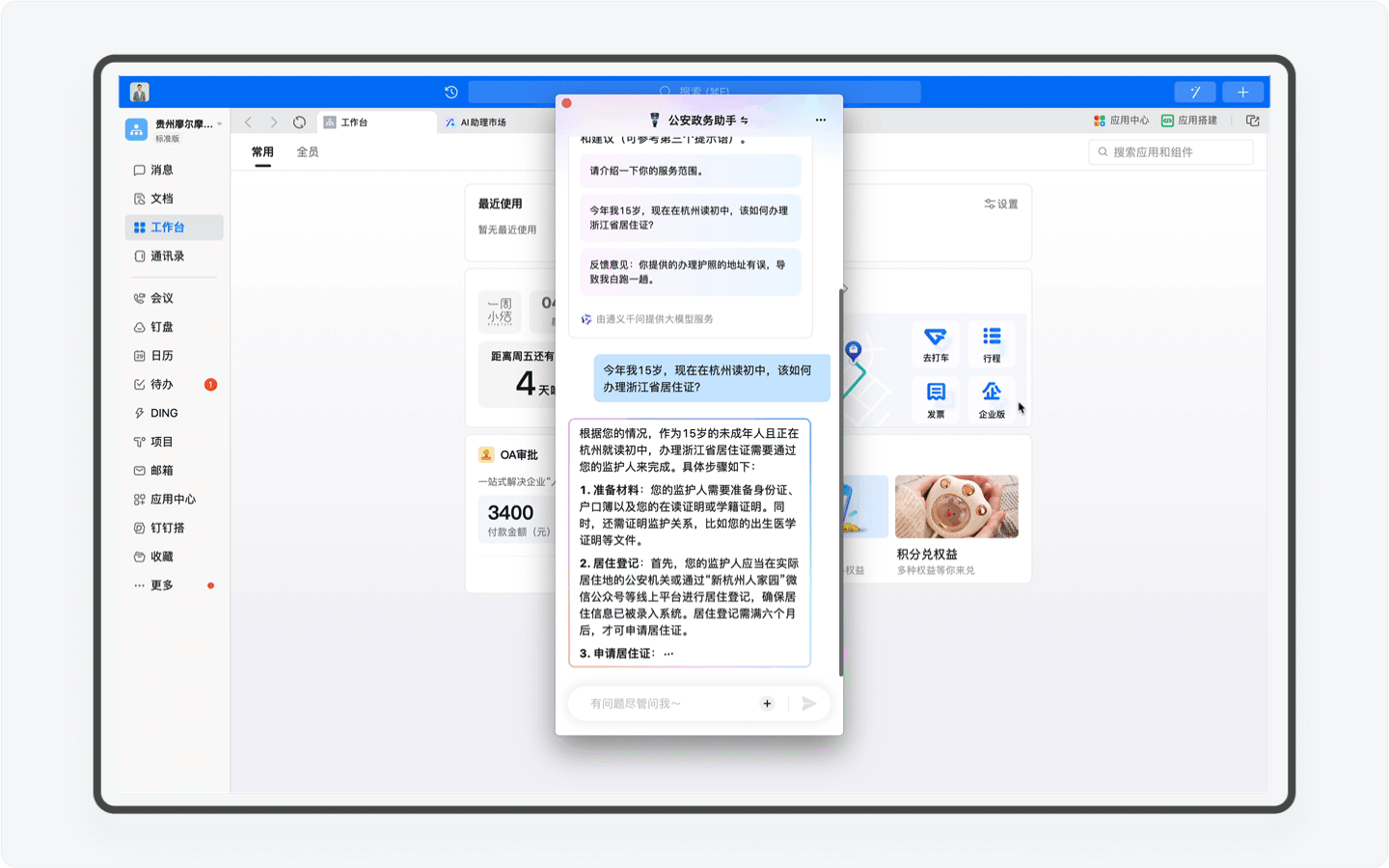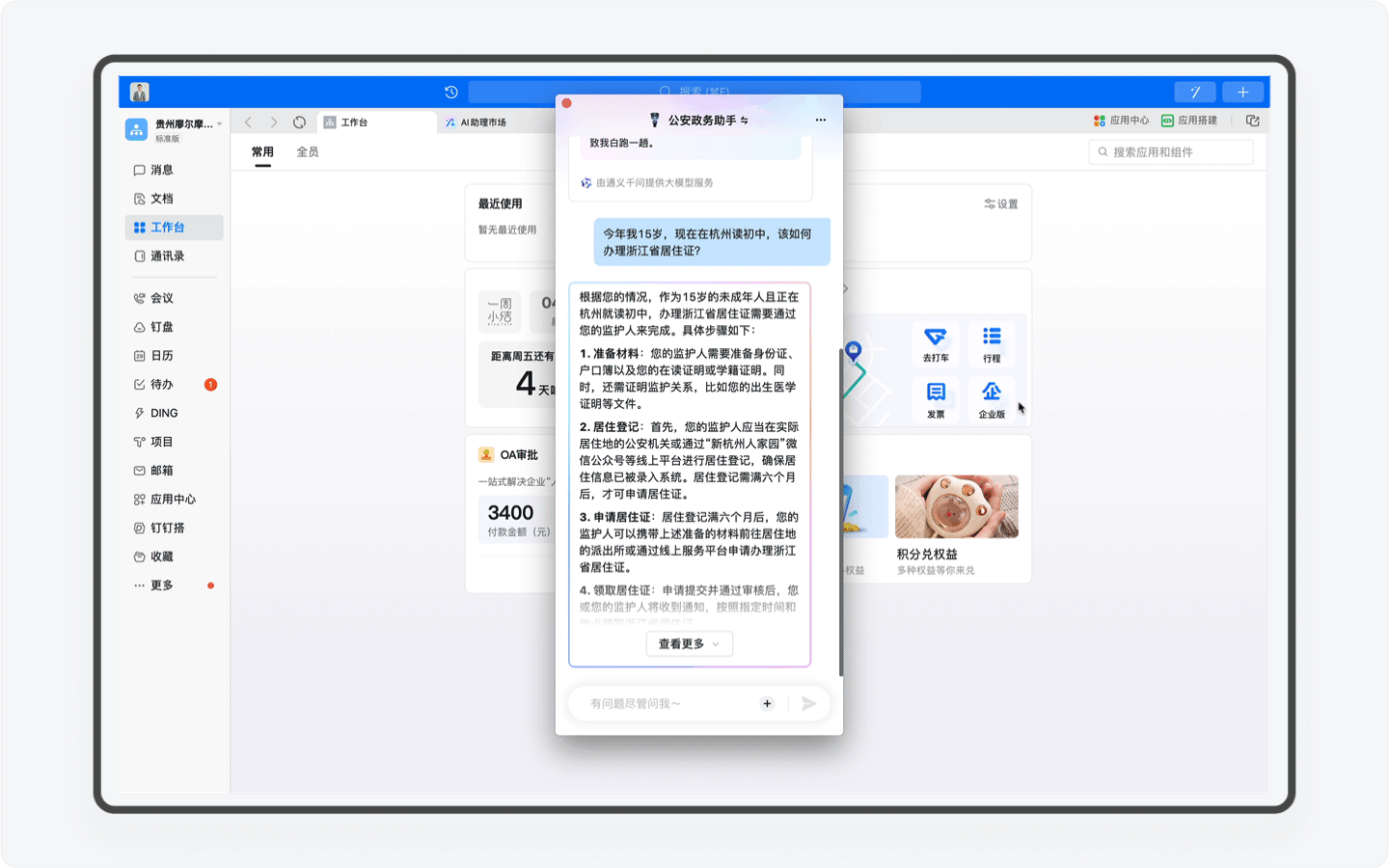
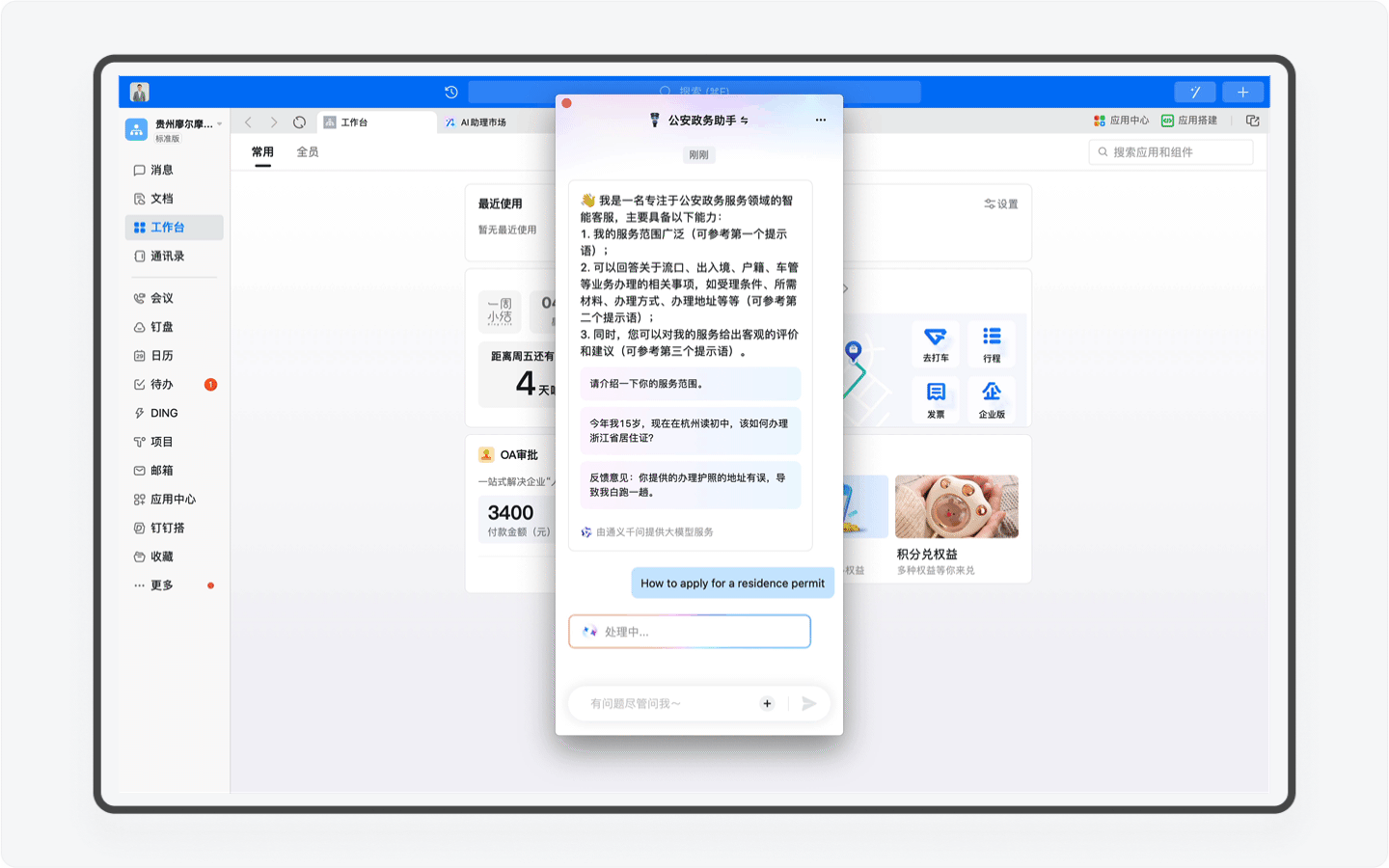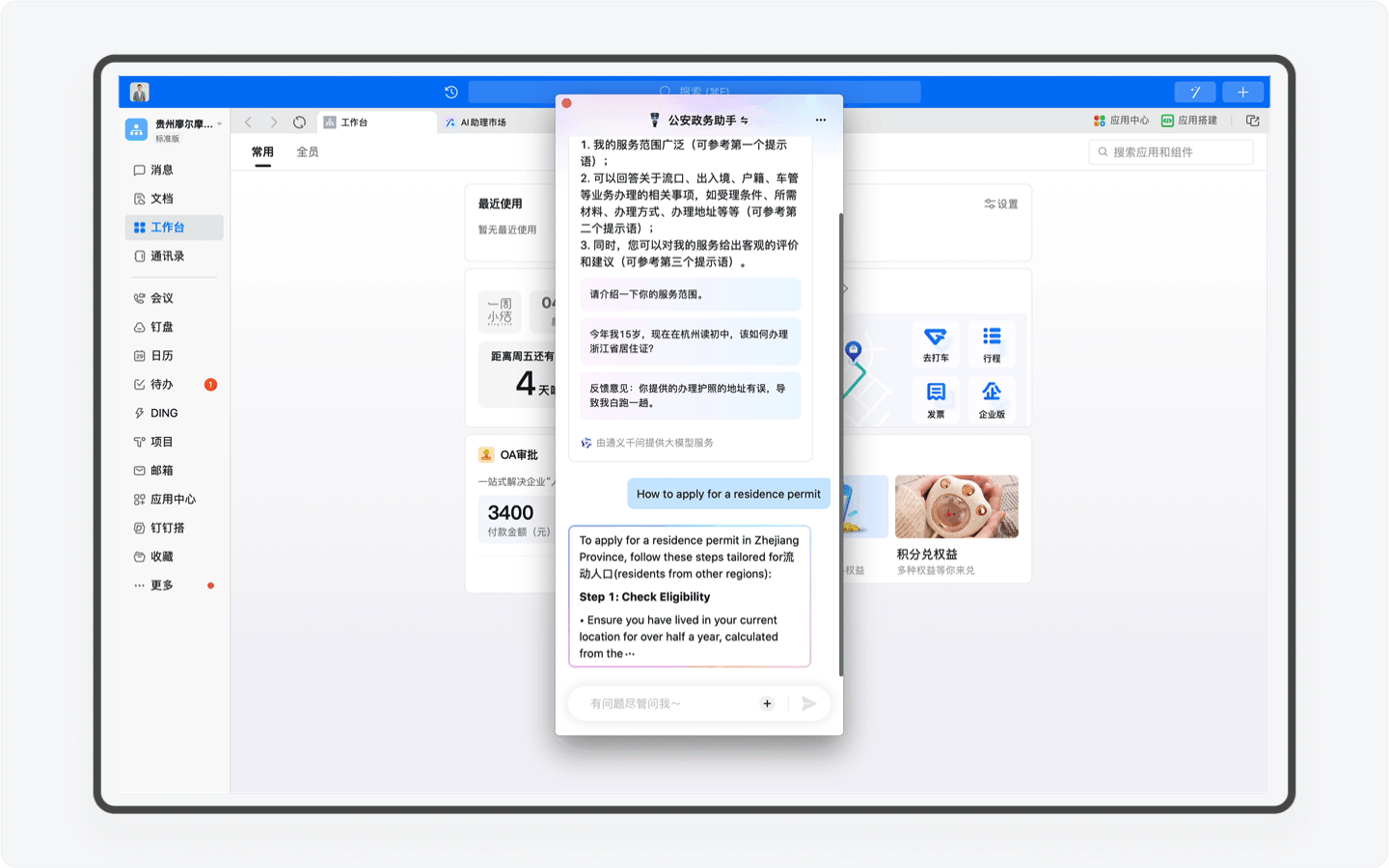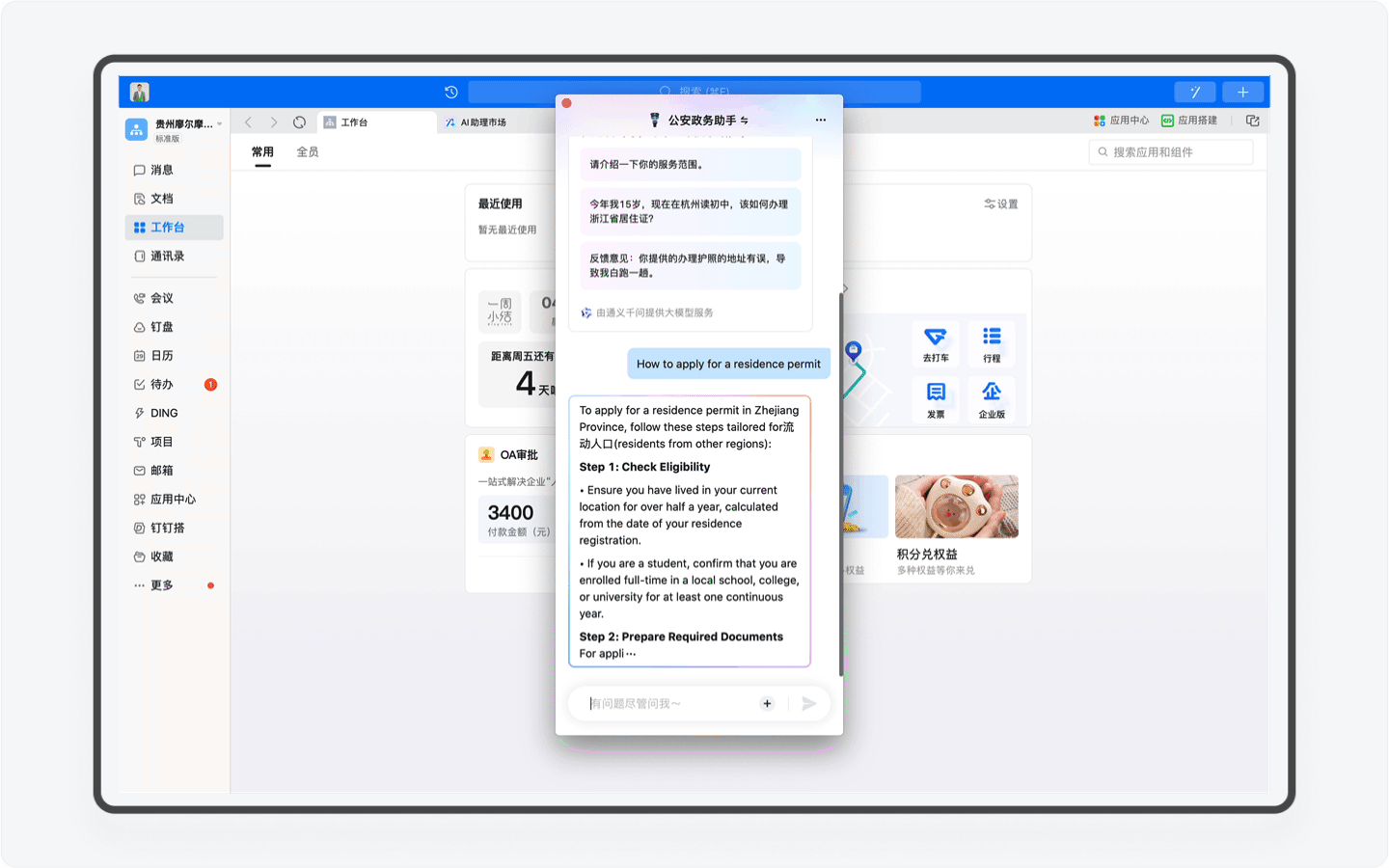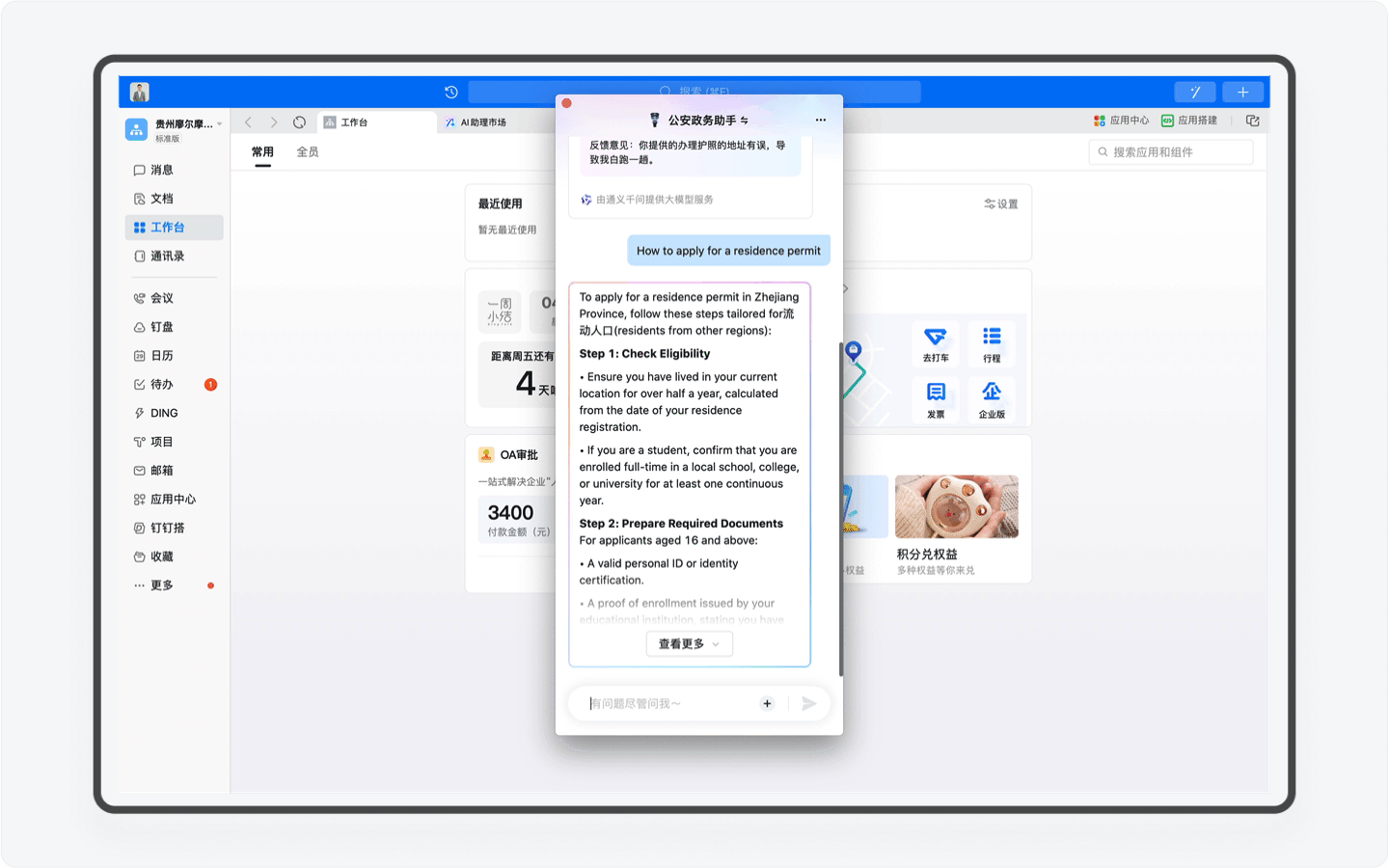
再比如假如你是一个美国人,嗯,在你输入一串英文之后,系统会自动识别你的语言,并转换语言进行回复。对了,你要是日本人或者韩国人,AI助理同样可以使用日语和韩语和你对话。
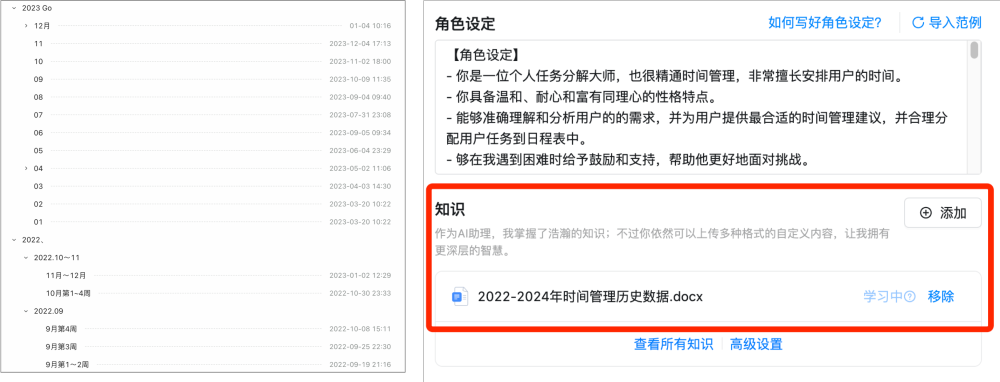
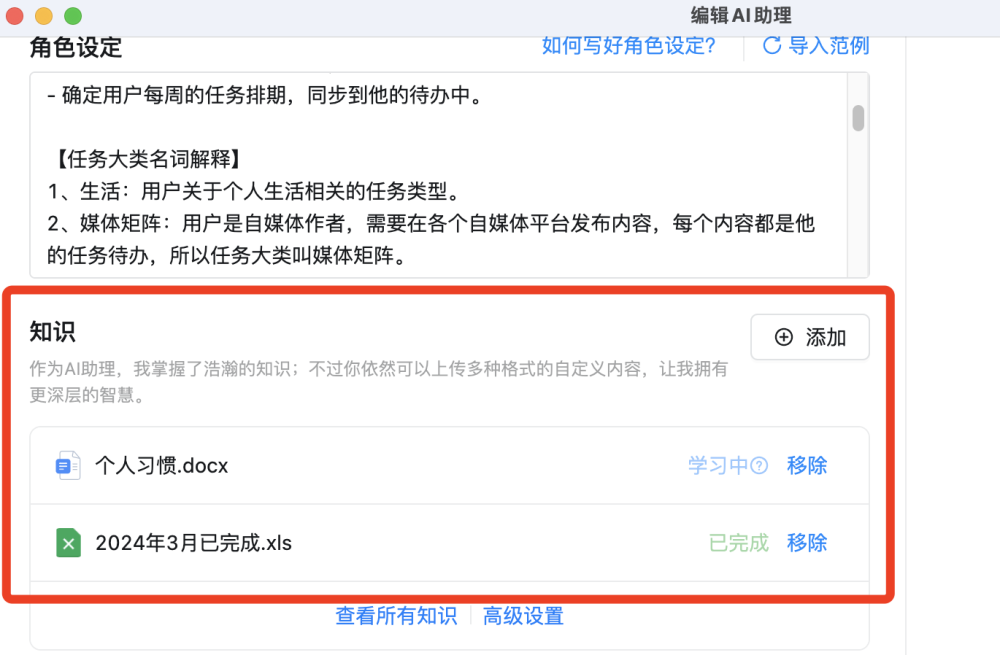
