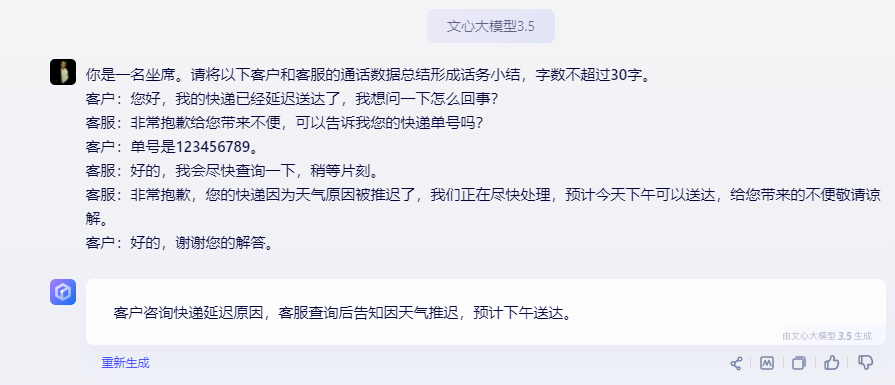
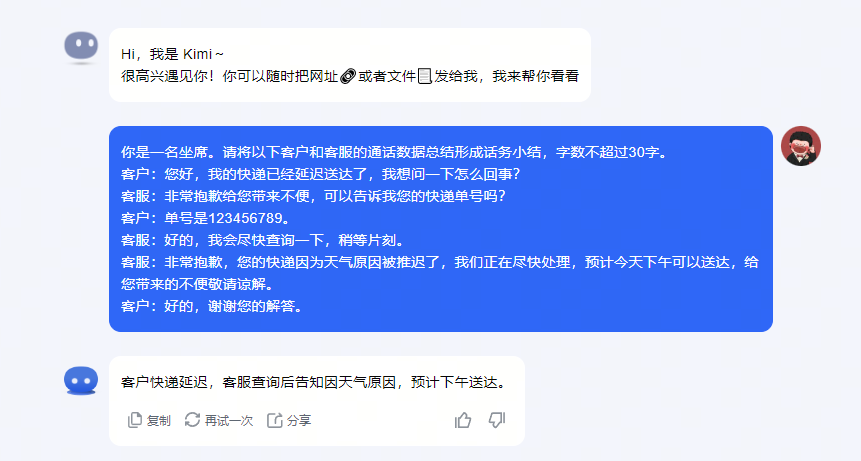
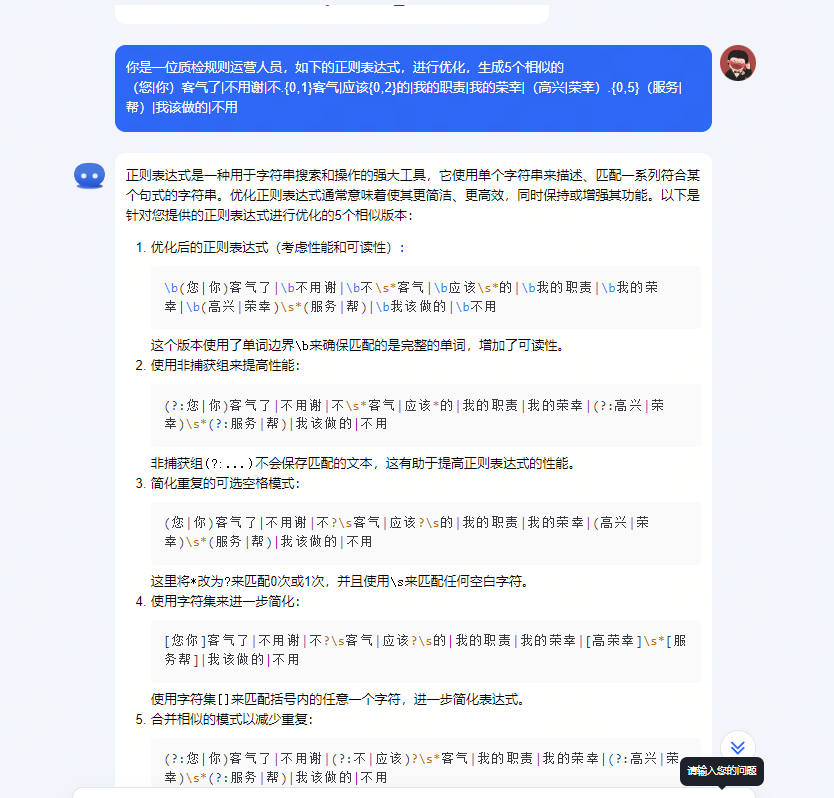
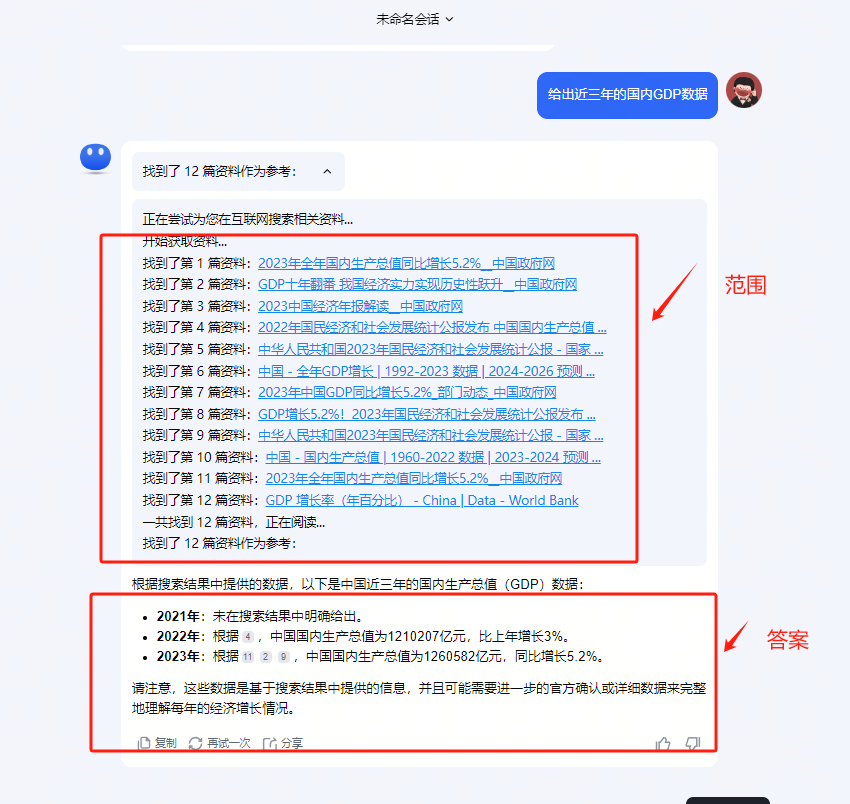
传说,这一夜,OpenAI要改变历史。
看完发布会的观众们,久久未从巨大的震惊中走出——科幻电影中的「Her」,在此刻成真了!

