一、核心判断及观点
压缩即智能-十几万字的核心不过100多字
注意力机制告诉我们要做减法,总结是最好的减法过程。一个产业的结论:5句话足以。
- 理解神经科学机制,会对AI的发展起到关键作用!
- 联结主义学派仍然继续要走压缩智能和物理世界模型等深度仿生路线!
- 大模型的Scaling Law大概率失效下,大模型将降本增效-模型更小,成本更低,大家将会专注基于目前大模型能力,开发PMF的产品!
- 国内大模型公司将会转型做垂直行业产品的变多,不会有那么多的人留在牌桌上!
- AI Infra:推理和训练阶段的计算优化,合成数据;大模型层:有持续稳定大流量使用以及良好的盈利潜力,期望能突破互联网的生态;应用层将大爆发:美术工具、音乐生成、AI4S、生产控制、学龄前儿童教育、游戏、智能眼镜、智能陪伴和具身智能;商业价值较高,投资机会明显。
二、AI导论
AI概念
人工智能(Artificial Intelligence,AI)研究目的是通过探索智慧的实质(哲学知识论和脑科学),扩展人造智能(计算机科学)—— 促使智能主体会听(语音识别、机器翻译等)、会看(图像识别、文字识别等)、会说(语音合成、人机对话等)、会思考(人机对弈、专家系统等)、会学习(知识表示,机器学习等)、会行动(机器人、自动驾驶汽车等)。
AI学科的发展是由哲学知识论不断引导着神经科学和计算机科学融合(两者互相促进)的。
一个经典的AI定义是:“ 智能主体可以理解数据及从中学习,并利用知识实现特定目标和任务的能力。(A system’s ability to correctly interpret external data, to learn from such data, and to use those learnings to achieve specific goals and tasks through flexible adaptation)”
意识之外…
辩证上来说,一定会有人类的感知系统盲区,无法感知就无法意识到盲事物的存在。而人类万万没想到,这个盲区竟先来自于我们的大脑,具体来说是我们的神经系统。
神经系统把我们的感知死死限制在了对外界信息的获取和处理过程中,你可以通过眼、耳、口、鼻、舌、皮肤等外界感受器,获取大街上的帅哥美女信息,想一想今天晚上吃些什么,然后再刷刷抖音【1】。
我们的意识绝对不能主观控制心跳,控制肠胃的蠕动,肝脏的运行,控制血管的收缩,当然,意识更不能指导每一个神经元的运转,由于意识权限仅仅被限制在神经网络之中,若不是通过解剖和显微镜看到了神经元,人类甚至不知道神经元本身的存在。
我们以为自己的意识是身体或者大脑的主人。但我们还在妈妈肚子里的前两个月,根本没有任何的意识。我们以为的“自我”根本就不存在。但身体,依旧按照DNA编码的规则,按部就班的发育着。
随着孕龄的增大,听觉、味觉、触觉等感知系统的发育逐渐完善后,大脑才能建立足够多的神经网络,让我们产生意识。
人类科学家终于认识到–意识不等于大脑。
我们思考中的意识世界不过是神经元相互协作的结果。主动的意识习惯也可以改造神经元回路。(辩证唯物主义:意识产生于物质,但意识可以改造物质)
神经科学
随着人们对神经系统的研究深入,科学家们对智能的形成逐渐从意识层面(可认知的、肤浅)转向至物理层面(难以认知的、源头)。
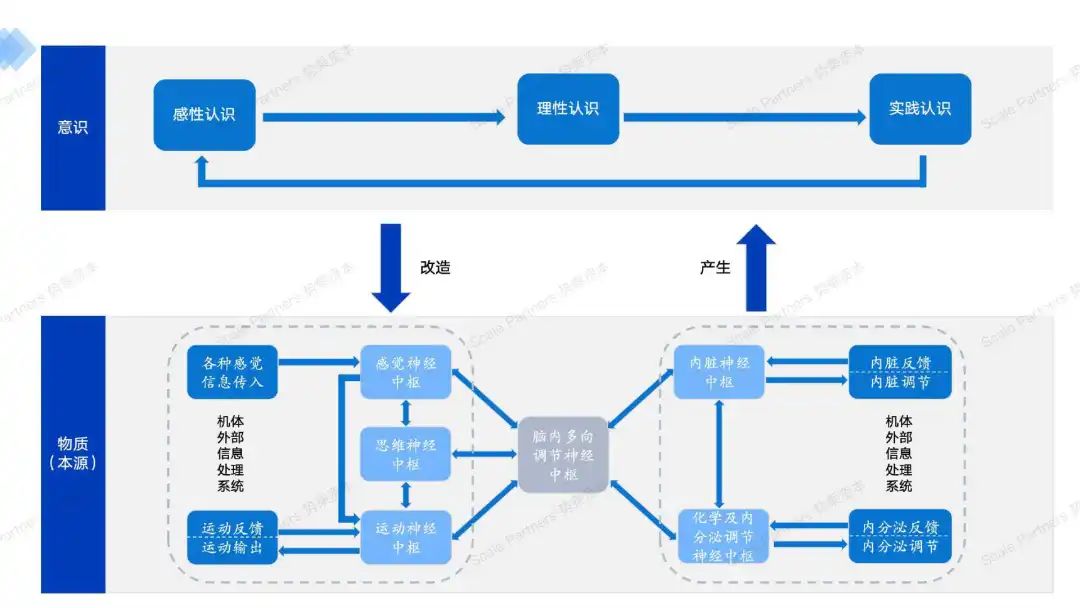
图:意识和物理上的知识形成【2】
很多AI创业者和科学家特别喜欢说自己的项目才是更像人的运动、思维和感知模式,来强调技术的优越性,本篇将注重:
- 人的神经系统如何运作
- 以及是否需要拟人才能实现效果
来帮助大家更好的独立判断项目。
1)神经科学的发展历史、现状和展望
注:本篇知识点和框架大规模借鉴了认知神经科学之父迈克尔·加扎尼加(Michael S. Gazzaniga)编写的认知神经科学教科书第三版,在此基础上补充了了前沿研究成果。

神经科学概述
神经科学(Neuroscience),又称神经生物学,是对神经系统(包括大脑、脊柱和周围神经系统)及其功能和疾病的科学研究。
神经科学是医学领域,乃至整个自然科学界最前沿、最复杂、最深奥的学科之一。近一百年,脑科学获得了近二十项诺贝尔奖。
“左脑负责理性思考,右脑负责创造力。”很多人曾经、甚至现在依然对类似这样的说法信以为真。这是因为,很长时间以来,对大脑的研究往往会把大脑划分出几个区域,分别研究单个脑区的功能。
但现在,许多神经科学家指出,是时候以新的方式来提升我们对大脑运行原理的认识了:大脑的各种功能,关键不在于某一个脑区,而是来自于不同区域之间的交流。
人类对脑的探索过程
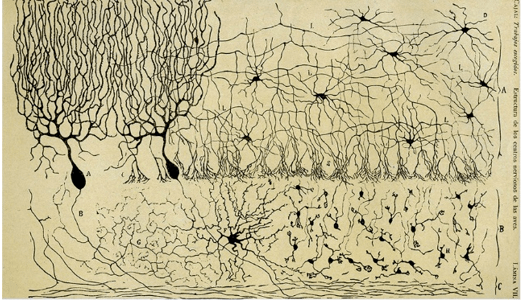
图:1873年,人类通过染色法第一次观察到完整的神经元
西方的科学家,经历了哲学思考、动物解剖、人类大脑解剖、脑功能分区、染色法发现神经元、电生理、神经化学、膜片钳、核磁共振成像、甚至是AI模拟的范式转变。由思想层面转变至物质层面,由整体层面转变至神经元微观层面,由直接观察到间接机制的模拟。
总而言之,神经科学发展是一个由不断更新的研究手段(1 直接观察:解剖、核磁共振影像;2 间接观察:电压钳、膜片钳、染色示踪;3 药理学;4 认知精神科学 5 AI模型复现)为主要驱动和从而发现的机制原理为次要驱动的相互影响双螺旋发展。
现状和展望
至今,目前的脑科学研究,在分子生物层面和认知行为层面还是很强的(个体机制),薄弱环节在于神经环路和系统机制方面(整体机制),如何分析各个神经环路的工作原理,以此来解释脑的功能或人的行为,进而阐明人脑的系统性工作机制。
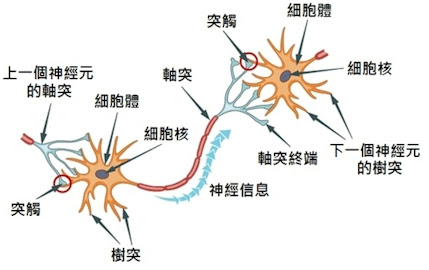
图:个体机制–神经元的工作机制
认识神经元不难,搞清楚它们之间的排列组合,才是难【3】。
因为人类的大脑估计已经包含860亿个(10^11次方)神经元,这些细胞信号传递到对方通过多达100万亿(10^15)突触连接。
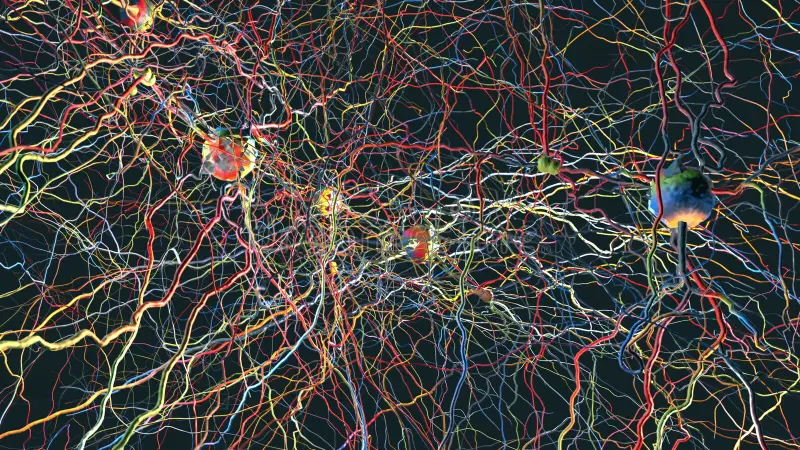
图:整体机制–神经元的排列组合
就好比,我们现在已经初步画好了咱们大脑图谱有哪些“中心功能大楼”,也知道了这些大楼本身是由神经元为砖瓦砌起来的,但是大楼内部的电线管道是怎么铺的?大楼与大楼之间的交通线路是怎么设计的?它们之间的排列组合、优先次序、是否有替代线路?我们仍然知之甚少。
这些像蜘蛛网一样密密麻麻排列的“大脑”线路,神经科学家们称之为“连接组”(connectome)。我们始终相信,研究大脑,就要先从全面绘制大脑的连接地图开始(大脑的物质构造)。
阶段一:C.elegan,线虫-302个神经元(重现方法:切片/电镜/手绘)
于是,我们决定先杀个小小的生物的大脑来试试水,第一刀,挥向的是C.elegan,线虫(302个神经元)。
1970年代,剑桥大学两位分子生物学家John White 和 Sidney Brenner决定利用线虫来研究大脑连接组学,他们将线虫大脑切成了超薄脑片,通过将相机架在电镜下拍摄微观图片,然后放大打印出每一个脑片的电镜下图像,再人工用彩色铅笔一点一点、一圈一圈地标记线虫的大脑结构,绘制线虫脑图。
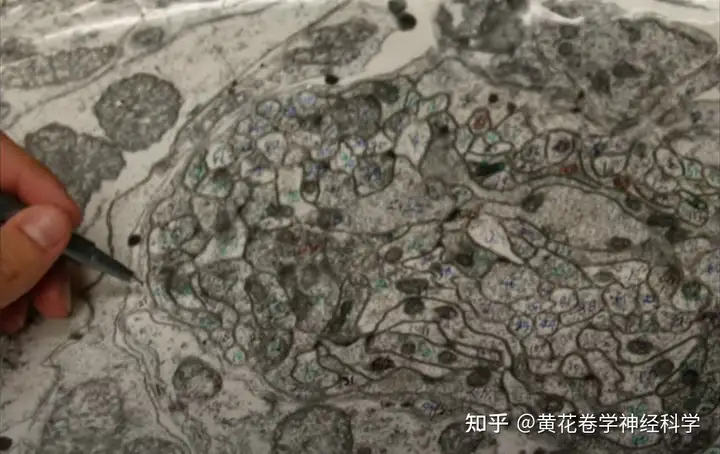
终于,十年以后,1986年,这项工作完成了,线虫–一个拥有302个神经元的简单生物–成为了人类神经科学研究史上第一个,也是迄今为止唯一一个,拥有完整大脑图谱的生物。
阶段2:果蝇的半个大脑-25,000个神经元(重现方法:切片/电镜/CV)
我们开始想办法提高技术,把样品准备和电镜拍摄速度提高、利用计算机算法来自动识别电镜图像下的神经元、以及引入人工智能来处理这大批量的数据,等等。
我们“教会”计算机如何识别一个个神经元细胞,命令它们将不同神经元以不同颜色区分开来,接着再将这每一个薄薄的脑片叠加还原成原本的脑组织块,以重建里面的每一个神经元的完整模样和真实连接关系……
果蝇的大脑有芝麻粒那么大,包含大约十万个神经元和数百万个突触连接。
2020年,哈佛大学研究团队宣布他们成功绘制出了…半个果蝇大脑图谱,下图是这半个果蝇大脑图谱的简单展示,包含了约25,000个神经元。
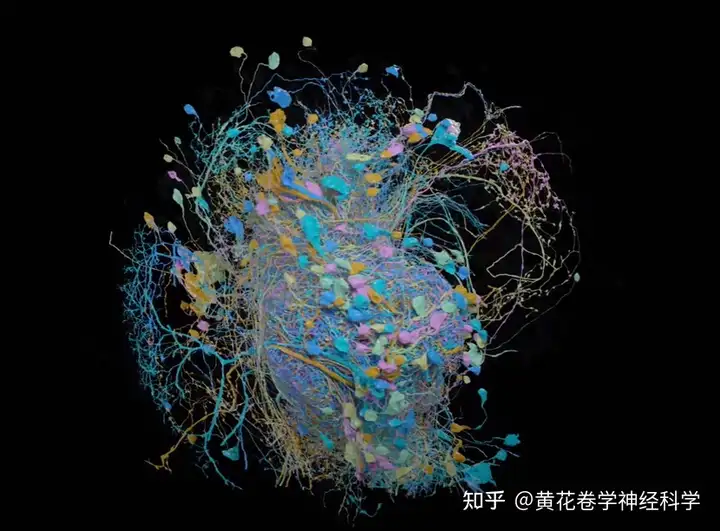
尽管还有半个果蝇大脑需要画,但是这半个果蝇脑谱,已经是现如今被报导出的最大的生物大脑图谱了。
阶段3:一立方毫米的老鼠的大脑-10万个神经元(重现方法:聚焦离子束显微镜&3D-CV)
Janelia团队则开始使用聚焦离子束显微镜,聚焦离子束系统除了具有电子成像功能外,由于离子具有较大的质量,经过加速聚焦后还可对材料和器件进行蚀刻、沉积、离子注入等加工,因此可以大大缩减样品和拍摄时间。
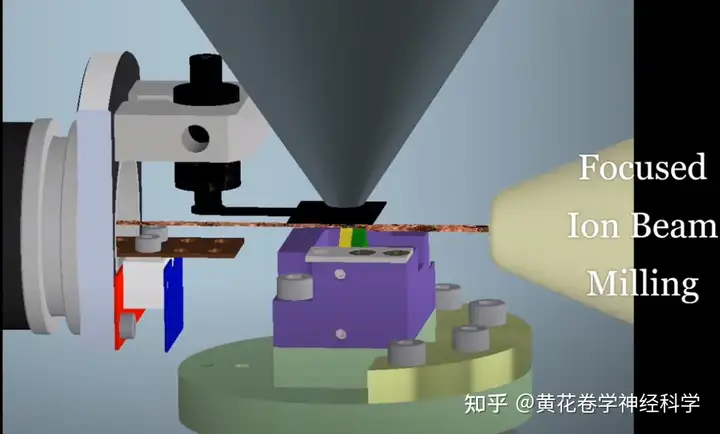
同时,他们找来了谷歌合作,将2D数据进行注释标记以及3D重建(谷歌地图技术),但是有时候计算机会将两个缠结在一起的神经元误认为是一个神经元,这给后期的勘误工作带来了很多麻烦。最后还是要靠经验丰富的科学家来进行最后的结果审查。
Allen Brain也是绘制脑图的主要贡献者,团队于2019年曾宣布他们已经花了十年时间绘制出了一立方毫米的小鼠大脑图,其中包含了10万个神经元和100万个突触结构。
虽然,一个小鼠大脑有大约500个立方毫米这么大,没关系,总有一天!
目前,脑功能成像,神经刺激,神经信号记录,脑损伤研究,等等研究方法【4】,大多是相关性研究,通过研究来证实某个神经核团或环路与某种脑功能的相关性,或者进一步再描述其简单的因果关系,“AA通过BB调制CC的活动来实现XX功能”之类。这些研究带来很多孤立的碎片的研究结论,每年在顶刊发表很多高分文章,但对整个人脑的工作原理仍然缺乏突破。
总而言之:仍然缺乏有效的观察研究方法(AI连接主义的模型模拟预测为一大方向),重现人类大脑结构和机制。(目前神经学前沿一大热点仍然是神经元分类)。
神经系统机制
大脑神经元的建立过程——从基础构建到复杂网络的形成之旅【5】。
神经细胞神经系统的细胞主要分为两大类:
一类是主导电化学信号传导的神经元细胞;
二类是像胶水一样把把神经元细胞联结起来,并辅助神经元功能的胶质细胞。
神经元具有感受刺激、整合信息和传导冲动的能力。
神经元感知环境的变化后,再将信息传递给其他的神经元,并指令集体做出反应。神经元占了神经系统约一半,其他大部分由神经胶质细胞所构成。
据估计,人脑中约有850-1200亿个神经元,神经胶质细胞的数目则更是其10倍之多。
神经元细胞
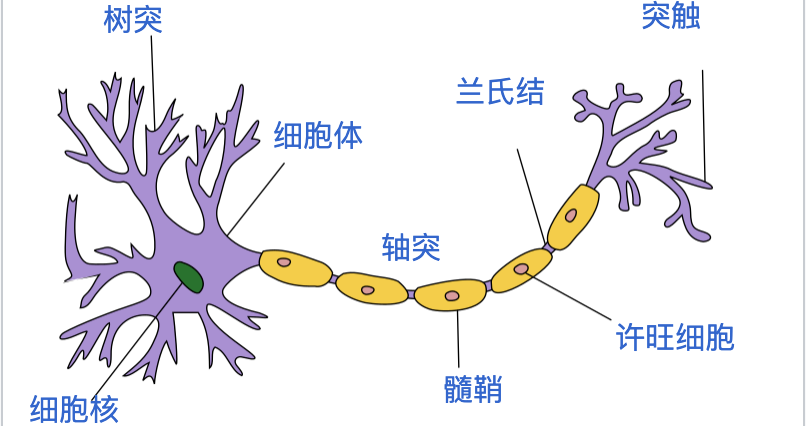
图:典型神经元2D结构
结构及功能
神经元形态与功能多种多样,但结构上大致都可分成细胞体(胞体)和神经突(胞突)两部分。
神经突又分树突(dendrite)和轴突(axon)两种。轴突往往很长,由细胞的轴丘分出,其直径均匀,开始一段称为始段,离开细胞体若干距离后始获得髓鞘,成为神经纤维。
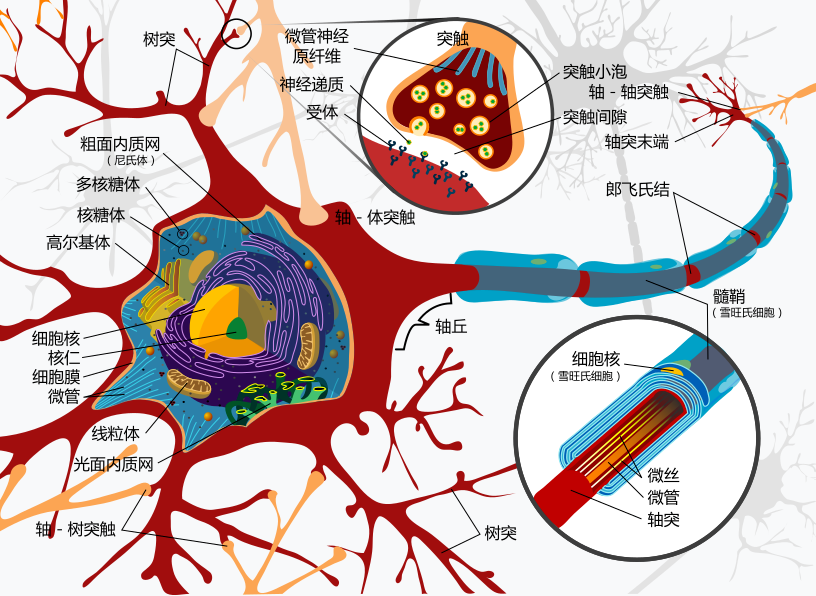
图:典型神经元3D结构
1、树突(dendrite)- 接收器:树枝状的纤维从细胞体向外伸出,分叉且非常多,这些纤维被称为树突,主要是收集来自感觉器官的直接刺激或来自相邻神经元的活动信息,并把传入信息传递给神经元的中心部分。这些突触具有一定的权重,它们决定了信号传递的强度和效率。权重的大小反映了神经元之间的连接强度,从而影响信息传递的效率和方式【6】。
2、胞体(soma) – 处理器:神经元的中心部分,含有细胞的染色体,能够迅速评估同时接收到的数百上千条信息。其中有些信息可能是兴奋性的(“放电”),有些是抑制性的(“不要放电”),胞体的唤起程度取决于所有传入信息的汇总。
3、轴突(axon) – 发射器:从胞体上伸出,上有髓鞘(轴突覆盖物),传递被唤起的神经元自己的信息(兴奋大于抑制),有时很长,有的人连接脊与脚趾的轴突可以长达一米多。轴突有时会非常短,大脑里中间神经元之间的轴突可能只有不到1厘米长。
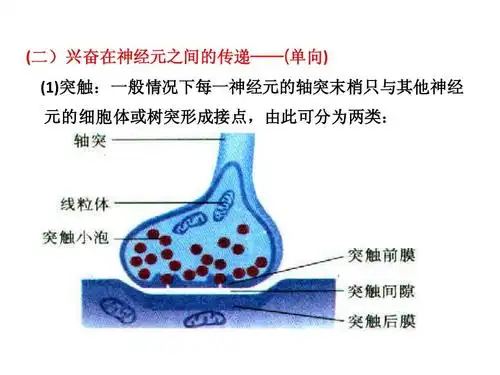
图:神经元连接部分-轴突末端和树突前段
神经元的轴突会与另一个神经元的树突通过形成突触结构建立联系,在突触结构中,一些神级递质(化学)会通过上一个细胞的轴突上的突触前膜,向下一个细胞的树突上的突触后面传递,以实现细胞间的信号传递。神经元轴突还可通过发生动作电位(电信号)进行电信号传递。
功能
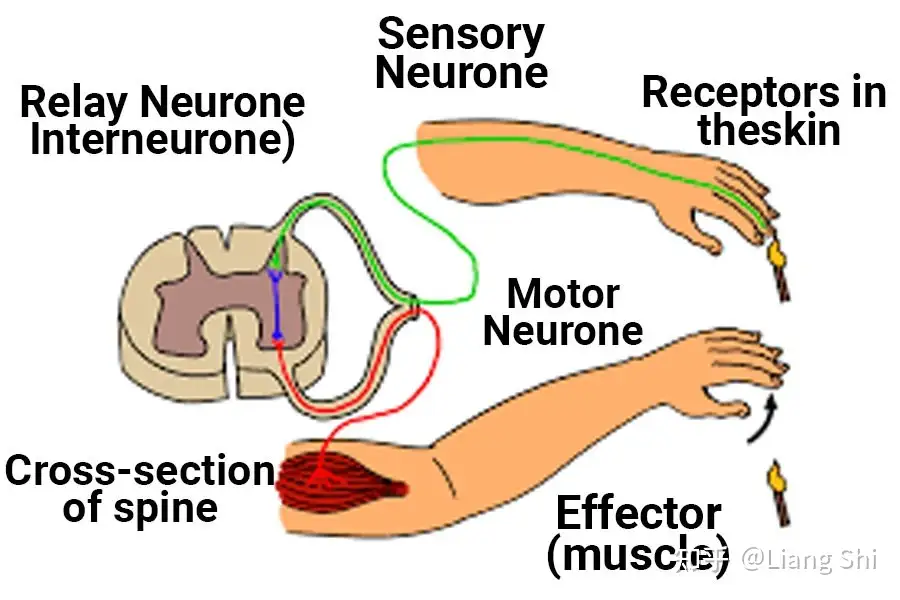
神经细胞可以大致分为运动神经细胞、感觉神经细胞和中间神经细胞三大类【7】。
感觉神经细胞(Sensory neurons)的细胞体位于背根神经节(细胞体簇就在脊髓外),而它们的外围延伸遍及全身。具体来说,感觉神经元通过特定的外部和内部受体被感觉输入激活。
- 外部感受器对身体外部的刺激做出反应包括嗅觉感受器、味觉感受器、光感受器、耳蜗毛感受器、温度感受器和机械感受器。内部受体对身体内部的变化作出反应。例如,它们可以检测血液化学性质的变化或通过引起疼痛感来对潜在的破坏性刺激做出反应。
- 感觉神经细胞利用其感受器,将特定类型的刺激转换为动作电位或阶梯性电位,并将信号传递回中枢神经系统。
运动神经细胞(Motor neurons)是一种位于大脑运动皮层、脑干或脊髓的神经细胞,其轴突(传出神经纤维)可延伸至脊髓内部或脊髓外部。
中间神经细胞(Interneurons)的细胞体皆位于中枢神经系统,连接神经系统的多个区域。中间神经元是神经回路的中心节点,允许感觉神经元、运动神经元和中枢神经系统之间进行通信。此类别包含最多种类的神经元,它们参与处理许多不同类型的信息,例如反射、学习和决策。
——此类神经元的数量庞大,约占神经元总数的99%。
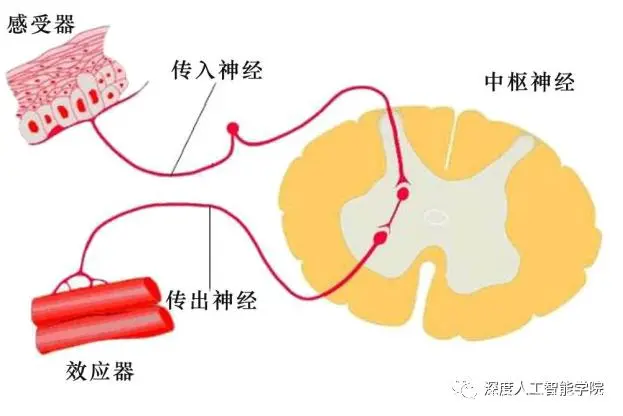
分工与合作:三种神经细胞构成了一个大环路,如下图。感觉神经细胞通过感受器感受到刺激(火的炙烤),并将刺激信号传递到中枢神经系统的中间神经细胞。中间神经细胞通过相互联络,做出决定(移开手指),并将指令传递给运动神经细胞。而后,运动神经细胞负责将指令信号传递到效应器,使肌肉动作(移开手指)。
释放不同的突触递质来区分神经元
突触神经突触是允许神经通信的神经元之间的连接点。
大脑中绝大多数的神经元大致可分为兴奋性神经元(excitatory)或抑制性(inhibitory)神经元。兴奋性神经元占80-90%,它们释放兴奋性神经递质并使得下游神经元更兴奋,相当于大脑中的”油门“;抑制性神经元占10-20%, 它们释放抑制性神经递质使得下游神经元更不兴奋,相当于大脑中的”刹车“,避免过于兴奋,比如痛觉麻痹等。
前者主要传递兴奋性神经递质,如谷氨酸(Glutamate)、肾上腺素(Epinephrine);而后者主要传递抑制性递质,如γ-氨基丁酸(GABA)和血清素(5-HT)【8】。
神经递质目前在人体中发现100多种(100多种信息维度),然而,大脑中绝大多数的神经元还是单纯的兴奋性或抑制性,再加上同时释放多种神经递质的意义和机制仍不清楚,相关问题还处于神经科学研究的早期阶段。
具体工作原理
一个典型的神经元能够通过树突和胞体一次接收上千条信息【9】。当胞体被充分唤起时,它自己的信息便会被传递给轴突,轴突通过动作电位将信息传递到突触小体。这个含有神经递质的小泡破裂,将神经递质释放到突触间隙中。形状合适的神经递质分子来到突触后膜时,会停留在受体上并刺激接收细胞。多余的神经递质通过再摄取过程被回收到“发送”神经元中。
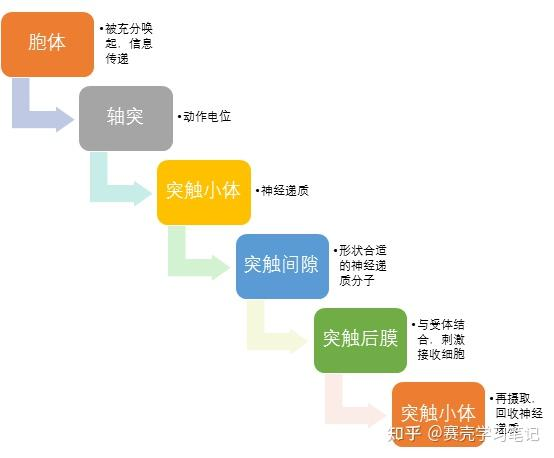
PS1:动作电位(action potential):当细胞体的唤起达到临界水平时,触发轴突中的电脉冲,轴突内外电荷发生逆转,导致电信号沿轴突传递,我们称之为神经元“放电”or“点火”。
PS2:全或无原则(all-or-none principle):动作电位没有中间状态,要么放电,要么不放电。
PS3:静息电位(resting potential):在正常的静止状态时,细胞中的离子使轴突带有少量的负电荷,此时状态即为静息电位。
特殊情况:同步放电即有些神经元(极少数)不使用神经递质在突触间传递信息,放弃了化学信息传递,通过电联系进行直接通信。电突触不如化学突触常见,主要存在于中枢神经系统中。电突触中的突触间隙要小得多,这使得神经元可以直接通过间隙连接传递离子电流。出于这个原因,电突触比化学突触工作得更快,并允许脉冲在神经元内沿任一方向传播。然而,因为它们不使用神经递质,所以电突触比化学突触更不易改变。
生物化学抽象到AI数学模型–M-P神经元模型(深度学习的起点理论)
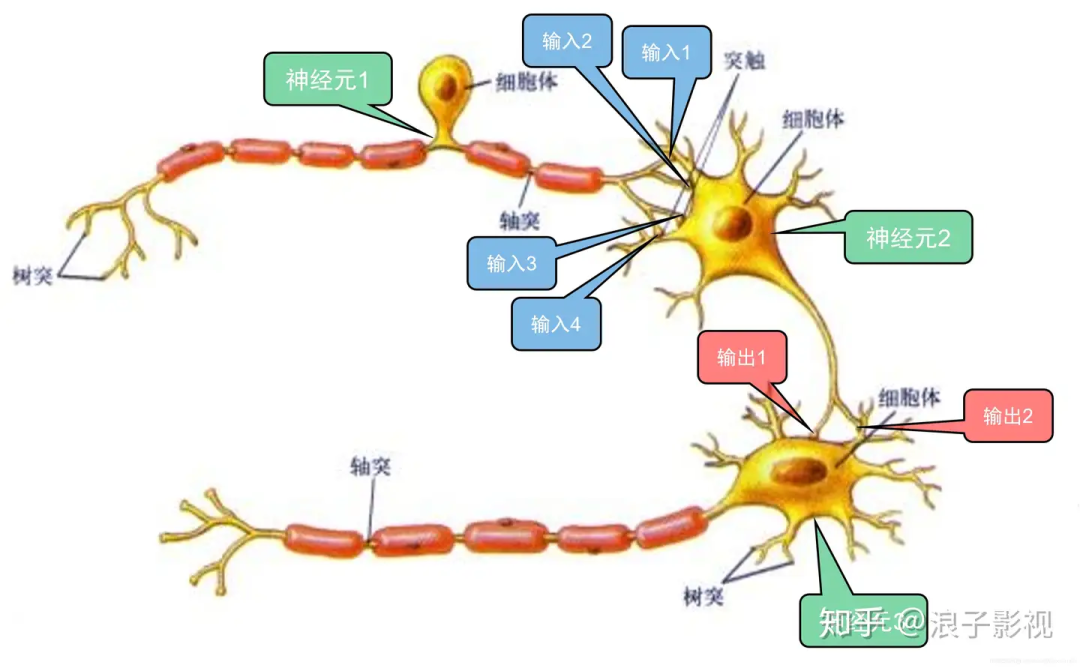
如上图所示,神经元1的轴突传递了4个信号给神经元2,分别是输入1、输入2、输入3和输入4。而神经元2的输出信号(输出1和输出2)分别是神经元3的输入信号(输入1和输入2)。
如果输入信号之和(由各正电离子受刺激流入胞体,电压变高)超过神经元固有的边界值(电压阈值),细胞体就会做出反应,向与轴突连接的其他神经元传递信号,这称为点火【10】。
点火的输出信号是可以由”0″ 或 “1”表示的数字信息表示–全或无原则(all-or-none principle):
无输出信号,
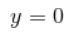
有输出信号,
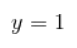
1943年, [McCulloch and Pitts, 1943] 将神经元的工作过程抽象为上图所示的简单模型,这就是一直沿用至今的 “M-P神经元模型” 。
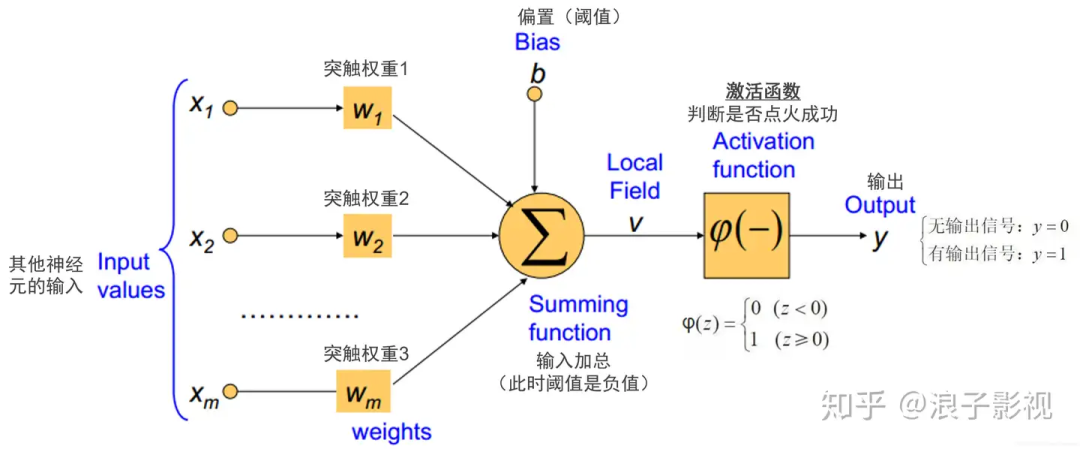
电信号的强弱用数字大小表示,突触的权重使用乘积,胞体接受的动作电位可以用点火函数表示,胞体的激活可以用阶跃函数比较表示。
在这个模型中,神经元接收到来自 m 个其他神经元传递过来的输入信号,这些输入信号通过带权重(weights)的连接进行传递,神经元接收到的总输入值将与神经元的阈值进行比较,然后通过”激活函数” (activation function) 处理以产生神经元的输出。神经元在信号之和超过阈值时点火,不超过阈值时不点火。
所以点火的函数可以表示为:
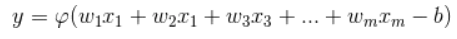
其中,
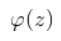
称为激活函数。理想中的激活函数是下图所示的阶跃函数,它将输入值映射为输出值 “0” 或 “1” ,
显然,
- “1” 对应于神经元兴奋(点火成功)
- “0” 对应于神经元抑制(点火不成功)
神经胶质细胞
神经胶质细胞,10-50倍与神经元数量,作用:隔离,支持,营养
这里不一一详细解释了,大家有兴趣可以自行查阅其功能。
神经回路
神经元从来不单独行动,总是与其他细胞一起合作,神经元与神经元结成一张神经网络,以神经反射的形式工作。
神经回路的结构
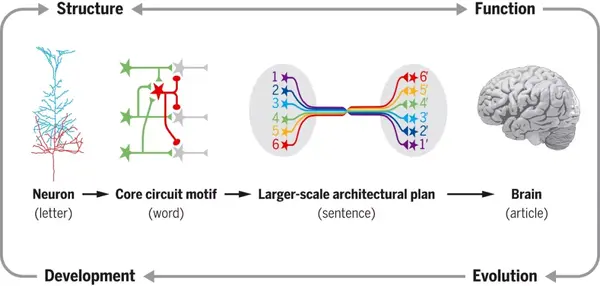
我们可以把把神经元比喻为字母,大脑比喻为整篇文章,而微环路就是字母组成的单词,神经环路则是单词组成的句子。不同脑区使用的不同单词就是环路模体(circuit motifs),而环路模体又进一步组成了复杂的神经环路架构【11】。
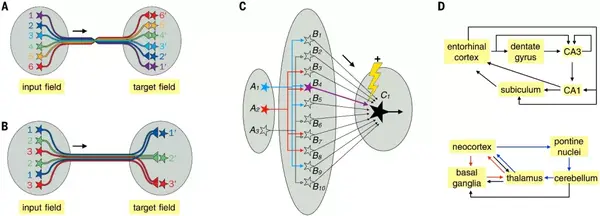
环路架构大体分为连续地形图、离散并行处理、维度扩展、循环回路、偏倚输入-分离输出的环路结构;通过神经的不同布线连接,达到计算和节能的目的。
神经环路架构案例
哺乳动物视觉系统,其中信号始于光感受器→ 双极细胞 → 视网膜神经节细胞 → 外侧膝状核 (LGN) 中继神经元 → 第 4 层初级视觉皮层 (V1) 神经元 → V1 神经元其他层 → 较高皮层区域的神经元。沿着这些前馈通路,视觉信息从简单的光强度转化为对比度、边缘、物体和运动。
回路进化
神经系统的逐渐复杂化需要神经元数量、神经元类型及其连接和大脑区域的扩展。所有这些过程都必须由 DNA 的变化引起。进化创新的一个关键机制是基因的复制和发散。
大脑区域进化的复制和发散原则上应该使神经元回路模块化:复制单元内的丰富连接和单元之间的稀疏连接。反过来,神经元回路的模块化特性可能会加速进化,因为不同的模块可以相互独立地进化。
为目前为止,负责AI大模型进化的,只是人工的版本更新。
计算机环路是自上而下设计的产物,而复杂的神经元环路已经进化了数亿年。神经元回路在发育过程中使用进化选择的遗传指令自组装,并通过经验进行微调。因此,现有的神经环路结构很可能是在演化过程中很容易进化和组装的那些选择。
神经组织
人类大脑的功能机制主要有7大类功能:1 感觉和知觉 2 注意与意识 3 语言 4 学习与记忆 5 运动控制 6 情绪 7 认知控制
1 感觉和知觉
五种基本的感觉系统,听觉、嗅觉、味觉、躯体感觉以及视觉,使我们可以解释周围的环境。每一种感觉包含了独特的通路和加工,以将外部刺激转化为可以被大脑解释的神经信号。
这五种感觉也不是孤立工作的,而是一致行动以构建一个对世界的丰富的解释。正是这一整合成为许多人类认知的基础,并且使我们在一个多感觉的世界中生存并兴旺发展【12】。
从信号的角度来看,人们通过耳朵接受声波,鼻子和舌头接受远近分子化学信号,皮肤接受机械波、温度波,视觉接受光波后,各个感觉神经再通过电信号、化学信号以及机械波的形式传递。
神经如何传递和加工处理至人类可意识的过程大抵相同,下面将主要讲述视觉神经工作原理。
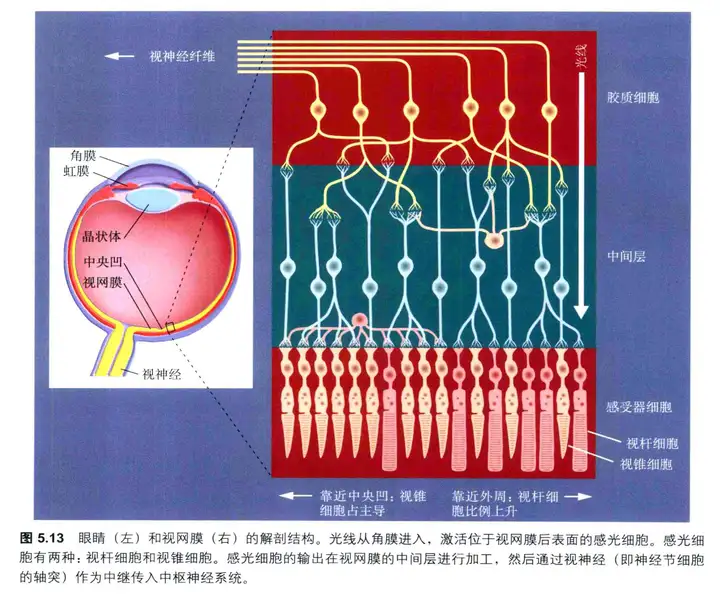
像大多数其他哺乳动物一样,人类是视觉生物:绝大多数人要依赖眼睛来辨别我们看到的是什么,往哪里看,来引导我们动作。这些过程当然是双向互动的。要完成诸如抓住一个扔出物的技巧性动作,我们必须确认物体大小、形状和空间运动轨迹,这样我们才能预先准备好把我们的手放到哪里。
从初级到更高级的视觉皮层,视觉信息逐级传递。人脑理解的内容越来越复杂化、抽象化,由”模式”变成具体的“物”,再到物的特性和物与物之间的关系。在逐级传到过程中,人们也注意到,其在皮层的传到可以大体分成两个通路,腹侧通路(Ventral Pathway/Stream)和背侧通路(DorsalPathway/Stream)。
这两个通路,也分别代表着视觉神经的两大功能:what-物体识别和where-空间感
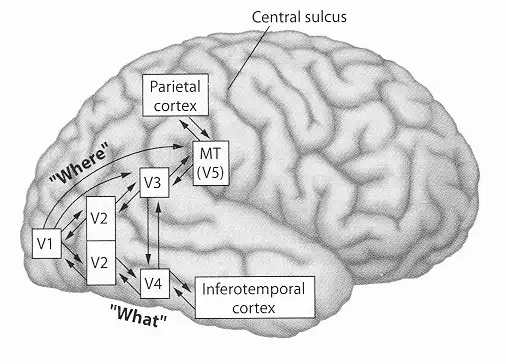
物体识别
对于物体识别而言,视觉系统中的ventral stream(V1 -> V4 -> IT)通路是至关重要的。在这一视觉信息处理通路中,信息被越来越抽象成高级的语义信息。比如V1视觉皮层表征“bar”,V4视觉皮层则表征texture, IT则存在着对物体类别(脸,动物)的直接表征【13】。
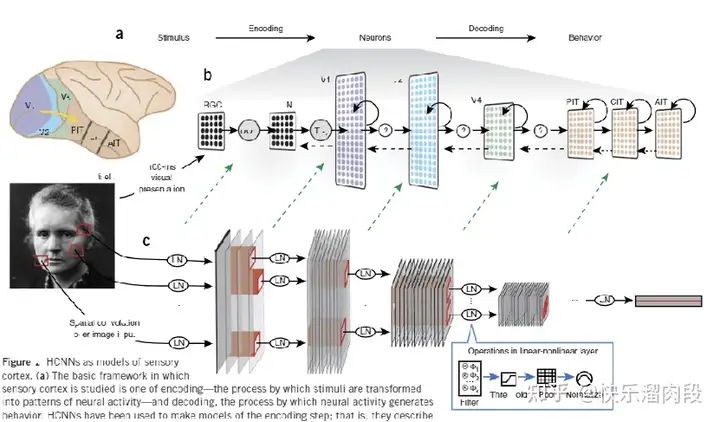
视觉识别是典型的Encoder-Decoder的RNN(循环网络)架构
总而言之:大脑对外部信息处理就是不断表征化的过程(并且是往返循环),表征简单理解为人类可认知到的集成的符号 – 能把某些实体或某类信息表达清楚的形式化系统。
神经元系统对于信息的处理是层级递进的,简单来说每一个皮层(不同的表征处理单元)处理逐级规律复杂,V1视觉皮层前,输入信息为像素点,V1视觉皮层将之处理为Bar-线,随后再由V2-V4视觉皮层处理为-面,3维;再由后续的视觉皮层加工为颜色、光影等更综合的表征,直至IT皮层-形成我们对图像的整体感知,并区分物体。
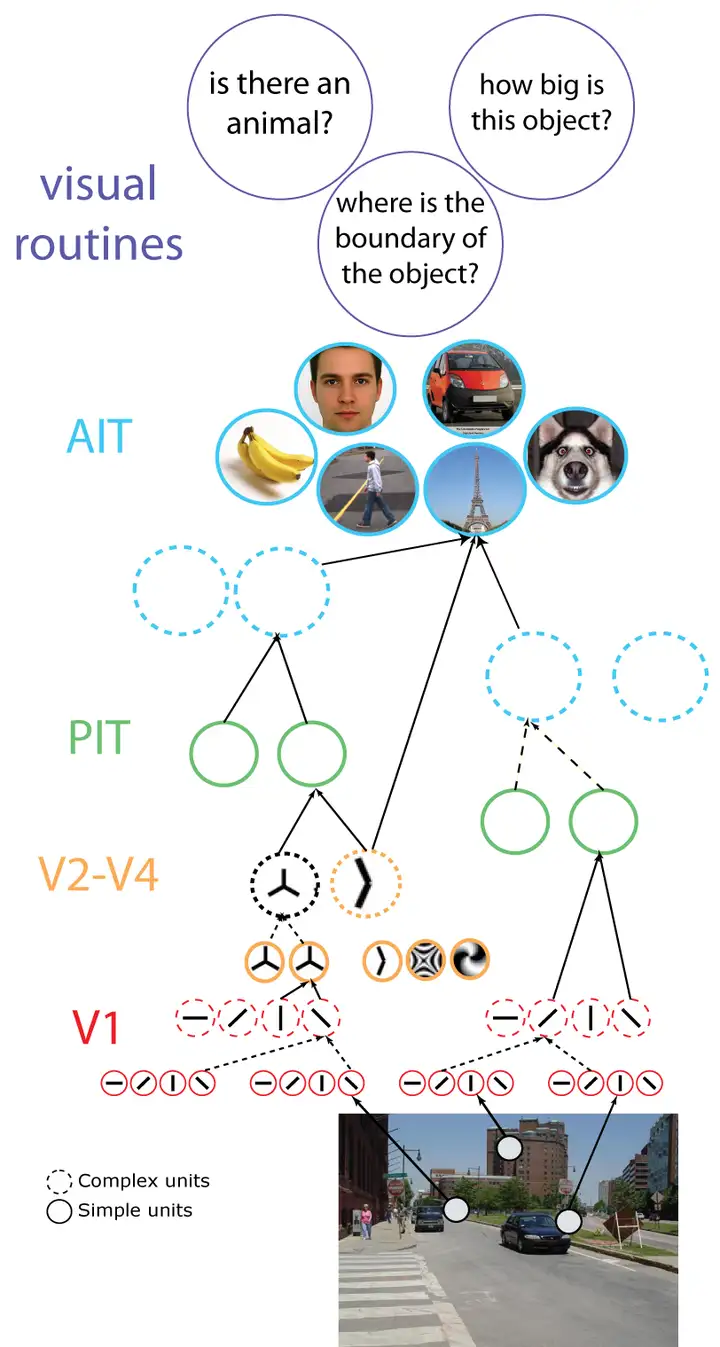
知觉分类只解决了部分识别问题。要使关键信息发挥作用,必须把现有加工内容与我们贮存的有关视觉物体的知识相联系。语义分类(学习和记忆的表达表征–语言)使我们看到知觉对象间的相似性,并辦认出物体的独特特征。
看到这里,大家对视觉神经元的表征化的工程,感到一丝熟悉,对!以CV计算机视觉技术为主的公司所采取的基础模型-CNN卷积神经网络-Convolutional Neural Networks,其设计灵感就来自于层级递进的视觉神经物体识别通路表征化过程–1960年代对猫的视觉皮层的研究。
有意思的是,2014年,James Dicarlo首次尝试使用CNN来直接预测IT神经元的活动。他们将同一张图片展示给猴子以及CNN模型,在利用线性回归直接根据CNN对图片的表征去预测在猴子IT脑区记录到的电信号。他们惊人的发现,仅通过简单的线性方法就可以从CNN的表征预测出IT的脑区活动,这说明两者表征的信息是十分相似的。
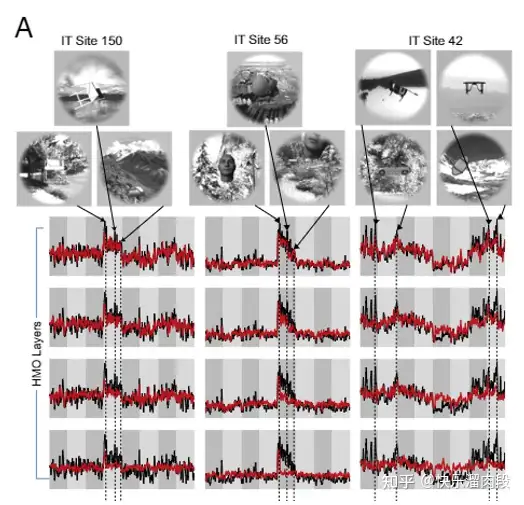
利用数学模拟的AI模型去预测脑区电信号,当实验结果趋同时,也意味着神经元架构和数学模型基本相同,这种新的研究范式正在反向助力神经科学的探索(比如当下最火的AI预测蛋白)!