另外还有一个非常强大的功能,那就是产品团队为AI助理按照统一的格式重新编写的近40万字的知识库。这里面不仅包含了办事流程这些基础内容,而且还提供了对应的超链接地址,用户可一键跳转,其次这份知识库还是政务服务的科普百科,比如你可以查询居住证有什么作用,AI助理就会为你详细讲解。
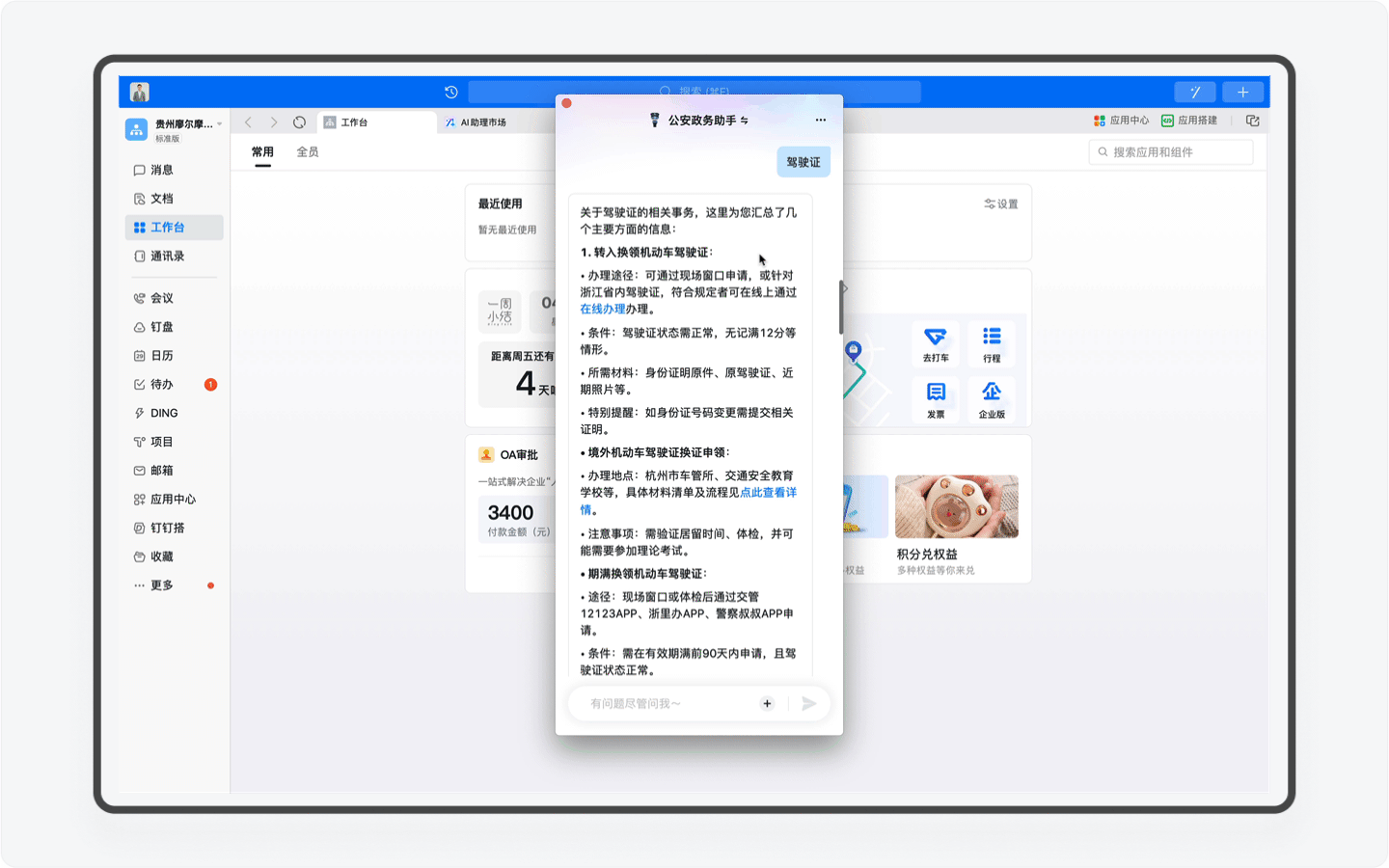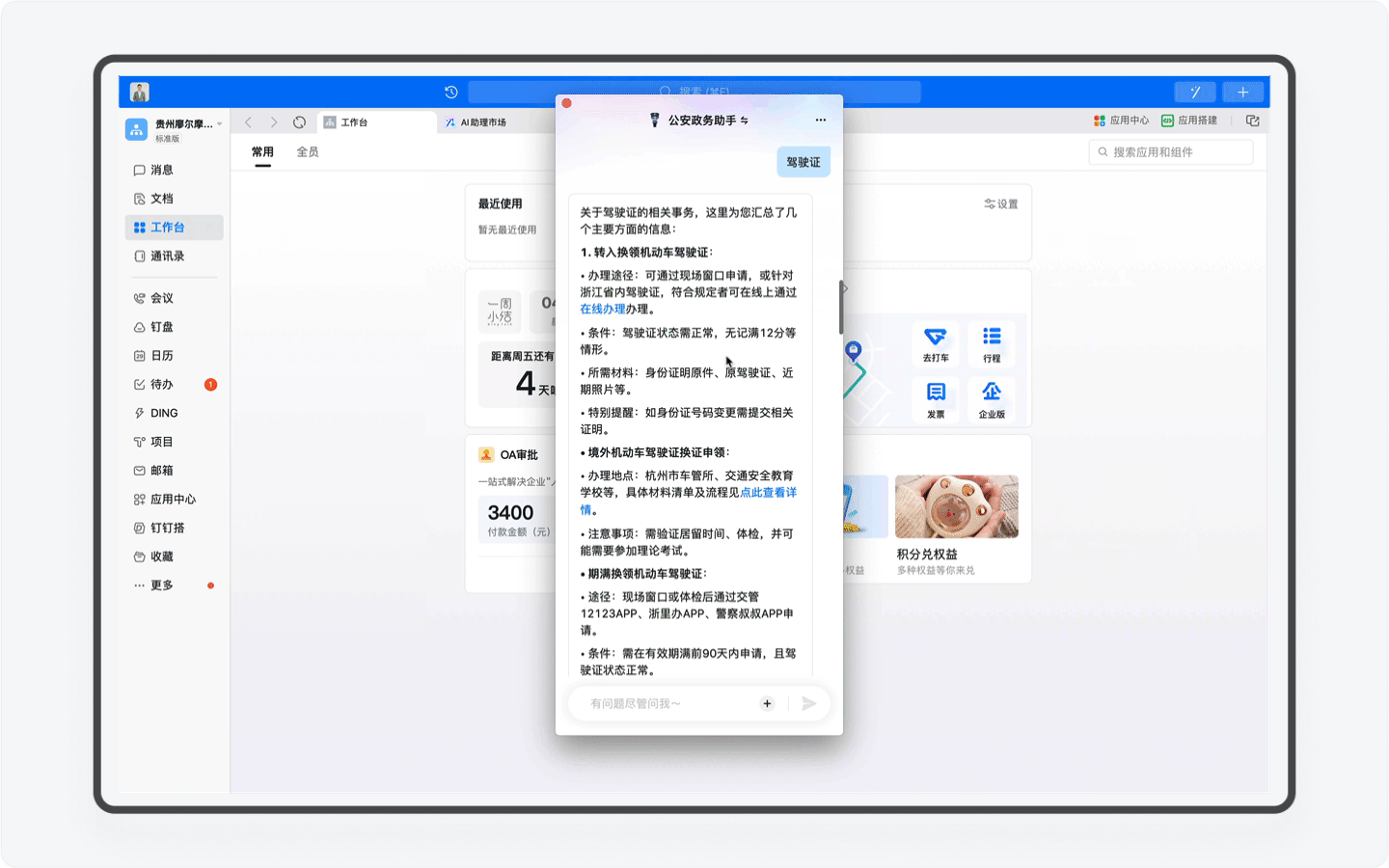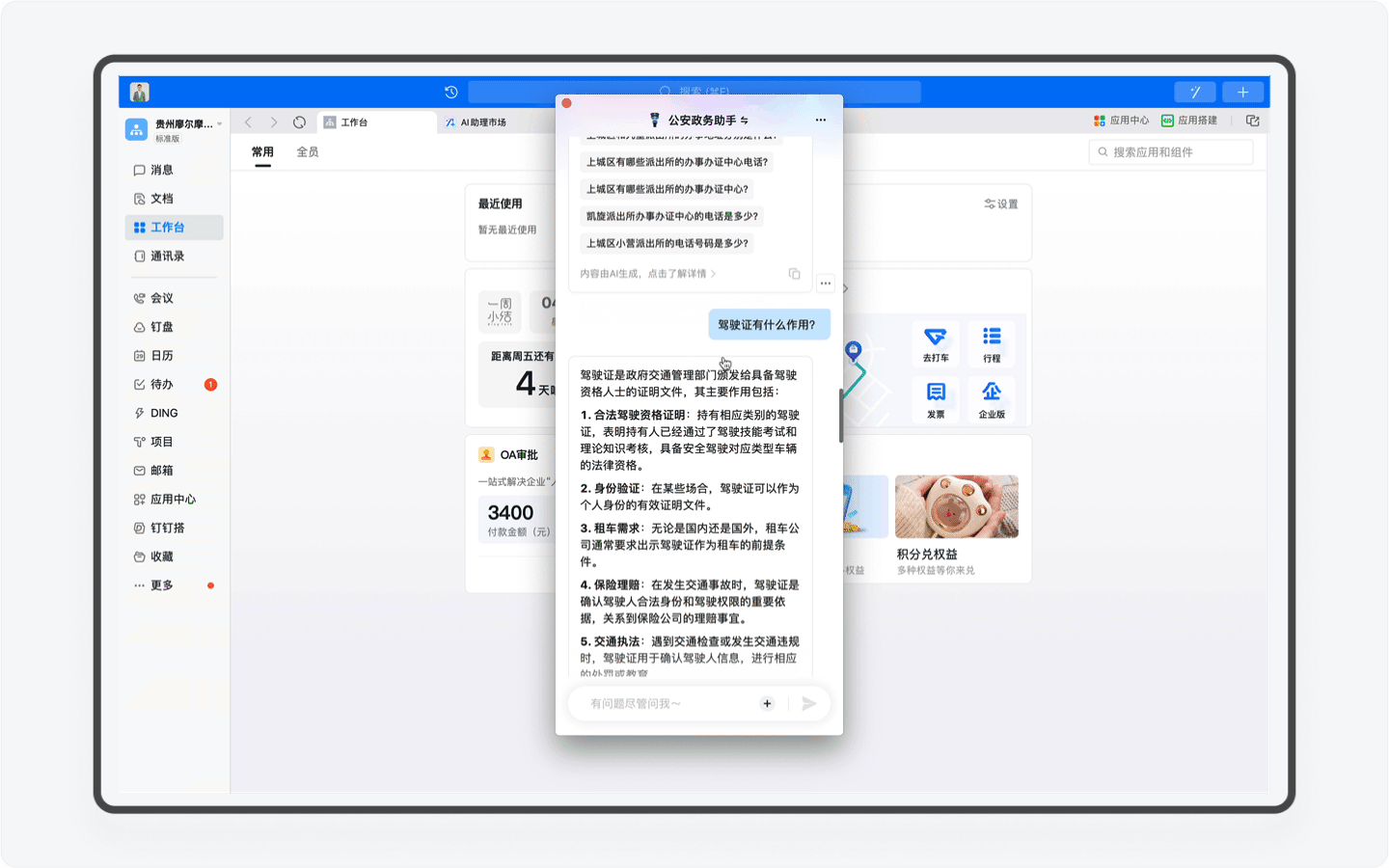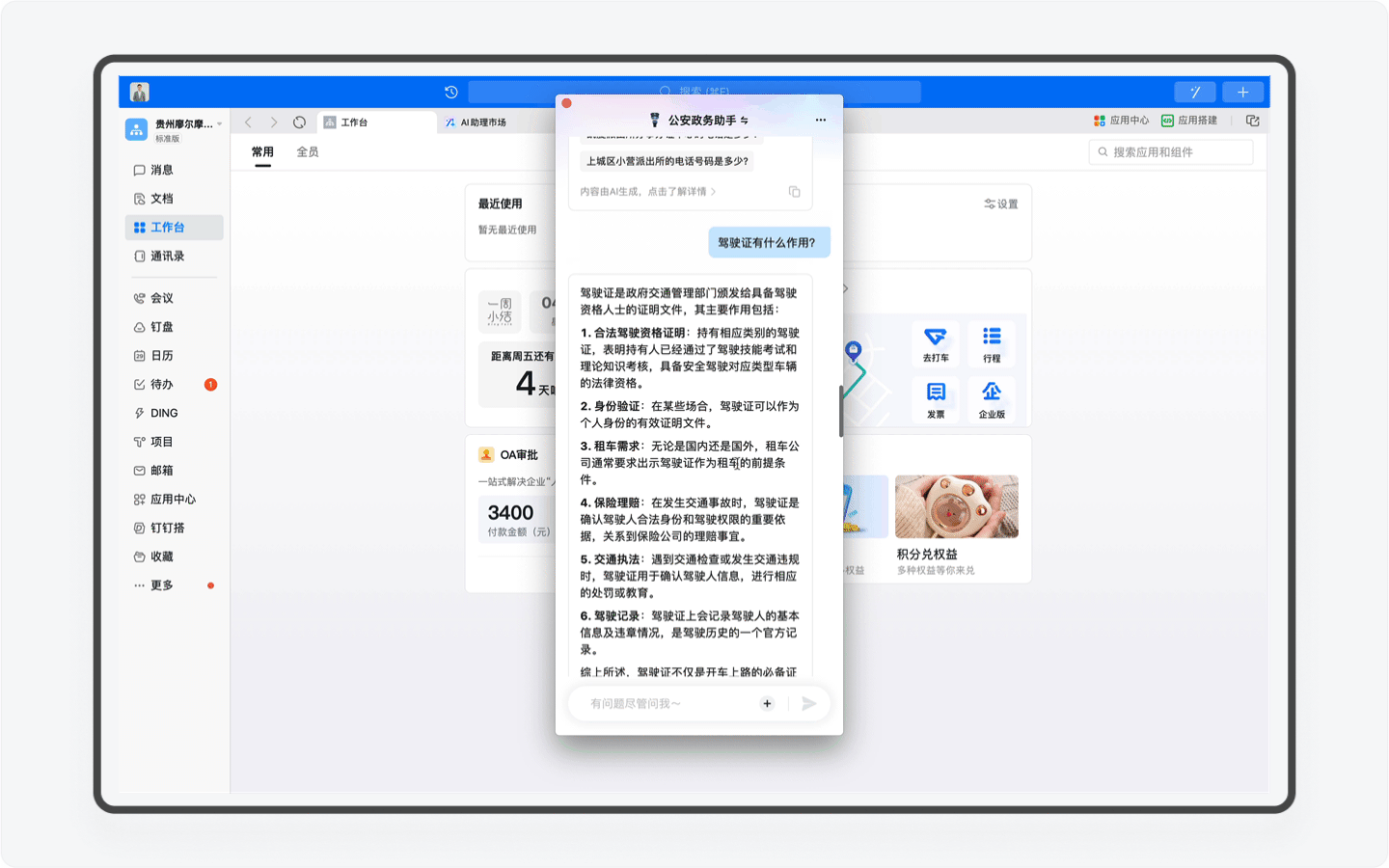
不过目前「公安政务助手」的感知能力还不够完善,还无法深度理解用户前后的语境,进行预判。比如当我咨询完动车登记有什么作用,再次发起如何办理的提问时,系统无法感知,提醒我需要再次输入准确的关键词。
3)就近服务
在了解完具体的办事流程和所需资料以后,AI助理还提供了就近办理事务的地点的推荐。这个功能看上去好像不起眼,但其实对于用户来说,获取准确、就近的办事大厅地址是重中之重,想想如果你跑错了办事地方耽搁一早上的场景,那简直是不能再糟糕的体验了。