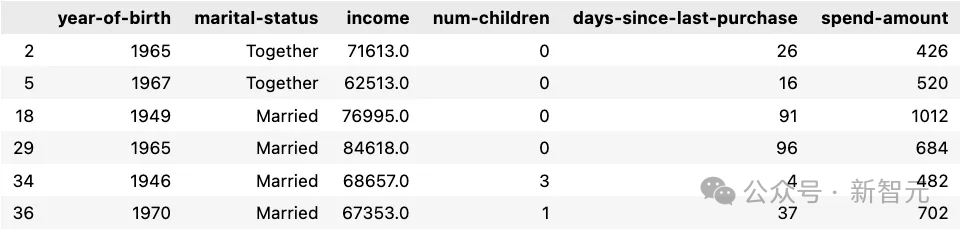
在全场欢呼中,CTO Mira Murati走到台上,为全世界揭晓了OpenAI神秘新产品的面纱——

GPT-4o,在千呼万唤中登场了。
现场演示中,它的表现仿佛一个人正坐在旁边,和人类的对话节奏自然、融洽,完全听不出是个AI。
从今夜之后,人机交互彻底进入新的时代!
这也正呼应着它名字中的玄机:「o」代表着「omni」,意味着OpenAI朝着更自然的人机交互迈出了重要一步。
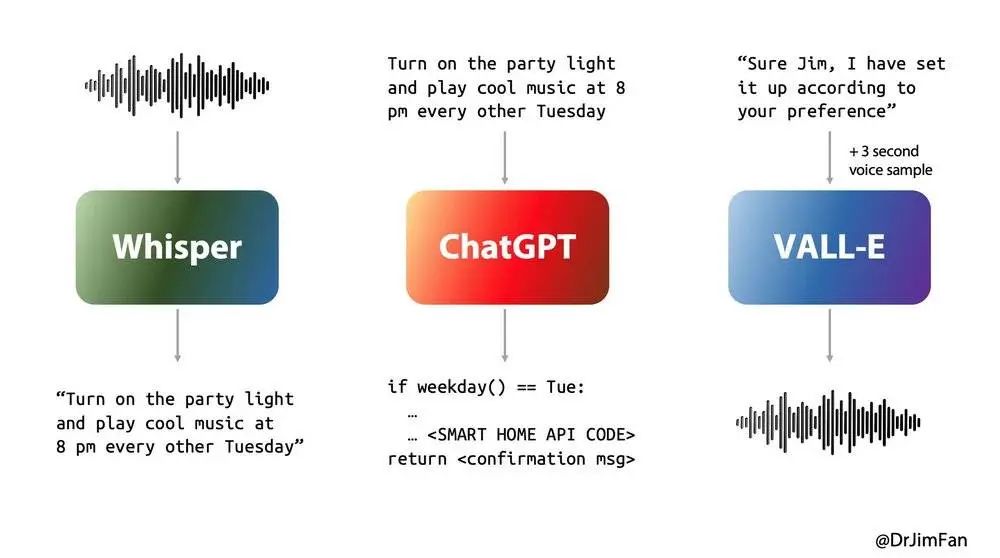
在短短232毫秒内,GPT-4o就能对音频输入做出反应,平均为320毫秒。这个反应时间,已经达到了人类的级别!