空间感(定位和导航)
通过空间通路,人可以很好的理解所观察到的物体在空间维度内和人的关系,从而得以判断和操作该物体。
太阳的东升西落,城市的东西南北,过马路要左右看……在人们的日常生活中,大脑的空间感知作用扮演着重要角色。无论是寻找方向、定位目标还是记忆场景,都需要大脑对空间信息的处理和记忆。
很遗憾的是,人类对此空间通路机制的研究,非常浅薄,对腹侧通路(物体识别功能)的神经通路的数学量化复现相当成功。
目前主流研究仍在通过小白鼠、猴子等哺乳动物实验,继续寻找空间感所涉及的神经单元及细分作用(仍未找齐,目前仅发现世界中心编码和自我中心神经元),各个单元如何相互作用以及如何集成编码,我们仍未探知清楚。空间感神经元与海马体(记忆)紧密联系。
幸运的是,科学界对神经科学空间感热情高,对此脑区的研究产出高。
- 自我中心细胞(前后左右-自己移动坐标系)主要负责以个体自身为参考点的空间信息处理。这意味着它们编码的是相对于观察者位置的物体或环境特征,如身体周围的边界或地标。当我们移动时,这些细胞会根据我们的视角变化来调整它们的活动模式,帮助我们感知方向和距离的变化。
- 世界中心神经元(东西南北-固定坐标系坐标系)则关注于环境中的绝对位置信息,它们编码的是不依赖于观察者位置的环境布局,比如一个房间的固定角落或地图上的绝对坐标。这些神经元帮助我们理解环境的全局结构,即使我们的位置改变,它们提供的信息依然保持稳定。
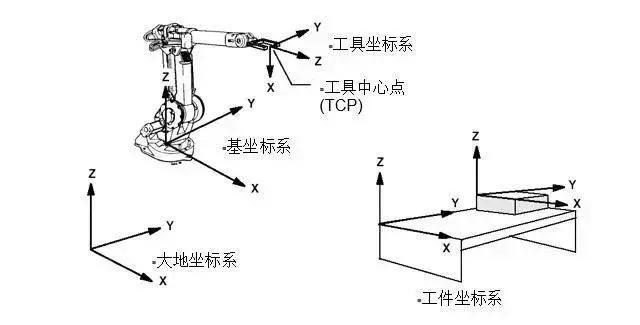
- 经典力学:一个物体简单移动需要至少两个坐标系:自己的坐标系和固定坐标系,如果要操作物体,则还需要物体的坐标系(如上图),才能清晰的表达各个位置关系,而运动控制算法就是在各个坐标系中求最优解。
世界中心的编码方式是建立在自我中心编码的计算和转换上的。换言之,相比起处理 ‘前后左右’的位置信息,大脑在处理‘东西南北’的位置信息要经过更为复杂的编码过程。
2 注意和意识
这部分我主要讲述注意,意识部分在上面已经有所提及。
想象你在参加一个鸡尾酒会,身边有人低语,有人高谈阔论,偶有玻璃碰杯声音,远处还有乐队在演奏。在这么嘈杂的环境中,你依旧能够听到身边的朋友在说什么。这不仅仅是因为你们离得近,更重要的是,你将注意力集中在了她身上。注意力让你「选择」把有效的认知资源都用于在一堆嘈杂的信息中,寻找、分析她的声音【14】。
这就是著名的「鸡尾酒会效应」。
注意力是一个用来分配有限的信息处理能力的选择机制。感知系统在做信息加法,那么注意力就是在做减法。
“少则得,多则惑,是以圣人抱一为天下式”-道德经
随着进化的脚步,生命体本身由简至繁,而人类历史发展到今天,我们的生存环境和所需要学习、掌握的工作任务和过去的丛林生活复杂到不知多少。为了应对这个变化,大脑会如何进化呢?是发展成一个同时处理庞大的信息并且容量超大的大脑,还是发展成虽然容量不大,但可以迅速地分析信息,并配有一个高效率信息选择和投注机制,将所有计算能力都放在重要的任务上的大脑呢?很明显的,后者更有优势,而且大自然也为我们选择了这个目标。这个「高效率信息选择和投注机制」就是我们说的「注意力」(attention)。
注意力是指,选择性地专注在某些感受到的信息上,这些信息可能是客观或主观的,同时忽视同一时刻收到的其他信息。这一个认知过程。
机制:注意力通过信号控制(关注的信息兴奋,不关注的信息抑制),锁定相关脑区的工作状态,同时加强相关脑区的连通性,削弱其他联通性,让我们的大脑临时性、软性的改变结构,变得“任务特异化”。
这种认知资源和认知资源协同状态的预锁定,就像对大脑这台计算机的“虚拟化”,预先写好资源请求参数,并预装了所需要的程序执行和依赖环境。
一切源于2017年谷歌Brain团队那篇鼎鼎大名的文章“Attention Is All You Need”(注意力就是你所需要的一切),就是这篇文章提出了以自注意力为核心的Transformer网络结构。
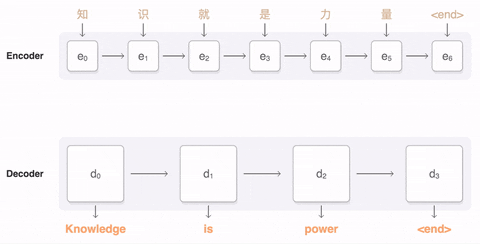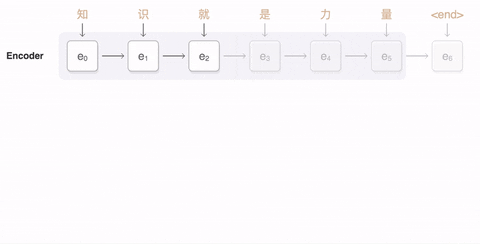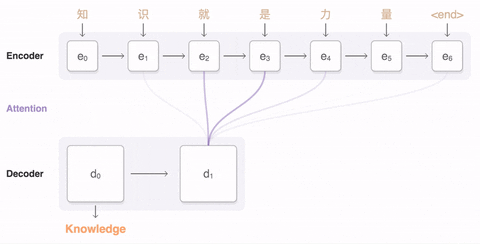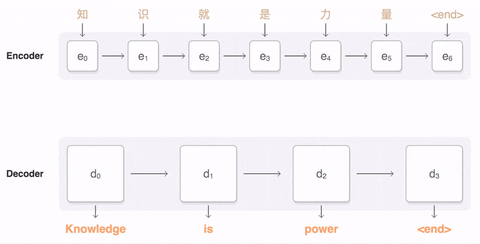
在自注意力机制下,输出的内容加权平均了输入,既考虑了输入的全面性,也考虑了输入的个别单词的相关性,从而更有针对性的理解句子中的含义并输出理解。
3 学习和记忆
学习 (learning)是获取新信息的过程,其结果便是记忆(memory)。也就是说,在学习了某样东西后,记忆便形成了,这种学习也许会发生在信息的单次呈现后,也许是在信息的重复呈现后。记忆必须是能够在一段时期内维持的【12】。
学习与记忆可以假设为三个主要的阶段,不断循环:
编码(encoding)是对输入信息的处理与储存它分为两个阶段:获取与巩固。
- 获取(acquisition)是对感觉通路和感觉分析阶段的输入信息进行登记,外部信号转换为内部可处理信号-电和化学信号,例如计算机转化为0和1(二进制);
- 巩固 (consolidation)是生成一个随时间的推移而增强的表征,进行特征提取和推理。
- 学习是大脑获得经验的过程,即中枢神经系统收集感觉器官和记忆的神经电位的过程-神经元形成连接(突触的可塑性),并保持兴奋与协调,直至形成记忆(神经元的连接),一般分为两种,简单学习与复杂学习。
存储(storage)是获取和巩固的结果,代表了信息的长久记录。
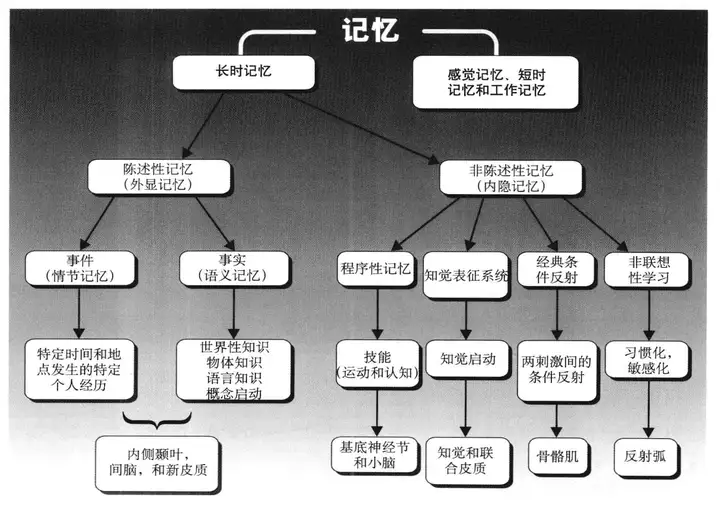
记忆则是对学习过程的储存,即中枢神经系统储存感觉器官的神经电位,一般也分为两种,短时记忆和长时记忆。
短时记忆是中枢神经系统对于刺激的瞬间记忆,是对刚刚发生事情的片刻记忆,这样的记忆往往只能维持几秒钟或几分钟。而当片刻记忆的刺激,重复作用于中枢神经系统时,便会形成对事情的长时记忆。
提取 (retrieval)是通过利用所储存的信息创建意识表征或执行习得的行为,如自动化动作。对学习机制的再次刺激,直至形成长期记忆。
有意思的是,人类的记忆向来不太准确,大家可以试着回想一下上周的事情,能不能像计算机的视频一样每一帧都能高清的回想起来?
4 语言
语言有两种形式:1 表达 2 语言推理(最重要)。
语言可以是某个语言上命名好的东西,也可以只是一种”表征”(representation)【15】。我们可以在不说话的情况下,直接使用这个“表征“进行思考、推理等等。所以常常有思维比口头表达更快的体验,而且如果口头说的比较快的话,经常会说错而不自知。也就是说,语言可以是更广义的概念。而这种推理和逻辑思考能力,我们称为Verbal Reasoning!
这里可以看出,“语言”(广义的)跟思考具有非常直接的关系。有了语言,我们能在大脑中思考的时候对事物形成“表征”。传统上,我们认为,为了方便思考,特别是在谈话和阅读中思考,我们会首先将口头语言中的对象物转化为大脑中的“表征”,这是一种”语言过程” ,然后使用这些“表征“进行演绎和推理,这是一种非语言过程,最后将结果转换为口头语言对象(表达)。
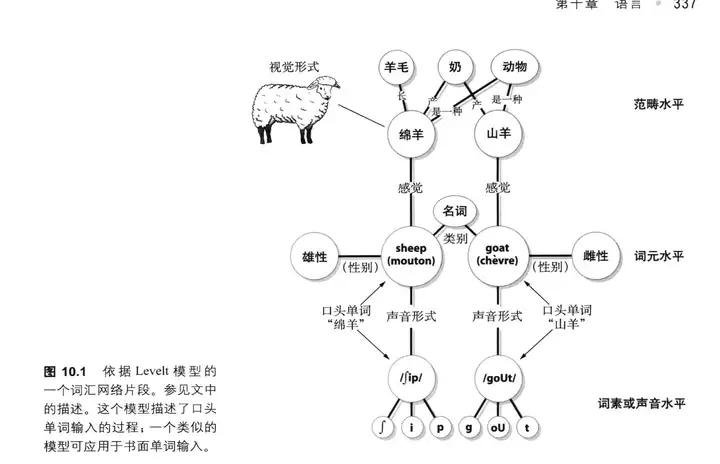
在整个过程中,从语言对象到大脑内在表征,以及从大脑内在表征到语言对象的两部转换自然是跟语言直接相关的。对应的,还有图像推理(Visual Reasoning),也就是直接使用视觉或者图像表征进行空间构建或者关系推理的过程,典型地比如玩俄罗斯方块。
既然有图像推理,那么,语言介质(广义的)就并非思考的必要条件,但是为最主要条件。
狭义上来说,人类就是用语言来进行高级思考的,输入的信息➡️形成表征➡️根据表征的特征,寻找匹配的语言形容➡️内在表征以语言的形式演绎推理➡️表达;
语言与思想的关系被认为是相互依存的。一方面,语言提供框架来组织和表达思想;另一方面,思想的边界可能受限于语言的表达能力。语言的使用不仅反映思想,也可能塑造思想,如母语对思维模式的影响。
5 运动控制
运动功能分为运动计划(同步感觉和运动信息后进行位置和轨迹预测空间编码)、运动准备(小脑-专门表征动作的时间特性的结构,控制节奏;基底神经节转化信息为动作信息)以及和运动执行(调动分布式专门运动神经系统)。
运动控制依赖于广布的解剖结构,这些广布的运动结构以层级式的方式进行运作:最高层计划最好以动作如何实现目的来描述,底层的运动层级致力于将目标转化为运动。最底层是实现一个特定动作的具体指令,最高层是动作目的的抽象表征。
然而运动计划和学习是同时发生在各个层级上的。学习发生在所有的层级。运动控制上解耦,运动学习上强耦合!
我们对机器人的控制理论仍然是数字自动化控制(预定和固定流程控制-PID等),关于对控制的神经网络设计(适应开放场景,鲁棒性高,泛化性强)才刚刚开始,具体看具身技术部分。
6 情绪
情绪的作用在动物中激励目标的实现和躲避危险的功能。
情绪识别不仅仅是单一神经元或区域的工作,而是涉及广泛的大脑网络。例如,视觉皮层首先处理情绪刺激的视觉信息,然后传递到包括杏仁核在内的边缘系统,进一步的处理涉及前额叶和其他高级认知区域,以综合信息并做出情绪反应。
由意大利理工学院科学家弗朗切斯科·帕帕莱奥领导的研究团队,发现了使人类能够识别他人情绪的大脑网络。识别他人表情并作出适当回应,是人类和动物的基本技能,这能使同伴间的互动更有效,从而提高生存概率。但对这一能力背后的大脑机制,人们仍知之甚少【16】。
使用荧光显微镜拍摄的神经元图像。图片来源:意大利理工学院
7 认知控制
认知控制 (cognitive control) 是指个体在特定的情境中,自上而下的灵活地调动认知资源来调整想法和行为的一种目标导向的心理过程;认知控制包括计划、控制和管理信息加工流的心理能力–调度资源和监控反馈保证目标导向行为的成功。
目前研究热点是认知控制的一般性/特异性机制。所谓一般性(大脑的泛化性),是指不同任务之间共享相同的加工机制 ;相反地,特异性(任务的专用性)是指不同的任务各有特异性的加工机制。
当两个任务之间的差别大到可以归为两类时,他们之间就产生了边界 (boundary)。因此,认知控制的一般性 / 特异性很可能不是非此即彼的。
这提示我们,大脑在进行信息加工时有一定的泛化能力,并不局限于具体的任务。但是这种泛化能力不是无限的,如果任务之间的差异达到了一定的程度,大脑会形成不同的功能模块来分别进行加工,这样能够保证在面对外界刺激时有最为高效的反应。从进化的角度来看,这种高效加工对人类适应环境也是极为有利的。
对认知控制的资源调度和监控反馈机制的研究可以让大模型(泛化)在应用(专用)时,进行特异化工程(形成洞悉),有效解决专用性不足的问题(通用大模型如何变成垂直大模型)。
8 大脑进化
1.智能史的第一次突破:两侧对称动物都有个脑子来趋利避害、整合信息、持续学习和情感惯性,发源于线虫–一切都是为了活下去【17】。