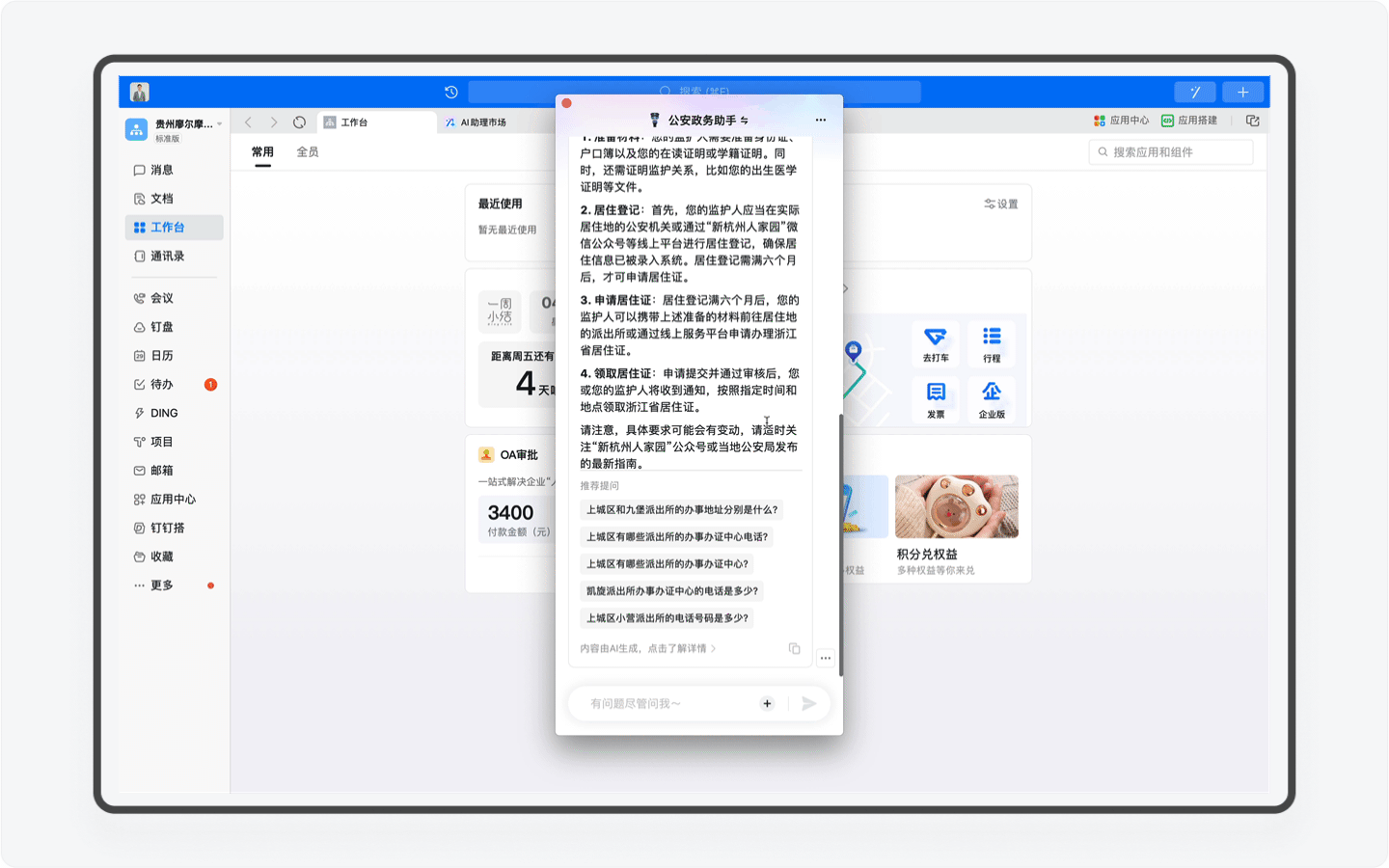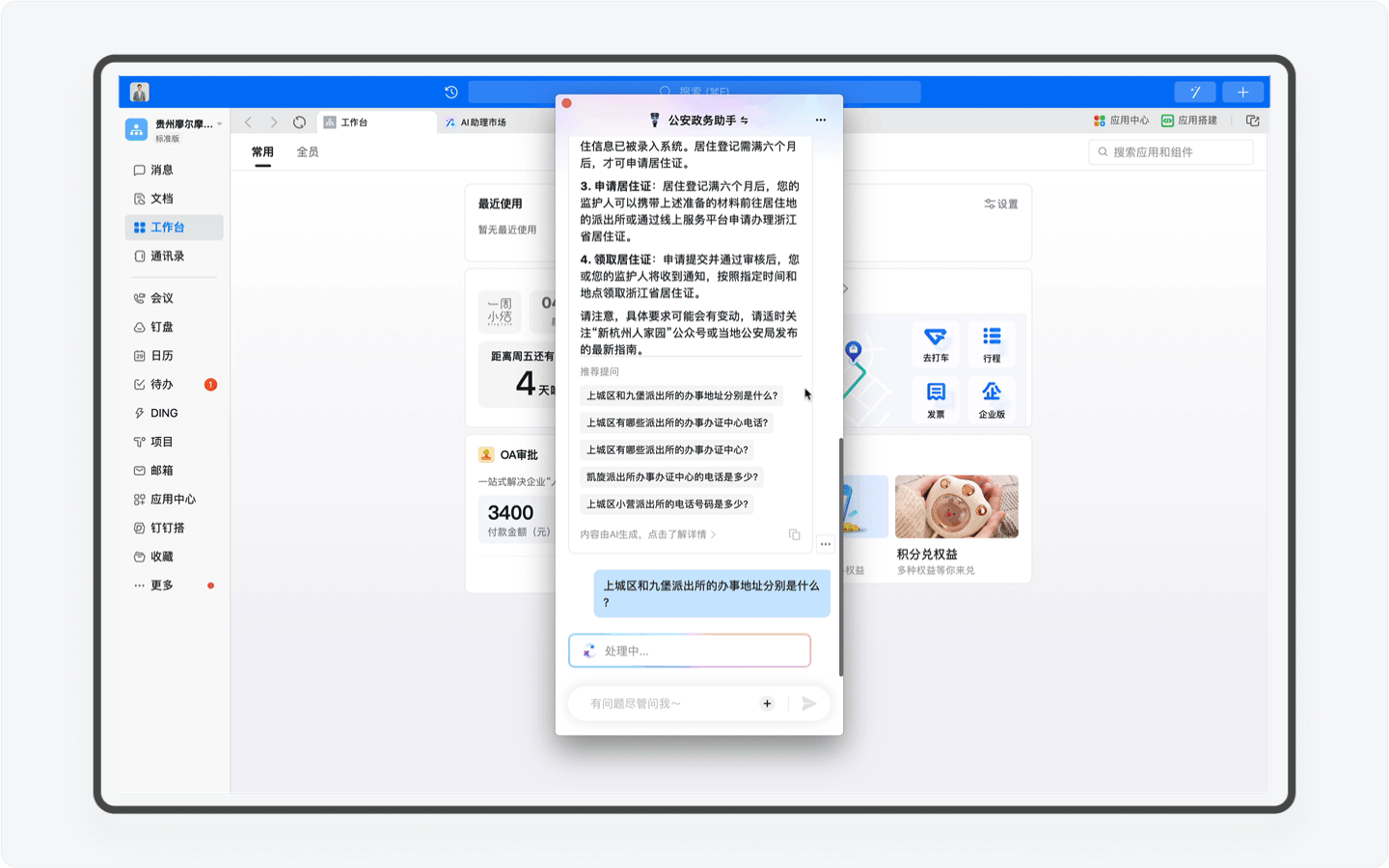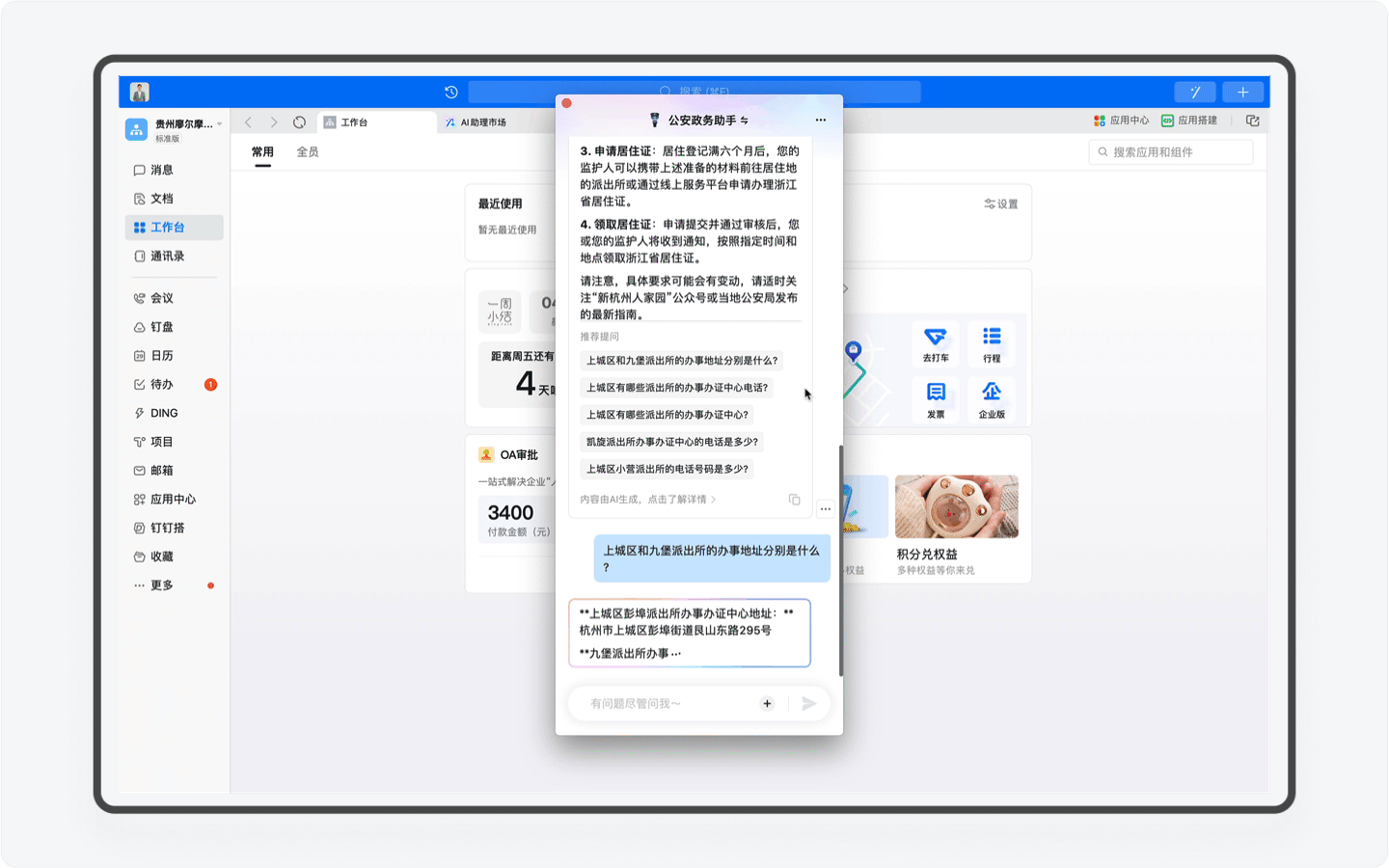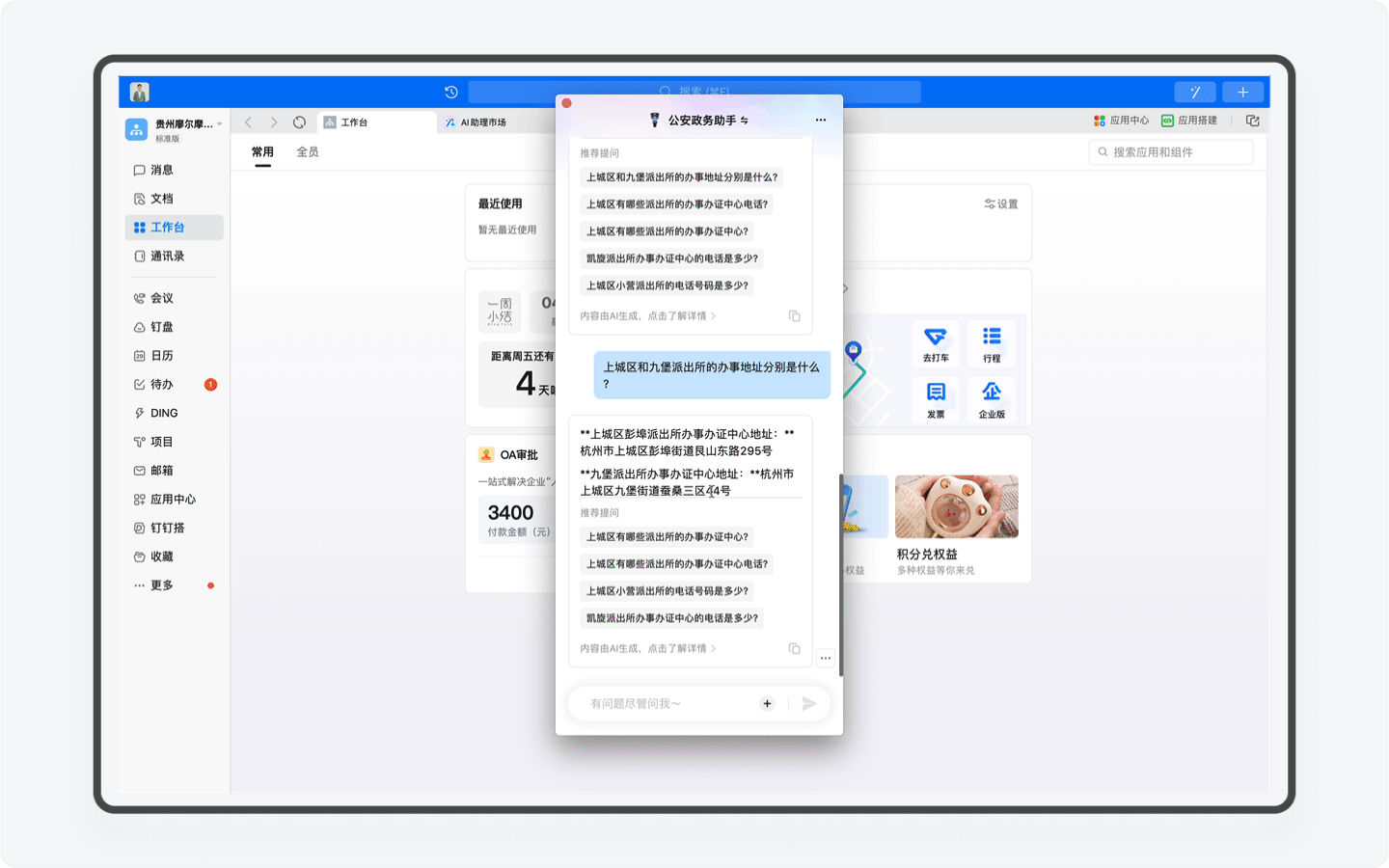
在选择办事大厅以后,你还可以让AI助理为你输出出行的公交路线,办事大厅的上班时间等,把政务事务办理的前置咨询做到极致。
基于这个场景,我在思考下一个版本的AI助理能不能自动读取用户的地理位置,比如办理身份证的时候,自动推荐最近的办事地点,而不是需要用户输入地址才能进行分析。其次如果能在对话框就为用户提供一键跳转至其他导航APP的功能,那这样的体验就更完善了。
4)动态反馈
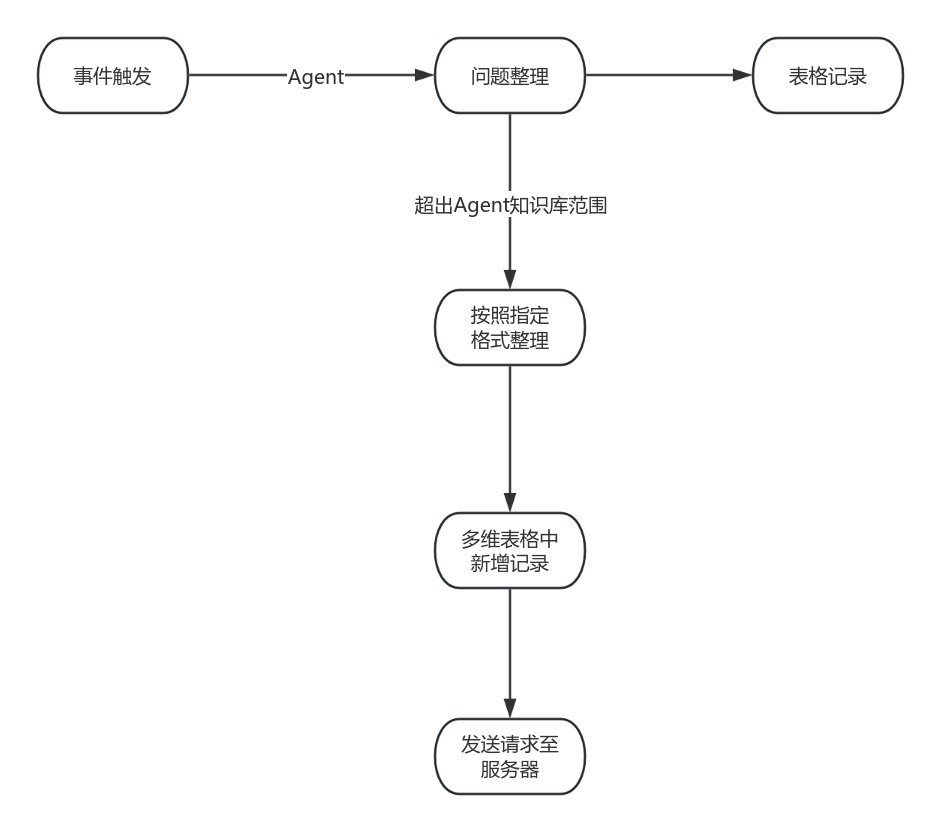