并且,它可以将文本、音频、图像任何组合作为输入和输出。
而在英语文本和代码基准测试中,GPT-4o的性能与GPT-4 Turbo不相上下,并在非英语文本得到显著改进。
更值得一提的是,这款全新的AI模型,免费向所有人提供GPT-4级别的AI。
(是的,上周在LMSYS模型竞技场上引起整个AI圈疯狂试用的那个gpt2,就是它!)
现在,进入ChatGPT页面,Plus用户可以抢先体验「最新、最先进的模型」GPT-4o。
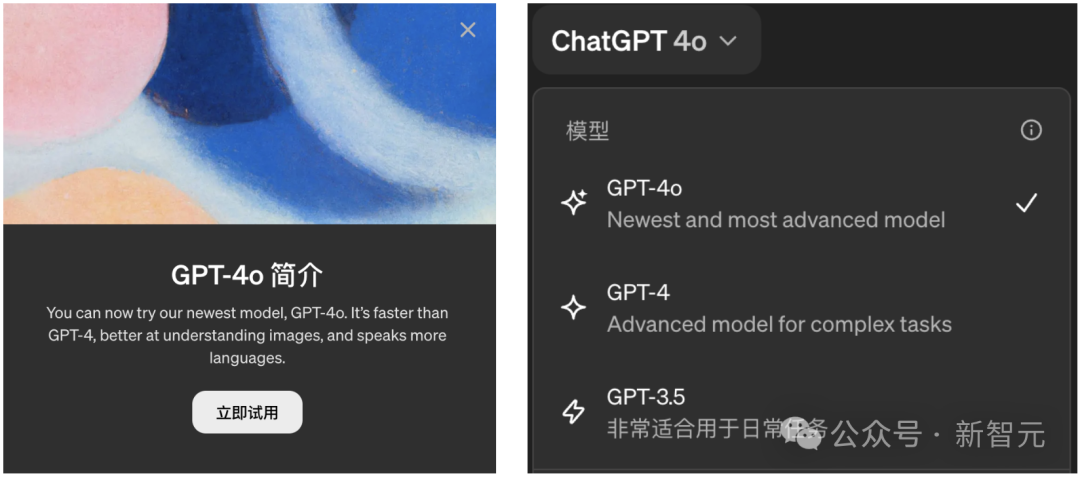
Sam Altman亲自在x上发起了产品介绍。
Altman介绍道「GPT-4o是OpenAI有史以来最好的模型,它很聪明,速度很快,是天然的多模态。」
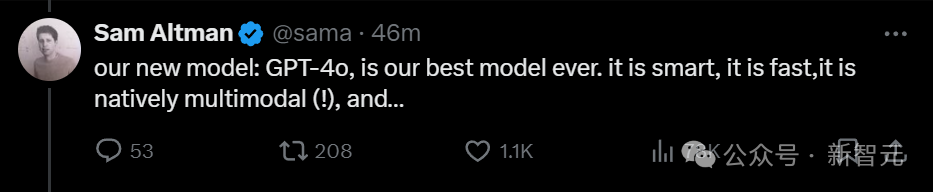
而且,所有ChatGPT用户都可以使用,完全免费!
Altman特意强调,此前虽然只有按月付费的用户才能使用GPT-4级别的模型,但这可不是OpenAI的本意哦。
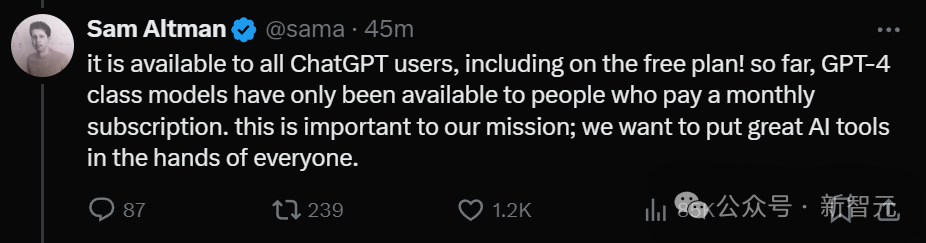
「我们的初心,就是把最出色的AI工具,交到每个人的手中。」

(还想着,这场重要的发布会,奥特曼怎么没有现身,原来在观众席中)
而即将召开年度I/O大会的谷歌,不甘示弱,也开启了语音助手的demo实时演示。
谷歌DeepMin的CEO Demis Hassabis激动地表示,自己将首次在I/O大会上演讲,并分享他们所做的工作。

两大巨头正面刚起来了!明天还有好戏要看,已经闻到硝烟味了。
一、一夜颠覆语音助手:全新旗舰GPT-4o登场
当然,这次发布会的压轴主角,就是OpenAI推出的旗舰模型GPT-4o了。
这个带着光环登场的模型,其最大意义就在于,把GPT-4级别的智能,带给了OpenAI的每一位用户!
从此以后,无论你是付费用户,还是免费用户,都能通过它体验GPT-4了。
唯一不同的是,ChatGPT Plus的消息限制是免费用户的5倍。
并且,GPT-4o不仅提供与GPT-4同等程度的模型能力,推理速度还更快,还能提供同时理解文本、图像、音频等内容的多模态能力。

注意,GPT-4o接下来要放大招了。
1. 实时语音对话:ChatGPT完美变身Moss
研发负责人Mark Chen首先展示的,是全新ChatGPT的关键功能之一——实时语音对话。
他向它问道:「我正在台上,给大家做现场演示呢,我有点紧张,该怎么办呀?」
ChatGPT非常体贴地表示:「你在台上做演示吗,那你真的太棒了!深呼吸一下吧,记得你是个专家!」
Mark疯狂地大喘气几次,问ChatGPT能给自己什么建议吗。(此处全场笑声)
它惊讶地说道:「放松啊Mark,慢点呼吸,你可不是个吸尘器!」(它的幽默感,也再次引起全场哄笑)

注意,在这个过程中,ChatGPT和Mark的互动几乎无延迟,随时接梗,共情能力满分。
而且,模型能够理解人类在对话中适时「打断」的习惯,会及时停下来听你说话,并给出相应的回复,而且也不会「断片」。
比如,Mark表示自己要再试一遍深呼吸,此时ChatGPT也恰到好处地插进来接话说「慢慢呼气」。
整个过程,自然连贯得仿佛它是个坐在你对面的人类,完全没有AI的机械感和僵硬感!
相比反应迟钝、没法打断还缺少情商的Siri等语音助手,这局ChatGPT完胜。
这,才是人类最理想AI语音助手的样子啊,Moss果然成真了!
不仅如此,ChatGPT的「高情商」也让观众们惊呼太顶了!
对话中,它可以听懂用户说话时不同的语调、语气,还能根据自己的台词生成不同语气的语音,完全没有「机械感」。
2. 扮演不同角色,给任性的人类讲睡前故事
接下来,ChatGPT被要求讲一个睡前故事,主题是「恋爱中的机器人」。
ChatGPT没讲几秒,就被人类粗暴地打断了:「多点情绪,故事里来点戏剧性行不?」
ChatGPT表示ok,用更起伏的声调、更夸张的语气开始讲起了故事。
结果没几秒,它又被再次打断:「不行不行,再多点情感,给我最大程度的表达可以吗?」
接下来,我们听到一个仿佛在舞台上表演莎剧的ChatGPT,语气夸张到仿佛是个戏剧演员。
随后,它又多次被打断,并且耐心地按照人类的要求,依次变成了机器人声和唱歌模式。
ChatGPT听到要求自己唱歌时,甚至叹了口气,然后开始亮起了优美的歌喉。
这也就是ChatGPT脾气好,要是真人,估计要被暴打了。不过它无奈叹气的那个瞬间,一瞬间的确san值狂掉——真的好像人啊!
3. 视频实时互动解方程
秀完情商,ChatGPT要开始秀智商了。
下一个任务,另一位研发负责人Barret手写了一个方程,并打开摄像头拍给ChatGPT,让它扮演「在线导师」的角色帮助自己解题,而且只能给提示,不能直接说答案。
接到任务的ChatGPT,甚至开心大叫:「Oops,我好兴奋啊!」
小哥在纸上写下这样一个方程:3x+1=4。然后问ChatGPT自己写的是什么方程,ChatGPT语调自然地回答出来了。