2. 智能史的第二次突破:脊椎动物的硬质骨骼催生了更大的身体、能够容纳更大的脑,大脑开始可以简单的强化学习(有明确的目标,但都是现实环境的目标)和好奇心(仅仅探索了未知区域满足好奇心、也应该得到强化鼓励);
强化学习-以“试错”的方式进行探索学习,通过与环境进行交互获得的奖赏(多巴胺是人强化学习的奖赏)指导行为,目标是为了最多的奖励;AI代表 -「时序差分学习(temporal difference learning)」,是现在强化学习的基本原理,包括AlphaGo也是这么做的。
3.智能史的第三次突破:依托于无监督学习、把同样的脑回路排队复制–神经元数量大爆炸(人类大脑中新皮层已经占整个脑容量的70%),新皮层创造出“在想象力中用强化学习模型思考”;哺乳动物的“新皮层”做模拟学习,是从自己的想象中学习(GPT-4 的阶段)。
人类新皮层玩的是无监督学习–无人指导的学习。大自然中的动物不可能搞监督学习,因为没有老师告诉它每一个东西是什么。你得自己摸索。而新皮层摸索的方法,恰恰就如同现在训练GPT一样,先读取一半信息,再自己「生成」下一半信息,然后把生成的信息跟训练素材比较。对了就加强,错了就改进。
对大脑来说,「生成」就是「模拟」,就是「想象」。
用模型思考:替代性试错-建模、反事实学习-辩证思考得到因果关系、情节记忆-具体事件的记忆。
纯粹的强化学习是只用直觉。有犹豫的,就是基于模型的强化学习(奖励是想象出来的,不是实际的)。现在几乎所有自动驾驶AI都是纯粹的强化学习,根据直觉直接行动,没有犹豫。但是应该有犹豫才好。
- 丹尼尔·卡尼曼说的系统1,也就是快思考,其实就是强化学习带来的本能反应,由基底神经节自动选择;卡尼曼所说的系统2,慢思考,其实就是前额叶皮层感觉到了冲突,先暂停自动反应,发起模拟再做选择,也就是基于模型的强化学习。
- 爬行动物全都是系统1思维。我们日常大部分时候也都是系统1思维。这很好,这使得我们做开车、走路、吃饭喝水这些日常动作都不需要思考,我们很轻松。只在矛盾时刻,我们才需要调用昂贵的新皮层算力去进行模拟。
OpenAI GPT4-草莓大模型(自我强化学习-RL新范式)已经发布:
你需要对一个问题建立多个智能体(agents),让每个智能体各自生成答案。选择最合适的一个,再输出。这两步加起来就是系统2思维。
而现今的大语言模型基本上只是系统1思维,纯直觉输出。但我们可以想见,跨越到系统2在技术上一点都不难,难的只是算力而已 —— 毕竟一切都是新皮层。
4. 有了心智理论,灵长类动物可以通过模仿另一个人做事来学习,也就是从他人的行动中学习(模仿学习)和群体生活(政治博弈-对抗学习)让大脑变得越来越大。
- 随着爬上食物链的顶端,我们获得了「空闲时间」。别的动物全天都得要么觅食、要么求偶、要么休息,而我们却有时间做点别的事情。
- 最早的哺乳动物的大脑只有0.5克,而到一千万年前,灵长类的大脑已经达到了350克,为什么我们需要这么大的大脑呢?现在科学家的共识是,为了搞政治。
- 与天奋斗、与地奋斗都不需要那么大的大脑,只有与人奋斗最费脑。看来还是与人奋斗其乐无穷。
- 最重要的理论贡献来自那个著名的「邓巴数」的提出者,罗宾·邓巴(Robin Dunbar)他发现灵长类动物的大脑新皮层的大小,和它所在群体的大小是成正比的关系。
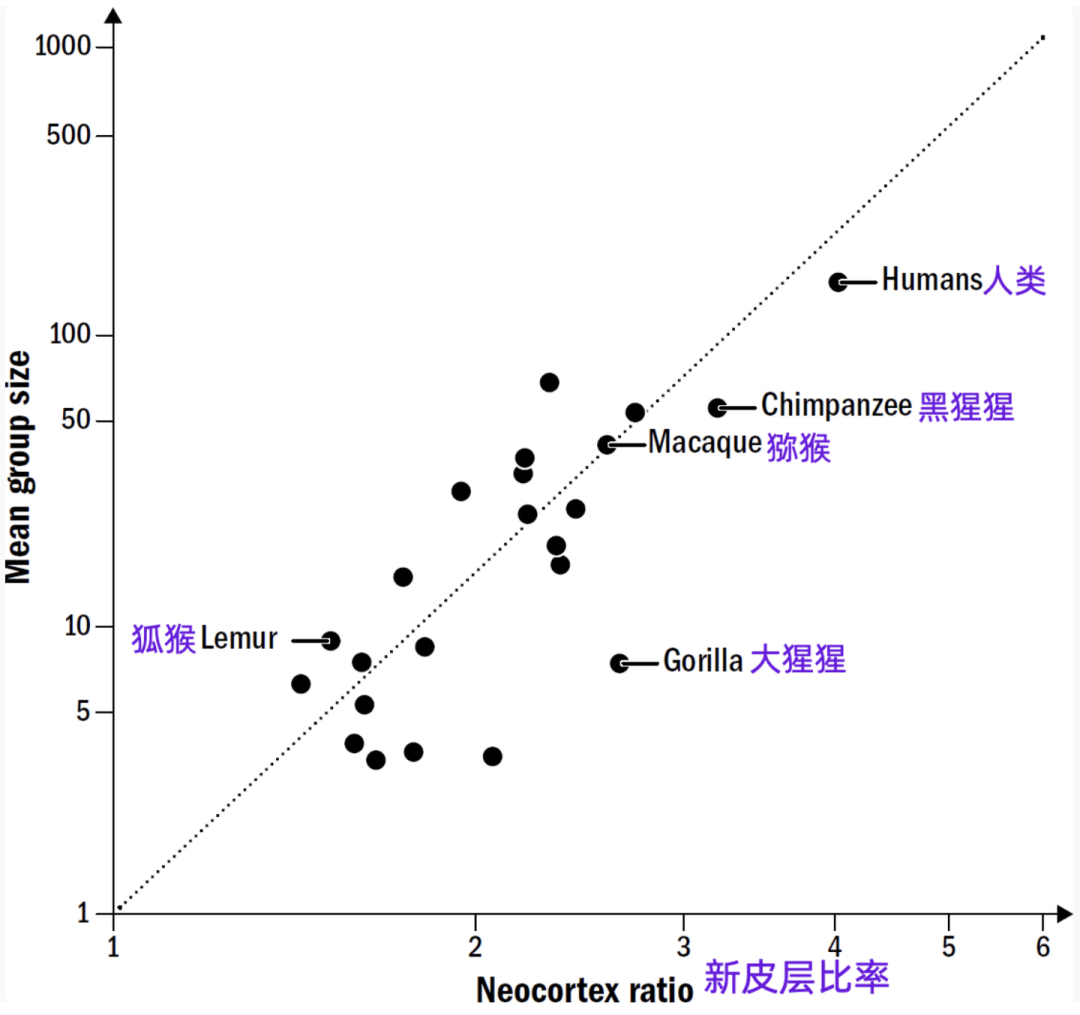
- 群居的麻烦是容易内耗。食物可能还好说,如果吃草的话谁都能吃到,但是交配对象就只有这么多,属于绝对的零和博弈,势必引起争斗。
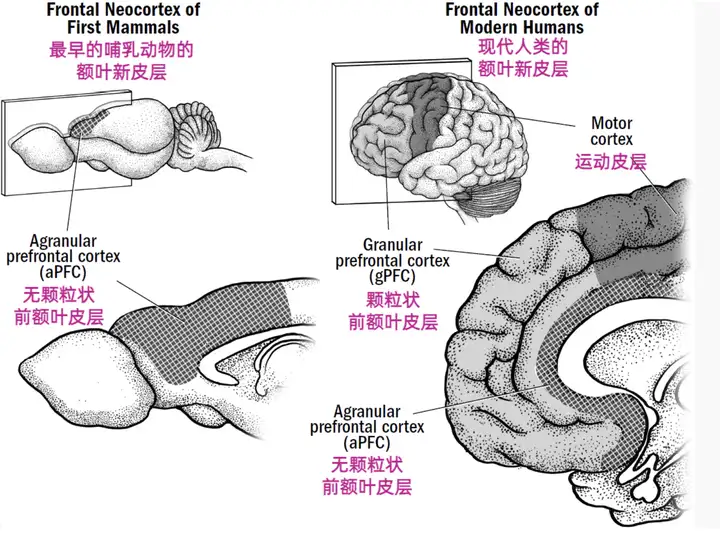
- 要玩政治,灵长类的大脑有个硬件基础。我们的大脑不只是比早期哺乳动物大,而且新皮层多了两个新的脑区:颗粒状前额叶皮层(gPFC)和灵长类感觉皮层(PSC)。
- 我们前面讲的哺乳动物的前额叶皮层说的是无颗粒状前额叶皮层(aPFC),现在这个gPFC是灵长类特有的,它跟PSC配合,让我们获得了一项新能力。这个能力也是新皮层的拿手好戏 —— 模拟和预测 —— 只是这一次是把自身放入情境之中模拟。
- 换句话说,gPFC能够让我们以第三人称的视角看自己,能跳出自我观察自我。
- 这种能把自己当做“他者”–换位思考,从高处旁观的能力,就是心理学家和哲学家说的「元认知(metacognition)」。
5.智能史的第五次突破:语言,语言让大脑和大脑联网。以前的我们是单独的个体,现在我们是网络中的一个个节点;有了语言,智人则能够从他人的想象中学习、知识开始爆炸性积累。(群体的智慧!)
- 语言带给我们的不只是一项个人能力,更是一项积累知识和建设文明的能力:语言能让说话的人把自己内心想象的场景和动作,传递给听话的人。这个功能大大提高了交流的效率。
- 到了这一步,知识已经不只是存在于人脑之中,更是存在于人脑之间,成了某种近乎独立的存在。人脑只是知识的载体而已,知识本身好像有了生命力。
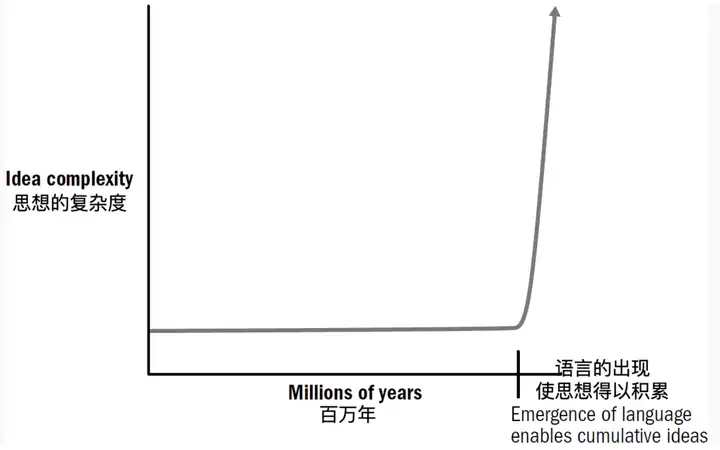
我们的祖先们,不断持续的优化和补充神经回路机制,神经元的数量飙升,同时配对上好的学习范式,最终要形成精简的功能(皮层or脑区 and 针对性功能的特异回路),才能实现真正的智能!
实现真正的涌现能力!
AI的涌现能力是指随着模型规模变大,模型突然在某一刻拥有了以前没有的能力-大型语言模型在未直接训练过的任务上表现出惊人性能的能力。
神经网络不是黑箱!只是因为我们尚未了解以及计算量过大。
神经学对AI的影响大讨论-鸟飞派和伪鸟派
当人们最初想要制造飞行器的时候,是希望模仿鸟的飞行方式,制造出像鸟一样飞行的机器。后来人们发现,这样的制造方法并不可行,可能不仅实现难度大,而且还不稳定,blablabla…(非专业人士,只是猜测)于是莱特兄弟想出了另一种制造飞行器的方式,相比于模仿鸟类的飞行方式,这种飞行器的工作方式更简单,更安全,更…【18】