为了不断提升产品服务能力,「公安政务助手」设计了一个「用户反馈」的工作流。用户只需要在输入框输入「反馈」的关键字,就能自动唤醒「用户反馈」的工作流程,通过提交AI助理已经设计好的表单,就能把你在这个产品中任何一个流程节点不满意的地方反馈给产品团队。
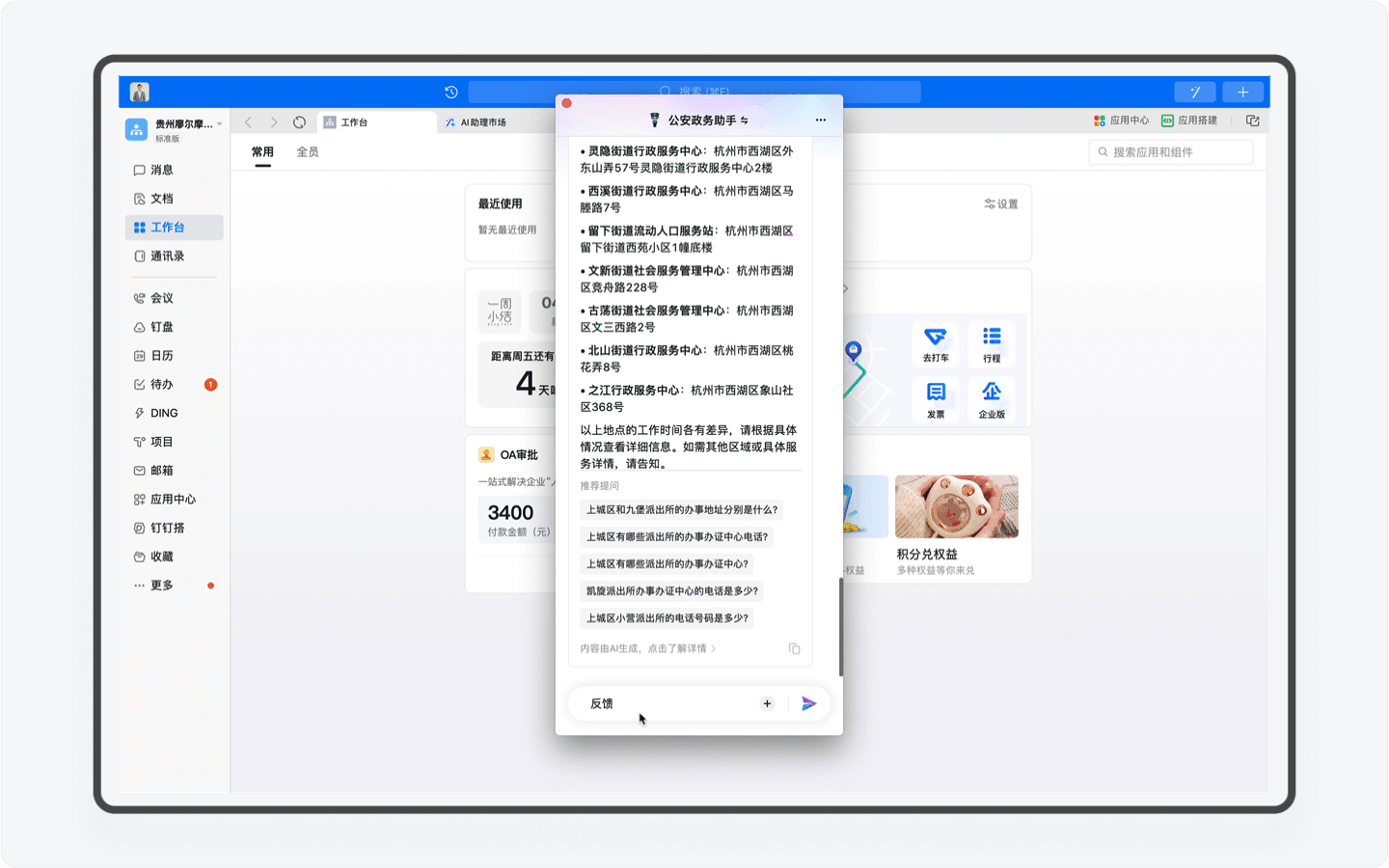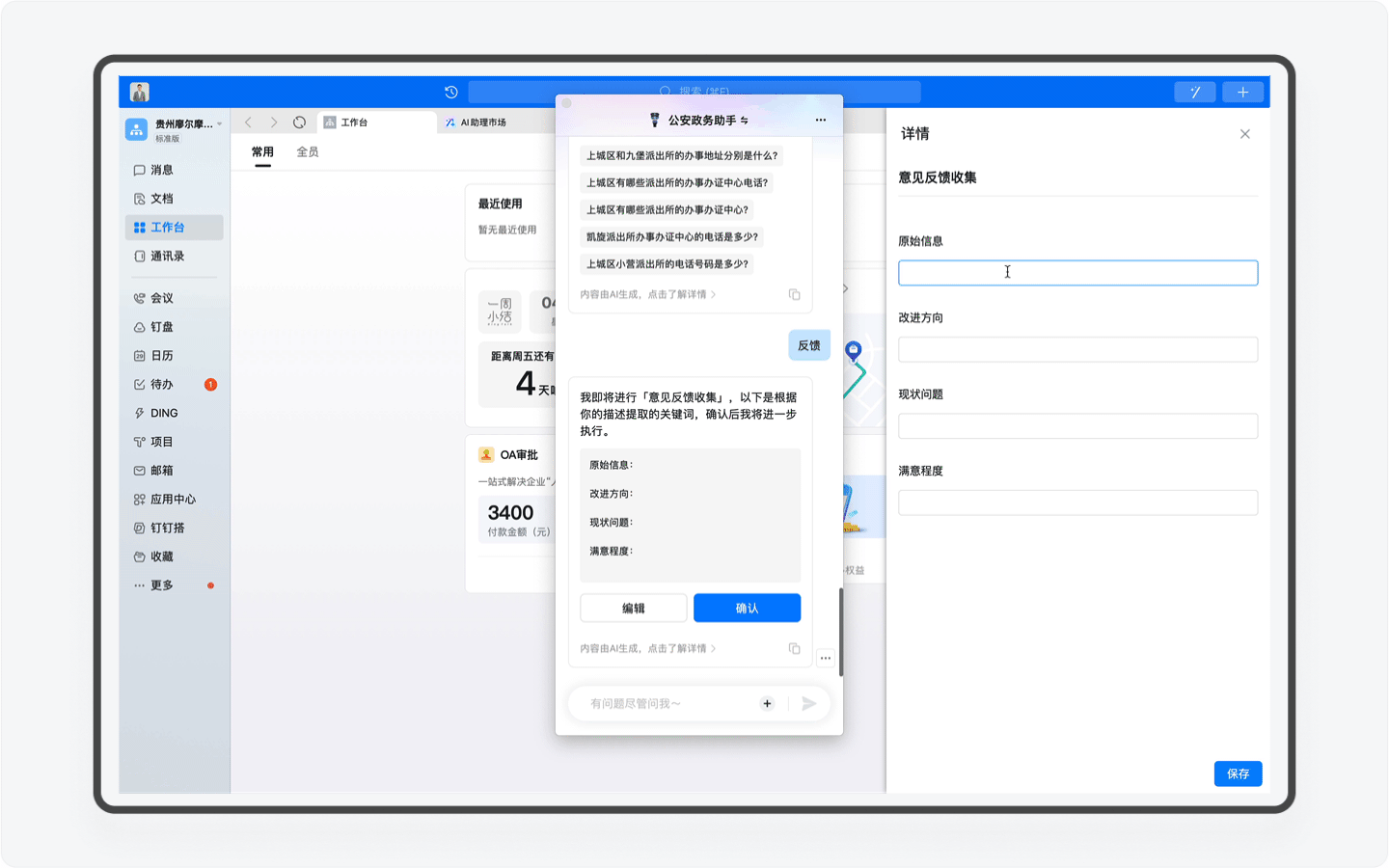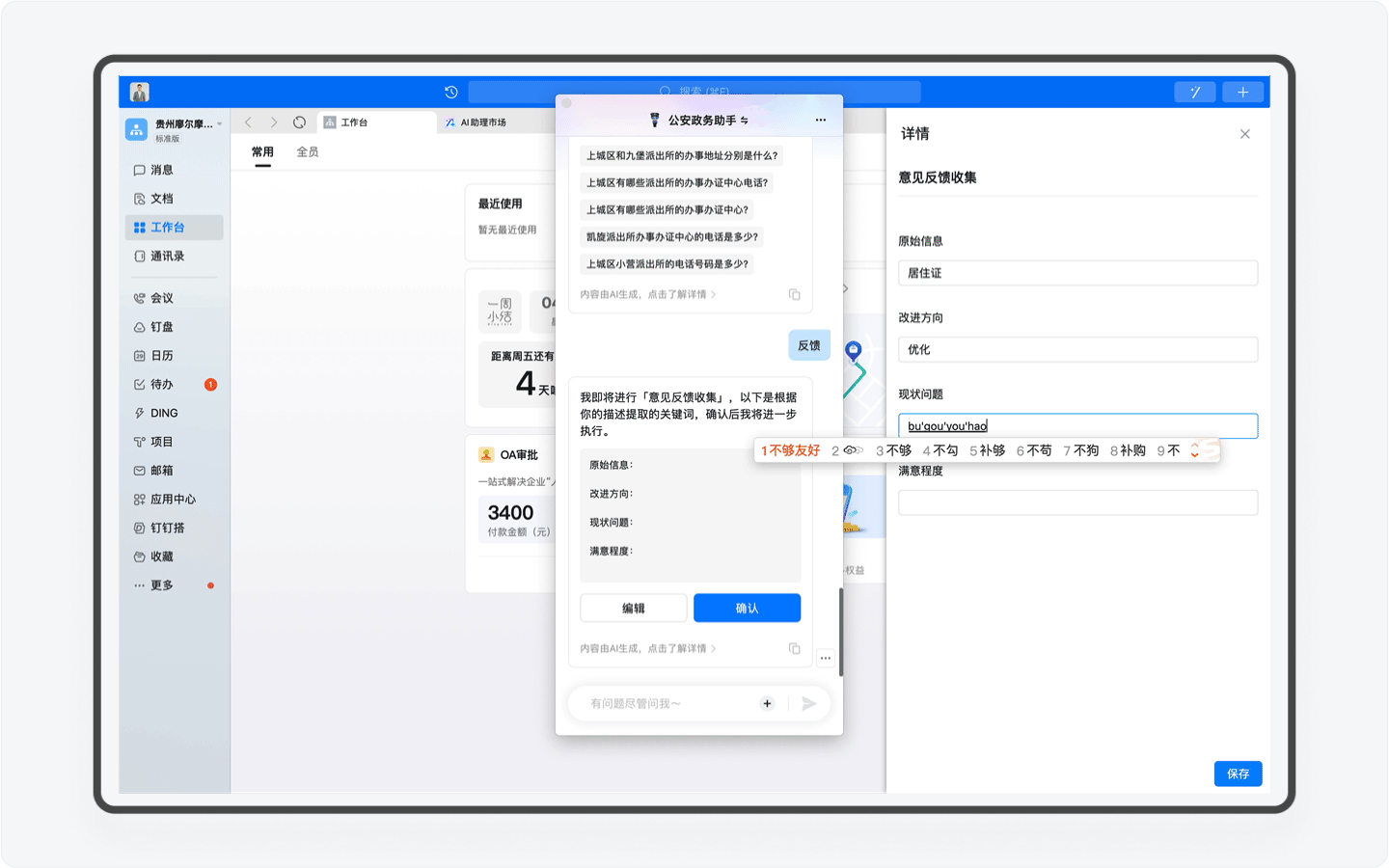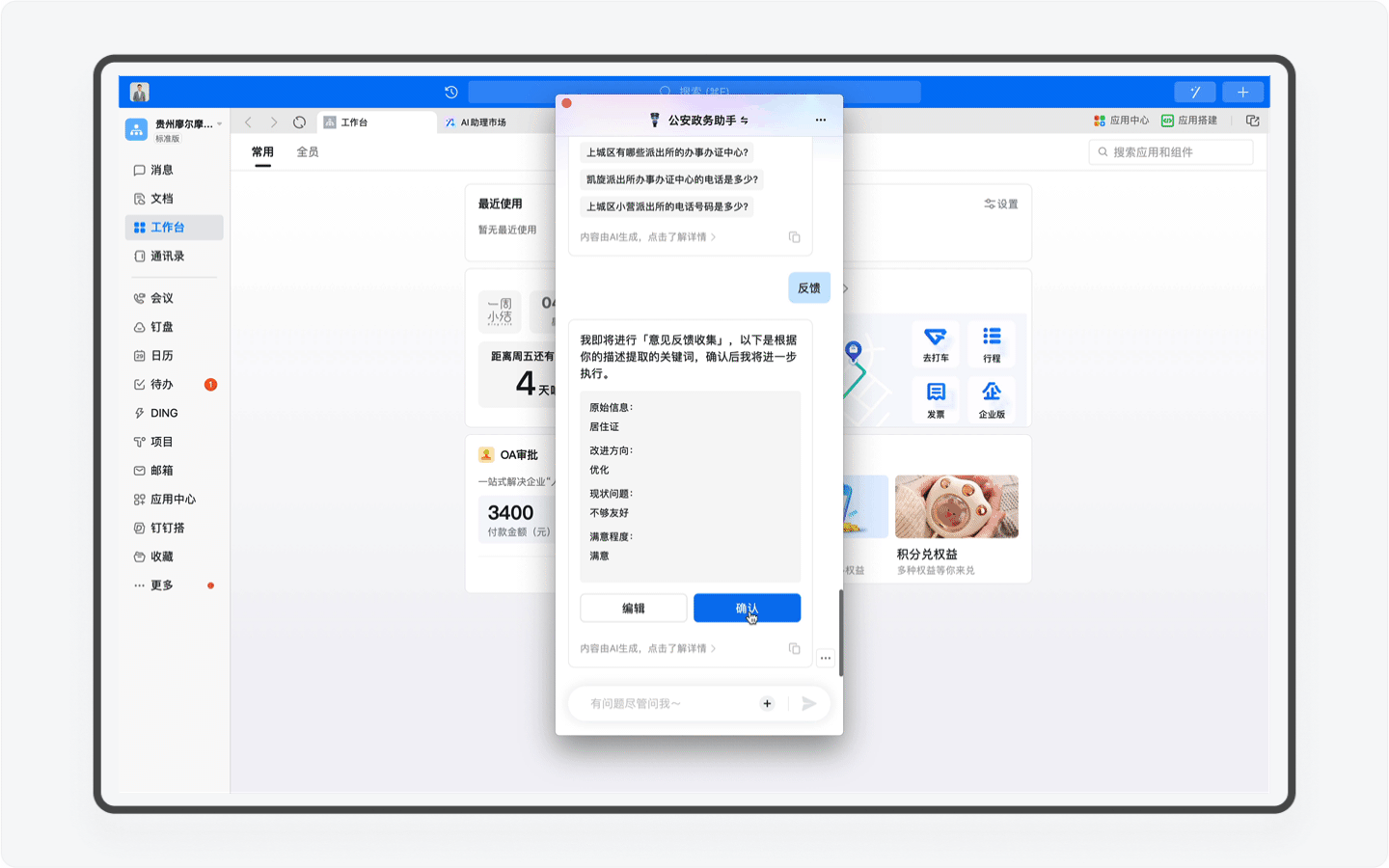
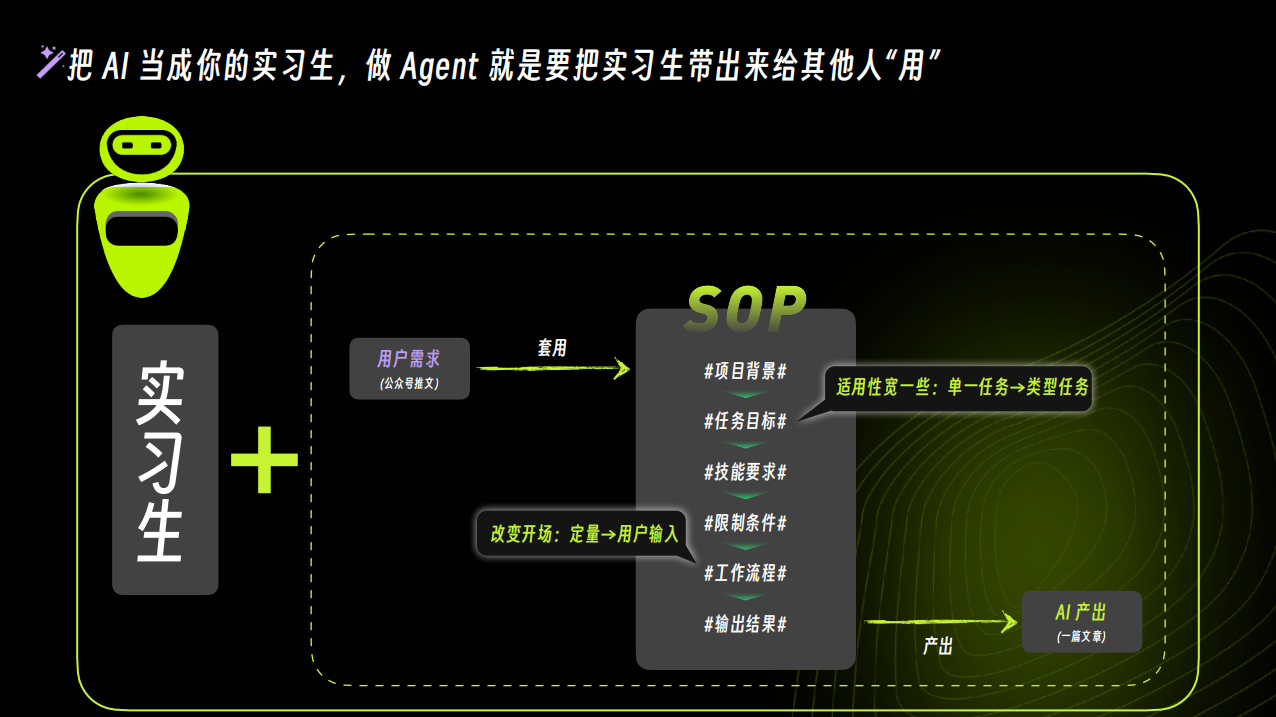
关于工作流,这是Agent( 智能体 )的另一大特色,这里的技术原理是产品团队通过模拟用户在使用产品中可能会出现的问题和输入的关键词触发反馈,用户填入信息后,反馈就自动提交给平台。随着这个产品的迭代,我相信未来也许会出现“一键预约”等工作流,用户通过AI助理查询以后,实现一键预约。