随后,在小哥的要求下,它一步一步说出了解题步骤。
最厉害的是,随着小哥在摄像头中解题,ChatGPT实时地就给出了鼓励和引导。
而且可怕的是,时间上没有丝毫延迟,这边人还在算呢,那边就实时给出了评价和反馈。(说背后没藏个人还真不信呢)

想起之前谷歌剪辑版的Gemini演示,这对比之下真是打脸啪啪的啊。
当被问到「学习线性方程在生活中有什么用」这样的问题时,ChatGPT还会举出实际的例子对你「循循善诱」:
这是个不错的问题,虽然我们没有注意到,但线性方程在每天的生活中都会出现,比如计算花销、规划旅行、烹饪,甚至在商业中进行盈亏计算。这基本上是解决问题的一种方式,你需要找到一个未知变量……
不仅言之有物,而且态度及其和蔼,说话说到一半被打断时都不会生气。
方程的任务告一段落,两人还现场来了一波表白——在纸上写下「我ChatGPT」。
ChatGPT看到后,惊喜又害羞地说:「哦,你竟然说爱我,你太可爱了!」
4. 桌面版ChatGPT秒解代码难题
解方程任务也许还不能充分展现ChatGPT的能力,于是OpenAI又上了一波难度——看代码,并进行简短描述。
模型几乎是立即理解了代码,并给出了丝滑且完整的描述。
比如准确对应了函数名及其功能,并识别出了其中取平均值、最高值等操作的意图。
当被问到「如果没有foo这个函数,绘制的图表会是什么样子」,ChatGPT也立即做出了正确回复,可见已经完美理解了代码中的内在逻辑。