这群试图完全模仿鸟类飞行方式来制造飞行器的人,在后世被称为“鸟飞派”,莱特兄弟制造出的飞机则告诉我们,鸟飞派不一定是最有效的工程方法。而他们造出的“伪鸟”,才是更可取的飞行器制造方案。
同样,人工智能发展的初期也有一波“鸟飞派”学者,他们认为只有完全用机器实现大脑的结构,才能制造出一台和人类拥有相似功能的机器大脑。然而这并非是现实的,无论是放在人工智能发展的初期还是放在工业技术更加发达的现代。
原因包括:a人脑拥有上千亿个神经元,神经元之间还有数量更多的连接。要实现这些连接绝不是一件容易的事情。b这些神经元之间是怎样连接,以实现复杂的功能的,目前神经科学家们所知甚少。
2022年的一个周末,twitter上的神经科学圈发酵了一起不大不小的争论,引得领域内好几个著名学者,包括Yann Lecun的参与。最初争论的是神经科学是否推动了人工智能,后来就更多变成了未来的人工智能是否需要神经科学。中国在类脑智能领域的投入也在增加,“该不该类脑”以及“如何类脑”这样的问题都值得在广泛范围内讨论–详见饶毅事件。【19】
争论的起点10月15号时候,神经科学领域和人工智能领域一群大佬,如Terry Sejnowski, Yoshua Bengio, Yann LeCun,Eero Simoncelli, James DiCarlo, Alex Pouget 以及今天争论的主角Konrad Kording, 在arXiv上发表了一篇白皮书文章文章的观点非常简单,摘要只有两句话:
Neuroscience has long been an important driver of progress in artificial intelligence (AI). We propose that to accelerate progress in AI, we must invest in fundamental research in NeuroAI.
概括起来就是:神经科学+人工智能非常有前途,政府请打钱。
没想到两天后,可能是周末比较清闲,来自DeepMind的David Pfau对着Kording的这篇tweet开喷了:神经科学从来都没推动过人工智能,你们白皮书中还说continue to drive AI progress你们真的认为发明Transformers / ADAM的人看过一篇神经科学论文吗?你们就假装在为人工智能做贡献吧。要点脸吧 “it’s embarrasing”(原文)
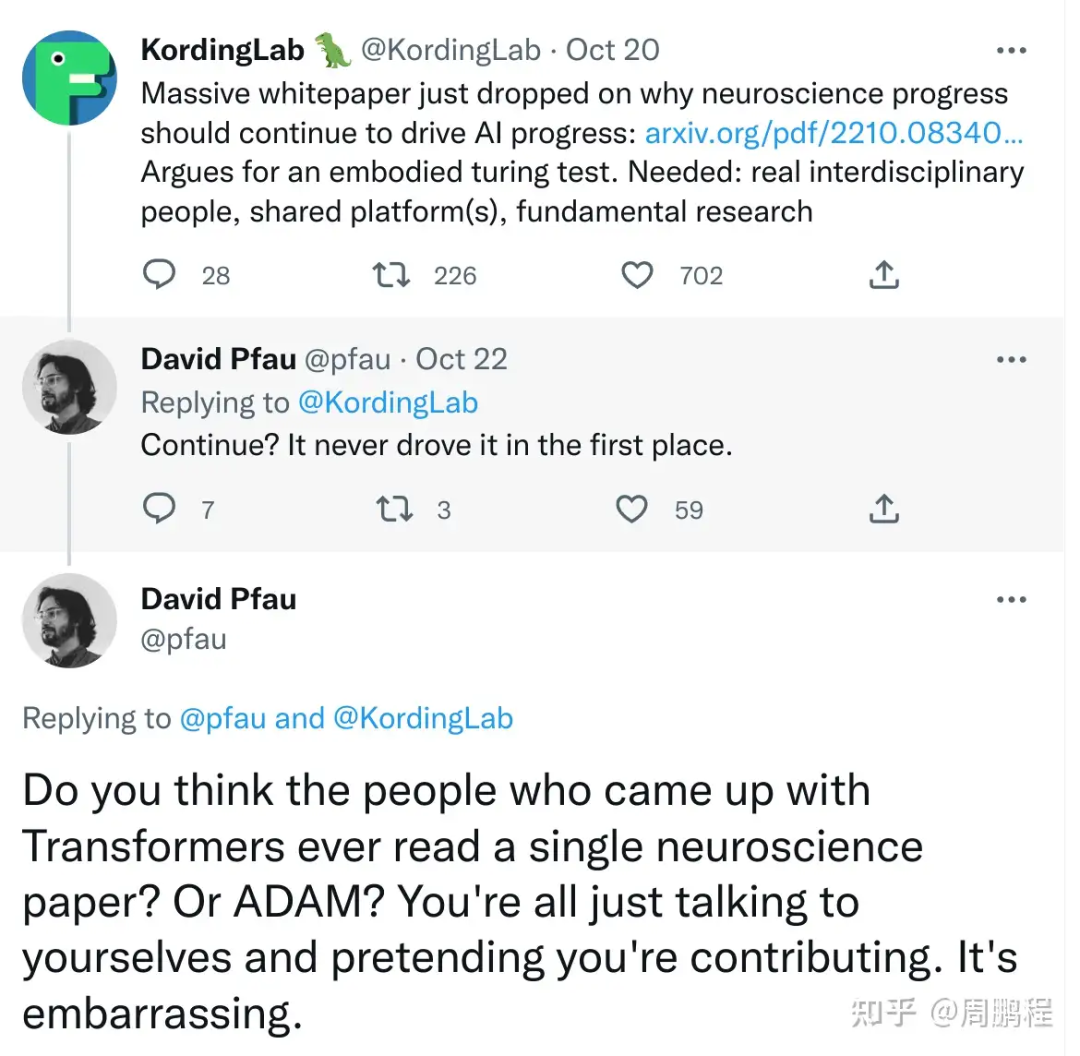
这样的回复立马就炸雷了,引起了后面很多人的“参战”。这里简单提一下这位Pfau,他其实是正儿八经的神经科学博士,毕业于哥伦比亚大学的神经生物学专业,附属于Center for Theoretical Neuroscience (CTN)。并且在CTN里边有Larry Abbott和Ken Miller等计算神经科学大佬,毕业生中走出了很多在人工智能领域的佼佼者,如David Sussillo,Pfau对于这神经科学和人工智能两个领域都不陌生。
Pfau的评论一出,上文我们所提到的David Sussillo就出来说话了过去几年,我在Google Brain跟Transformer的主要贡献人交往很多。我虽然不能冒昧地推定到底是什么启发了他发明transformer,但是他对神经科学是发自内心的感兴趣,问了很多神经科学的问题。
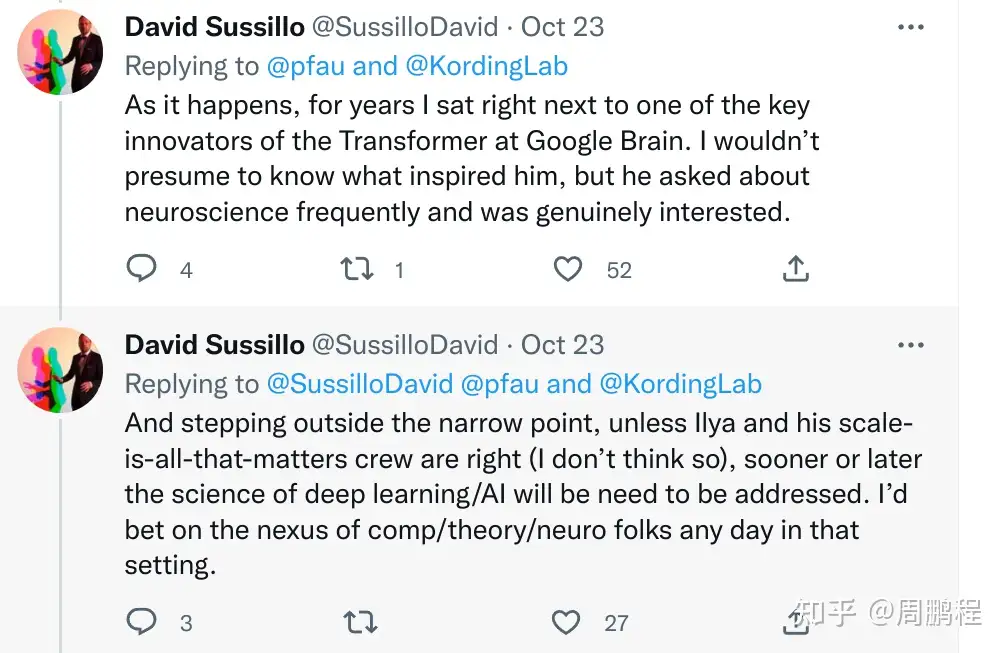
Yann Lecun大佬出马,直接就一句”You are wrong”甩到Pfau老兄脸上了:你错了 。神经科学极大并且直接启发了我和Hinton,另外神经网络通过调节突触权重来实现学习这一整套想法确定无疑来自神经科学。
- 1 在应对不同的任务,人的神经元机制反而不如计算机文档(人的记忆不准确,但计算机存储准确等),两者需要结合,不必完全模拟人脑,实际看效果;
- 2 了解神经基础机制会给当前的AI带来底层创新(深度学习-神经元机制,CNN-猫视觉皮质层,transfomer-注意力机制等等!)。
- 目前神经科学还处于初级阶段,作为最热门的学科之一,已经是最好的时代。
笔者认为如今神经学的研究会在两大方面极大的推动AI的发展:
- 1 (人脑进化的现成结果)对现有人脑神经系统机制的突破研究:特别是理解某一功能的神经环路;直接在计算机上复刻实现。
- 2 神经系统改善进化机制:神经系统如何优化和调整神经回路机制;赋予计算机自我智能进化的能力。
总结
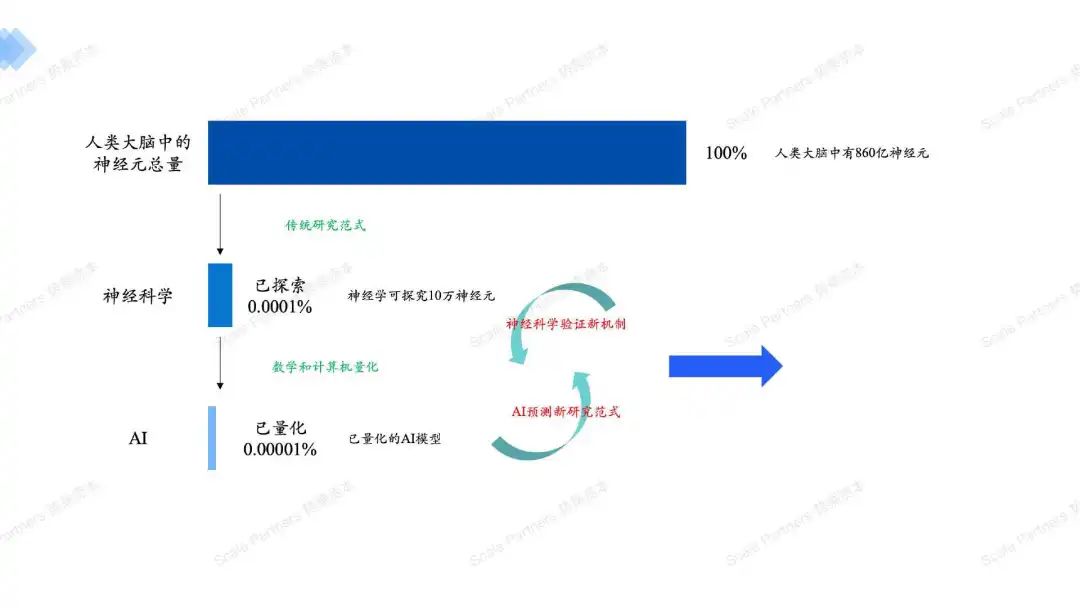
AI模型预测作为新的研究方法也在助推神经科学的发展,在探索完神经学原理后,又帮助ai发展,两者螺旋上升。还有大量神经元原理未被量化,技术天花板尚未显现!
三、AI技术流派原理与发展
(1) 总体流派类别原理和历史
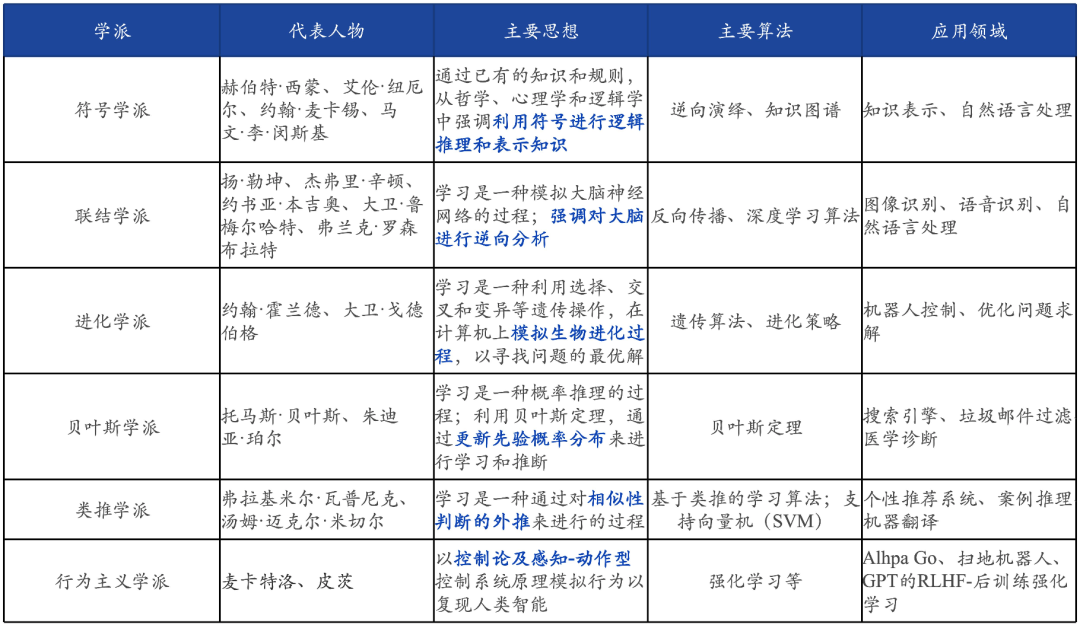
在人工智能的发展过程中,不同时代、学科背景的人对于智慧的理解及其实现方法有着不同的思想主张,并由此衍生了不同的学派,影响较大的学派及其代表方法如下:
学派之间的范式方法早已融合贯通,以神经网络深度学习的联结主义是目前主要贡献学派,学派之争都在想深度学习神经网络的联结主义收敛。
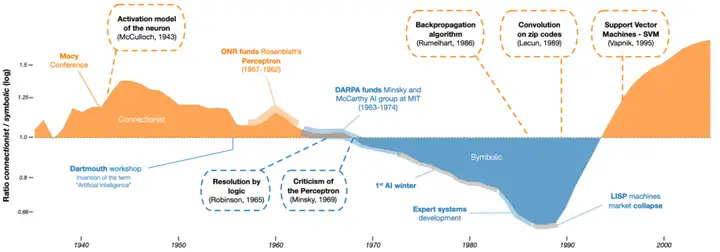
其中,符号主义及联结主义为主要的两大派系【20】:
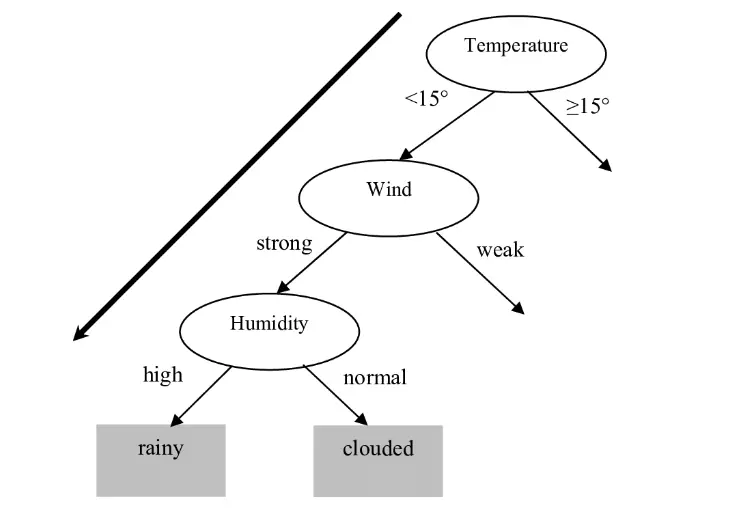
“符号主义”(Symbolicism),又称逻辑主义、计算机学派,认为认知就是通过对有意义的表示符号进行推导计算,并将学习视为逆向演绎,主张用显式的公理和逻辑体系搭建人工智能系统(已有知识的数学复刻)。如用决策树模型输入业务特征预测天气:
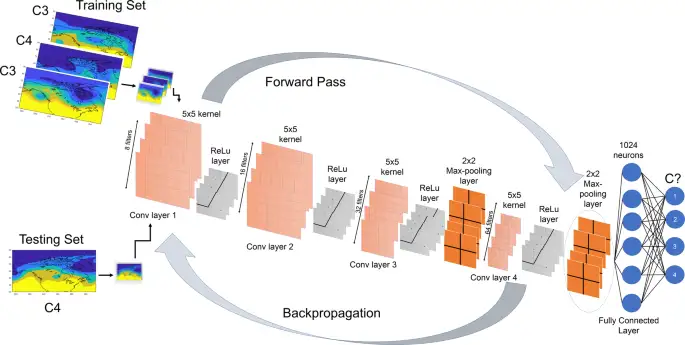
“联结主义”(Connectionism),又叫仿生学派,笃信大脑的逆向工程,主张是利用数学模型来研究人类认知的方法,用神经元的连接机制实现人工智能。如用神经网络模型输入雷达图像数据预测天气:
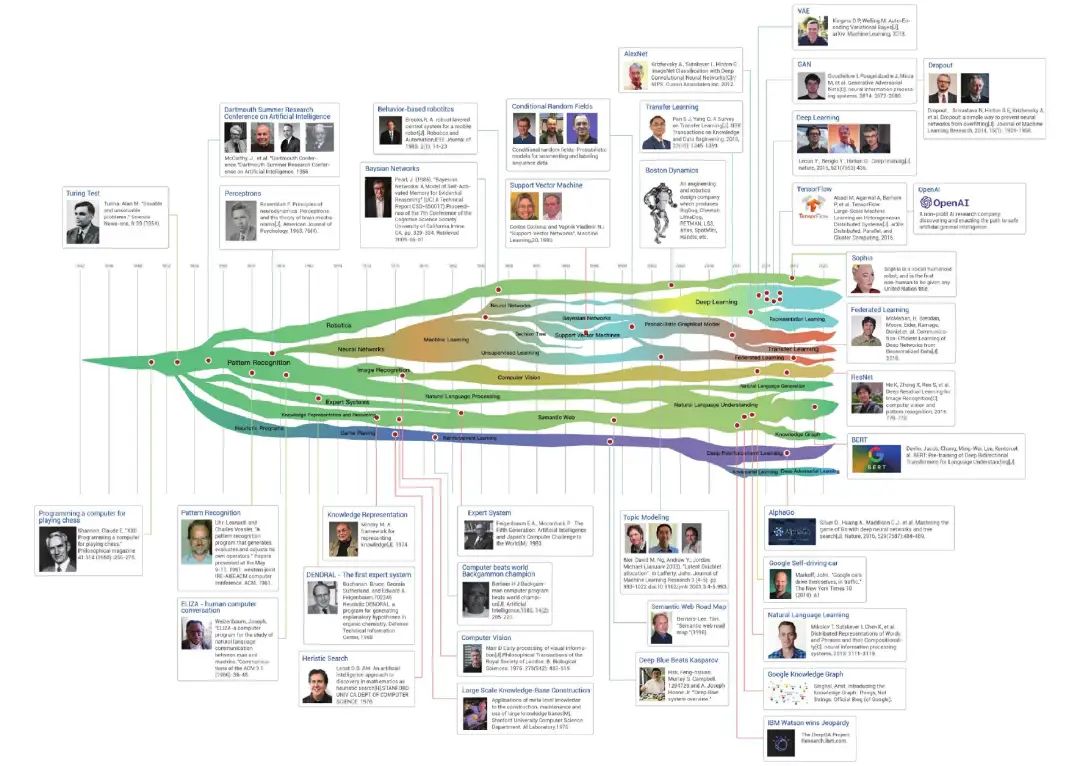
从始至此,人工智能(AI)便在充满未知的道路探索,曲折起伏,我们可将这段发展历程大致划分为5个阶段期(笔者罗列了关键的事件):
起步发展期:1943年—20世纪60年代
人工智能概念的提出后,发展出了符号主义、联结主义(神经网络),相继取得了一批令人瞩目的研究成果,如机器定理证明、跳棋程序、人机对话等,掀起人工智能发展的第一个高潮。
1943年,美国神经科学家麦卡洛克(Warren McCulloch)和逻辑学家皮茨(Water Pitts)提出神经元的数学模型,这是现代人工智能学科的奠基石之一。
1950年,艾伦·麦席森·图灵(Alan Mathison Turing)提出“图灵测试”(测试机器是否能表现出与人无法区分的智能),让机器产生智能这一想法开始进入人们的视野。
图灵在一篇论文中开门见山问道:
“I propose to consider the question, ‘Can machines think?’”
“我提议思考这样一个问题:‘机器可以思考吗’”
以此拉开AI的序幕,激发当时刚刚兴起的计算机科学领域对AI的思考。
1956年,达特茅斯学院人工智能夏季研讨会上正式使用了人工智能(artificial intelligence,AI)这一术语。这是人类历史上第一次人工智能研讨,标志着人工智能学科的诞生。
1957年,弗兰克·罗森布拉特(Frank Rosenblatt)在一台IBM-704计算机上模拟实现了一种他发明的叫做“感知机”(Perceptron)的神经网络模型。
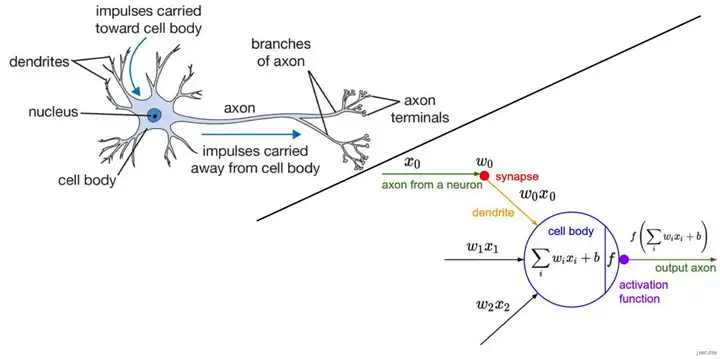
1969年,“符号主义”代表人物马文·明斯基(Marvin Minsky)的著作《感知器》提出对XOR线性不可分的问题:单层感知器无法划分XOR原数据,解决这问题需要引入更高维非线性网络(MLP, 至少需要两层),但多层网络并无有效的训练算法。这些论点给神经网络研究以沉重的打击,神经网络的研究走向长达10年的低潮时期。
反思发展期:20世纪70年代
人工智能发展初期的突破性进展大大提升了人们对人工智能的期望,人们开始尝试更具挑战性的任务,然而计算力及理论等的匮乏使得不切实际目标的落空,人工智能的发展走入低谷。
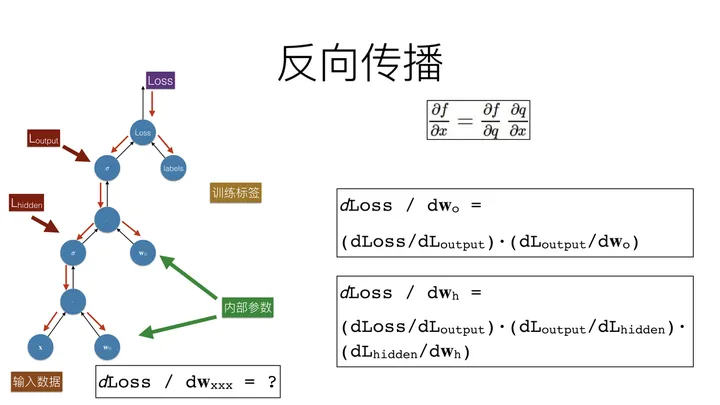
1974年,哈佛大学沃伯斯(Paul Werbos)博士论文里,首次提出了通过误差的反向传播(BP)来训练人工神经网络,但在该时期未引起重视。
1975年,马文·明斯基(Marvin Minsky)在论文《知识表示的框架》(A Framework for Representing Knowledge)中提出用于人工智能中的知识表示学习框架理论。
1979年,汉斯·贝利纳(Hans Berliner)打造的计算机程序战胜双陆棋世界冠军成为标志性事件。(随后,基于行为的机器人学在罗德尼·布鲁克斯和萨顿等人的推动下快速发展,成为人工智能一个重要的发展分支。格瑞·特索罗等人打造的自我学习双陆棋程序又为后来的强化学习的发展奠定了基础。)
应用发展期:20世纪80年代
人工智能走入应用发展的新高潮。专家系统模拟人类专家的知识和经验解决特定领域的问题,实现了人工智能从理论研究走向实际应用、从一般推理策略探讨转向运用专门知识的重大突破。而机器学习(特别是神经网络)探索不同的学习策略和各种学习方法,在大量的实际应用中也开始慢慢复苏。
1980年,在美国的卡内基梅隆大学(CMU)召开了第一届机器学习国际研讨会,标志着机器学习研究已在全世界兴起。
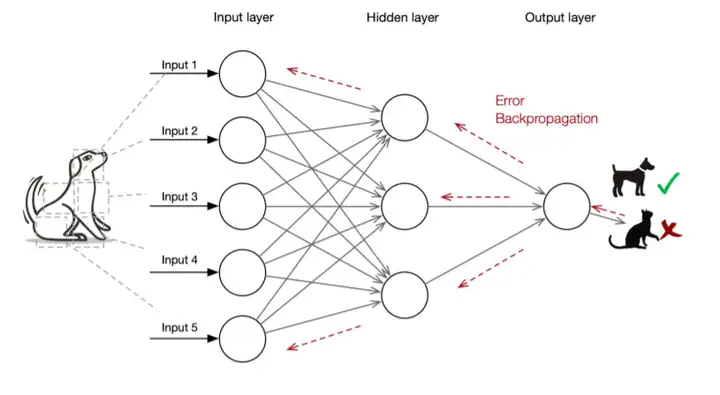
1982年,约翰·霍普菲尔德(John Hopfield) 发明了霍普菲尔德网络,这是最早的RNN的雏形。霍普菲尔德神经网络模型是一种单层反馈神经网络(神经网络结构主要可分为前馈神经网络、反馈神经网络及图网络),从输出到输入有反馈连接。它的出现振奋了神经网络领域,在人工智能之机器学习、联想记忆、模式识别、优化计算、VLSI和光学设备的并行实现等方面有着广泛应用。
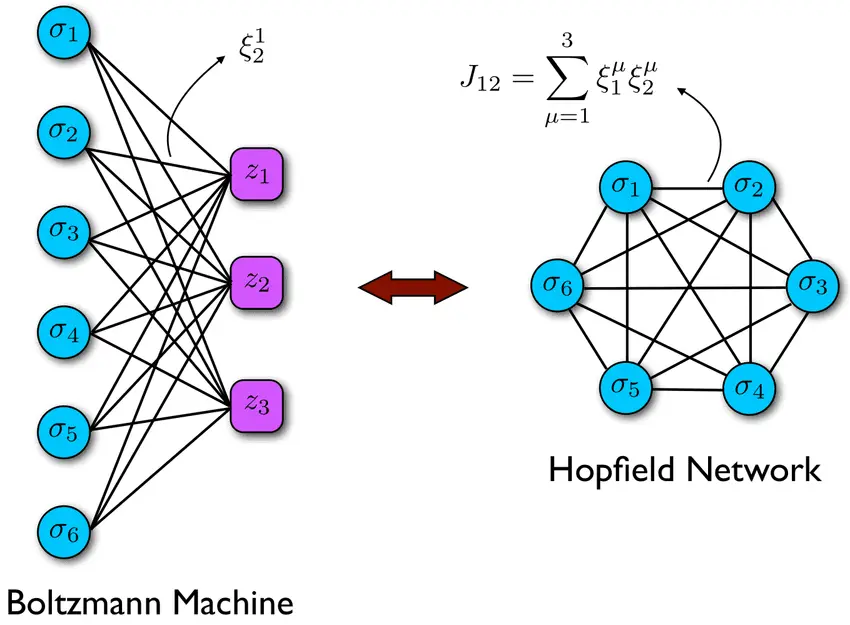
1983年,Terrence Sejnowski, Hinton等人发明了玻尔兹曼机(Boltzmann Machines),也称为随机霍普菲尔德网络,它本质是一种无监督模型,用于对输入数据进行重构以提取数据特征做预测分析。
1985年,朱迪亚·珀尔提出贝叶斯网络(Bayesian network),他以倡导人工智能的概率方法和发展贝叶斯网络而闻名,还因发展了一种基于结构模型的因果和反事实推理理论而受到赞誉。
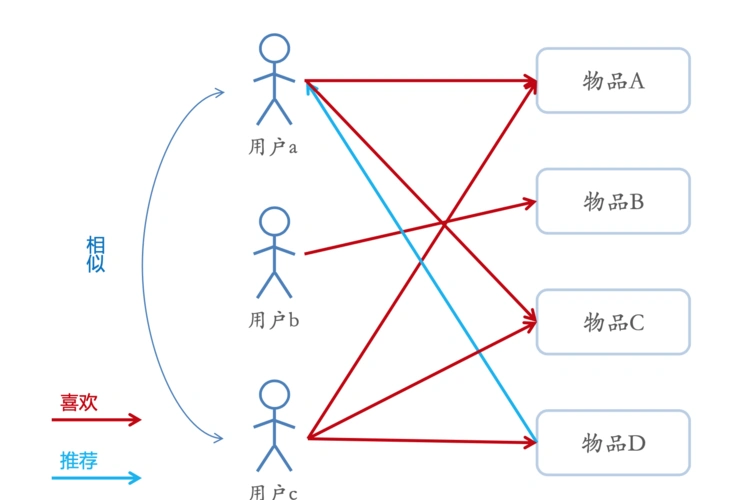
个性推荐算法简介:用户c看过物品a,c,d,用户b看过物品b,与用户c的喜好不重合,用户a看过物品a,c,由此可以推测用户a与用户c相似,可以推荐物品d给用户a;当然后续技术添加了组标签等新算法,使得推荐算法更加精确,推荐算法成为了新一代互联网的核心护城河!任何互联网平台都离不开推荐算法,抖音,小红书等推荐机制吸引了大量的注意力,便由此通过广告变现,成为新一代互联网龙头。
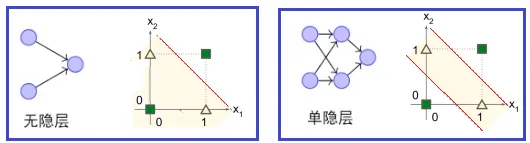
1986年,辛顿(Geoffrey Hinton)等人先后提出了多层感知器(MLP)与反向传播(BP)训练相结合的理念(该方法在当时计算力上还是有很多挑战,基本上都是和链式求导的梯度算法相关的),这也解决了单层感知器不能做非线性分类的问题,开启了神经网络新一轮的高潮。
1989年,LeCun (CNN之父) 结合反向传播算法与权值共享的卷积神经层发明了卷积神经网络(Convolutional Neural Network,CNN),并首次将卷积神经网络成功应用到美国邮局的手写字符识别系统中。
卷积神经网络通常由输入层、卷积层、池化(Pooling)层和全连接层组成。卷积层负责提取图像中的局部特征,池化层用来大幅降低参数量级(降维),全连接层类似传统神经网络的部分,用来输出想要的结果。
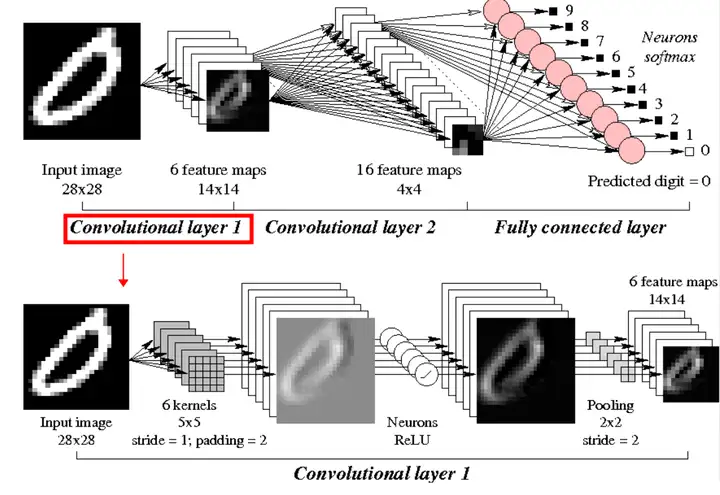
平稳发展期:20世纪90年代—2010年
由于互联网技术的迅速发展,加速了人工智能的创新研究,促使人工智能技术进一步走向实用化,人工智能相关的各个领域都取得长足进步。
在2000年代初,由于专家系统的项目都需要编码太多的显式规则,这降低了效率并增加了成本,人工智能研究的重心从基于知识系统转向了机器学习方向。
1997年国际商业机器公司(简称IBM)深蓝超级计算机战胜了国际象棋世界冠军卡斯帕罗夫。深蓝是基于暴力穷举实现国际象棋领域的智能,通过生成所有可能的走法,然后执行尽可能深的搜索,并不断对局面进行评估,尝试找出最佳走法。
1997年,Sepp Hochreiter 和 Jürgen Schmidhuber提出了长短期记忆神经网络(LSTM)。
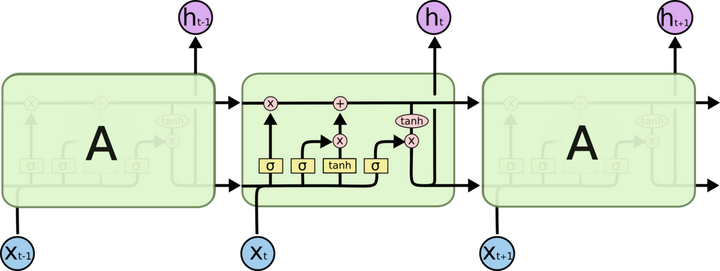
LSTM是一种复杂结构的循环神经网络(RNN),结构上引入了遗忘门、输入门及输出门:输入门决定当前时刻网络的输入数据有多少需要保存到单元状态,遗忘门决定上一时刻的单元状态有多少需要保留到当前时刻,输出门控制当前单元状态有多少需要输出到当前的输出值。这样的结构设计可以解决长序列训练过程中的梯度消失问题。
2003年,Google公布了3篇大数据奠基性论文,为大数据存储及分布式处理的核心问题提供了思路:非结构化文件分布式存储(GFS)、分布式计算(MapReduce)及结构化数据存储(BigTable),并奠定了现代大数据技术的理论基础。
2006年,杰弗里·辛顿以及他的学生鲁斯兰·萨拉赫丁诺夫正式提出了深度学习的概念(Deeping Learning),开启了深度学习在学术界和工业界的浪潮。2006年也被称为深度学习元年,杰弗里·辛顿也因此被称为深度学习之父。
深度学习的概念源于人工神经网络的研究,它的本质是使用多个隐藏层网络结构,通过大量的向量计算,学习数据内在信息的高阶表示。
- 隐藏层(Hidden Layer)是人工神经网络中的中间层,位于输入层和输出层之间。它的作用是对输入数据进行特征提取和变换,为最终的输出层提供高层次特征。隐藏层这个术语之所以称为“隐藏”,是因为其输出对外界不可见,只在网络内部流通。
- 隐藏层的主要任务是通过线性变换和激活函数来捕捉数据中的复杂模式和特征。
- 多层隐藏层:通过多层隐藏层的堆叠,网络可以逐渐提取出数据中越来越抽象的特征,这也是深度学习的核心思想。
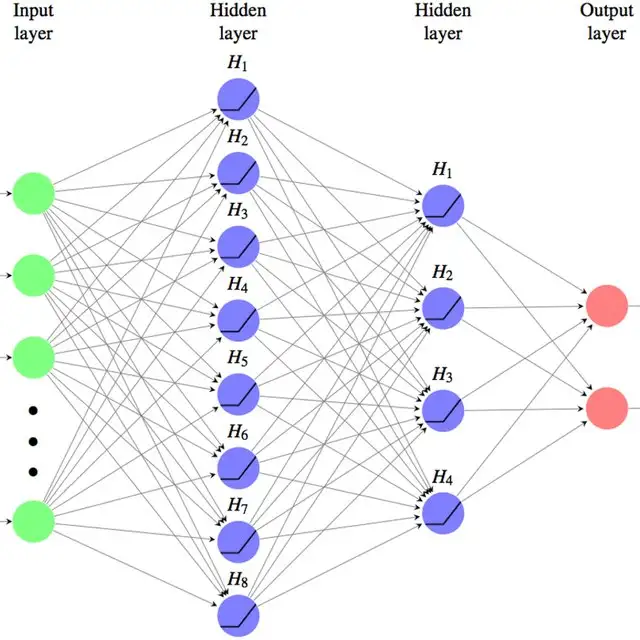
深度学习算法简述
深度神经网络的开发与工作模式抽象为以下几个步骤:
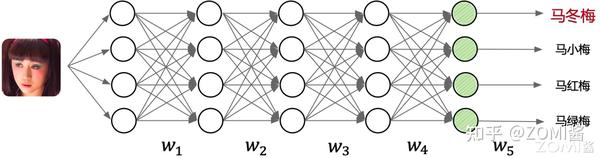
1.确定模型输入输出
首先需要确认神经网络模型的输入样本学习数据(Sample)、输出标签(Label)。如图中所示,给 AI 模型输入图片,输出是图片所对应的类别(马冬梅、马小梅等)。用户需要提前准备好模型的输入输出数据,进而展开后续的模型训练【21】。
一般来说,输入和输出的数据将分为80%的模型训练数据- training data,20%的模型用来测试模型-test data,来计算loss function。
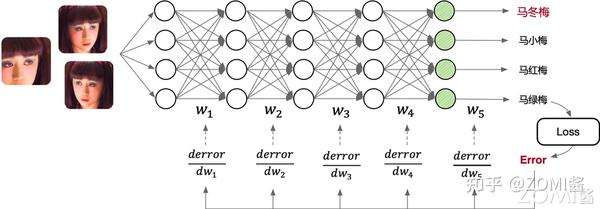
2.设计与开发模型
开发者通过 AI 开发框架提供的 API 开发了图中的模型结构,线段代表权重,圆圈代表输入数据发生计算操作。其中 wn 代表权重,也就是可以被学习和不断更新的数值。权重w和偏置b就被称为神经网络的参数,其约等于连接的个数-就是图像里的线条个数。
3.训练(Training)过程
训练的本质上是通过网络中的连接逐层向后传播总误差,计算每个层中每个权重和偏差对总误差的贡献(梯度 δw),然后使用求解梯度的优化算法(如梯度下降算法)进行优化权重和偏差,并最终最小化神经网络的总误差。如图中上半部分所示,训练过程就是根据用户给定的带有标签(如图中的马冬梅、马小梅等输出标签)的数据集,不断通过优化算法进行学,通过下面步骤学习出给定数据集下最优的模型权重 wn 的取值。
3.1 前向传播(Forward Propagation):由输入到输出完成 AI 模型中各层矩阵计算(例如卷积层,池化层等),每一层都在提取更高维度的目标特征(点-线-面),产生输出并完成损失函数 LOSS 计算。
- 损失函数就是模型的预测值和实际值的总差
- 深度学习神经网络计算80%都是简单的加减乘除四则运算,20%才是复杂的微积分运算-梯度更新等
3.2 反向传播(Back Propagation):由输出到输入反向完成 AI 模型中各层的权重和输出对损失函数的梯度求解。
x 轴和 y 轴分别代表两个权值,z 轴代表在给定两个特定权值的情况下损失函数的值。我们的目标就是找到损失最小的特定权值,这个点被称作损失函数的最小值点。
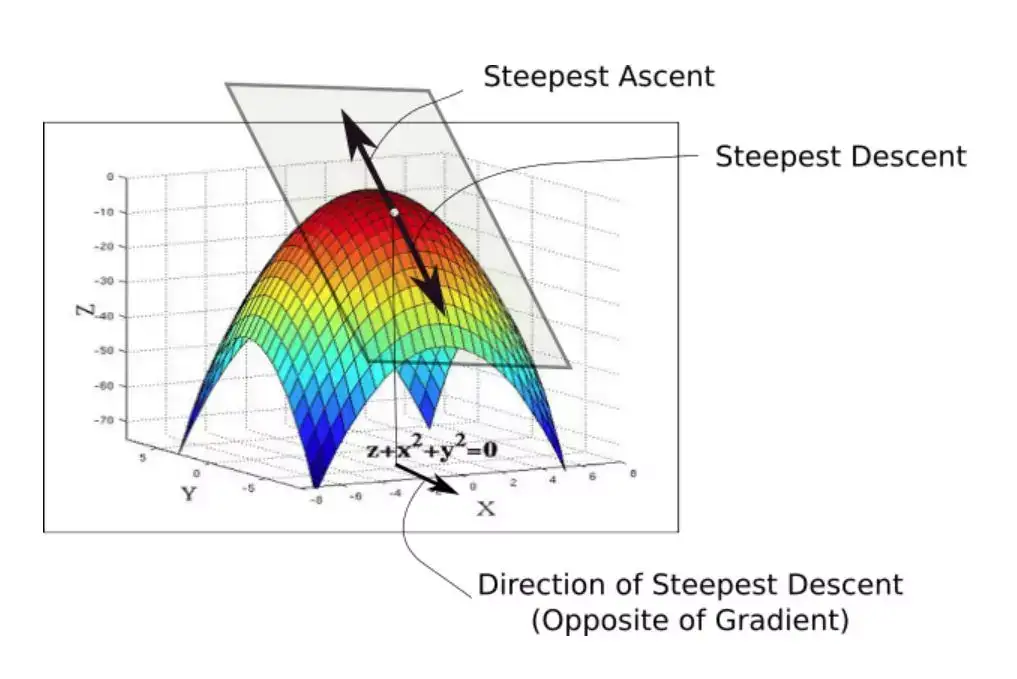
图:初始的损失函数
3.3 梯度更新(Weight Update):对模型权重通过梯度下降法完成模型权重针对梯度和指定学习率更新。
- 初始化权值的时候,我们处于损失函数图形中的最高点。首先要做的就是查看 x-y 平面中所有可能的方向,看看哪个方向是损失函数的值下降最陡峭的方向。这个就是我们必须移动的方向,它恰恰与梯度的方向相反。梯度是高维导数的另一种说法,它给出了最陡峭的上升方向【22】。
- 在曲面的任何一点,我们都能够定义一个与其相切的平面。在更高维度,我们总能够定义一个超平面,但在这里我们还是坚持使用 3 维空间。然后,在这个平面上有无限个方向。其中,准确来说只有一个使函数上升最快的方向,这个方向由梯度给出,与之相反的方向就是下降最快的方向。这就是算法名称的来源,我们沿着梯度的方向进行下降,所以就叫做梯度下降。
- 现在,既然已经有了前进方向,我们必须决定需要采取步子的大小,而控制下降步幅大小的参数即学习率。为了保证降到最小值,我们必须谨慎地选择学习率。
- 如果移动得太快,我们可能越过最小值,沿着「山谷」的山脊蹦蹦跳跳,永远都不可能到达最小值。如果移动太慢,训练可能花费太长的时间,根本就不可行,此外太慢的学习率也容易让算法陷入极小值。
- 一旦有了梯度和学习率,我们就开始行动,然后在最终到达的任何位置重新计算梯度,然后重复这个过程。
- 梯度的方向告诉我们哪个方向上升的最快,它的幅值则表示最陡峭的上升/下降有多陡。所以,在最小值的地方,曲面轮廓几乎是平坦的,我们期望得到几乎为零的梯度。事实上,最小值点的梯度就是 0。
- 在实践中,我们可能永远无法精确地达到最小值,但是我们能够在最小值附近的平坦区域震荡。当我们在这个区域震荡时,损失值几乎是我们能够达到的最小值,并且不会有很大的变化,因为我们是在真实的最小值附近跳动。通常,当损失值在预定的数字内没有提升的时候我们会停止迭代,例如 10 次或者 20 次迭代。当这种情况发生时,我们就说训练已经收敛了,或者说收敛已经实现了。
- 调整学习率是算法工程师的重要工作之一,也称之为调参工程。
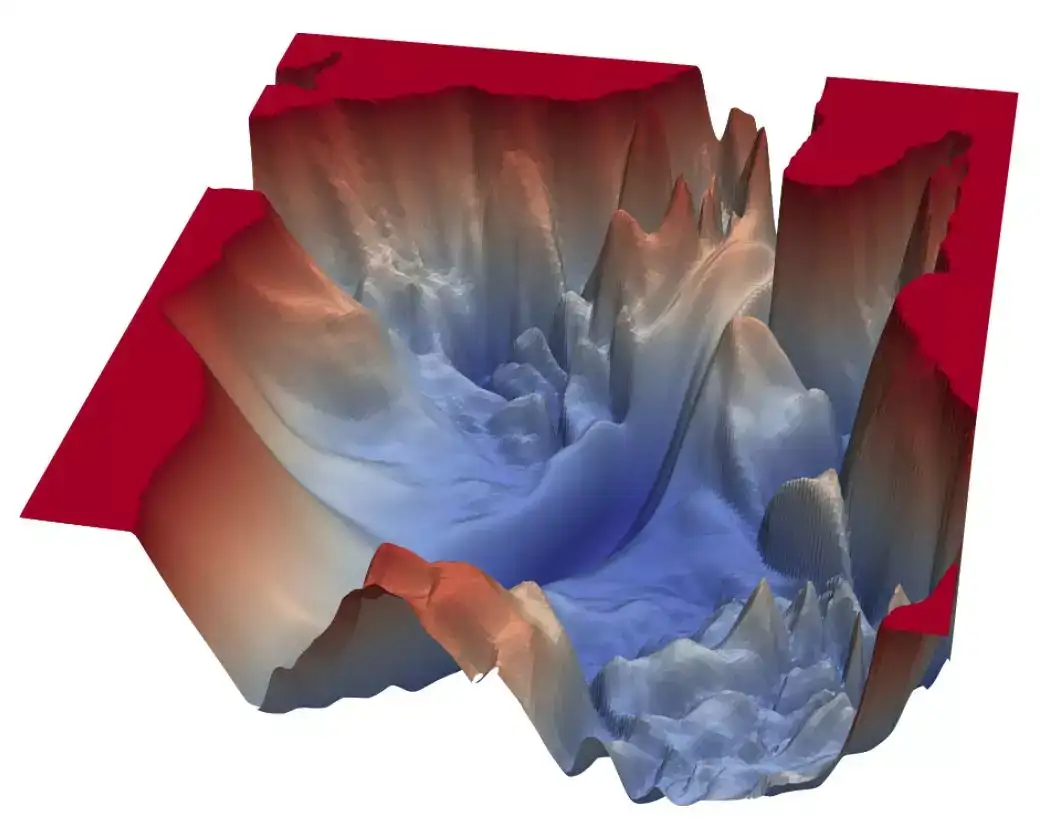
图:实际的梯度更新后的损失函数
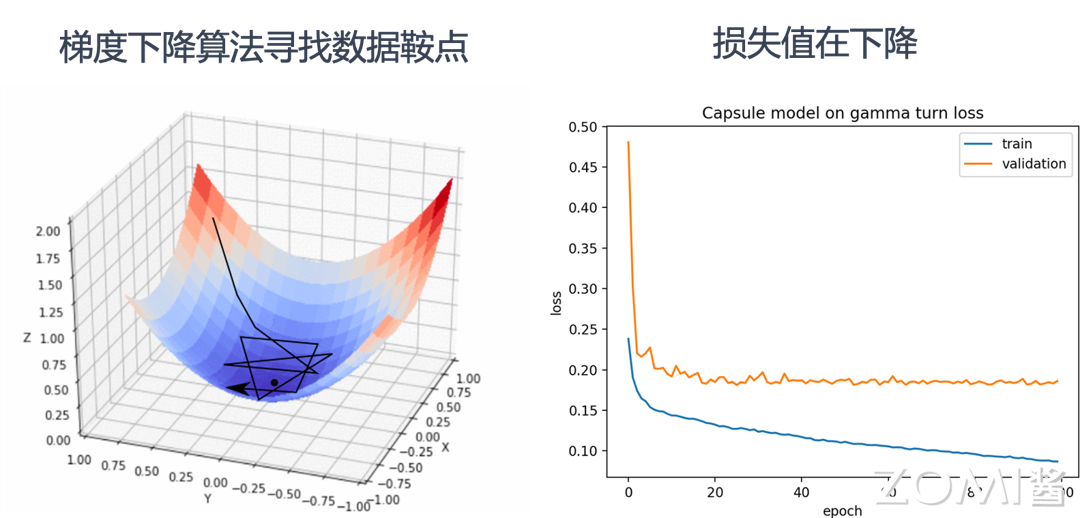
- 不断重复以上步骤 3.1 ~ 3.2,直到达到 AI 模型收敛或达到终止条件(例如指定达到一定迭代(Step)次数然后停止执行)。
- 如图所示,当完成了模型训练,意味着在给定的数据集上,模型已经达到最佳或者满足需求的预测效果。在如果开发者对模型预测效果满意,就可以进入模型部署进行推理和使用模型。一句话而言,我们训练 AI 模型的过程,就是通过不断的迭代计算,使用梯度下降的优化算法,使得损失函数越来越小。损失函数越小就表示算法达到数学意义上的最优。
4.推理(Inference)过程
推理只需要执行训练过程中的前向传播过程即可,推理的原理是基于训练好的 AI 模型,通过输入待预测的数据,经过前向传播过程,即通过 AI 模型定义的激活函数和非线性函数处理数据,得到最终的预测结果。
如图中下半部分所示,由输入到输出完成 AI 模型中各层的矩阵计算(例如卷积层,池化层等),产生输出。本例中输入是“马冬梅”的图片,输出的结果为向量,向量中的各个维度编码了图像的类别可能性,其中“马冬梅”的类别概率最大,判定为“马冬梅”,后续应用可以根据输出类别信息,通过程序转换为人可读的信息。
蓬勃发展期:2011年至今
随着大数据、云计算、互联网、物联网等信息技术的发展,泛在感知数据和图形处理器等计算平台推动以深度神经网络为代表的人工智能技术飞速发展,大幅跨越了科学与应用之间的技术鸿沟,诸如图像分类、语音识别、知识问答、人机对弈、无人驾驶等人工智能技术实现了重大的技术突破,迎来爆发式增长的新高潮。
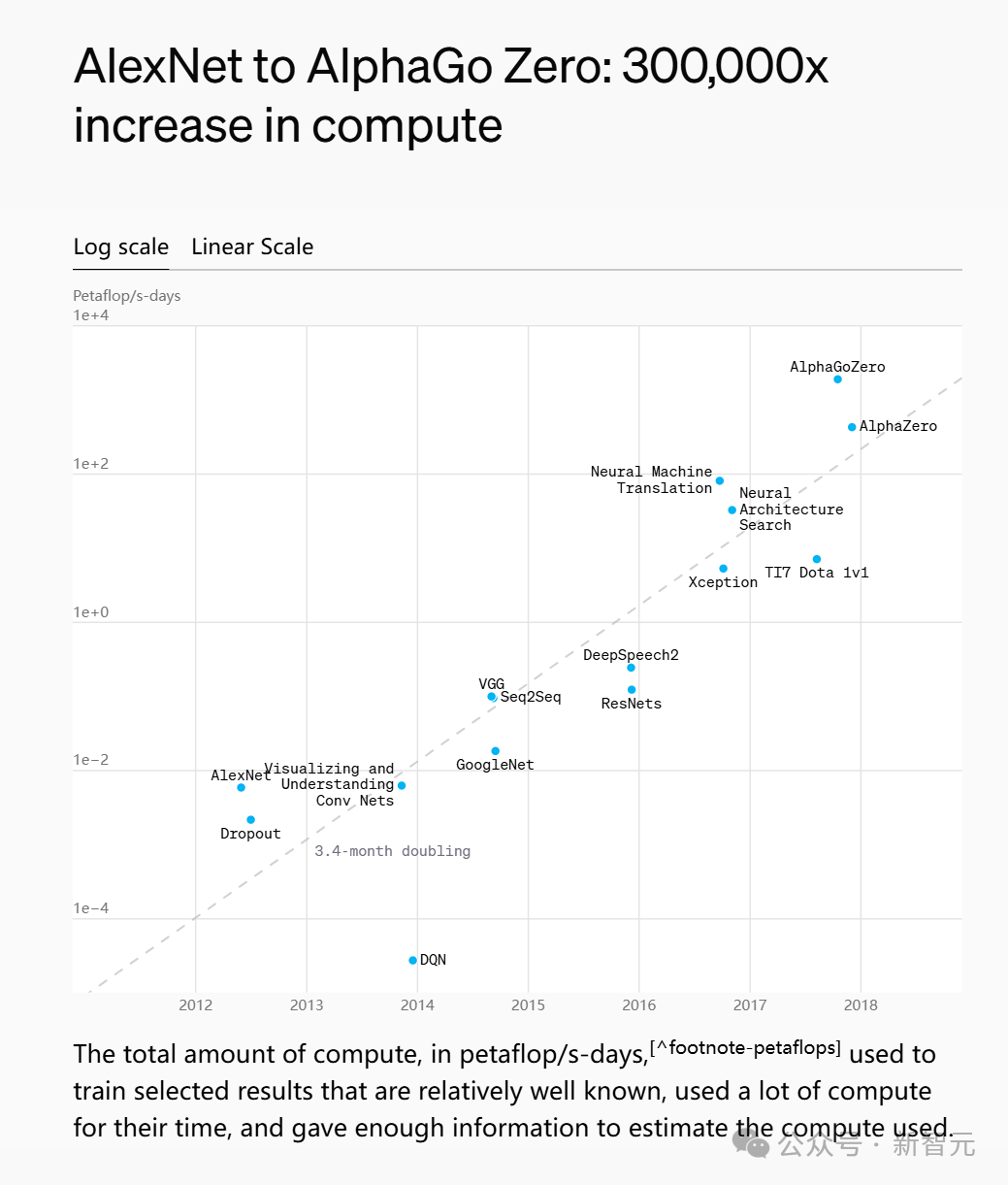
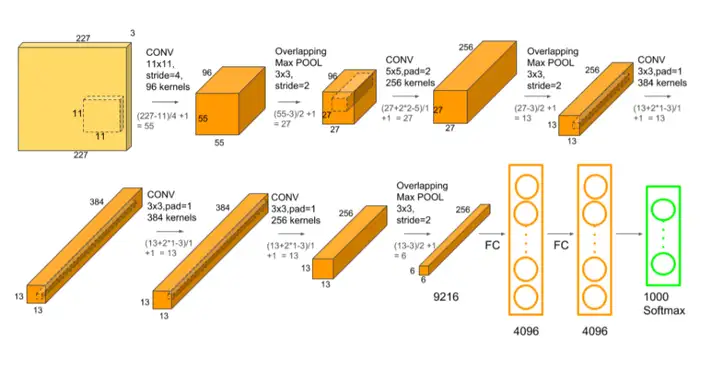
2012年,Hinton和他的学生Alex Krizhevsky设计的AlexNet神经网络模型在ImageNet竞赛大获全胜,这是史上第一次有模型在 ImageNet 数据集表现如此出色,并引爆了神经网络的研究热情。
AlexNet是一个经典的CNN模型,在数据、算法及算力层面均有较大改进,创新地应用了Data Augmentation、ReLU、Dropout和LRN等方法,并使用GPU加速网络训练。GPU在深度学习网络的作用开始远远大于CPU。
2012年,谷歌正式发布谷歌知识图谱Google Knowledge Graph),它是Google的一个从多种信息来源汇集的知识库,通过Knowledge Graph来在普通的字串搜索上叠一层相互之间的关系,协助使用者更快找到所需的资料的同时,也可以知识为基础的搜索更近一步,以提高Google搜索的质量。
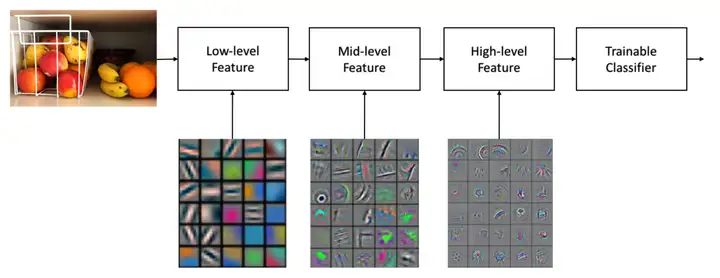
2015年,为纪念人工智能概念提出60周年,深度学习三巨头LeCun、Bengio和Hinton(他们于2018年共同获得了图灵奖)推出了深度学习的联合综述《Deep learning》。
《Deep learning》文中指出深度学习就是一种特征学习方法,把原始数据通过一些简单的但是非线性的模型转变成为更高层次及抽象的表达,能够强化输入数据的区分能力。通过足够多的转换的组合,非常复杂的函数也可以被学习。
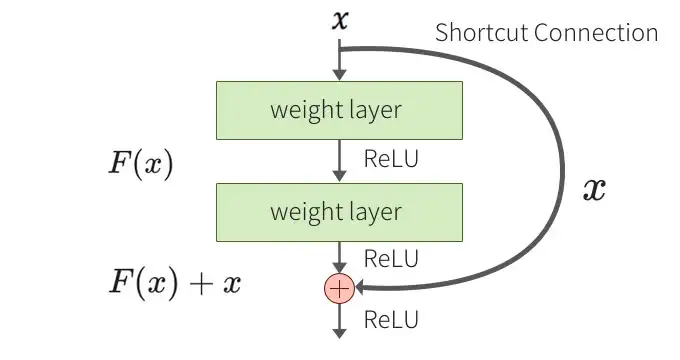
2015年,Microsoft Research的Kaiming He等人提出的残差网络(ResNet)在ImageNet大规模视觉识别竞赛中获得了图像分类和物体识别的优胜。
残差网络的主要贡献是发现了网络不恒等变换导致的“退化现象(Degradation)”,并针对退化现象引入了 “快捷连接(Shortcut connection)”,缓解了在深度神经网络中增加深度带来的梯度消失问题。
2015年,谷歌开源TensorFlow框架。它是一个基于数据流编程(dataflow programming)的符号数学系统,被广泛应用于各类机器学习(machine learning)算法的编程实现,其前身是谷歌的神经网络算法库DistBelief。
2015年,马斯克等人共同创建OpenAI。它是一个非营利的研究组织,使命是确保通用人工智能 (即一种高度自主且在大多数具有经济价值的工作上超越人类的系统)将为全人类带来福祉。其发布热门产品的如:OpenAI Gym,GPT等。
2016年,AlphaGo与围棋世界冠军、职业九段棋手李世石进行围棋人机大战,以4比1的总比分获胜。
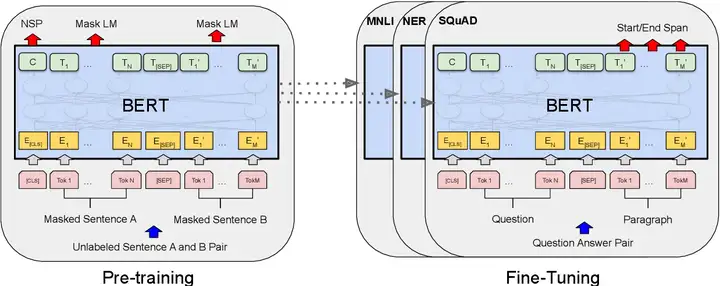
2018年,Google提出论文《Pre-training of Deep Bidirectional Transformers for Language Understanding》并发布Bert(Bidirectional Encoder Representation from Transformers)模型,成功在 11 项 NLP 任务中取得 state of the art 的结果。
BERT是一个预训练的语言表征模型,可在海量的语料上用无监督学习方法学习单词的动态特征表示。它基于Transformer注意力机制的模型,对比RNN可以更加高效、能捕捉更长距离的依赖信息,且不再像以往一样采用传统的单向语言模型或者把两个单向语言模型进行浅层拼接的方法进行预训练,而是采用新的masked language model(MLM),以致能生成深度的双向语言表征。
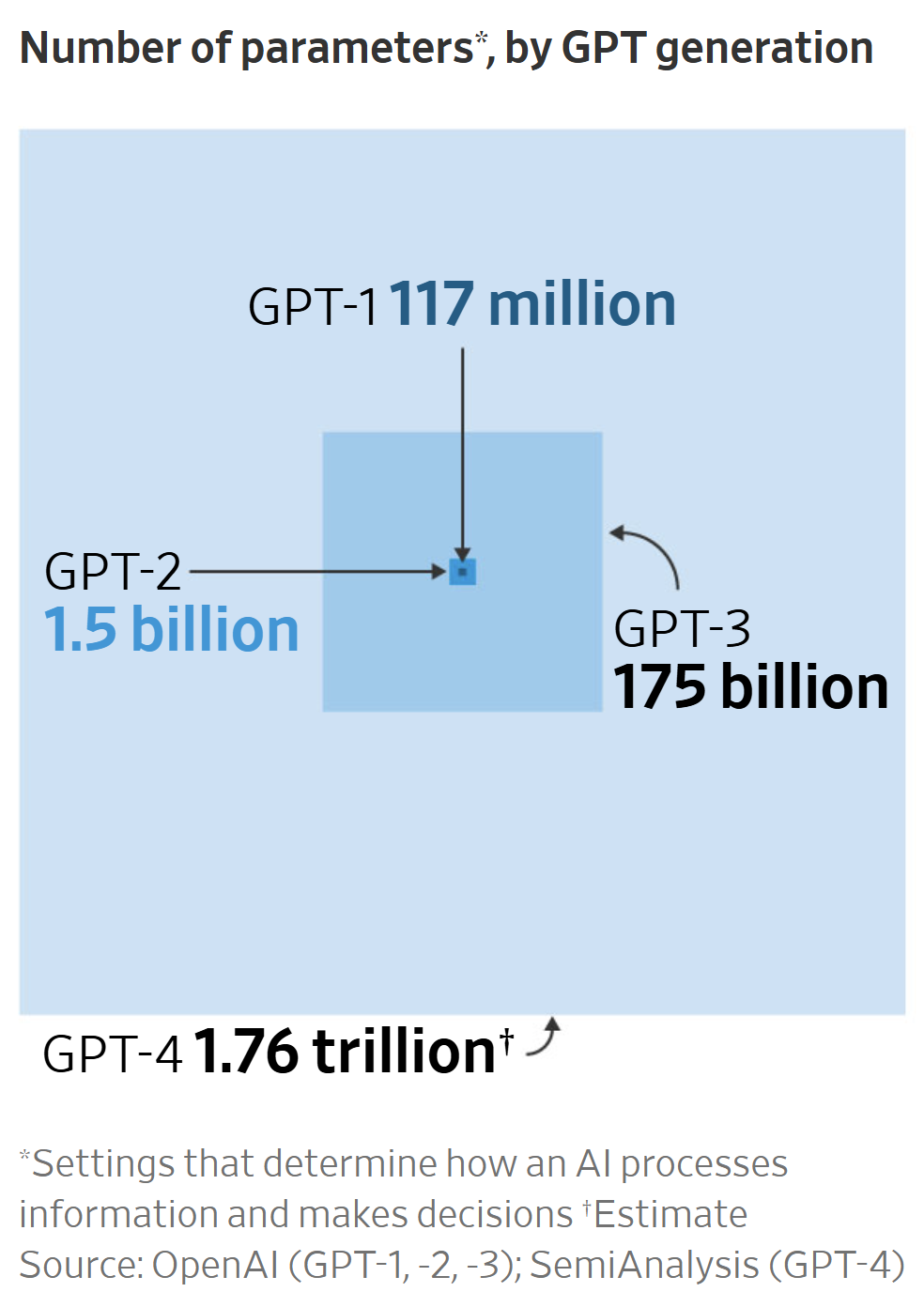
2020年,OpenAI开发的文字生成 (text generation) 人工智能GPT-3,它具有1,750亿个参数的自然语言深度学习模型,比以前的版本GPT-2高100倍,该模型经过了将近0.5万亿个单词的预训练,可以在多个NLP任务(答题、翻译、写文章)基准上达到最先进的性能。
2020年,谷歌旗下DeepMind的AlphaFold2人工智能系统有力地解决了蛋白质结构预测的里程碑式问题。它在国际蛋白质结构预测竞赛(CASP)上击败了其余的参会选手,精确预测了蛋白质的三维结构,准确性可与冷冻电子显微镜(cryo-EM)、核磁共振或 X 射线晶体学等实验技术相媲美。
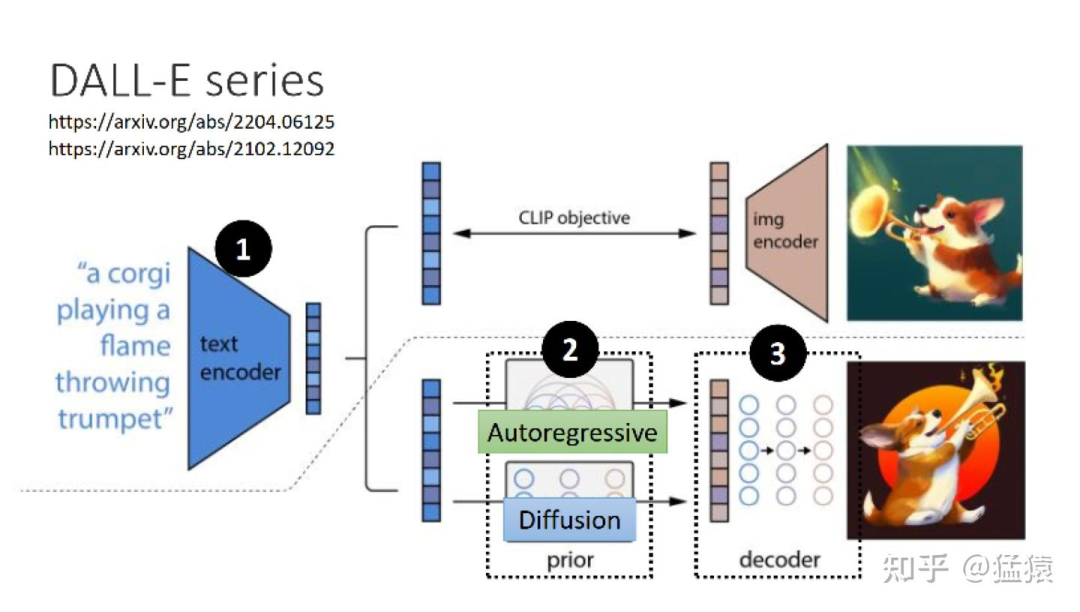
2021年,OpenAI提出两个连接文本与图像的神经网络:DALL·E 和 CLIP。DALL·E 可以基于文本直接生成图像,CLIP 则能够完成图像与文本类别的匹配。
2021年,AlphaFold 2 能很好地预判蛋白质与分子结合的概率,为我们展示了人工智能驱动自然学科研究的无限潜力;