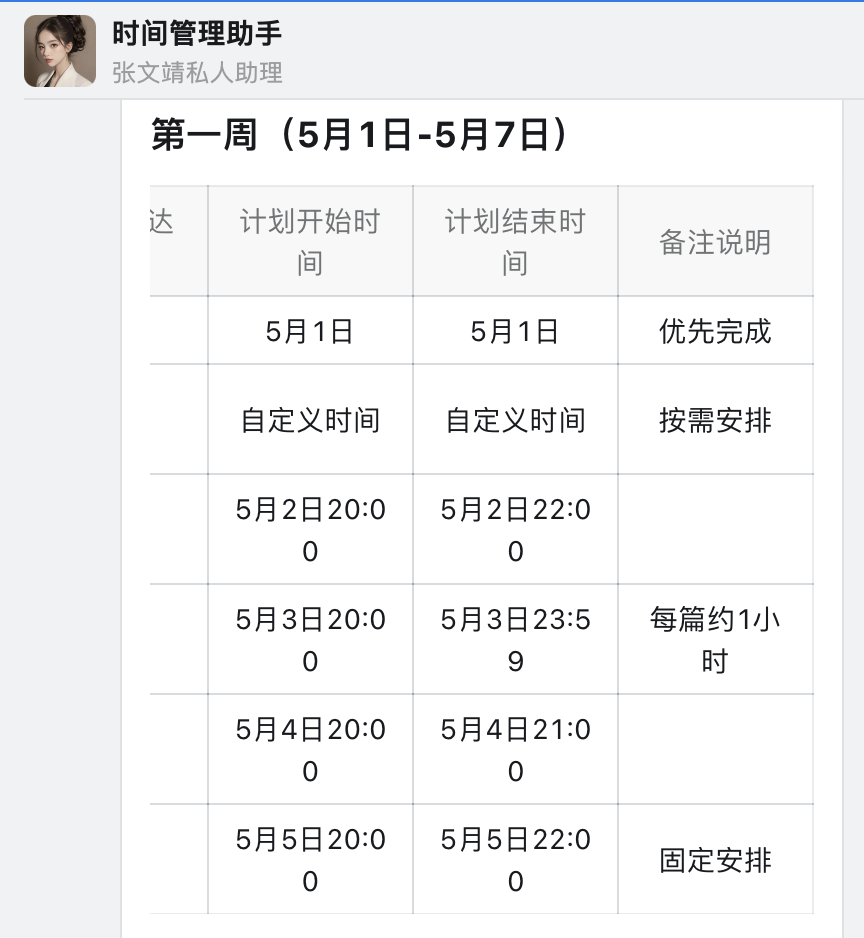
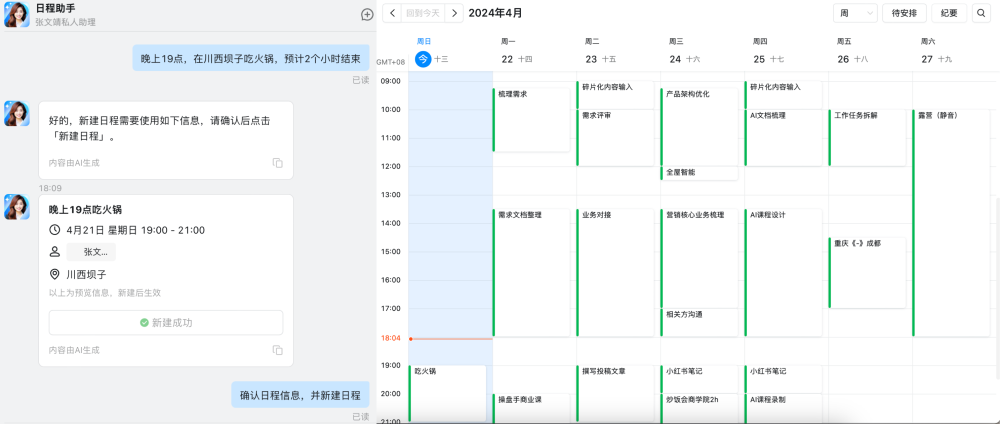
5)日程策划
受益于钉钉平台强大的应用,「公安政务助手」还能结合用户的日程安排,为用户自动安排办事行程计划,规避时间冲突。我认为这是钉钉平台和AI Agent天生契合、完美的场景之一,毕竟用钉钉为用户设计的场景正是智能、协同办公,而感知和规划能力,正是Agent的优势之一。
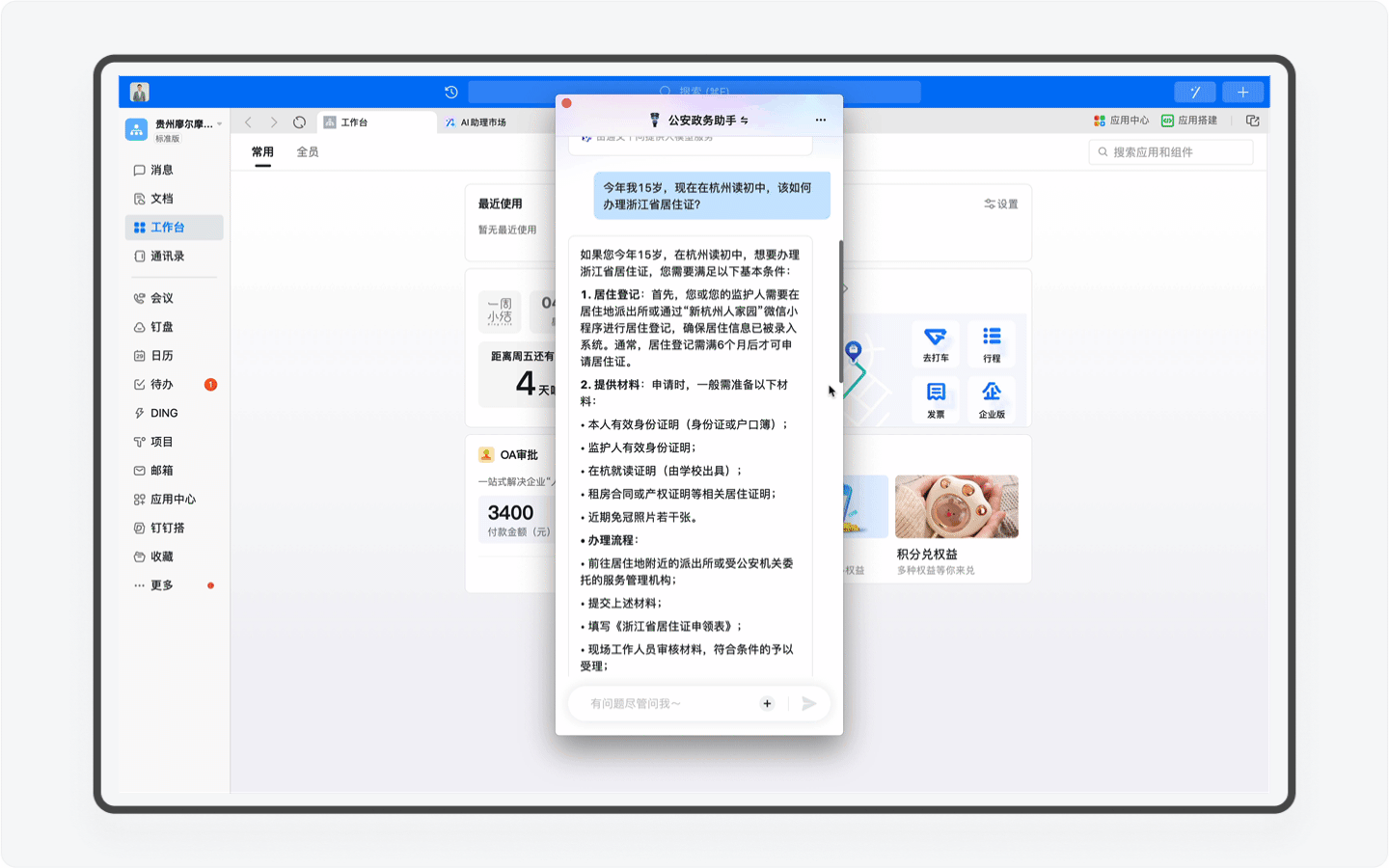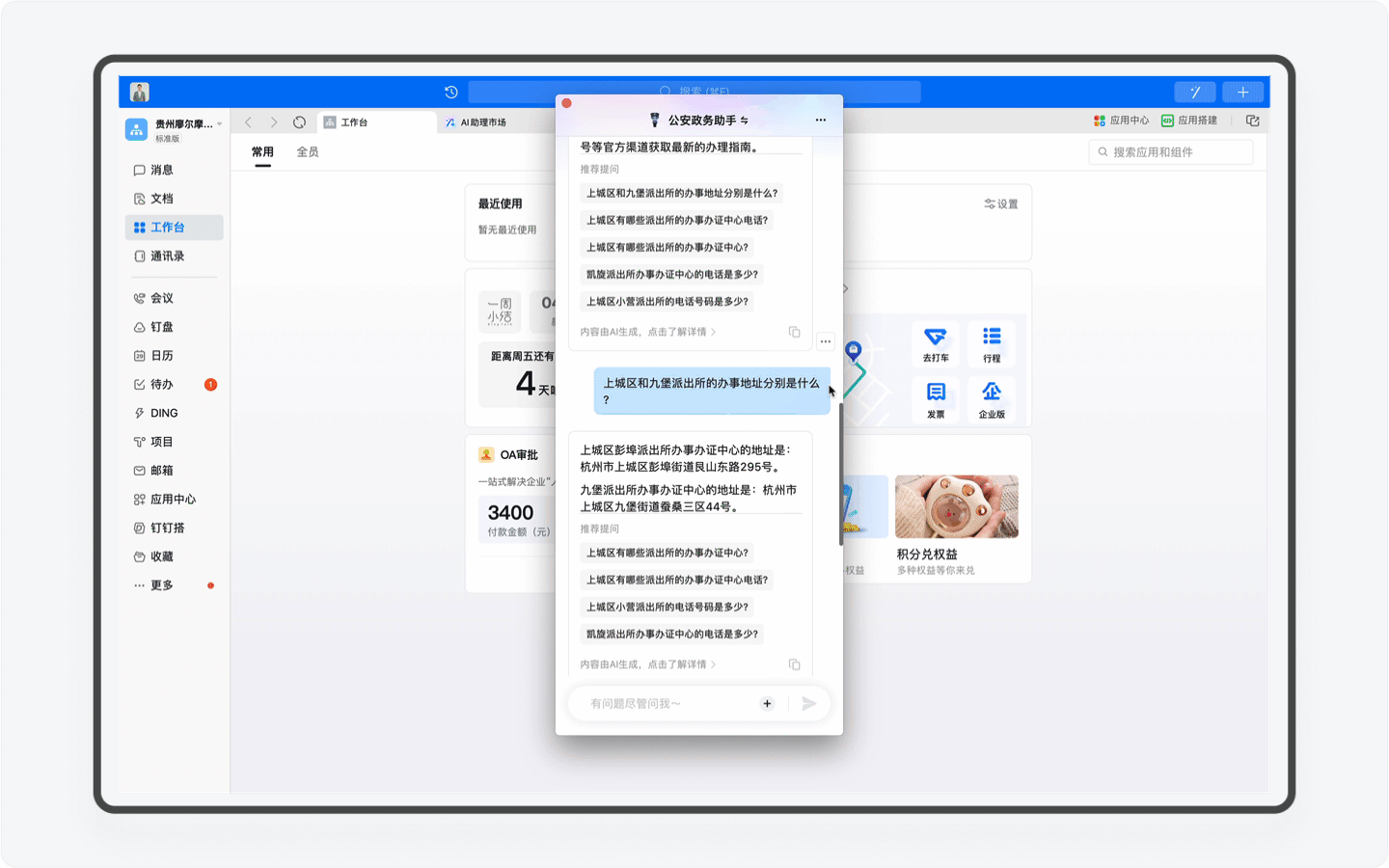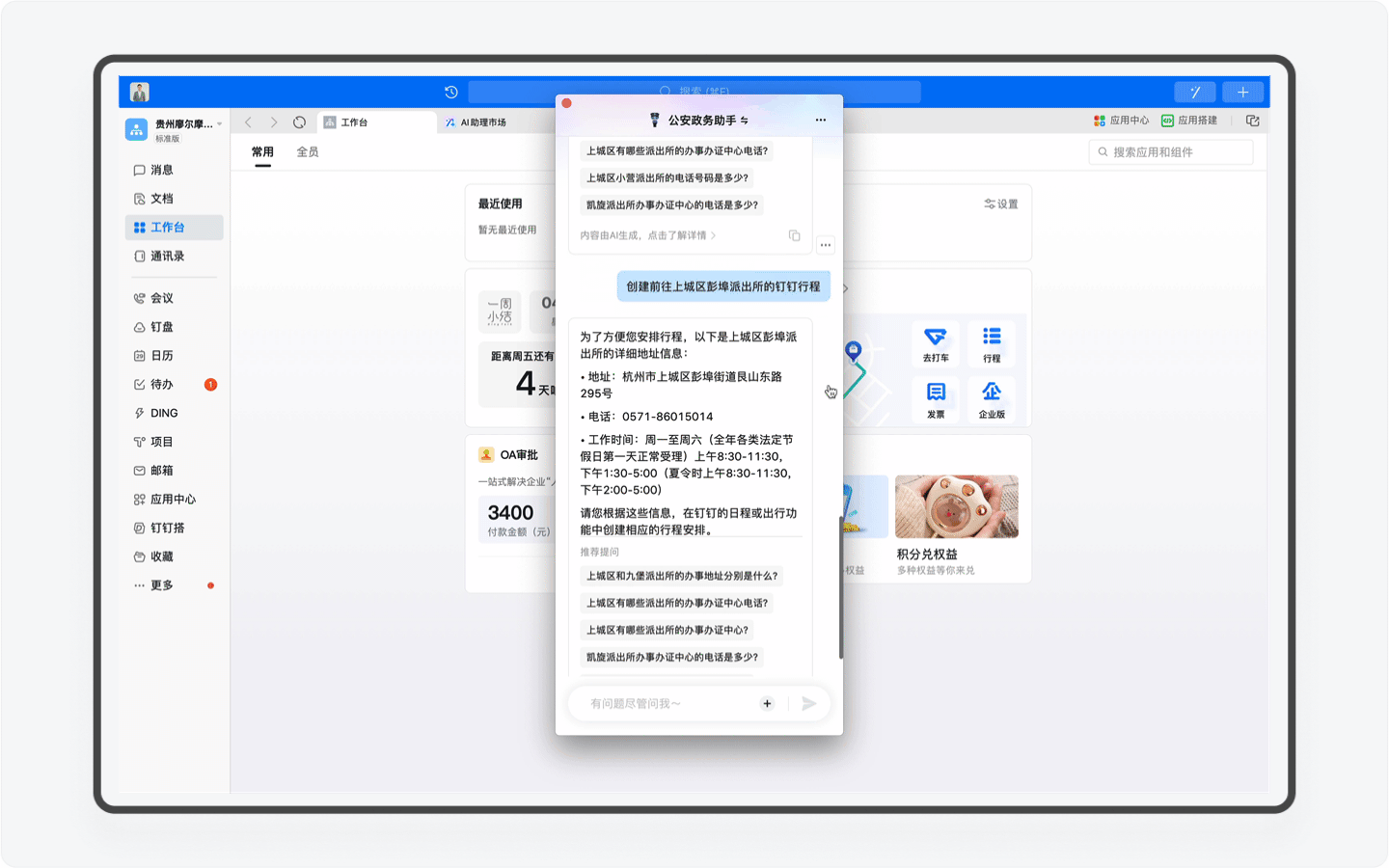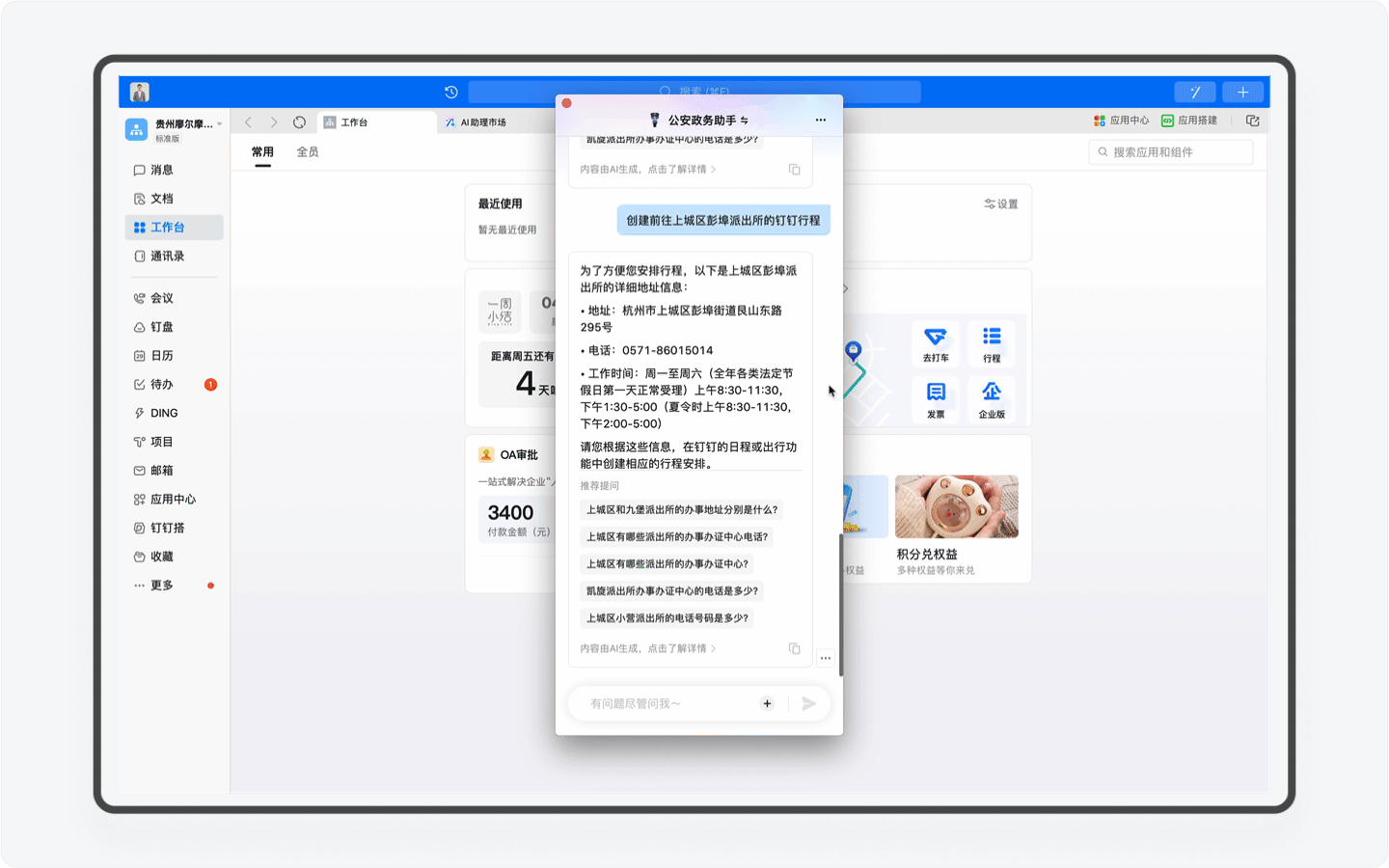
不过目前「公安政务助手」在这个场景的开发还比较基础,比如我先让AI助理为我查询5月20日能否办理杭州市的居住证,但接下来我让AI助理创办行程的动作中,AI却无法感知,而是需要我再次输入准确的日期和时间。期望这个产品能在随后的版本中持续迭代,让用户真正感受到钉钉AI所带来的办公便利和优势。