接下来,ChatGPT还被要求概述代码生成的图表,并回答用户问题。

不出意外,图表中各方面的关键信息也都被ChatGPT精准捕捉到了,包括x、y轴的信息与范围、数据标注的含义等。
随后Mark提出的问题是「你看到哪个月的气温最高?对应的最高气温大概是多少?」
这种能作为学校数学考试题目的图表理解任务,ChatGPT解决起来也几乎没有障碍,还能像接受面试一样实时回答你的问题。
5. 直播观众提问:给你看看我的自拍
模型演示之后,还有彩蛋。
发布会在线上同步直播,于是主持人收集了一些推特网友的提问,并且当场展示。
这可以说是比演示更加刺激的环节,在没有准备和彩排的情况下,这可是真刀真枪地检验模型实力了。
第一位网友的提问是「GPT-4o是否具有实时翻译功能?」
随后,在Mark的任务定义下,ChatGPT完成了将英语「同声传译」为意大利语的任务。
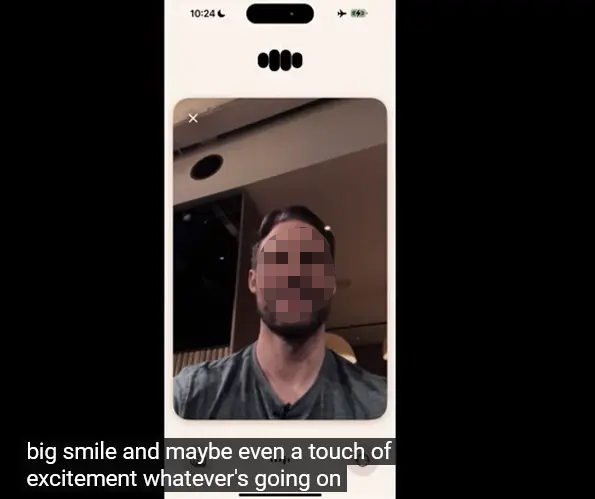
第二位网友的提问是「模型可以只通过我的表情识别情绪吗?」
研发负责人Barett也没在怕,拿起手机就照了一张自拍,甩给了ChatGPT,问道「我现在是什么情绪呢?」
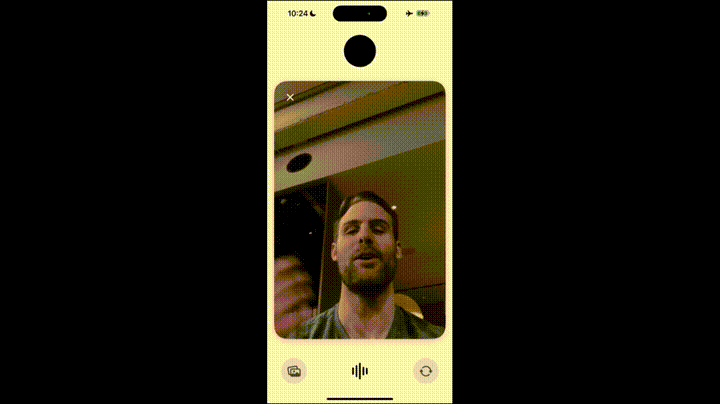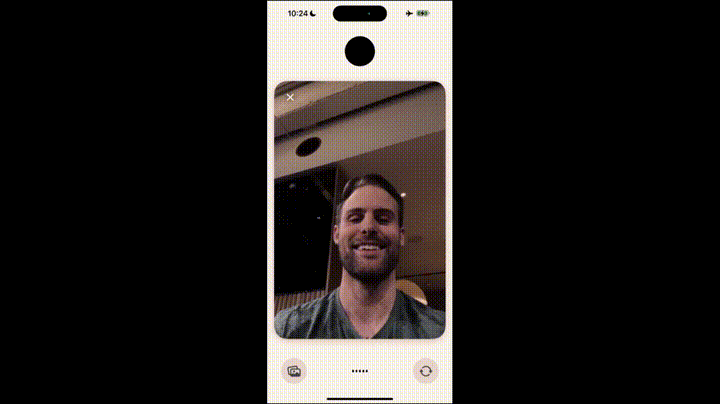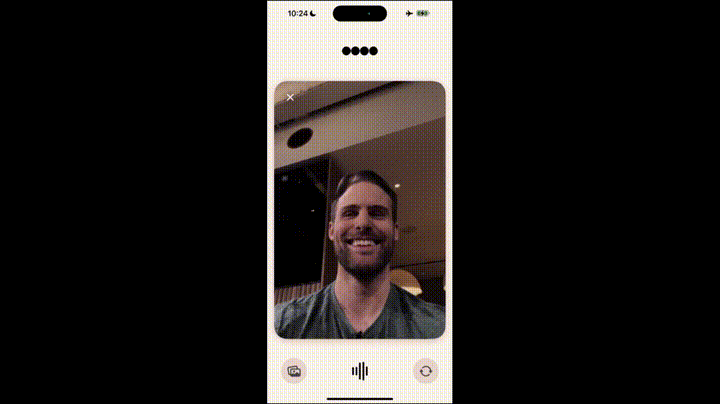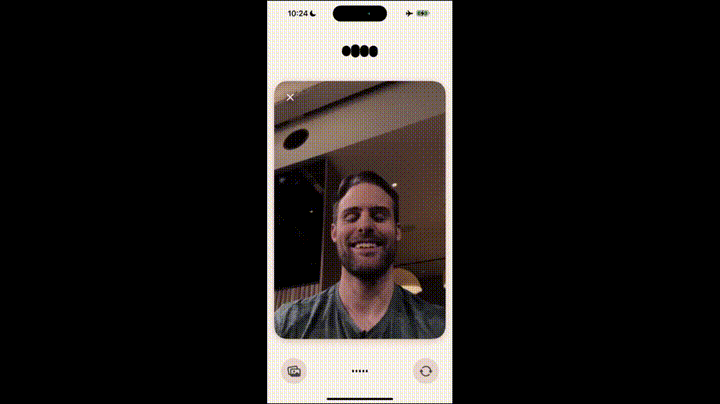
ChatGPT不知是幽默了一把还是翻车了,说「我好像在看一个木质表面的东西」。
见势不好,Barett匆忙打断。他在提示工程方面也是经验颇深,一句话就将对话拉回正轨:「那是我之前发给你的的东西,不用担心,我不是一张桌子」。
ChatGPT表示,啊,这就对了嘛。再次引起全场哄笑。这次它给出了非常「人性化」的正确答案——
「看起来你非常开心快乐,带着大大的笑容,可能甚至有一点兴奋。无论正在发生什么事,似乎你心情很好,愿意分享一下有什么高兴事吗?」
Barett顺势表示:「我开心的原因是我们正在做演示,你的表现很棒。」
受到夸奖的ChatGPT居然很风趣地来了一句「哦,别说了,你都让我脸红了」,再次逗笑了全场。
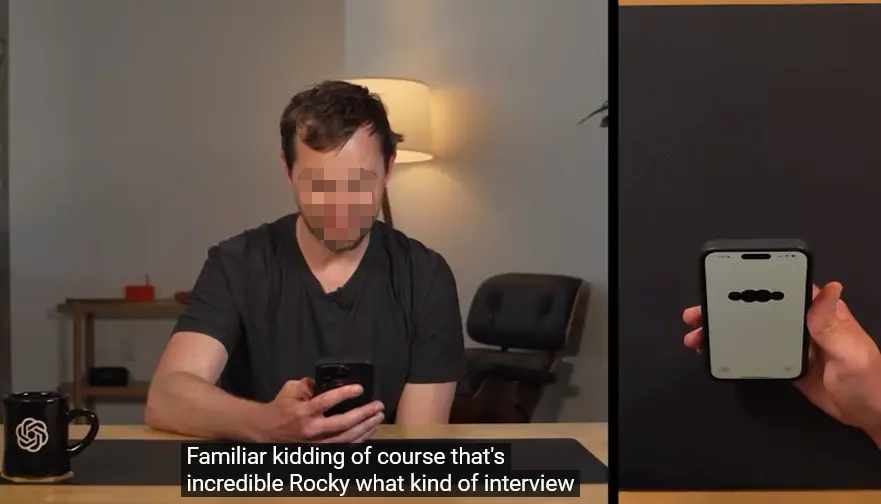
6. Greg Brockman亲自演示
除了发布会上的现场演示之外,OpenAI总裁Greg Brockman也亲自下场,在网上发布了一段自己使用ChatGPT各种功能的视频。
二、GPT-4o强在哪儿?
在过去几年里,OpenAI一直在专注于提升模型的智能水平。
虽然后者已经达到了一个相当的水平,但是,今天这是第一次,模型在易用性方面,迈出了一大步!
为什么会把模型的易用性提到如此战略层面的高度?这是因为,即使一个AI再强大,如果它不能和人有效互动,也就失去了意义。
在这个过程中,OpenAI所着眼的,是人类和机器交互的未来。
而今天GPT-4o的发布,可能会成为一个分水岭,让人机协作的范式彻底迈入一个新阶段!
为此,OpenAI希望把GPT-4o和人类的互动,打造得格外舒服自然。
不过,虽然这个理想很宏大,但是在实际操作过程中,却遭遇了不小的困难。

1. 毫秒级响应,与人类对话一致
首先,在人类之间互动时,有很多东西是我们认为理所当然的,但要让AI理解这些,就变得很困难。
比如,我们的谈话经常被打断,谈话过程中会有背景噪声,会有多个人同时说话的情况,说话人的语气语调也经常发生微妙的变化。
OpenAI克服了很大困难,花费了数月的时间,终于打造出了完美适应这些状况的GPT-4o!
在GPT-4o发布之前,通过语音模式(Voice Mode)与ChatGPT对话,平均延迟为2.8秒(GPT-3.5)和5.4秒(GPT-4)。
当时,为了实现这一点,「语音模式」设有三个独立模型的管线:
– 一个简单模型将音频转录成文本
– GPT-3.5或GPT-4接收文本并输出文本
– 第三个简单模型将文本转换回音频
这一过程走下来,意味着主要的智能来源GPT-4就丢失了很多信息:
不能直接观察语气、多位说话者或背景噪音,也无法无法输出笑声、歌声或表达情感。
而这也导致了延迟,大大破坏了我们和ChatGPT协作的沉浸感。
但现在,GPT-4o让一切都发生得很自然。
它能以平均320毫秒,做出响应。