2022年,ChatGPT推出,AI爆炸进行时!

总结来说,AI技术学派的发展,随着人类对自己的智慧的研究深入-当然也有客观物理条件的满足(算力和数据),从意识层面(现成的知识复制)到物质层面(神经网络的机制),所产生的智能从机械重复性工作到创意生成实现了跨越,符号主义范式向联结主义范式迁移,少层次神经网络到多层次深度学习的神经网络。
(2)AI理论
在实践中,我们根据任务,优先确认学习范式和算法,搭建ai模型,在小规模应用中收敛学习范式和ai模型至可以被大规模训练的最佳状态–loss fuction表现优异。
学习范式
机器学习的范式包含三种主流范式:
监督学习(Supervised Learning)
监督学习模型主要是根据人类已标注数据对模型的输入和输出学习到一种映射关系,以此对测试数据集中的样本进行预测。包含两类任务:分类和回归。许多数据标注公司业务依赖于此学习范式的模型公司。
模仿学习(Imitation Learning)
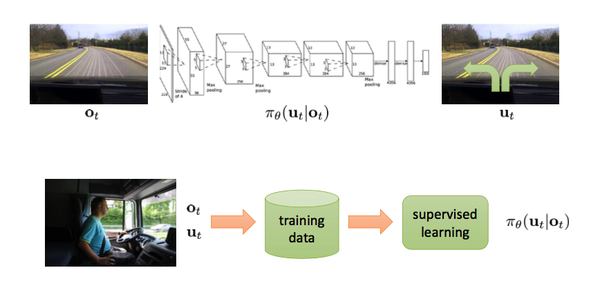
模仿学习是指从示教者提供的范例中学习,把状态作为特征(feature)【23】,动作作为标记(label)进行分类(对于离散动作)或回归(对于连续动作)的学习从而得到最优策略模型。模型的训练目标是使模型生成的状态-动作轨迹分布和输入的轨迹分布相匹配。本质上是一种对齐手段,不是真正的理解世界。
在简单自动驾驶任务中(如下图),状态就是指汽车摄像头所观测到的画面,动作即转向角度。根据人类提供的状态动作对来习得驾驶策略。这个任务也叫做行为克隆(Behavior Cloning),即作为监督学习的模仿学习。
缺点:由于没有自我探索能力,性能不可能超过人类遥控机器人所能达到的性能。而很多任务实际上是通过遥控/示教难以实现的,比如人形机器人的奔跑跳跃等动态平衡问题,以及与动态物体的交互。
无监督学习(Unsupervised Learning)
相比于监督学习,无监督学习仅依赖于无标签的数据训练模型来学习数据表征。自监督学习是无监督学习的一种。
自监督学习(Self-Supervised Learning)
自监督学习主要是利用「辅助任务(pretext)–自动标注、自动训练「从大规模的无监督数据中挖掘」自身的监督信息」来提高学习表征的质量,通过这种构造监督信息对网络进行训练,从而可以学习到对下游任务具有价值的表征。
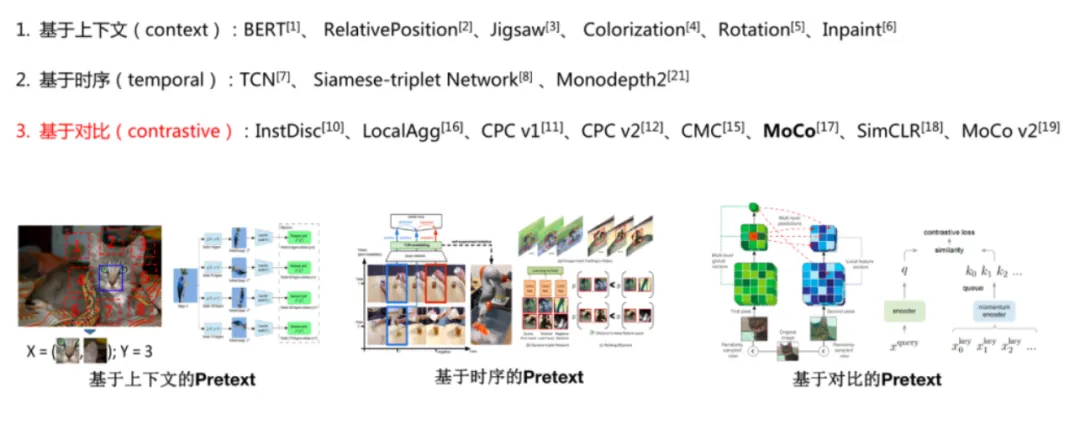
最常见的通过随机删去训练集句子中的单词来构造辅助任务训练集和标签,来训练网络预测被删去的单词,以提升模型对于语序特征的提取能力(BERT)。

强化学习(Reinforcement Learning)
基于环境的反馈而行动,通过不断与环境的交互、试错,最终完成特定目的或者使得整体行动收益最大化。强化学习不需要训练数据的label,但是它需要每一步行动环说给的反馈,是奖励还是惩别!反馈可以量化,基于反馈不断调整训练对象的行为【24】。
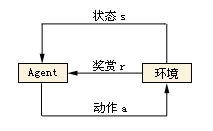
强化学习是智能体(Agent)以“试错”的方式进行学习,通过与环境进行交互获得的奖赏指导行为,目标是使智能体获得最大的奖赏。
强化学习主要是指导训练对象每一步如何决策,采用什么样的行动可以完成特定的目的或者使收益最大化。
比如AlphaGo下围棋,AlphaGo就是强化学习的训练对象,AlphaGo走的每一步不存在对错之分,但是存在“好坏”之分。当前这个棋面下,下的“好”,这是一步好棋。下的“坏”,这是一步臭棋。强化学习的训练基础在于AlphaGo的每一步行动环境都能给予明确的反馈,是“好”是“坏”?“好”“坏”具体是多少,可以量化。强化学习在AlphaGo这个场景中最终训练目的就是让棋子占领棋面上更多的区域,赢得最后的胜利。
EE(Explore & Exploit)探索和利用的权衡 trade-off
但实际我们在进行强化学习训练过程中,会遇到一个“EE”问题。这里的Double E不是“Electronic Engineering”,而是“Explore & Exploit”,“探索&利用”。
所以在强化学习训练的时候,一开始会让Agent更偏向于探索Explore,并不是哪一个Action带来的Value最大就执行该Action,选择Action时具有一定的随机性,目的是为了覆盖更多的Action,尝试每一种可能性。等训练很多轮以后各种State下的各种Action基本尝试完以后,我们这时候会大幅降低探索的比例,尽量让Agent更偏向于利用Exploit,哪一个Action返回的Value最大,就选择哪一个Action。
Explore&Exploit是一个在机器学习领域经常遇到的问题,并不仅仅只是强化学习中会遇到,在推荐系统中也会遇到,比如用户对某个商品 or 内容感兴趣,系统是否应该一直为用户推送,是不是也要适当搭配随机一些其他商品 or 内容。
该学习范式容易陷入局部最优:部分场景中Agent采取的行动可能是当前局部最优,而不是全局最优。网上经常有人截图爆出打游戏碰到了王者荣耀AI,明明此时推塔或者推水晶是最合理的行为,但是AI却去打小兵,因为AI采取的是一个局部最优的行为。再合理的Reward函数设置都可能陷入局部最优中。
能力成长滞后:比如没有遇到的问题–长尾问题,长时间重复学习后,才能学会,没有Zero-Shot的能力。
AI模型算法
下面对典型的基本 AI 模型结构进行类型归纳【25】:
卷积神经网络(Convolutional Neural Network,CNN)
以卷积层(Convolution Layer)为主,池化层(Pooling Layer),全连接层(Fully Connected Layer)等算子(Operator)的组合形成的 AI 网络模型,并在计算机视觉领域取得明显效果和广泛应用的模型结构。
循环神经网络(Recurrent Neural Network,RNN)
以循环神经网络、长短时记忆(LSTM)等基本单元组合形成的适合时序数据预测(例如,自然语言处理、语音识别、监控时序数据等)的模型结构。
图神经网络(Graph Neural Network,GNN)
使用神经网络来学习图结构数据,提取和发掘图结构数据中的特征和模式,满足聚类、分类、预测、分割、生成等图学习任务需求的算法总称。目的是为了尽可能多的提取 “图” 中潜在的表征信息。
生成对抗网络(Generative Adversarial Network,GAN)
该架构训练两个神经网络相互竞争,从而从给定的训练数据集生成更真实的新数据。例如,可以从现有图像数据库生成新图像,也可以从歌曲数据库生成原创音乐。GAN 之所以被称为对抗网络,是因为该架构训练两个不同的网络并使其相互对抗。
扩散概率模型(Diffusion Probabilistic Models)
扩散概率模型是一类潜变量模型,是用变分估计训练的马尔可夫链。目标是通过对数据点在潜空间中的扩散方式进行建模,来学习数据集的潜结构。如计算机视觉中,意味着通过学习逆扩散过程训练神经网络,使其能对叠加了高斯噪声的图像进行去噪。
混合结构网络(Model Ensemble)
组合卷积神经网络和循环神经网络,进而解决如光学字符识别(OCR)等复杂应用场景的预测任务。
基础模型的典型算子已经被 AI 开发框架和底层 AI 硬件做了较多优化,但是 AI 模型已经不单纯只在算子层面产生变化,其从网络结构,搜索空间等方向演化出如下的新的趋势:
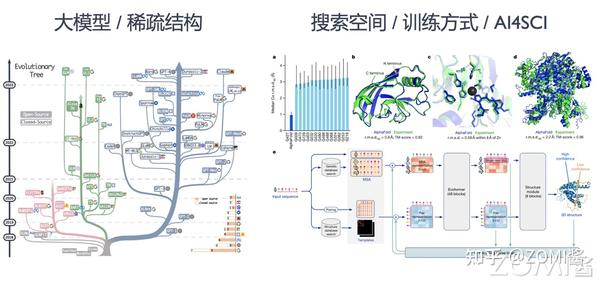
更大的模型:以 Transformer 为基本结构的代表性预训练神经语言模型(Neural Language Model),例如,BERT、GPT-3、LLAMA 等,在自然语言处理和计算机视觉等场景应用越来越广泛。其不断增加的层数和参数量,该模型对底层系统内存管理,分布式训练和硬件设计提出了很大的挑战。
更灵活的结构:图神经网络模型、深度搜索树网模型等算法不断抽象多样且灵活的数据结构(例如图 Graph,树 Tree 等),应对更为复杂的建模需求。进而衍生了新的算子(例如图卷积等)与计算框架(例如图神经网络框架等)。
更稀疏的模型结构:以多专家模型(Mixture of Experts,MoE)和 Pathways 模型结构为代表的模型融合结构,让运行时的 AI 系统执行模型更加动态(Dynamic)和稀疏(Sparse),提升模型的训练效率减少训练代价,支持更多的任务。给系统设计静态分析带来了不小的挑战,同时驱动运用即时编译(Just In Time Compiling)和运行时(Runtime)更加高效的调度与优化。
更大规模的搜索空间:用户定义更大规模的超参数与模型结构搜索空间,通过超参数搜索优化(HPO)与神经网络结构搜索(NAS)自动化找到最优的模型结构。自动化机器学习(AutoML)为代表的训练方式,衍生出多作业执行与多作业(Multi-Jobs)编排优化的系统需求。
更多样的训练方式:扩散模型(Diffusion Model)和深度强化学习(Deep Reinforcement Learning)为代表的算法有比传统训练方式更为复杂的过程。其衍生出训练,推理,数据处理混合部署与协同优化的系统需求。
当然还有软硬结合的算法:具身智能算法和自动驾驶算法。
接下来,笔者会重点阐述以trasfomer架构为主的算法演变及原理。
Transfomer模型算法
深度学习算法都是:通过学习输入的概率分布,形成神经网络潜空间的知识库-包罗万象的概率分布,然后引导输出的概率分布与现实的需求对齐。
一句话:通过概率分布找到事物的各种关系
RNN的梯度消失和爆炸
深度学习RNN模型在自然语言领域的大规模探索和商业化后,人们逐渐发现其致命弱点,导致其学习能力受限–梯度爆炸和消失问题。
比较简单的深层网络如下【26】:
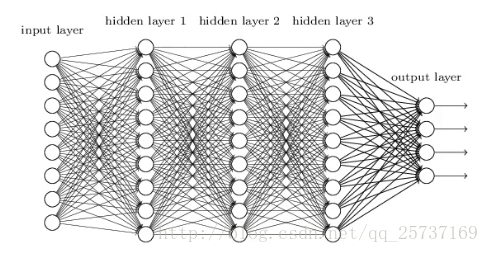
图中是一个四层的全连接网络,假设每一层网络激活后的输出为
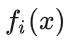
其中i为第i层, x代表第i层的输入,也就是第i−1层的输出,f是激活函数,那么,得出
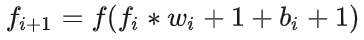
简单记为
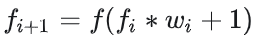
BP算法基于梯度下降策略,以目标的负梯度方向对参数进行调整,参数的更新为
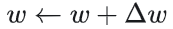
给定学习率α,得出
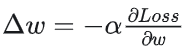
如果要更新第二隐藏层的权值信息,根据链式求导法则,更新梯度信息:
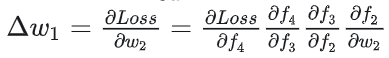
很容易看出来
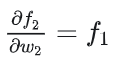
所以说, 就是对激活函数进行求导,如果此部分大于1,那么层数增多的时候,最终的求出的梯度更新将以指数形式增加,即发生梯度爆炸,如果此部分小于1,那么随着层数增多,求出的梯度更新信息将会以指数形式衰减,即发生了梯度消失。
总而言之,随着层数增多,链式求导的微积分算法导致的梯度更新求解失控。
如果说从数学上看不够直观的话,下面几个图可以很直观的说明深层网络的梯度问题。
注:下图中的隐层标号和第一张全连接图隐层标号刚好相反。
已经可以发现隐藏层2的权值更新速度要比隐藏层1更新的速度慢,第四隐藏层比第一隐藏层的更新速度慢了两个数量级。
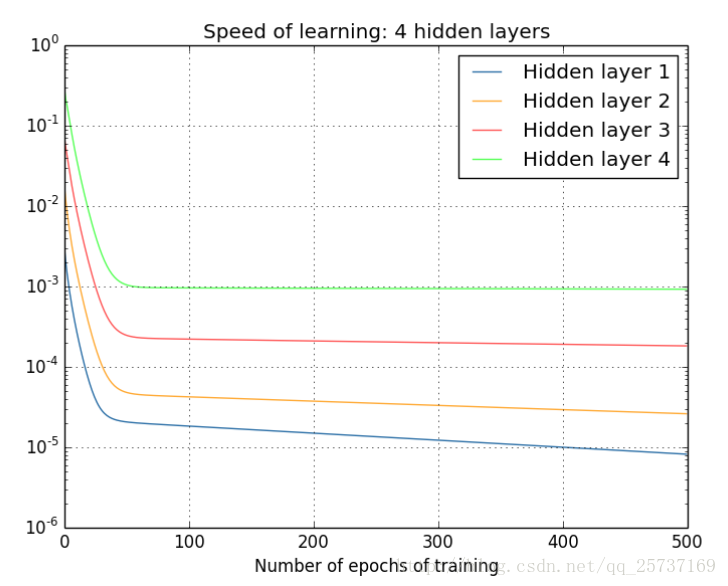
从深层网络角度来讲,不同的层学习的速度差异很大,表现为网络中靠近输出的层学习的情况很好,靠近输入的层学习的很慢,有时甚至训练了很久,前几层的权值和刚开始随机初始化的值差不多。
梯度消失、爆炸,导致了RNN的学习能力受限,从而无法解决长时依赖问题,当预测点与依赖的相关信息距离比较远的时候,就难以学到该相关信息。例如在句子”我是一名中国人,…(省略数十字),我会说中文”,如果我们要预测未尾的“中文”两个字,我们需要上文的“中国人”,或者“中国”。
其根本原因在于反向传播训练法则,本质在于方法问题,而且对于人来说,在大脑的思考机制里是没有反向传播的。
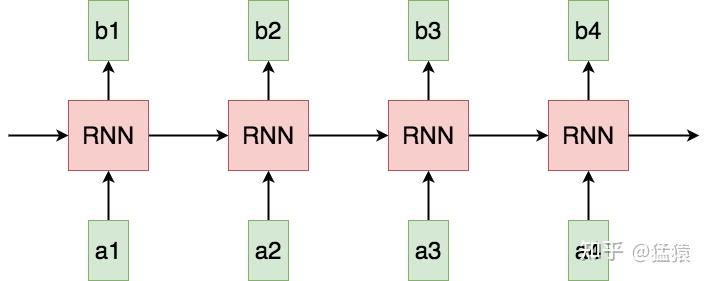
同时在RNN当中,tokens是一个一个被喂给模型的。比如在a3的位置,模型要等a1和a2的信息都处理完成后,才可以生成a3。无法并行计算导致只能接纳有限的上下文。
Transfomer
为了更好地捕捉长距离信息,研究者们想要寻找到一种更强的语言模型方法,由此提出了以 transformer结构为基础的预训练语言模型。
一切源于2017年谷歌Brain团队那篇鼎鼎大名的文章“Attention Is All You Need”(注意力就是你所需要的一切),就是这篇文章提出了Transformer网络结构。
首先,Transformer引入的自注意力机制能够有效捕捉序列信息中长距离依赖关系,相比于以往的RNNs,它在处理长序列时的表现更好。
而自注意力机制的另一个特点是允许模型并行计算,无需RNN一样t步骤的计算必须依赖t-1步骤的结果,因此Transformer结构让模型的计算效率更高,加速训练和推理速度。
Transformer最开始应用于NLP领域的机器翻译任务,但是它的通用性很好,除了NLP领域的其他任务,经过变体,还可以用于视觉领域,如ViT(Vision Transformer)。
我们把模型拆成了各个零件进行学习,最后把这些零件组装成一个标准的Transformer。
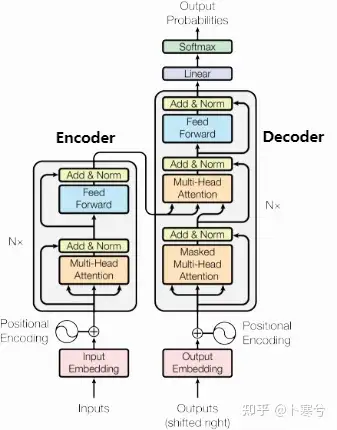
最初,Transformer 模型是为机器翻译而设计的。它是一个编码器-解码器结构,其中编码器将原始语言的句子作为输入并生成基于注意力的表征。而解码器关注编码信息并以自回归方式生成翻译的句子,就像 RNN 一样。
1 输入:Embedding(嵌入)– 降维至数字
“Embedding”直译是嵌入式、嵌入层。作用就是将文字降维至数字,让计算机可计算。
嵌入之前,我们首先tokenize是指将文本分割成称为“tokens”的有意义的片段的过程–可以理解为把句子里的主语、谓语等有意义的单词切割开,每个token单独输入给嵌入层。
简单来说,我们常见的地图就是对于现实地理的Embedding,现实的地理地形的信息其实远远超过三维,但是地图通过颜色和等高线等来最大化表现现实的地理信息。通过它,我们在现实世界里的文字、图片、语言、视频就能转化为计算机能识别、能使用的语言,且转化的过程中信息不丢失。
图:直观的几何表达压缩为:三维图像变压缩成3张二维的图像
假设,我们中文,一共只有10个字,那么我们用0-9就可以表示完【27】。比如,这十个字就是“小普喜欢星海湾的朋友”,其分别对应“0-9”,如下:

那么,其实我们只用一个列表就能表示所有的对话。例如:

但是中文单词有几十万的,都需要特殊编码,可以经过one-hot编码把上面变成,保持其唯一特殊性:

即:把每一个字都对应成一个十个(样本总数/字总数)元素的数组/列表,其中每一个字都用唯一对应的数组/列表对应,数组/列表的唯一性用1表示。
稀疏矩阵做矩阵计算的时候,只需要把1对应位置的数相乘求和就行。何况这个列表还是一行,如果是100行、1000行或1000列呢?所以,one-hot编码的优势就体现出来了,计算方便快捷、表达能力强。
然而,缺点也随着来了。比如:中文大大小小简体繁体常用不常用有十几万,然后一篇文章100W字,表示成100W X 10W的矩阵???这是它最明显的缺点:过于稀疏时,过度占用资源。比如:其实我们这篇文章,虽然100W字,但是其实我们整合起来,有99W字是重复的,只有1W字是完全不重复的。那我们用100W X 10W的岂不是白白浪费了99W X 10W的矩阵存储空间。那怎么办???这时,Embedding层就出现了!
假设:我们有一个2 x 6的矩阵,然后乘上一个6 x 3的矩阵后,变成了一个2 x 3的矩阵。
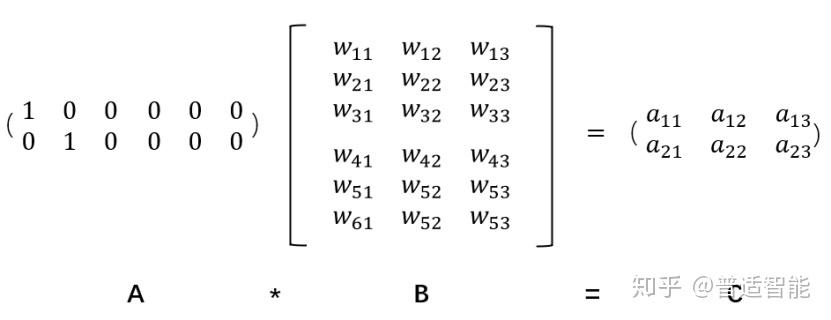
这个过程,我们把一个A中的12个元素的矩阵变成C中6个元素的矩阵,直观上,大小是不是缩小了一半,Embedding层,在某种程度上,就是用来降维的,降维的原理就是矩阵乘法。
假如我们有一个100W X10W的矩阵,用它乘上一个10W X 20的矩阵,我们可以把它降到100W X 20,瞬间量级降了10W/20=5000倍。
它就是作为这个桥梁的存在,让我们手头的东西可伸可缩,变成我们希望的样子。
2 输入:Positional Encoding (位置编码)
我们的输入除了嵌入层的降维数字信息外,还需要对每一个文字打上数字编码,知道每一个文字的上下文顺序【28】。
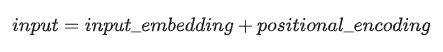
在self-attention模型中,输入是一整排的tokens,对于人来说,我们很容易知道tokens的位置信息,比如:
(1)绝对位置信息。a1是第一个token,a2是第二个token……
(2)相对位置信息。a2在a1的后面一位,a4在a2的后面两位……
(3)不同位置间的距离。a1和a3差两个位置,a1和a4差三个位置….
但是这些对于self-attention来说,是无法分辩的信息,因为self-attention的运算是无向的。因为,我们要想办法,把tokens的位置信息,喂给模型。
编码有三大要求:1 绝对位置信息有界限(否则距离大小无限)2 连续 3 不同位置的相对距离可以被转换计算
3 Self-attention(自注意力机制)– 注意力机制下的权重计算
假设以下句子是我们要翻译的输入句子:
“动物没有过马路,因为它太累了”【29】
这句话中的“它”指的是什么?它是指街道还是动物?这对人类来说是一个简单的问题,但对算法来说却不那么简单, 当模型处理单词“它”时,自注意力允许它将“它”与“动物”联系起来。
当模型处理每个单词(输入序列中的每个位置)时,自注意力允许它查看输入序列中的其他位置以寻找有助于更好地编码该单词的线索。
自注意力机制就是要通过权重矩阵来自发地找到词与词之间的关系
(1)计算框架
Self-Attention的意思是,我们给Attention的输入都来自同一个序列,其计算方式如下【30】:
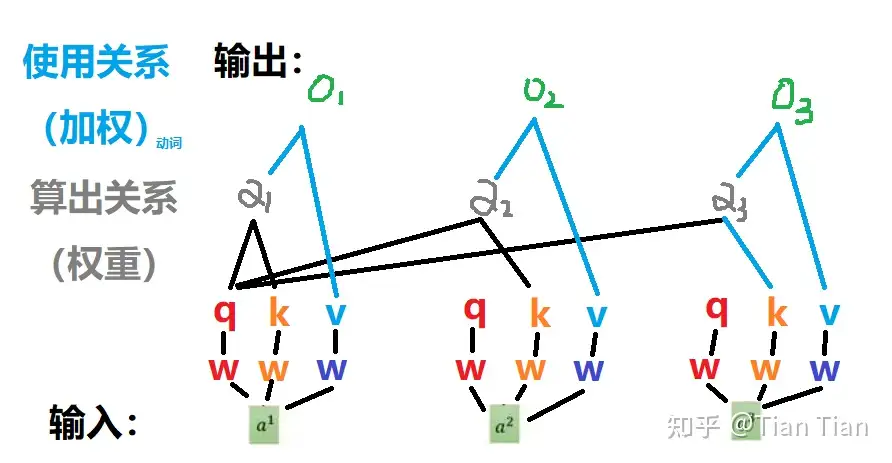
这张图所表示的大致运算过程是:对于每个token,先产生三个向量Query,Key,Value:
- Query向量类比于询问。某个token问:“其余的token都和我有多大程度的相关呀?”
- Key向量类比于索引。某个token说:“我把每个询问内容的回答都压缩了下装在我的key里” 。
- Value向量类比于回答。某个token说:“我把我自身涵盖的信息又抽取了一层装在我的value里” 。
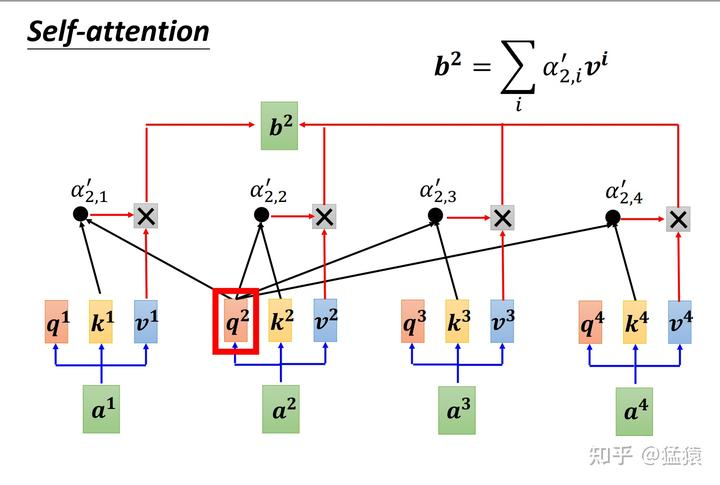
以图中的token a2为例:它产生一个Query,每个Query都去和别的token的Key做“某种方式”的计算,得到的结果我们称为attention score。则一共得到四个attention score。
将这四个score分别乘上每个token的Value,我们会得到四个抽取信息完毕的向量。将这四个向量相加,就是最终a2过attention模型后所产生的结果b2。
(2)Query,Key和Value 的计算方式 — 计算权重矩阵
下图描述了产生Query(Q),Key(K)和Value(V)的过程:
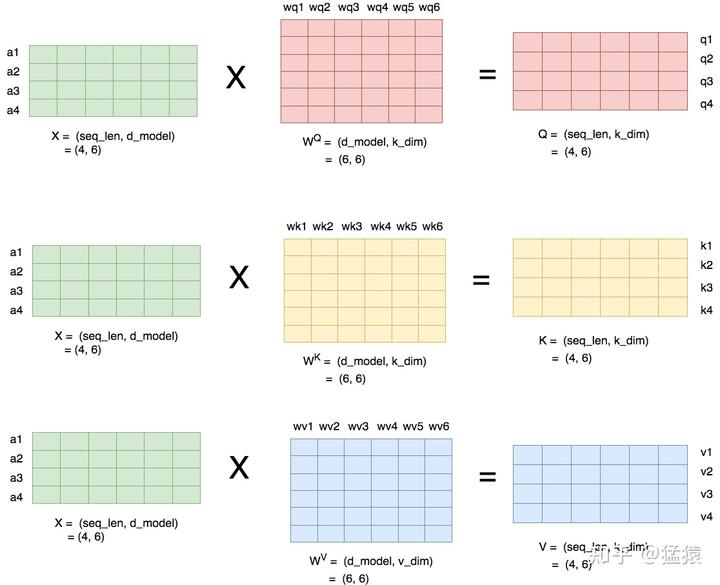
实际上,要理解QKV,重点是理解 Wq、Wk、Wv这三个矩阵。为什么会有这三个矩阵?前面文章中,只说明了Q、K、V,而省略了Wq、Wk、Wv。但是,要理解 attention 中的QKV,首先要理解这三个矩阵。
简单来说,这是三个权重矩阵。那么,它们是怎么来的?自然,是在模型训练过程中得到的。如果只关注模型运行时的Q、K、V,就不容易理解它们的作用。要结合模型的训练过程和运行过程来理解QKV【31】。
假设有一个问答数据库,包含有很多问答,比如:

假设有一个新问题:今天会下雨吗?
此时:Q = 今天会下雨吗?那么这个问题的输出V,应该是什么?
通过问题Q,如果要从问答数据库中查找最接近问题的答案,当然是找相似了。
首先,从所有 K 中寻找最接近 Q 的 K,也就是说要计算 Q 和 [多个K] 的相似性,只有找到最接近 Q 的 K,才能找到最接近 K 的 V。
Q和K的相似性,实际上在训练的过程中,就是训练数据K1、K2之间的相似性。在得到了输入序列之间的相关性权重之后,对V做一个加权处理,从而就找到了最接近 K 的那个 V。
Q 和 K 的相似性,K 和 V 的相关性,都是在训练过程中得到的,包含在模型权重矩阵之中。
通过训练过程,得到了 Wq、Wk、Wv 权重矩阵。
这样,在模型运行过程中,当输入一组新的 word 序列时,通过这些权重矩阵对输入进行相似性、相关性计算,最后就得到了最接近 V(训练得到的) 的一个输出序列。
(3)计算attention score — 算出关系
总结一下,到目前为止,对于某条输入序列X,我们有【32】:
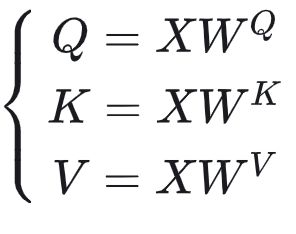
现在,我们做两件事:
- 利用Q和K,计算出attention score矩阵。
- 利用V和attention score矩阵,计算出Attention层最终的输出结果矩阵。
记最终的输出结果为 Attention(Q,K,V),则有:
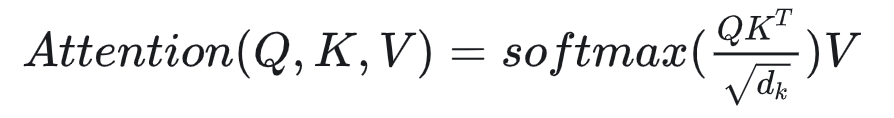
(4)输出 — 使用关系,加权输出
在softmax之后,attention score矩阵的每一行表示一个token,每一列表示该token和对应位置token的α值,因为进行了softmax,每一行的α值相加等于1。
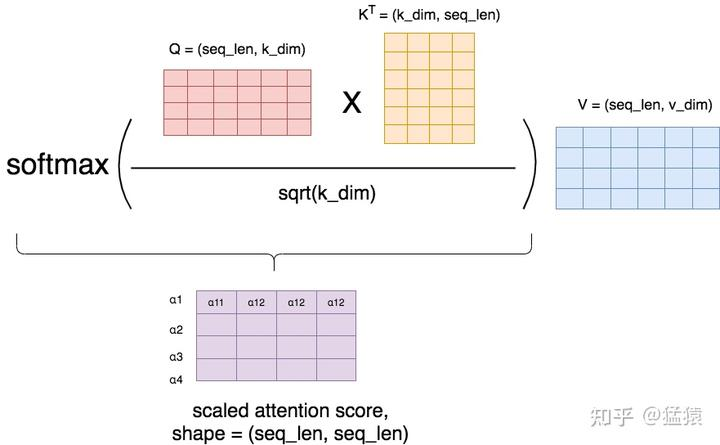
之所以进行scaling out(大规模的预训练),是为了使得在softmax的过程中,掌握更多更准确的关系,梯度下降得更加稳定,避免因为梯度过小而造成模型参数更新的停滞。
4 ResNet(残差网络)和 Batch Norm & Layer Norm(批量标准化/层标准化)
用于稳定和加速训练。自注意力机制层上方还包括一个 Add & Norm 层,Add 表示残差连接 (Residual Connection) 用于防止网络退化(这也是RNN的顽疾),而Norm 表示 Layer Normalization,用于对每一层的激活值进行归一化,也就是将每一层神经元的输入都转成均值方差都一样的,这样可以加快收敛。
5 Feed Forward Network (前馈网络)
用于进一步处理和变换特征表示。Transformer还使用了Feed Forward前馈网络,它由两个线性变换和一个非线性激活函数(通常是ReLU)组成。输入的词向量经过一个线性变换,将其映射到一个更高维度的空间。然后,通过ReLU进行非线性变换。最后,再经过一个线性变换,将其映射回原始的词向量维度。通过多层前馈网络的堆叠,模型可以学习到更复杂的特征表示,从而更好地捕捉输入序列中的语义信息。
6 标准的Transfomer的组装 — Encoder – Decoder结构
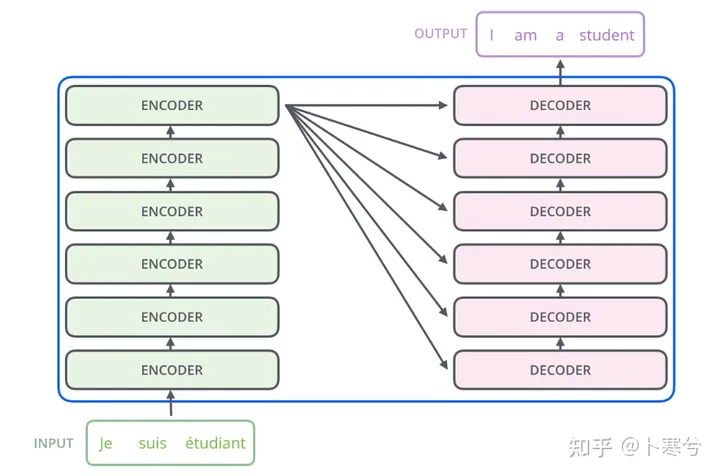
上述的5大算法框架组成了基本的编码器和解码器。
- Encoder的主要任务是将输入序列(通常是文本)转换为一组特征表示(也称为编码)。这些特征表示包含了输入序列的语义信息,供Decoder在生成输出序列时参考。多层的编码层堆叠在一起,每一层都处理并增强特征表示,用来提取、凝练(降维)特征,GPT已知是6层。
- Decoder的任务是生成输出序列,通常是根据Encoder的输出特征表示和前面的已生成的输出序列生成下一个单词或符号。相比于Encoder,解码器多了掩码多头自注意力机制(Masked Multi-Head Self-Attention Mechanism):用于处理已经生成的输出序列,通过掩码确保解码器在每个位置只关注之前的位置,避免泄露未来的信息。
- 线性层和Softmax:Decoder的最终输出通过一个线性层变换为词汇表大小的向量,并通过Softmax函数转换为概率分布,用于选择下一个单词。
其实了解了Encoder-Decoder架构的训练思路和过程后,就可以发现这种架构存在的几个最大的缺点【33】:
- 数据预处理:Encoder-Decoder模型通常对于输入和输出之间的精确对齐要求非常严格,这也就意味着需要复杂的数据预处理过程。而且对于不同类型的输入和输出数据,可能需要用到不同的预处理方法,比如机器翻译中的双语对齐;比如图像字幕识别任务中的图像预处理和文本预处理等等。
- 输入数据难以获取:Encoder-Decoder架构通常高度依赖于输入和输出之间的关系,这就要求收集到的输入和输出数据具备精确的映射关系,增大了数据收集的难度,大大减少了符合要求的数据量。
- 训练时间更长:由于结构的复杂性,Encoder-Decoder模型可能需要很长的训练时间。尤其是处理长序列时,为了理解和编码整个序列的上下文,为了计算序列中每个元素与其他所有元素间的关系,为了储存更多的数据点和中间计算结果,仅在Encoder阶段,就需要消耗大量的时间和内存,增加训练难度。
- 模型应用受限:仅对特定类型的任务表现良好,比如谷歌翻译不能用于进行语音识别,每涉及到一种新的功能,便需要重新训练一个模型,耗时耗力,很不灵活。
Encoder-Decoder架构通常用于处理一些需要在输入和输出间建立精确映射的任务,比如机器翻译、文本摘要等。在这些任务中,理解输入的精确内容并据此生成特定的输出是非常重要的。而基于这种架构训练出来的模型,一般只能应用于某种特定的任务,比如一个专为机器翻译训练的Encoder-Decoder模型可能不适合直接用于文本摘要或其他类型的任务。
而去年如雨后春笋般冒出来的各种大模型,一个重要的主打功能便是:多模态。
也就是说,对于大模型的要求是,既能文字聊天,又能语音聊天;既能生成文本,又能画出美图;
既能根据文字出音,又能根据文字做视频。
这样”既要又要”的高难度需求,显然Encoder-Decoder架构不再适用,Decoder-only架构也就应运而出。
7 其他大模型的框架演变 — Encoder-Only & Decoder-Only结构
下面这张图是一个大模型的一个分布树,纵轴代表大模型的发布年份和大模型输入token数,这个图很有代表性,每一个分支代表不同的模型架构,今天以图中根系标注的三大类展开:Encoder-only、Encoder-Decoder、Decoder-only。
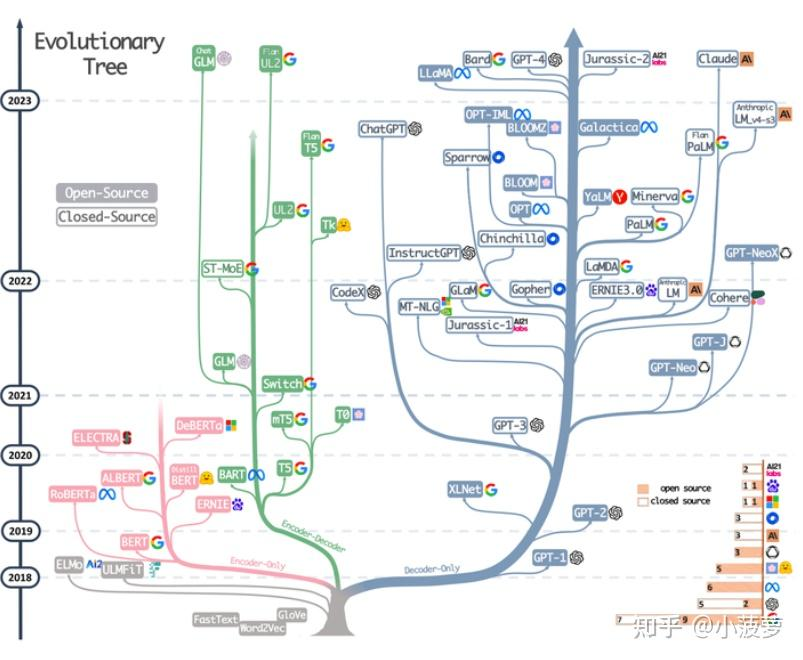
Encoder-only
Encoder-only是以Bert为代表的模型及其衍生优化版本为主。
一句话总结,BERT核心原理:使用多层嵌套的Transformer的编码器来处理输入序列,使用双向语言模型预训练策略进行掩码预测。
Bert开始的时候只是希望能够用这个框架能够学习语言的语法规则,针对主要是文本分类、问答等任务,所以只需要使用Transformer的编码器能够实现文本的语义理解就可以了,不需要生成序列。
搞清楚了Bert原理,那为什么说BERT属于Encoder-only模型?很简单,因为它只使用了Transformer模型中的编码器部分,而没有使用解码器。
在Transformer模型中,编码器负责将输入序列转换为上下文感知的表示,而解码器则负责生成输出序列。BERT使用了编码器。
只使用编码器最主要的原因:BERT的预训练目标是通过掩盖部分输入来预测其他部分,或者预测两个句子之间的关系–已有内容的预测,不是新的输出,这些任务并不涉及到生成输出序列,因此不需要解码器。
Encoder-only架构的LLMs更擅长对文本内容进行分析、分类,包括情感分析,命名实体识别。
Decoder-Only
现在最热门就是这个架构了,解码器结构,当家的应该也是目前整个大模型领域的领头羊:GPT。
Decoder主要是是为了预测下一个输出的内容/token是什么,并把之前输出的内容/token作为上下文学习。实际上,decoder-only模型在分析分类上也和encoder only的LLM一样有效。
各种实验表明decoder-only模型更好,Google Brain 和 HuggingFace联合发表的 What Language Model Architecture and Pretraining Objective Work Best for Zero-Shot Generalization? 曾经在5B的参数量级下对比了两者性能。
从技术上讲,Decoder Only的LLM始于GPT,可能最初仅仅是为了简化结构追求规模。后来发现Transformer的Attention层存在低秩问题,会失去表达能力,而Decoder Only结构保留的Skip Connection和MLP能很好的对抗Attention层的低秩,效果要优于Encoder Only。这种理论上的优势成为后来LLM普遍采用Decoder Only的一个重要原因。
论文最主要的一个结论是decoder-only模型在没有任何tuning数据的情况下、zero-shot表现最好,而encoder-decoder则需要在一定量的标注数据上做multitask finetuning才能激发最佳性能。而且encoder-only在大参数下还有一定的涌现能力。
通过体验多模态LLM的聊天功能、图片生成、语音对话等,就可以发现Decoder-only架构的灵活性。不仅如此,Decoder-only可以让模型构建和训练的各个步骤都显得更加便捷:
- 灵活的输入格式:由于Decoder-only模型本质上是根据给定的文本串生成输出,因此它们可以接受各种格式的输入。包括问题和回答、提示和续写、以及代码和其执行结果等。也就是说,无需特意对输入数据集进行”清洗”。
- 无需特定的任务架构:与Encoder-Decoder架构不同,Decoder-only模型不需要为不同类型的任务构建特定的encoder部分。也就是说,同一个模型可以在没有或仅需要少量修改的情況下,处理多种任务。
- 简化的预训练和微调过程:在预训练和微调阶段,没有繁琐的encoder过程,Decoder-only模型可以更加容易的进入训练过程。此外,由于训练过程主要关注如何基于给定的上下文生成文本,因此既不需要用户提供复杂的输入输出编码关系,也不需要专门处理这些复杂的映射。
- 易于扩展性:由于结构的简单和统一,Decoder-only模型通常更容易扩展到更大的模型尺寸,有助于提升模型的性能和适应性。这也就是去年涌现出的众多LLM,参数数量能够不断攀上新高的主要原因之一。
总而言之,在成本、泛化性、可扩展scale out上,decoder-only模型更优越,更容易做大模型。
但挑战也依然存在:
- 大模型的可解释性较为薄弱。由于大模型采用了深度神经网络架构,模型参数往往过亿级别,因此数据在模型中的处理过程难以追踪,也很难获得对模型推理结果的有效解释。
- 更大的模型带来了更高的训练成本,包括高科技人才的智力支出、大数据和大算力所需的经济成本,此外,还有不可忽视的环境影响。
- 越来越大的模型所带来的效用提升正在缩小。人们发现,当模型参数规模增长 10 倍时,得到的性能提升往往不到 10 个百分点。
- 大模型带来了伦理方面的风险。由于大模型的训练需要的数据极为庞大,因此靠人工进行收集和检查并不现实,一般都采用机器自动进行训练数据的收集,导致训练集中可能存在粗俗、暴力、色情等内容。
8 Scaling Law 缩放定律
Scaling Laws简单介绍就是:随着模型大小、数据集大小和用于训练的计算浮点数的增加,模型的性能会提高。并且为了获得最佳性能,所有三个因素必须同时放大。当不受其他两个因素的制约时,模型性能与每个单独的因素都有幂律关系(短板效应)。
大模型的Scaling Law是OpenAI在2020年提出的概念【34】,具体如下:
对于Decoder-only的模型,计算量C(Flops), 模型参数量N, 数据大小D(token数),三者满足:
C≈6ND
模型的最终性能主要与计算量C,模型参数量N和数据大小D三者相关,而与模型的具体结构(层数/深度/宽度)基本无关【35】。
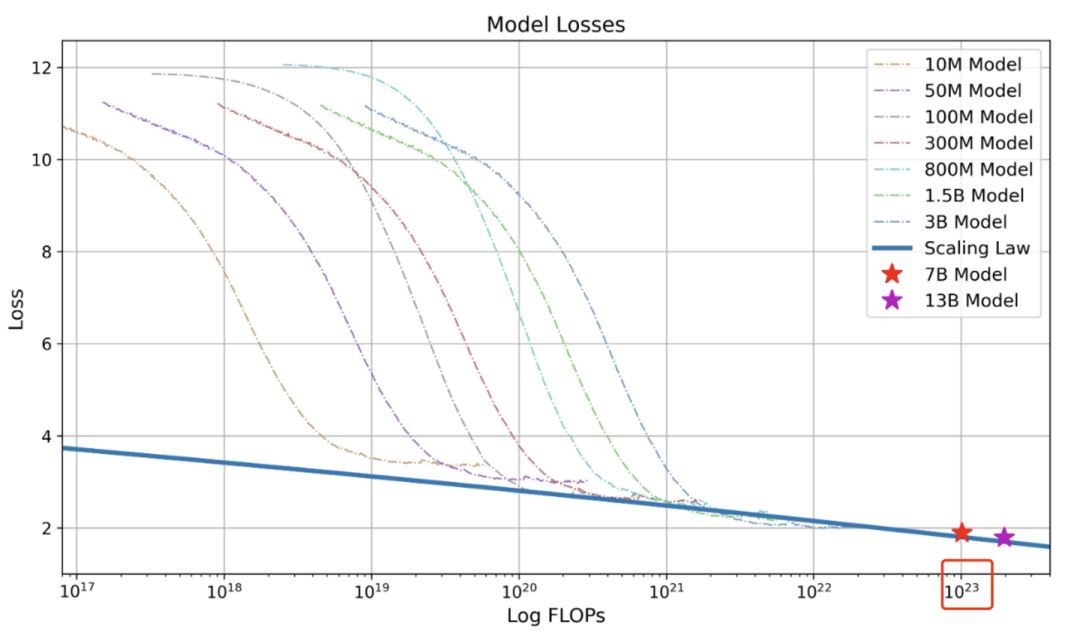
LLM的训练、微调和落地过程-以GPT为例
GPT的三个英文字母分别代表Generative(生成式),Pre-trained(预训练),Transformer。
本质上来说,大模型训练就是对互联网数据进行有损压缩,需要一个巨大的GPU集群来完成。
以700亿参数的Llama 2为例,就需要6000块GPU,然后花上12天从大概10T的互联网数据中得到一个大约140GB的“压缩文件”,整个过程耗费大约200万美元。
GPT的原理—文字接龙游戏
GPT真正在做的事就是“文字接龙”。简单来说就是预测输入的下一个字概率【36】。
但并不是直接选择概率最大的文字作为输出,而是在输出时候还要掷骰子,也就是说答案具有随机性 也就是为什么每次你问大模型的时候,一样的问题会得到不一样的输出。
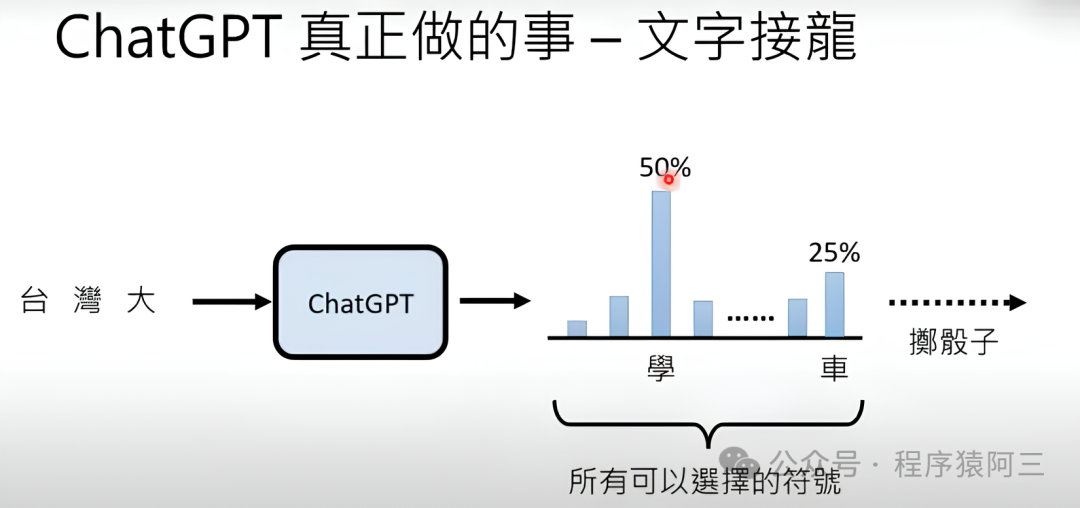
这跟我们以往做预测的时候,感觉很不一样, 以往我们都是输出概率最大作为结果,所以为什么要掷骰子呢?
因为有很多相关研究证明,每次输出最大概率不一定是最好的,类似地文章《The Curious Case of Neural Text Degeneration》中有论证过, 同时这也符合我们人类特征, 同一个问题,可能问同一个人多次, 答案的输出并不是一模一样。
ChatGPT的答案为什么不一定是对的?
如果我们理解了ChatGPT的原理之后,其实ChatGPT就是在关心文字接龙顺不顺畅, 而不会关心内容的真实性。
GPT为什么可以实现上下文关联?
其实还是文字接龙的游戏,在每次回答问题的时候,GPT不仅考虑当前的输入, 也会将历史的对话作为输入。
OpenAI的创始人之一,大神Andrej Karpthy刚在微软Build 2023开发者大会上做了专题演讲:State of GPT(GPT的现状)。首次披露了GPT的训练过程【37】。