3. 小结
正如「公安政务助手」产品团队负责人在钉钉AI极客盛典的总结,他们的产品目标是借助钉钉、借助AI,努力去打造一个真正聪明、懂你的24小时公安政务助手。在全面体验完这款AI助理之后,我认为这是政务服务全新的用户体验升级,相比过往和那些冰冷机器人的对话,正是AI Agent的赋能,让「公安政务助手」这样的政务产品,充满了服务的温度和力量。它聪明,理解你的想法;它懂你,预判你的行为!
三、公安政务助手带给我们的思考和启发
一百年前,英国人嘲笑美国人发明的电话,因为他们拥有足够多的马匹和驿站。
二十年前,当国内互联网的浪潮来临时,有很多传统企业不屑一顾,他们只想要更多的门店和雇佣更多的员工。
如今,在科技时代的又一个拐点,面对AI持续不断的发展升级,我们又该如何面对?我认为从「公安政务助手」这款AI助理至少可以为我们带来三个启发。
第一,拥抱AI+,就像十年前一样拥抱互联网+。
毫无疑问,我们已经踏入了AI时代,无论你身处哪个行业,AI都已经带来了巨大的变化。在体验「公安政务助手」这样的AI助理之前,你能想象得到在政务办事的场景中,你可以通过一个对话工具,就能先把所有资料都带齐吗?甚至连最近的办事大厅上班时间、地址和行车路线都为你规划好了。
这不仅仅是效率和服务的提升,更是产品设计理念的提升,而促成这样质的变化的最大原因,就是AI的发展,就是AI Agent。拥抱 AI+,正如我们十年前一样拥抱互联网+,无论你是传统企业、小微企业还是超级个体,在时代的洪流面前,我们需认真思考一下AI如何改善我们的产品和工作模式了。
第二,优化升级工作流,让AI为我们降本增效。
如上文所说,我认为钉钉平台和AI Agent的理念是天生契合的完美场景之一,因为钉钉就是基于企业办公的场景而设计,而AI Agent超强的感知、记忆、规划和任务执行能力,刚好可以和钉钉这样以工作场景为中心的企业办公平台深度结合。
在「公安政务助手」的体验中,我构思了多个未来AI助理可以帮助用户实现更深层次需求的功能和场景,这是工作流的升级,也是企业服务的升级,如果没有AI,靠我们通过人工的形式去实现,也许是天方夜谭,但加入了AI,一切就变得不再那么困难。是时候像「公安政务助手」一样,思考一下如何借助钉钉、借助AI,优化升级我们的工作流了。
第三,沉淀企业知识库,通过AI提升品牌专业度。
「公安政务助手」产品团队为AI助理打造的近40万字的知识库深深地启发了我,不仅改变了我对AI这项技术的看法,更是让我明白打造自己核心知识库对于企业和个人的重要性。无论你身处哪个行业,你是企业还是个人,知识才是你真正赖以生存的筹码,而通过AI的赋能,我们完全可以打造一个提升品牌专业度和权威度的专属AI Agent。
如果「公安政务助手」只是为我提供基础的信息查询功能,我会觉得它只是一个优秀的AI助理,但当它通过自身沉淀的知识库加入了政务服务科普百科的理念,我觉得这才是它真正的核心竞争力,以及为社会和用户创造的真正价值。而实现这一切,只需要我们从现在开始,重新认识AI,结合自身的知识库,开始打造一个专属的AI Agent!