它可以跨越语音、文本、视觉多种形式,直接进行推理!
GPT-4o是OpenAI首个端到端训练的跨越文本、视觉和音频的新模型,意味着所有输入和输出都由相同的神经网络处理。
这就会彻底颠覆ChatGPT 1亿用户的工作和生活。

不仅如此,由于GPT-4o是「原生的多模态」,自然地集成了语言、视觉和音频等多种能力。
用户可以上传各种图片、视频,以及包含图片和文字的文档,讨论其中的内容。

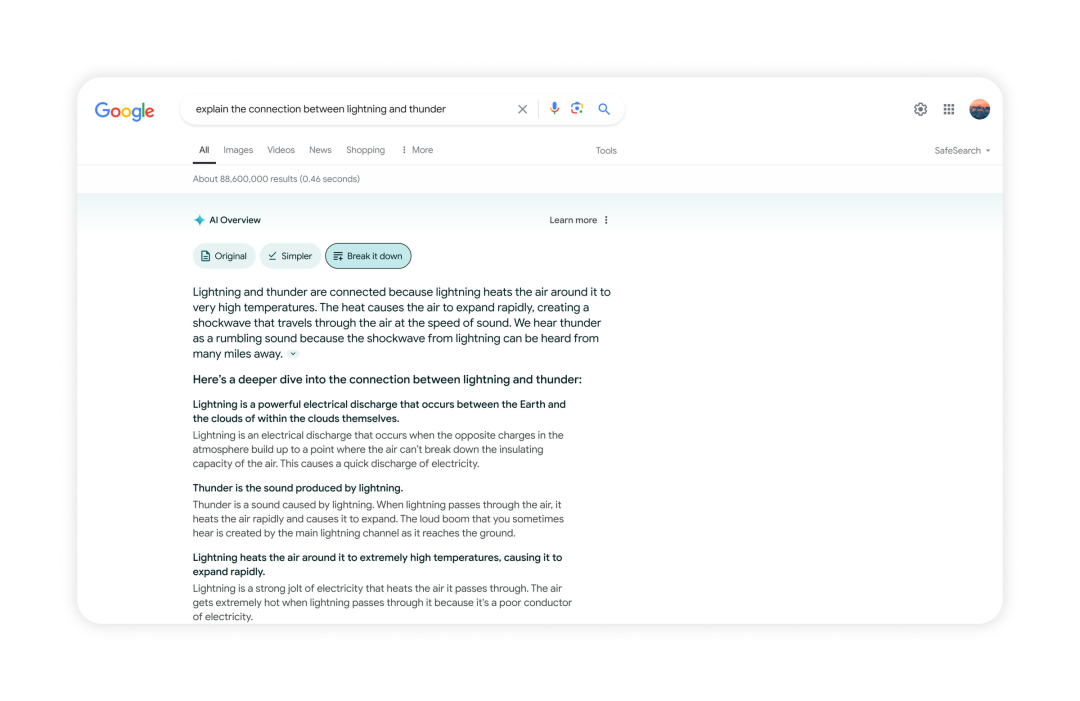
GPT-4o也内置了搜索功能,可以实时搜索网页信息来回复用户。

相比ChatGPT,GPT-4o的记忆能力更是提升了不少,不仅在对话中可以记住你提过的问题,还能记住你们之间的所有对话,提供「连续感」。

更高级的是,新版模型还具备了数据分析能力,可以理解并分析用户上传的数据和图表。

而且,为了真正实现「让AGI惠及全人类」的愿景,GPT-4o有50种语言的版本,并改进了推理的质量和速度,这也就意味着,全球97%的人口都可以使用GPT-4o了!