粗略地说,我们有四个主要阶段:预训练、有监督微调、奖励建模、强化学习,依次类推。
可以粗浅的的理解为自学、人类教导、找到好老师、老师引导四个的过程。
现在在每个阶段我们都有一个数据集来支持。我们有一个算法,我们在不同阶段的目的,将成为训练神经网络的目标。然后我们有一个结果模型,然后在上图底部有一些注释。
Pretraining 预训练–自学阶段
我们要开始的第一个阶段是预训练阶段。
实际上预训练消耗的时间占据了整个训练pipeline的99%。
因此,这个阶段就是我们在超级计算机中使用数千个 GPU 以及数月的训练来处理互联网规模数据集的地方。
其他三个阶段是微调阶段,更多地遵循少量 GPU 和数小时或数天的路线。
那么让我们来看看实现基础模型的预训练阶段。
首先,我们要收集大量数据。这是我们称之为数据混合的示例,该示例来自 Meta 发布的这篇论文,他们发布了这个 Llama 基础模型。
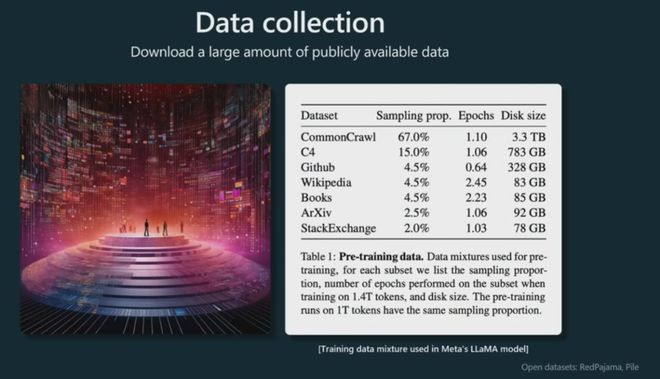
由上图可以看出,大约1个T的数据,作为Llama基础模型的训练集。最多的为网络爬虫数据,然后是谷歌的C4数据集、数集、论文、github等等语料。
那么数据有了,如何把这些数据转化成机器能够看懂的语言?
所以在我们实际训练这些数据之前,我们需要再经过一个预处理步骤,即tokenization。
 T
T
okenization是文本片段与整数之间的一种无损转换,这个阶段有许多算法。通常您可以使用诸如字节编码之类的东西,将所有的文本转化为一个很长的整数列表。
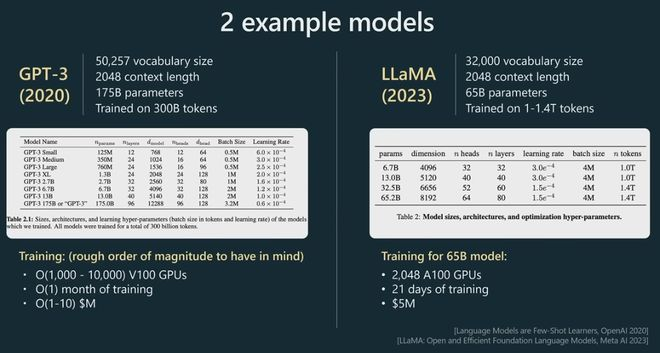
下面我用LLama为例,是Meta的一个相当新的模型。
你可以看到,LLama的参数数量大概是650亿。现在,尽管与GPT3的1750亿个参数相比,Llama 只有65个B参数,但 LLama 是一个明显更强大的模型,直观地说,这是因为该模型的训练时间明显更长,训练了1.4 万亿标记而不是3000亿标记。所以你不应该仅仅通过模型包含的参数数量来判断模型的能力。
这里我展示了一些粗略的超参数表,这些超参数通常用于指定Transformer神经网络。比如头的数量,尺寸大小,层数等等。在底部,我展示了一些训练超参数。例如,为了训练 65 B 模型,Meta 使用了 2,000 个 GPU,大约训练了 21 天,大约花费了数百万美元。这是您在预训练阶段应该记住的粗略数量级。现在,当我们实际进行预训练时,会发生什么?一般来说,我们将获取标记并将它们放入数据批次中。

我们将tokenization后的数组输入Transformer,不可能全部一次性输入,需要用batch思想分批导入。
在此批量大小是B,T是最大上下文长度。
在我的这个图里,长度T只有10,实际工作里这可能是 2000、4000 等等。这些是非常长的行。
批量化后,我们就需要开始训练了。
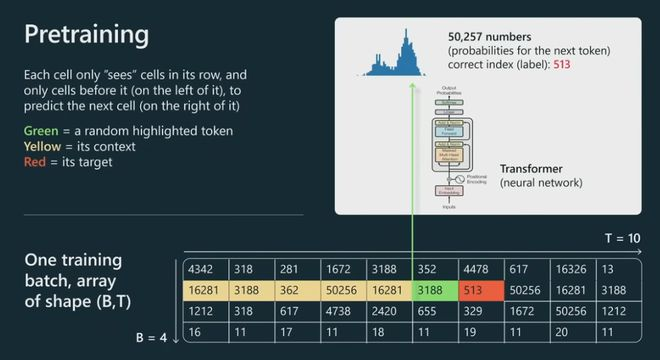
我们只关注一个特定的单元格,但同样的事情会发生在这个图中的每个单元格上。
让我们看看绿色单元格。绿色单元会查看它之前的所有标记,所有标记都是黄色的,我们将把整个上下文输入到 Transformer 神经网络中,Transformer 将尝试预测序列中的下一个标记,在本例中为红色。
现在,在这个特定的例子中,对于这个特定的单元格,513 将是下一个标记,因此我们可以将其用作监督源来更新Transformer的权重。将同样的做法应用于并行中的每个单元格,并且不断交换批次,并且试图让Transformer对序列中接下来出现的标记做出正确的预测。
由上图可以看到,预训练的目标其实很简单。
就是去预测下一个词,根据softmax概率分布,取出相应的词作为输出。
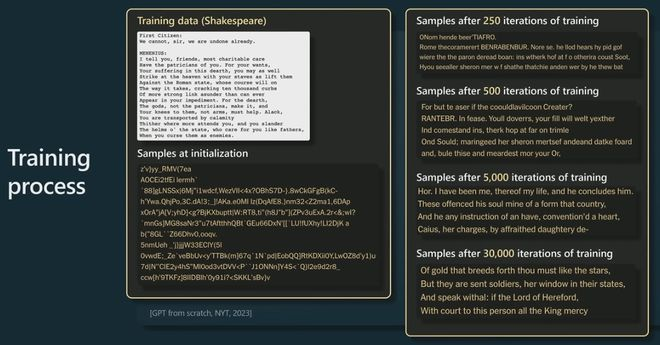
这实际上来自纽约时报,他们在莎士比亚上训练了一个小的 GPT,这是莎士比亚的一小段,他们在上面训练了一个 GPT。
一开始,在初始化时,GPT 以完全随机的权重开始,因此也将获得完全随机的输出。但是,随着时间的推移,当训练 GPT 的时间越来越长时,我们会从模型中获得越来越连贯和一致的样本。
当然,你从中抽样的方式是预测接下来会发生什么,你从那个分布中抽样,然后不断将其反馈到过程中,基本上就是对大序列进行抽样。到最后,你会看到 Transformer 已经学会了单词,以及在哪里放置空格,在哪里放置逗号等等。
随着时间的推移,模型正在做出越来越一致的预测。
然后以下这些,是在进行模型预训练时会查看的图类型。
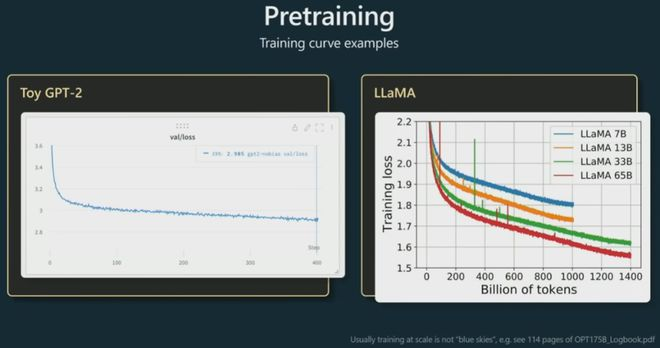
实际上,我们在训练时查看随时间变化的损失函数,低损失意味着我们的Transformer正在预测正确 – 为序列中正确的下一个整数提供更高的概率。
训练一个月后,我们将如何处理这个模型?
我们注意到的第一件事,在这个领域,这些模型基本上在语言建模过程中学习了非常强大的通用表示,并且可以非常有效地微调它们以用于您可能感兴趣的任何下游任务。
Supervised Finetuning (STF)有监督微调 –人类教导
这时候在语言模型自学之后,需要引入人类监督训练。这个阶段不需要很多标注好资料去训练,毕竟成本太大。
你写了一篇关于垄断一词的相关性的简短介绍,或者类似的东西,然后承包商也写下了一个理想的回应。当他们写下这些回复时,他们遵循大量的标签文档,并且要求他们生成提供帮助、真实且无害的回答。

通过这种人类监督训练,我们就可以得到一个简易版的GPT模型。
Reward Modeling 奖励建模 — 好老师模型
现在,我们可以从这里继续流程,进入 RLHF,即“从人类反馈中强化学习”,它包括奖励建模和强化学习。
为了让简易版的GPT模型变强,其实OpenAI参考了以前的AlphaGo模型的方式,通过海量的自我对弈优化模型,最终超过人类。为了完成目标,人类引导的方式成本过高,于是乎,请了一个”好老师“(reward模型),这个老师不会像人类监督那样,直接给出答案,而是对模型输出给一个反馈,只有好与不好,让模型根据反馈自动调整输出,直到老师给出好的评价。
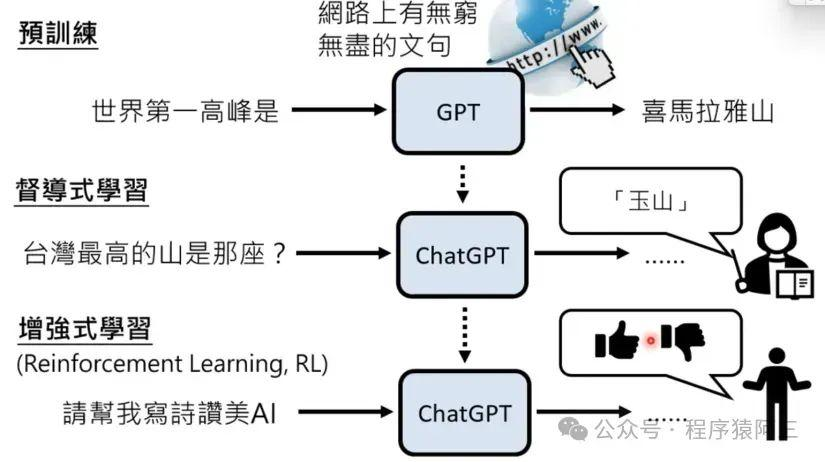
怎么找到有个能辨别 GPT 回答好坏的老师模型(即 Reward 模型)?
于是研究人员让 GPT 对特定问题给出多个答案,由人类来对这些答案的好坏做排序(相比直接给出答案,让人类做排序要简单得多)。基于这些评价数据,研究人员训练了一个符合人类评价标准的老师(Reward 模型)。
Reinforcement Learning 强化学习 — 老师引导
现在我们有了奖励模型,但我们还不能部署它。
因为它本身作为助手不是很有用,但是它对于现在接下来的强化学习阶段非常有用。
有了好老师后,就可以开始像周伯通那样,左手(GPT)右手(好老师)互搏。要实现 AI 引导AI,得借助强化学习技术;简单来说就是让 AI 通过不断尝试,有则改之、无则加勉,从而逐步变强。
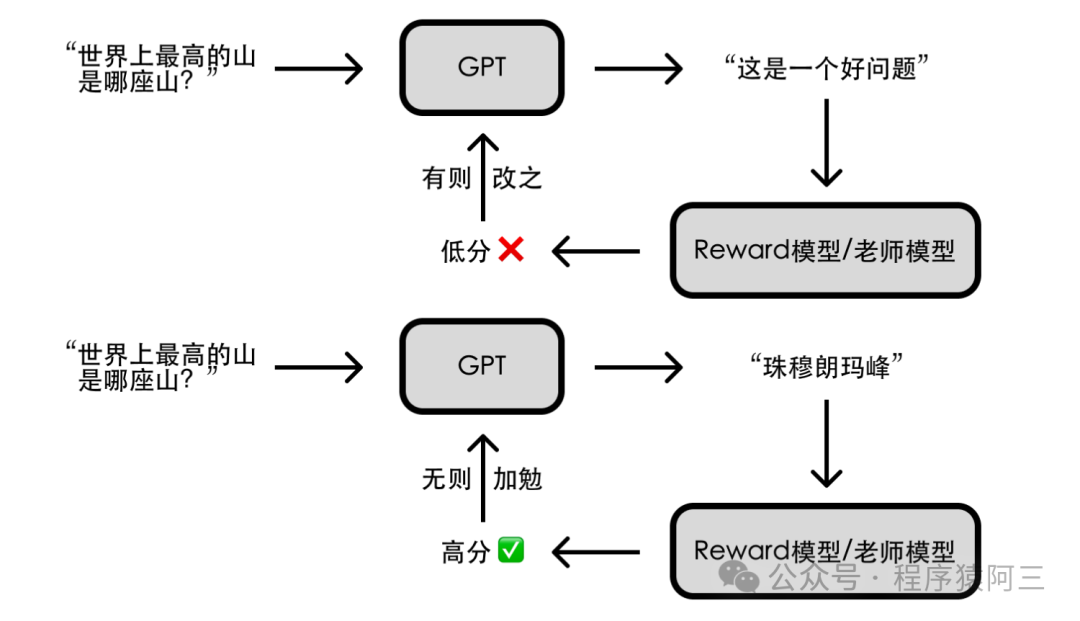
有了人类训练出来的好老师,通过好老师夜以继日引导,从而最终对齐了人类的偏好,最终实现了符合人类特征的回答。
这就是我们训练的方式——这就是 RLHF 流程。
最后,您得到了一个可以部署的模型。例如,ChatGPT 是 RLHF 模型。您可能会遇到其他一些模型,例如 Kuna 13B 等,这些都是 SFT 模型。
我们有基础模型、SFT 模型和 RLHF 模型,这基本上是可用模型列表的事物状态。
你为什么想要做 RLHF?一个不太令人兴奋的答案是它的效果更好。
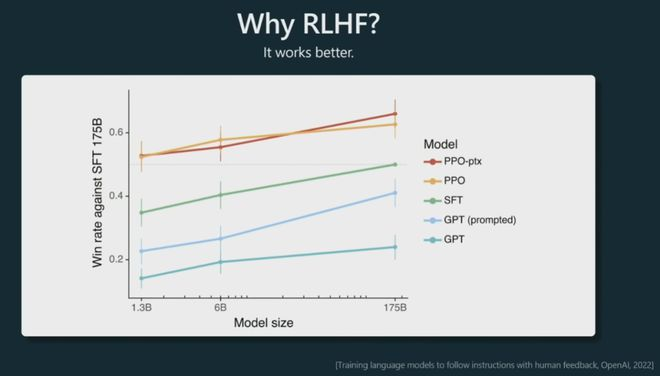
以上这个图来自instructGPT论文。
这些 PPO 模型是 RLHF,根据前一段时间的这些实验,我们看到把它们提供给人类时,它们在很多比较中更受欢迎。与提示为助手的基础模型相比,与 SFT 模型相比,人类基本上更喜欢来自 RLHF 模型的标记(输出文字)。
特别是,我们注意到,例如,RLHF模型失去了一些熵,这意味着它们给出了更多的峰值结果。(更符合人类希望的回答偏好)

模型部署和应用 Deploy and Application
模型压缩:通过剪枝、蒸馏、量化等技术减少模型大小,便于部署。
系统优化:计算机架构上进行推理加速等
服务部署:将训练好的模型部署到服务器或边缘设备上,提供给用户使用。
开发Agent工具:前后端,RAG、执行工具、和产品逻辑等。
多模态大模型
多模态指的是多种模态的信息,包括:文本、图像、视频、音频等。顾名思义,多模态研究的就是这些不同类型的数据的融合的问题。通过NLP的预训练模型,可以得到文本的嵌入表示;再结合图像和视觉领域的预训练模型,可以得到图像的嵌入表示。
那么,如何将两者融合起来,来完成以上的各种任务呢?
很简单将图像转变为语言描述即可,和其他语言大模型一起训练,本质都是找关系,输入输出语义的对齐。
Diffusion 模型 –DDPM架构
文生图、视频皆来源此架构,LLM提供语义指导,Diffusion模型通过指导生成图片和视频,两者对齐指导和生成图像信息。
DDPM(Denoising Diffusion Probalistic Models)。扩散模型的研究并不始于DDPM,但DDPM的成功对扩散模型的发展起到至关重要的作用。后续一连串效果惊艳的文生图模型,都是在DDPM的框架上迭代改进而来【38】。
假设你想做一个以文生图的模型,你的目的是给一段文字,再随便给一张图(比如一张噪声),这个模型能帮你产出符合文字描述的逼真图片,例如:
文字描述就像是一个指引(guidance),帮助模型去产生更符合语义信息的图片。但是,毕竟语义学习是复杂的。我们能不能先退一步,先让模型拥有产生逼真图片的能力?
比如说,你给模型喂一堆cyberpunk风格的图片,让模型学会cyberpunk风格的分布信息,然后喂给模型一个随机噪音,就能让模型产生一张逼真的cyberpunk照片。或者给模型喂一堆人脸图片,让模型产生一张逼真的人脸。同样,我们也能选择给训练好的模型喂带点信息的图片,比如一张夹杂噪音的人脸,让模型帮我们去噪。
具备了产出逼真图片的能力,模型才可能在下一步中去学习语义信息(guidance),进一步产生符合人类意图的图片。而DDPM的本质作用,就是学习训练数据的分布,产出尽可能符合训练数据分布的真实图片。所以,它也成为后续文生图类扩散模型框架的基石。
1 DDPM训练流程
理解DDPM的目的,及其对后续文生图的模型的影响,现在我们可以更好来理解DDPM的训练过程了。总体来说,DDPM的训练过程分为两步:
- Diffusion Process (又被称为Forward Process)
- Denoise Process(又被称为Reverse Process)
前面说过,DDPM的目的是要去学习训练数据的分布,然后产出和训练数据分布相似的图片。那怎么“迫使”模型去学习呢?
一个简单的想法是,我拿一张干净的图,每一步(timestep)都往上加一点噪音,然后在每一步里,我都让模型去找到加噪前图片的样子,也就是让模型学会去噪。
这样训练完毕后,我再塞给模型一个纯噪声,它不就能一步步帮我还原出原始图片的分布了吗?一步步加噪的过程,就被称为Diffusion Process;一步步去噪的过程,就被称为Denoise Process。
2 文生图模型的一般公式
当我们拥有了能够产生逼真图片的模型后,我们现在能进一步用文字信息去引导它产生符合我们意图的模型了。通常来说,文生图模型遵循以下公式:
- Text Encoder:一个能对输入文字做语义解析的Encoder,一般是一个预训练好的模型。在实际应用中,CLIP模型由于在训练过程中采用了图像和文字的对比学习,使得学得的文字特征对图像更加具有鲁棒性,因此它的text encoder常被直接用来做文生图模型的text encoder(比如DALLE2)
- Generation Model:输入为文字token和图片噪声,输出为一个关于图片的压缩产物(latent space)。这里通常指的就是扩散模型,采用文字作为引导(guidance)的扩散模型原理,我们将在这个系列的后文中出讲解。
- Decoder:用图片的中间产物作为输入,产出最终的图片。Decoder的选择也有很多,同样也能用一个扩散模型作为Decoder。
但是目前的的生成模型,去噪不够精细化(比如手无法精细到5个指头),幻象多,生成不连续,生成时间短,离真正的生成还很远,但在图片创意设计领域可以有一定的实际实现。
Agent
Diffusion模型的由DDPM和LLM的结合idea后,那么LLM能否和其他模型结合,能获得更加强大的能力呢?
答案就是Agent,是能够自主感知环境并采取行动实现目标的智能体,并可以通过交互提升能力,甚至与别的 agent 合作实现任务。目前我们所用到的AI大模型相关软件都是Agent。
LLM 是整个系统的“大脑”,围绕其语言理解能力,调用各个模型。
所以Agent的本质还是Prompt Engineering。
Prompt,即提示词或指令,是指向人工智能模型提供的输入文本,用于引导模型生成特定的输出。
很多人认为人类的语言指令本来就非常模糊,定义广泛,所以我们在给LLM下达指令的时候,要明确分步骤和结果等可以引导LLM最大化输出智能的输入方式。这种编辑引导LLM的输入过程就叫prompt engineering-提示词工程。
但笔者认为本质上就是LLM的潜空间Latent space -(可以理解为多个隐藏层导致的无法观察深度黑箱)的语义–LLM的输出没和人类的需求通过transfomer对齐。
基于LLM的Agent,将大语言模型作为核心计算引擎,实现感知(Perception)、规划(Planning)、行动(Action),形成自主闭环的学习过程。
- 感知:理解你的指令,收集信息并从中提取相关知识的能力
- 规划:思考、拆分,总结感知到的信息,为达成目标而做出决策的过程
- 执行:依赖大模型执行,调用工具API或与其他Agent交互
- 记忆:将整个过程(思维链条)保存起来,循环迭代
“认识从实践开始,经过实践得到了理论的认识,再回到实践中去。” -(实践论)
具身智能模型
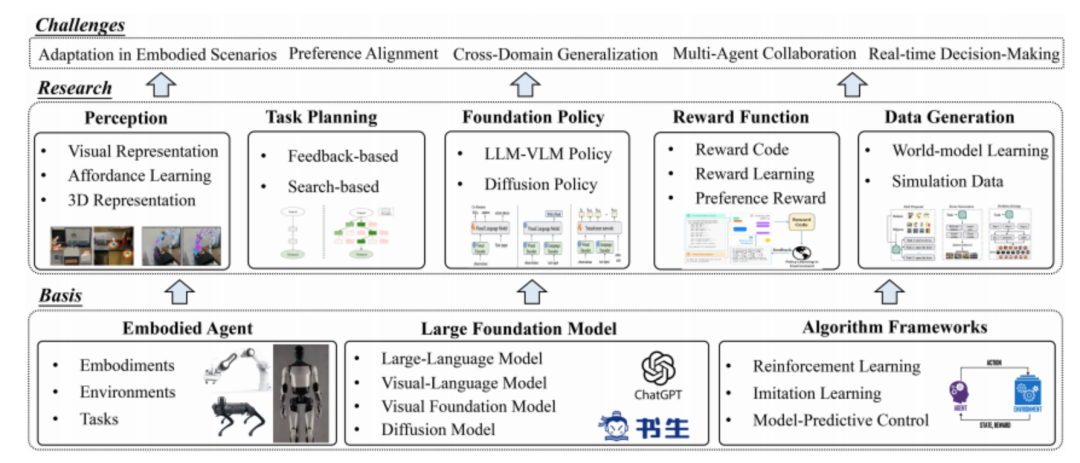
1 引言
具身智能 (embodied AI) 是人工智能、机器人学、认知科学的交叉领域,主要研究如何使机器人具备类似人类的感知、规划、决策和行为能力。具身智能可以追溯到 20 世纪 50 年代, 艾伦 · 图灵首次提出具身智能的概念,探索如何使机器感知和理解世界, 并作出相应的决策和行动。随后在 80年代对符号主义的反思中,以罗德尼 · 布鲁克斯为代表的研究者逐渐认识到, 智能不应该只在对数据的被动学习中得到, 而应该通过与环境进行主动交互中获取, 应当重点研究如何让机器人主动适应环境【39】。
近年来,以ChatGPT为带代表的大语言模型(large language model, LLM)技术取得了突破性的进展,通过在大规模网络对话数据中进行学习,ChatGPT能够实现包括自动问答、文本分类、自动文摘、机器翻译、聊天对话等各种自然语言理解和自然语言生成任务,同时具备在少样本和零样本场景下达到了传统监督学习方法的性能,并具有较强的泛化能力。通过先进的思维链(chain-of-thought,CoT)等提示技术,大语言模型的逻辑推理能力获得了大幅提升,从而有望解决复杂具身智能场景中的任务分解和推理问题。
视觉基础模型(visual foundation model, VFM),通过自监督的学习目标可以获得强大的视觉编码器,能够解决如图像分类、语义分割、场景理解等视觉感知任务。在具身智能任务中,强大的视觉编码器能够对视觉传感器获得的周围环境信息进行分析和理解,从而帮助智能体进行决策。
在此基础上,视觉-语言模型(visual-language model, VLM)通过引入预训练视觉编码器和视觉-语言模态融合模块,使得大语言模型能够获取视觉输入,同时根据语言提示进行视觉问答。在具身智能中,引入视觉-语言模型能够使智能体根据任务语言指令和环境的视觉观测进行推理和决策,从而提升智能体对环境的感知和理解能力。
多模态大模型(large multimodal model)通过引入视频、音频、肢体语言、面部表情和生理信号等更多模态,可以分析更丰富的传感器输入并进行信息融合,同时结合具身智能体中特有的机器人状态、关节动作等模态信息,帮助解决更复杂的具身智能任务。大模型通过充分利用大规模数据集中学习到的知识,结合特定的具身智能场景和任务描述,为智能体提供环境感知和任务规划的能力。
2 传统机器人控制算法简介
MPC和WBC简单介绍
MPC(全称Model Predictive Control)模型预测控制。Whole-Body Control(WBC)翻译过来可以叫全身控制或者整体控制。
机器人的运动控制经历了感知-决策-规划-执行。
MPC主要的任务是预测环境变化,进行姿态规划,然后将姿态的信息–就是时间和空间,传递给WBC(输出电机等指令),充分利用机器人的自由度同时执行多个任务。MPC就是规划求解器,WBC是执行求解器,两者技术都是基于数学的线性规划最优化求解。
一句话通俗易懂的解释:MPC根据状态转移模型(已知当前状态的情况下,给定一个控制,可以准确推导未来的状态),推导出未来一段时间的状态表达式(工程上实现一般用误差表示,即未来状态和目标状态的差值),求解未来一段时间的控制量,做到尽量接近目标状态、尽量的小的控制变化,同时满足控制输出的阈值范围约束【40】。WBC则是分优先级的多任务控制。
算法流程-案例演示
MPC一般用于车辆的控制,特别是在智能驾驶领域,路径的跟踪控制大都离不开此算法,那我们就以车辆控制来说明MPC的主要步骤:
1、建立车辆的运动学模型
2、模型的线性及离散化
3、预测模型推导(建立关于未来一段时间车辆的状态矩阵)
4、目标函数设计(设计未来车辆状态好坏的评价函数)
5、约束设计(速度、加速度等限制);
6、优化求解
总的来说:以上过程就是一个高阶版的线性规划问题,只是里面优化求解的计算过程不需要人工计算,我们只需要根据车辆的模型、约束条件、目标等计算或设计出一些基本的矩阵,然后丢给二次规划优化求解器即可得到。
线性规划最优化求解图文解释
我们知道一个带约束的数学优化问题可以写成如下形式:
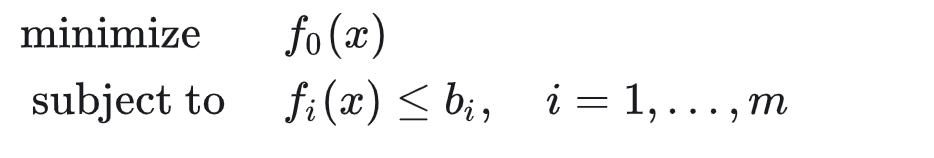
带约束的数学优化问题的优先级体现在约束和目标函数的关系上,当我们求解一个优化问题的时候,总是会保证求解的结果是在满足约束的前提下去最小化目标函数,因此约束本身具有更高的优先级。


我们可以把上述方程式转为几何:针对X1、X2和Z的3D图像(网上随便找的图)
图像里的最高点即为在各个限制条件下的X1,X2自变量的最优Z的解。总而言之,在最优化线性优化的求解器基础数学模型下虽然结果很准确-唯一解;但也有以下缺点:
- 需要对限制条件要求十分严格(不能变)
- 可容纳自变量少,否则运算量爆炸
- 因变量基本唯一
所以在数字化和机器人领域,对于重复性非常强的工作,可以实现替代,但是对于开放式的环境替代极差(结果定义不一、环境条件不一切变动大、任务变化多–术语鲁棒性差)比如:机器人码垛的物料形状一变,就需要重新学习,更别说形状不规则、柔性的物体例如纺织品——纺织行业自动化一直困难的原因。
而随着,科学家们对AI的研究深入,以transfomer为主的注意力架构重塑了深度学习网络,并赋予了更高的智能,Open AI大语言模型和特斯拉的完全端到端fsd神经网络验证了大模型的智能程度以及完全神经网络的架构的优越性。
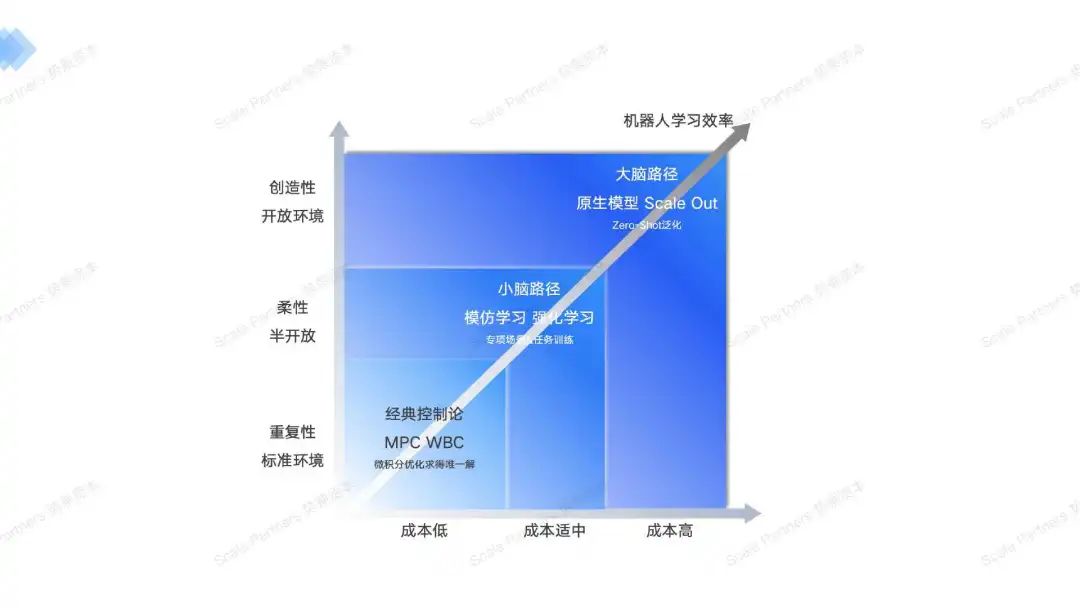
由此诞生出了小脑和大脑路径的公司,针对不同的场景,都有着不同的适用算法模型。
3 小脑算法
在仿真强化学习中,目前比较成功的方向主要集中在强化学习与运动控制上。相关研究通常是完全基于状态,或者通过模仿学习一个表征(latent space),然后再Sim2Real或者Real2Sim2Real在现实世界与仿真环境之间做一个对齐,强化学习在范围内搜索和探索【41】。
目前,该小脑算法可以通过几个小时的时间内通过几十次演示强化机器人某一场景的柔性任务,并且准确率可以达到95%,落地快。
但是由于仿真环境和真实环境GAP、强化学习的长尾问题、模仿学习的过拟合向演示收敛问题,导致小脑并不能拥有很好的泛化性,并对外部的抗干扰弱,而且和本体强耦合。适用于短程任务。
同时也随着模仿和强化学习正在深度融合,稀疏奖励函数设计、人类反馈、采样效率和S2R GAP缩小等新趋势促进了小脑的性能提升,且比大脑落地速度更快,商业化会在近期显现。
期待小脑路径在可执行任务上的扩展。
4 大脑算法
大脑为了找到最佳Scale Out算法,实现GPT的Zero-Shot泛化;通过使用VLM/LLM/DM等模型驱动,强化/模仿学习微调方案,其与模仿学习和强化学习的最大区别为通过大模型学习高级表征在潜空间形成输入输出的关系,提取和理解真实世界的高级物理信息,并推理采取行动。
目前大脑的技术和学习范式还未收敛,我们把市场上的主流路径进行了归纳,分为3条路线。
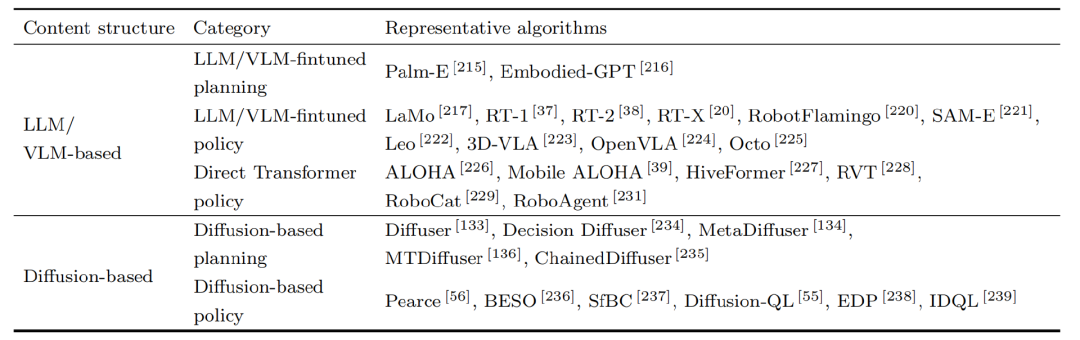
图:大模型驱动的具身大脑算法【39】
Duffsion Model
扩散模型在近期受到了广泛关注, OpenAI 提出的 Sora 视频生成模型被认为是世界模拟器。与隐空间世界模型不同, Sora 可以根据语言描述在原始的图像空间中生成多步的图像预测,组成长达 60s 的内容连贯的视频。
在实现上, Sora使用编码网络将视频和图像表示为词元, 随后使用超大规模的扩散模型在编码中进行加噪和去噪流程, 随后将去噪后的词元映射到原始的图像空间中。Sora在具身智能任务中有着广泛的应用前景, 可以根据机器人任务的描述和轨迹先验生成智能体在后续时间步的轨迹视频, 将生成的视频序列用于基于模型的强化学习、蒙特卡洛树搜索、MPC算法中。在Sora大规模扩散模型提出之前, 已有多个小规模的扩散模型用于具身智能数据生成。
扩散模型作为一种图像生成模型, 通过前向的噪声扩散过程得到高斯噪声, 通过多步逆向的去噪过程恢复出原始图像。在图像生成领域, 扩散模型已经被验证能够建模高维度的复杂数据, 因此在具身智能任务中被用于建模高维度的决策序列。具体地, 扩散模型可以直接作为策略规划器 (Planner), 通过对状态 – 动作序列 [(s0, a0), . . . ,(sT , aT )] 的整体建模, 能够从原始噪声还原出整条决策轨迹, 从而在执行时作为规划器来生成未来的轨迹。

最近的研究中,DiT 模型 (Diffusion Transformer Model)取得较大的进展,例如清华大学的RDT模型-将Diffusion和Transfomer融合,DiT模型是RDT的核心组件,用于处理编码后的特征向量序列,并生成生成机器人动作轨迹。扩散策略是一种生成式策略,它通过学习将数据逐渐转换为噪声,然后再从噪声中恢复数据的过程来生成新的数据样本,恢复数据由transformer的编码器来实现。扩散策略的核心任务是从噪声中恢复数据,这通常需要模型理解输入数据(带噪声的数据和条件信息)的表示。Transformer编码器非常适合这项任务,因为它能够捕捉输入序列中不同位置之间的关系,并生成有效的上下文表示【42】。
该模型在简单任务的频率(200Hz)和准确率(99%)山获得了非常大成功。但仍在萌芽期,期待该技术路径下更多的进展。
VLM/LLM
目前该方式是具身大脑公司的主流技术路径。
在大语言模型直接产生任务规划时依赖模型中编码的知识。由于大模型缺乏具身任务规划的相关知识, 且在具身任务规划时不对大模型参数进行调整, 大模型需要使用额外的反馈模块来对产生的不合理规划进行迭代【39】。
现有研究指出, 一种更为直接的方式是使用具身智能数据对大模型原有的预训练参数进行微调, 使其适应于具身智能任务场景。此时, 可以认为预训练的大语言模型/视觉语言模型将作为具身智能的基础策略, 在进行微调后得到具身大模型。
但是这种组装式的微调具身大模型的缺点非常明显,由于大模型具有较大的参数量, 在机器人任务中需要更大的计算和时间消耗,具有较低的决策频率,频率只能达到30-50Hz,无法达到流畅丝滑运行。且模型本身不是自己研发的,无法进行底层的优化,除非大模型本身能力出众。
原生物理世界大模型
在上述结构的启发下, 有部分研究采取自行设计的以Transformer为主干网络结构, 直接使用机器人数据从头开始训练网络【39】。
在目前技术百花齐放的阶段下,为了收敛至Best Model,为了更好的Scale Out,原生模型在收敛模型范式上具有独一无二的优势:可底层算法优化,自定义设计学习范式和数据类型,模型优化的潜力大。原生模型更能体现出团队的对深度学习,机器人学习等领域的高度理解力!
斯坦福大学提出ALOHA结构使用Transformer编码 – 解码网络结构, 以不同方位的观测图像作为输入, 通过解码器直接输出机械臂动作。为了解决长周期决策问题, ALOHA使用动作分块的概念, 一次预测多个时间步的动作序列, 增强了长周期任务中动作预测的整体性。
在硬件方面, 该研究搭建了低廉的ALOHA开源双臂机器人实验平台, 使人类能够完成便捷的示教数据采集, 仅使用采集的机械臂数据进行训练.。进一步地, 斯坦福大学团队搭建了 Mobile ALOHA移动平台, 通过专家示教数据的模仿学习能够完成滑蛋虾仁、干贝烧鸡、蚝油生菜等菜品的制作, 其出色的效果获得了广泛关注。但成功率有待提升。
还有世界首家设计和训练出AI原生物理世界大模型的公司-智澄AI,在评估所有算法优缺点后自研,以其独特的技术路线、全栈技术实力和前沿深度的AI理解,在交互、场景泛化上获得了优异的模型效果。
5 笔者理解
其中目前主流的投资界将技术分为两条路径:一是端到端训练一套具身大模型;二是基于现有的 LLM 或 VLM 的训练具身分层模型。
然而这种归纳方法,在技术上并不准确,因为两者并不是Mutually Exclusive的,两者是紧密结合的,端到端的大模型也有分层的概念存在–直接使用开源的VLM加上MPC模型进行训练等。同时也不是具身智能算法所关注的重点来区分的,目前学术界和商业界的所需关注的统一的进程为:
在快速发展且百花齐放的观点中,达到学习范式、模型和最佳训练数据的收敛,以此来Scale Out,获得涌现能力。
技术上更进一步,哪种模型可以快速收敛?很肯定的是,原生自研的模型拥有巨大优势,开源模型进行微调的公司,缺少对技术核心–模型的理解,原生模型团队可以随时调整模型训练和结构,进行更好的收敛。
自动驾驶行业的借鉴
我个人认为,自动驾驶的商业演变和技术发展非常雷同,0-1技术阶段上都经历了学习范式和模型的收敛(如下第一阶段),完全可以借鉴自动驾驶的发展路程来推演机器人的未来;特斯拉自动驾驶自2016年起开始自主研发,历经4代硬件计算平台和12个软件算法版本,2021年才推出fsd beta试用版本,2024年V12版本采用端到端自动驾驶技术路线。因此技术到商业化5年比较合理。
当然,自动驾驶也存在完全的软件提供商,也有车队管理商,估值最高的仍是硬软并重的整车商,毕竟先满足了人开车的刚性需求,但是机器人并不是人来操作或者说日常需求的,由此纯硬件的厂商重要性不如软件商。
具身智能的模型相比于自动驾驶也会相对困难,但是ai的产业链也比自动驾驶时期发达多了:
- 没有大量人示教视频数据进行学习——自动驾驶会自动采集人类开车数据,且开车的人非常多
- 具身智能模型需要更深入的理解世界的能力,因为需要执行互动各个物体–自动驾驶操作只需要操作车一个模型
目前可以看到的是,商业和学术领域对此热情高涨,几年内不同的观点理论不断碰撞融合,大家对于具身智能的GPT时刻的快速到来信心充足,加上Open AI和特斯拉成功在前;
虽然目前机器人使用具身智能模型的效果相较于自动化:延迟高、频率低、准确率低;但已经展现出zero-shot(零样本展示,但是模型成功执行)的泛化能力。
个人观点:目前处于0-1的阶段,通过对大模型和运动控制领域的深度理解力,不断试错,来学习和训练范式的收敛才会有泛化效果不错的具身大模型出现,且一定要用神经网络实现定位导航等基础功能,平面预测的泛化性一定会比3d弱;神经网络必须要实现人类的运动控制功能,才能达到泛化性的效果(当然也有隐藏层,无法解释的可能性),具体还是要看效果。
(3)AI算法的评判标准
那么我们怎么去评判一个模型的性能呢?
很多人以为模型算法披露就可以从数学上判断出来,其实不然,一方面没有哪家公司会把算法代码披露给其他方——核心机密,另一方面,算法本身通过无数次训练循环的模式就是黑箱;所以无法像材料学那样,一旦披露分子结构,基本的物理化学特性可以被推测出来。
只有模型的训练结果才可以证明算法的优越性。又或者说统一的测试集即可,比如说一起做高考卷的得分进行比较。
统一的结果:Loss Function
在机器学习领域,损失函数是一种用来衡量模型预测值和真实值之间差异的量度 (偏离程度)。
当然每家的损失函数不尽相同,要保重统计口径的统一,一般论文会附上与其他模型的对比,也要看是否进行了全面的比较。
公开的测试集&评测网站
在业界,评估大模型的指标众多,但大模型的能力多样化使得评价标准难以统一,为选择和衡量大模型带来了新的挑战。
一般业界评测方案是基于数据集评估:
斯坦福大学在探索语言模型(LLM)全面评估的初期,便率先采用数据集作为基准,其选取16个核心任务几十个数据集对常见的30个LLM进行了评测,发布了开创性的评测论文。此后,SuperGLUE、C-Eval及Opencompass等评估框架相继涌现,进一步丰富了基于数据集的LLM评估生态【43】。
无论在什么测试基准里都被当作是一个核心的数据集,值得进一步讨论其细节。它最早是在 Measuring Massive Multitask Language Understanding 这篇 ICLR 2021 的文章中被提出。从题目也可以看到,重要的点在于 multitask,也即模型在非常多的任务下的表现如何。
具体来说他收集了涵盖 57 个任务(也可以说是科目)的人类试题,包含例如数学、历史、计算机科学、法律等等学科,将其组成一个测试基准。可以想到,如果模型要有比较好的效果,需要同时具备世界知识(world knowledge),以及解题能力(problem solving)。现在看来似乎这个想法非常自然且合理,但回头看在当时算是非常有前瞻性了。
这类人类试题主要有以下几个好处:
整体来看,这种试题是测试人类智能的一个很好的载体,无论在哪个国家,试卷考试的方式来判断一个学生的智力水平发展到了什么阶段都是主要做法。所以在AGI比较火热的时候,用来测试模型/机器智能也是十分自然。
从类型来看,不同科目的试题带来了不同纬度的测量,正如 MMLU 强调的,可以测试多任务的能力,拆解来说:
语言 / 社会科学类题目,可以测量世界知识(world knowledge)——想想一个模型需要对中文语境的知识了解到什么程度才可以回答 “明朝的第二个皇帝是谁” 这种问题
数学 / 自然科学类题目,可以测量推理能力(reasoning ability)——模型不仅需要理解题意,还需要根据所有信息进行推理甚至计算再答题
当然还有很多其他的能力,但是上面两个世界知识及推理能力,往往是大模型擅长(相较于小模型),或者说希望能够增强的方面。
由于大家所训练的语境不同,又分为了中文和英文等公开测试:
详细如下,大家可以随时关注榜单变化以了解大模型公司能力的变化。
中文:SuperCLUE
网站如下:
https://www.cluebenchmarks.com/superclue.html
SuperCLUE着眼于综合评价大模型的能力,使其能全面的测试大模型的效果,又能考察模型在中文上特有任务的理解和积累。
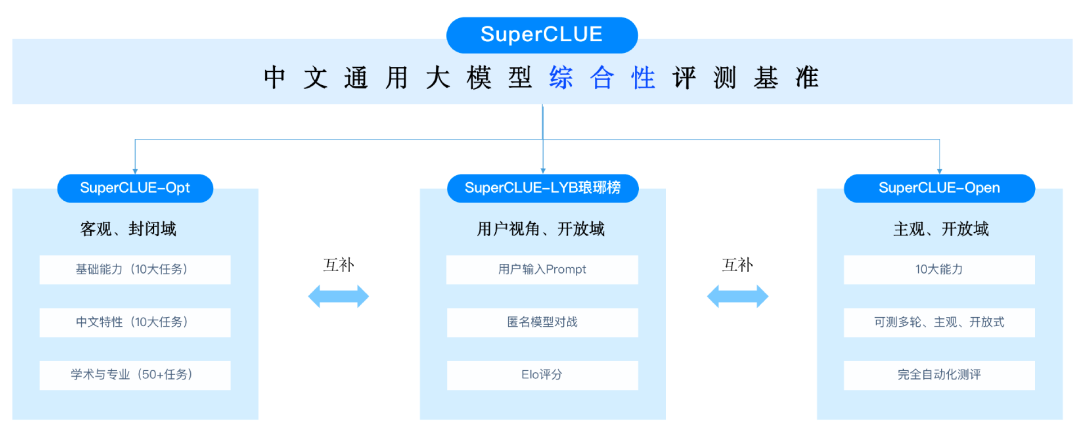
SuperCLUE从三个不同的维度评价模型的能力:基础能力、专业能力和中文特性能力。
基础能力: 包括了常见的有代表性的模型能力,如语义理解、对话、逻辑推理、角色扮演、代码、生成与创作等10项能力。
专业能力: 包括了中学、大学与专业考试,涵盖了从数学、物理、地理到社会科学等50多项能力。
中文特性能力: 针对有中文特点的任务,包括了中文成语、诗歌、文学、字形等10项多种能力。
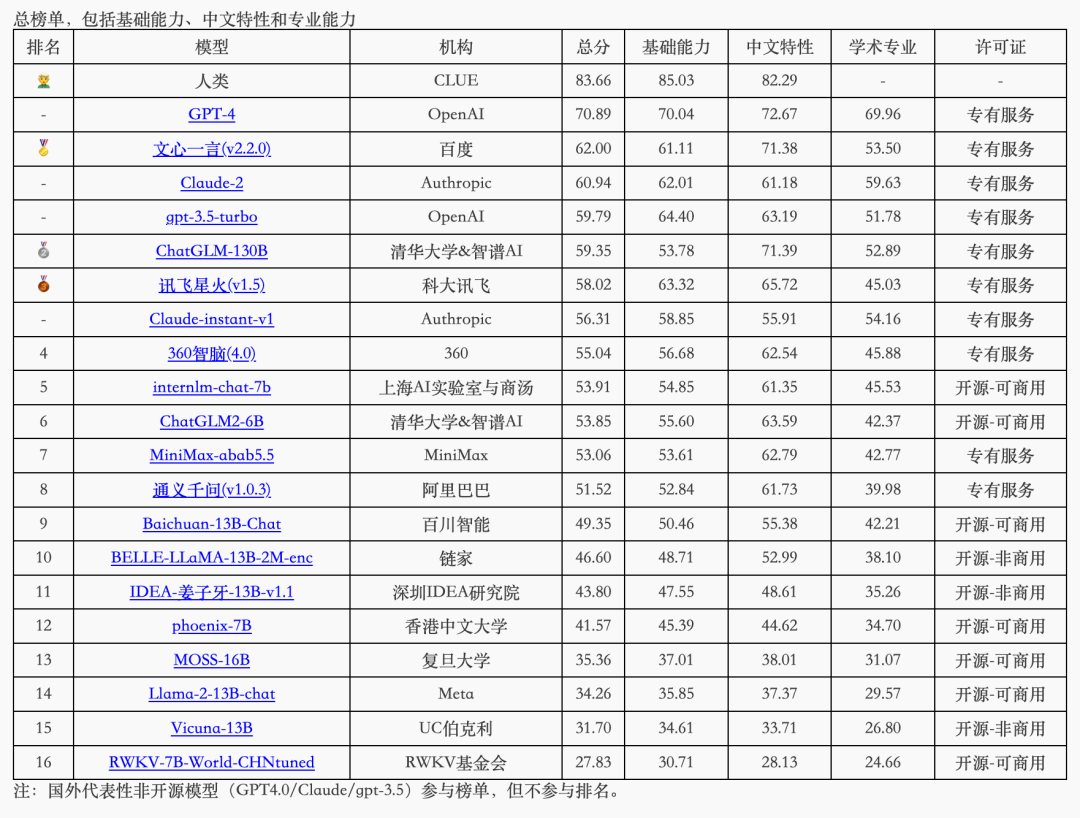
具有自己有评测标准和数据集。评测数据集为闭源类型并不公开,所以评测结果很难模型在上面训练过,大家比较认可这个榜单。
英文:LiveBench AI
网站如下:
https://livebench.ai/#
2023年6月13日,AbacusAI宣布,他们联合了AI界的超级大咖杨立昆(Yann LeCun)和英伟达团队,推出了一个新玩意儿——LiveBench AI,号称是“全球首个无法作弊的LLM基准测试”【44】。
作弊解释:模型公司提前使用将要测试的数据进行微调,从而刷分
为了避免大模型「作弊」,LiveBench 每月发布新问题,并根据最近发布的数据集、arXiv 论文、新闻文章和 IMDb 电影简介设计问题,以限制潜在的数据污染。每个问题都有可验证的、客观的基本真实答案,这样就可以在不使用 LLM 评审员的情况下,对难题进行准确的自动评分。
通过定期更新的问题集和客观的自动化评分方法,LiveBench 提供了一个公平、准确的评估平台,还同时推动了 LLM 的持续改进和社区参与。
LiveBench评判方法
LiveBench的任务设置堪称全面,目前涵盖了18个任务,分布在六大类别:数学、编码、推理、语言理解、指令执行和数据分析。每个任务都属于以下两种类型之一:
- 信息源任务:比如基于最近Kaggle数据集的数据分析问题,或者修复最新arXiv摘要中的拼写错误。这就像是给模型们的实时突击测试。
- 增强版基准任务:更具挑战性或更多样化的现有基准任务版本,比如来自Big-Bench Hard、IFEval、bAbI或AMPS的任务。这些任务就像是高级别的期末考试,难度升级!
具体类别和任务如下:
- 数学:包括过去12个月的高中数学竞赛问题(如AMC12、AIME、USAMO、IMO、SMC)以及更难版本的AMP问题。看看这些问题,真是让人怀疑是不是从数学天才的梦境里偷来的!
- 编码:包括通过LiveCodeBench从Leetcode和AtCoder生成的代码问题,以及一个新颖的代码完成任务。这简直是程序员版的高考。
- 推理:涵盖了Big-Bench Hard中的Web of Lies的更难版本、bAbI中的PathFinding的更难版本,以及Zebra Puzzles。感觉像是推理小说中的谜题在向你招手。
- 语言理解:包含三个任务:Connection单词谜题、拼写修正任务和电影梗概重组任务,均来自IMDb和Wikipedia上的最新电影。这些任务就像是语言学家的午夜狂欢。
- 指令执行:包括四个任务,要求释义、简化、总结或根据《卫报》的最新新闻文章编写故事,并且需遵循一到多个指令或在响应中加入特定元素。真是给AI模型们上了一堂指令遵循的高强度训练课。
- 数据分析:包括使用Kaggle和Socrata最新数据集的三个任务:表格转换(在JSON、JSONL、Markdown、CSV、TSV和HTML之间)、预测哪些列可以用来连接两个表格,以及预测数据列的正确类型注释。简直是数据科学家的最爱!
通过这种多维度的综合方法,LiveBench能够有效评估大型语言模型在不同任务中的表现,确保评估结果的公平性和可靠性。
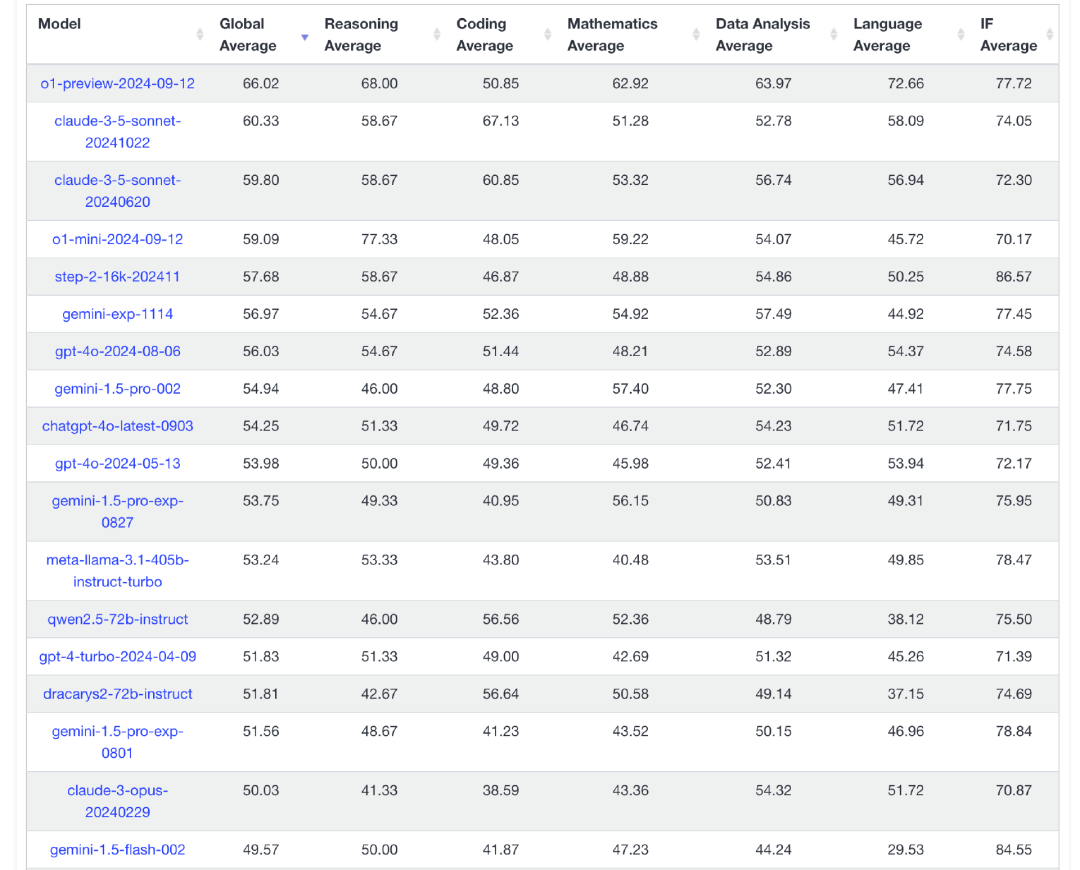
目前国内公司阶跃星辰和阿里的模型分别综合排名第5和13名。
同时若是在离数学模型中获得最好成绩,那我们称该模型为SOTA,SOTA全称是State of the Art,是指在特定任务中目前表现最好的方法或模型。
(4)AI模型的趋势
符号主义到联结主义
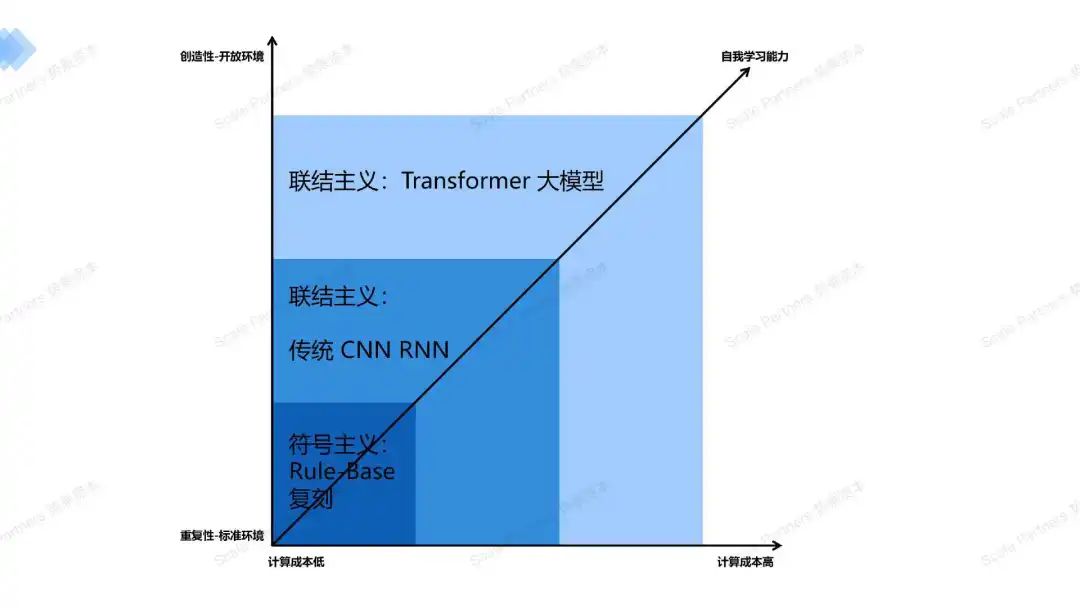
我们能看到三种范式在成本、自学能力和应用下的场景不同。笔者相信每一种算法在成本、技术等考虑下都有其适用的场景。很显然,用大模型推理去做传统数字化、重复性非常高的标准场景例如开发票、结账等,是非常不实用的-成本高,准确率远远不如符号主义的Rule-Base。但是大模型可以指导规则的变化,重写流程。
再例如,目前ViT(transformer的视觉识别)的识别图片的泛化性强但准确率还是不如传统的CNN。不同的算法总有自己的商业和技术定位。
联结主义中,从Transfomer中,我们能明显看到明显的趋势就是一切都是为了更好的Scale Out:
- 架构更加简洁:decoder-only单一架构,输入后即输出,在输出中理解。
- 更精准的压缩和还原:通过注意力机制,实现对大规模数据的特征提取,极限压缩进行理解,并还原。
- 可兼容的训练数据最大化:图片、视频和语言等等,大规模输入,统一化训练
目前大语言模型的趋势
01 技术上
传统Scaling Law正在失效?
近期,围绕Scaling Law的讨论不绝于耳。
起因是,The information在一篇文章指出,OpenAI下一代旗舰模型Orion(或称GPT-5)相较于现有模型,能力提升“有限”(代码能力甚至不如现有模型),远不如GPT-3到GPT-4的跃升,而且Orion在数据中心的运行成本更高。为此,OpenAI不得不连夜转变策略【45】;并且在12月份的产品发布会中,也只发布了o3,GPT5一点消息后没有披露。
如果其所言非虚,就不会只有OpenAI一家被困扰。
果不其然,Google也“出事”了。其下一代Gemini模型原本应该是一次重大升级,但有员工透露:近期在大幅增加资源投入后,模型性能未达到领导层预期,团队连夜调整策略。
与此同时,Anthropic被曝已暂停推进Opus 3.5的工作,官网还撤下了“即将推出”字样。
“三巨头”接连碰壁,让人联想到:Scaling Law可能失效了?
正方:Scaling Law神话终结
- Ilya Sutskever:扩展训练的结果,已经趋于平稳。
- Arvind Narayanan & Sayash Kapoor:即使有效,也数据不足;合成数据并不有效。
反方:Scaling Law没有墙
- OpenAI CEO Sam Altman:there is no wall。
- 英伟达黄仁勋:Scaling Law还会继续。
- 微软AI主管Mustafa Suleyman:不会有任何放缓。
- 微软CEO Satya Nadella:是定律,并且一直有效。
- 前谷歌CEO Eric Schmidt:没有证据显示。
无论各位如何“挽尊”,都掩盖不了大模型“减速”的事实——感受不到当初的惊艳。
退一万步,正如OpenAI研究人员Steven Heidel 所言,就算现在LLM 停滞了,在当今模型的基础上,还有至少十年的产品等着你去开发。
Self-Play RL(自我强化学习)- 后训练是新Scaling Law?
随着9月份 OpenAI o1 模型的发布,LLM 正式进入self-play RL技术阶段。
OpenAI 不是唯一重视 RL 和 Self-Play 的公司,在 o1 之前,Anthropic Claude 3.5 Sonnet 就被视为一个标志性里程碑,Claude 3.5 Sonnet 代码能力显著提升的背后其实是 RL 在起作用;Google 也已经围绕 LLM 做 reward model 展开了多个项目的研究;前 OpenAI 的核心人物 Ilya 创立的新项目 SSI 也和 RL 相关。o1 的发布势必会加速新范式共识的形成,将 RL从头部 AI Labs 的尝试向全行业扩散。
2018 年,Lex Fridman 邀请 Ilya 来 MIT 客座讲一节课,Ilya 选择的主题是 RL 和 self-play,因为他认为这是通往 AGI 的路上最关键的方法之一。Ilya 在讲座中用一句话概括了强化学习:让 AI 用随机路径去尝试一个新的任务,如果效果超出预期,就更新神经网络的权重让 AI 记得多使用成功的实践,然后开始下一次尝试。
强化学习的核心在于”探索”(Explore)和”利用”(Exploit)之间的权衡。LLM 在”利用”现有知识上做到了现阶段的极致,而在”探索”新知识方面还有很大潜力,RL 的引入就是为了让 LLM 能通过探索进一步提升推理能力。
RL 在 LLM 中应用的思路本质是用 inference time 换 training time,来解决模型 scale up 暂时边际收益递减的现状。
Self-Play + MCTS:高质量博弈数据提升 reasoning 能力
推理成本大幅上升:MCTS搜索加入 LLM inference
LLM 直接生成是可以类比系统 1 的慢思考。而 RL 就为 LLM 带来了系统 2 慢思考。
引入了 MCTS 之后,LLM inference 会变得更慢、更贵、更智能。因为每一次回答问题时都会推演很多种可能的思考路径,并自行评估哪一个能获得最高的 reward,然后再将最终的生成结果输出给用户。理想中越难的问题需要分配更多的算力和时间:简单问题 1s 直接输出答案,复杂问题可能需要 10min 甚至 10h 来思考最佳的解决方式。
MCTS 实际推理中,可能是和之前我们预测成本的范式类似:把任务拆解成 5 步推理,每一步尝试 k 次模拟,搜索一整个决策树中的最佳方案。Alphago 下围棋时也是这么在推理时深度推演之后的下棋决策的,只是应用到 LLM 上对算力的要求更高了,需要更多智能剪枝等优化方式。
因此这一部分很难定量的计算其实际对推理需求带来了多大数量级的提升:理论上 MCTS 推演的策略集越全面一定是效果越好的,但是推理算力、用户体验的角度来说一定需要 LLM 厂商去做严格的资源约束,来达到性能和成本之间的平衡。
很明显看到的,最近几个月,o1的推出整体效果并不是很惊艳,笔者观点:一个学习慢的人,再怎么探索世界,学习效果也是缓慢的,效率低下。
02 商业上
未来商业的情况仍然取决于Scaling Law是否继续有效,虽然很多利益相关者都在说并未失效,但是如果后续成本太高或者资源无法满足,也是一种失效。
如果Scaling Law继续有效
在数据满足的前提下,那么继续建造万卡集群,将模型往T级别参数量走,大模型公司继续融资狂欢。
无论Scaling Law失效与否
大家会更加关注大模型如何落地:应用和成本!
基于大模型的应用落地(软硬件、to b to c)将迎来百花齐放,特别关注ARR、月活等关键数据。
由AI Infra优化大模型推理成本直线下降。
大模型将会更注重性价比,模型的参数量会变小的同时,效果会有一定的提升。