2. GPT-4o刷新SOTA,击败「开源GPT-4」还免费用
GPT-4o的具体性能表现如何?
接下来的图表中,可以看到,OpenAI对此前所有堪称超越GPT-4版本的模型,做出了统一回应:
We’re so back!
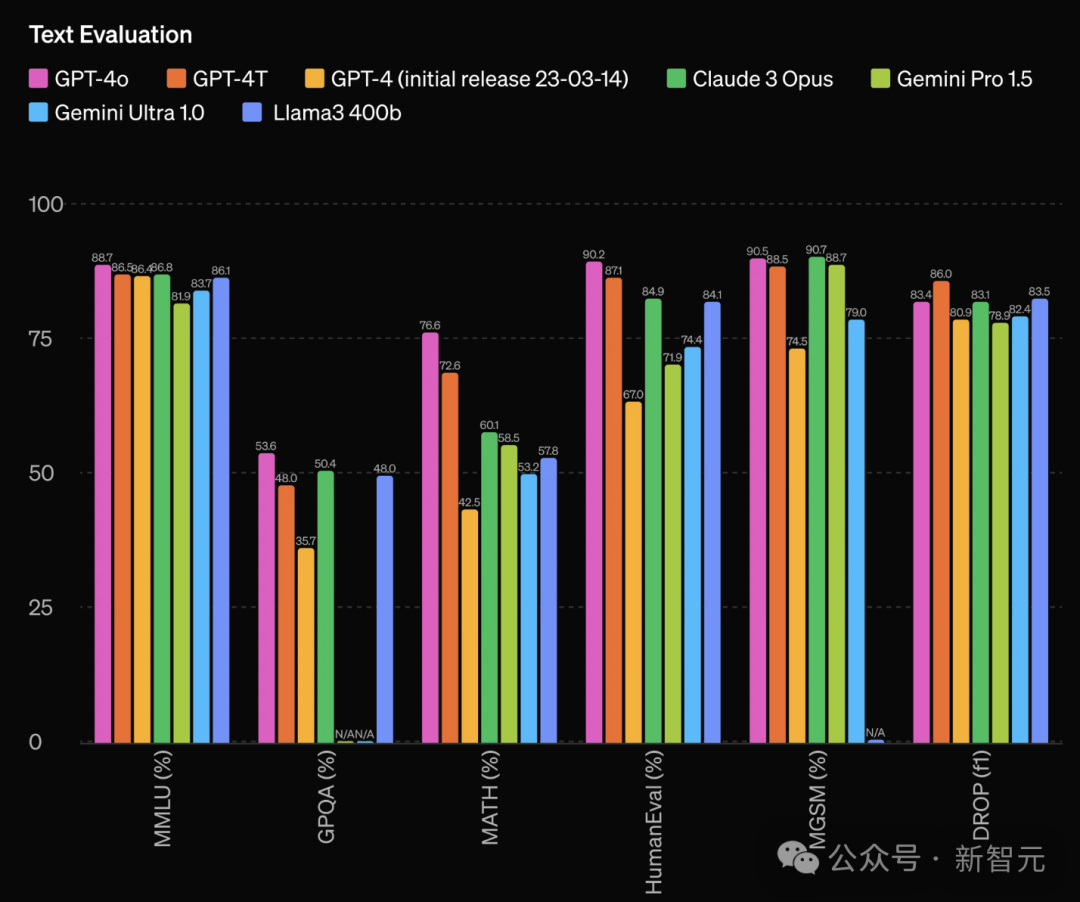
在传统基准测试中,GPT-4o在文本、推理和编码智能方面,达到了GPT-4 Turbo级别的性能,同时在多语言、音频和视觉能力方面创下了新高。
如下是,在文本评估中,GPT-4o几乎碾压一众模型,包括Claude 3 Opus,Gemini Pro 1.5,甚至是「开源版GPT-4」Llama 3 400B。
GPT-4o在零样本的COT MMLU(常识问题)上创造了88.7%的新高分。
与传统的5个样本,没有使用COT的MMLU评测中,GPT-4o更是创下了87.2%的新高分!
不过在DROP中,GPT-4o的表现稍落后于GPT-4 Turbo。
在音频ASR表现上,比起Whisper-v3 ,GPT-4o显著提高了所有语言的语音识别性能,尤其是对资源较少的语言。
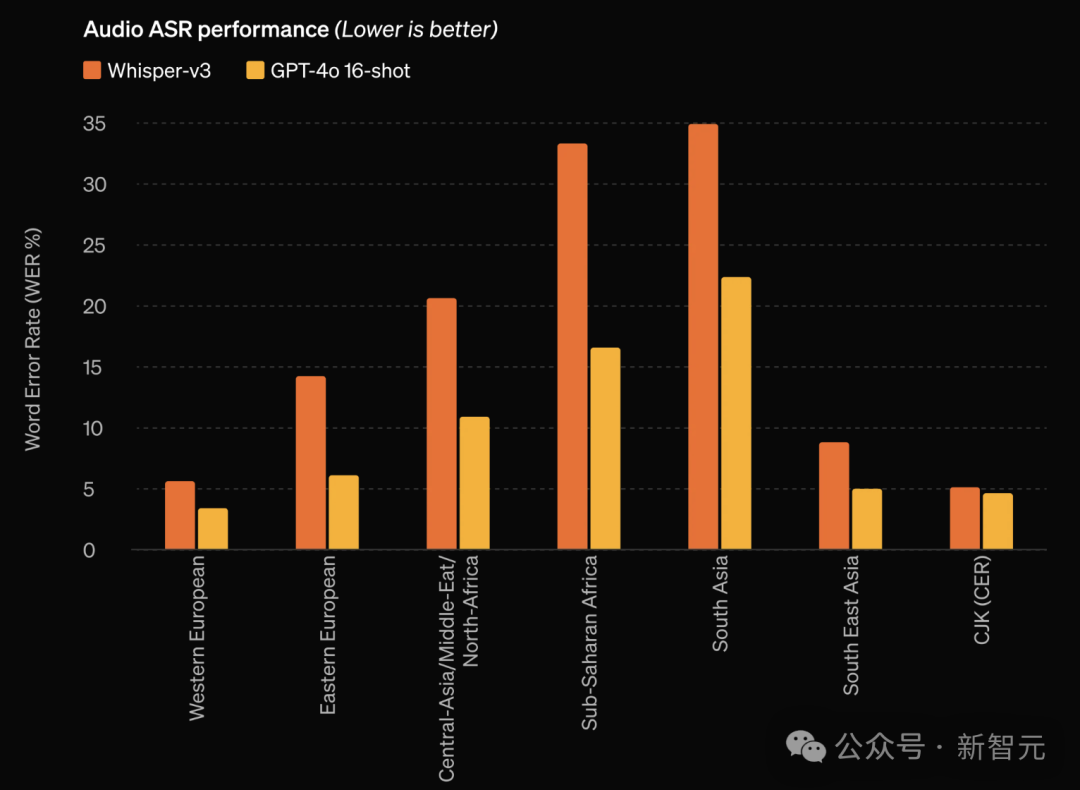
再来看音频翻译能力,GPT-4o刷新SOTA,并在MLS基准上超过了Whisper-v3。

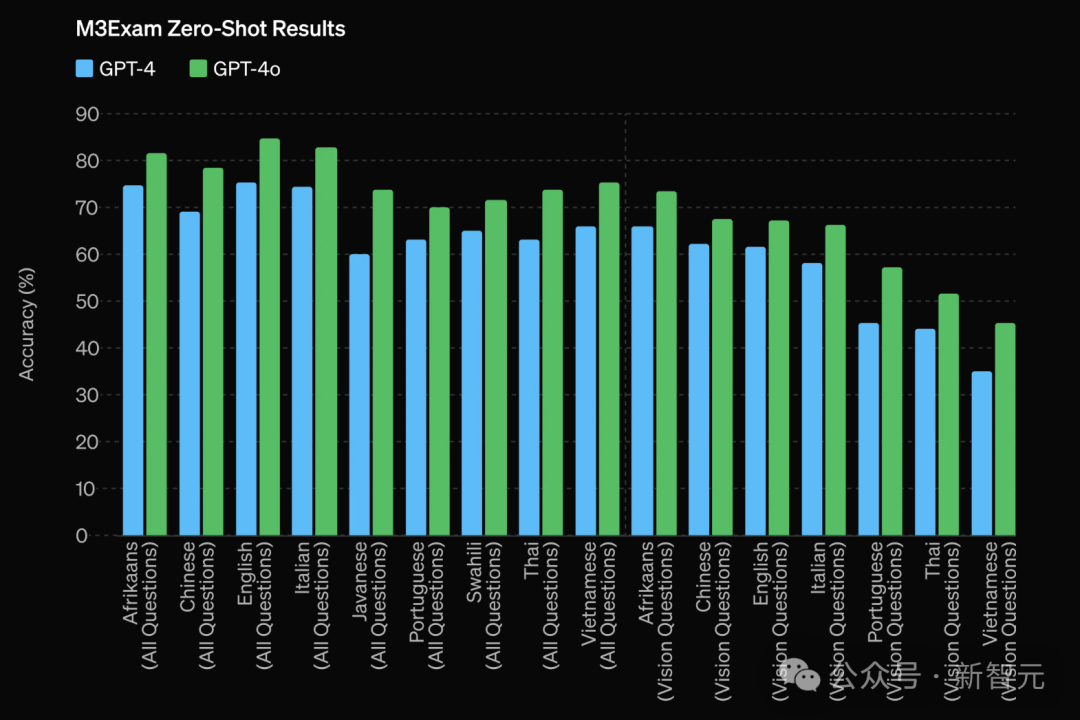
另外,OpenAI团队还对最新模型GPT-4o在M3Exam基准上进行了测试。
这是一种多语言和视觉评估基准,由来自其他国家标准化测试的多项选择题组成,有时还包括数字和图表。
结果如下表所示,在所有语言的测试中,GPT-4o都比GPT-4强。
(在此,省略了Swahili和Javanese两种语言的视觉结果,因为这些语言只有5个或更少的视觉问题。)
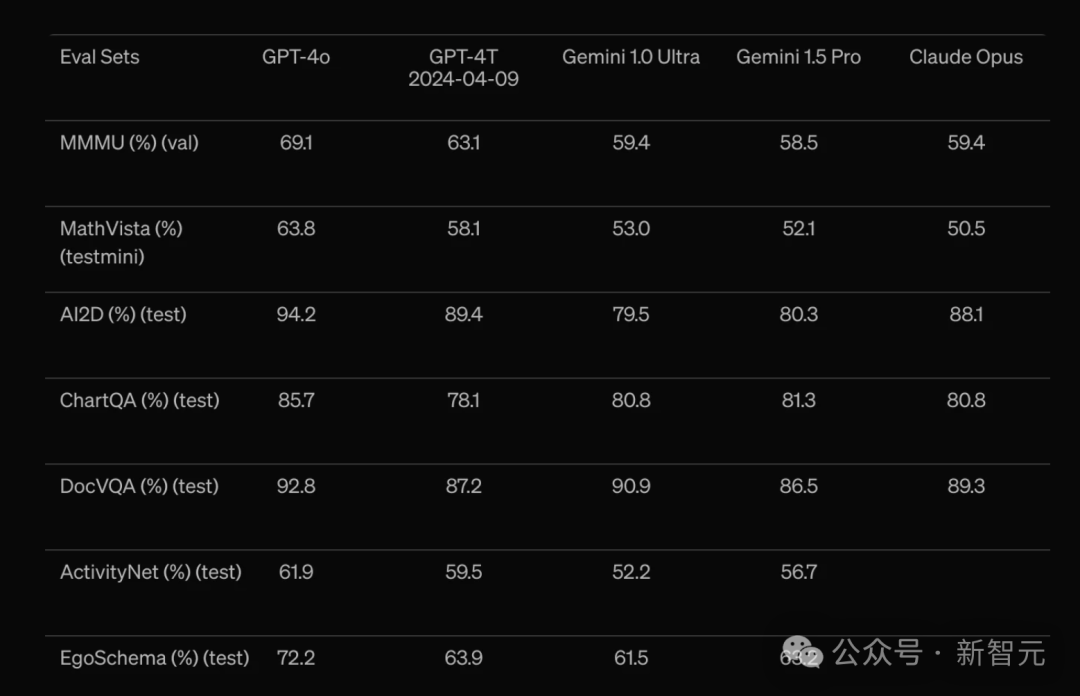
最后,在视觉理解基准EVALS评估上,GPT-4o也取得了领先的性能。
同样,击败了GPT-4 Turbo、Gemini 1.0 Ultra、Gemini 1.5 Pro,以及Claude 3 Opus。
3. ChatGPT免费用户,可以访问的功能
OpenAI官博还介绍了,ChatGPT免费用户可以访问新模型加持下的功能,包括:
– 体验GPT-4级别的智能
– 从联网后的模型得到响应
– 分析数据并创建图表
– 畅聊你拍的照片
– 上传文件以帮助总结、撰写或分析
– 发现和使用GPTs和GPT Store
– 用记忆构建更有用的体验

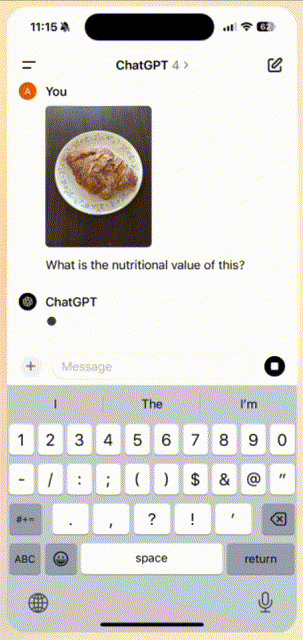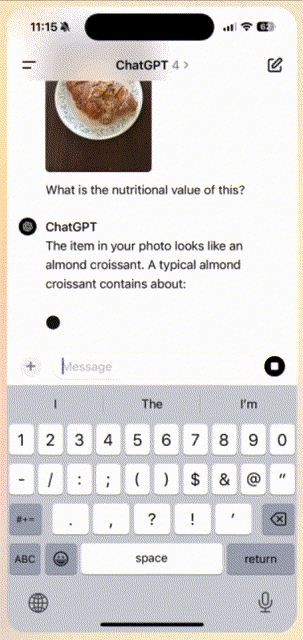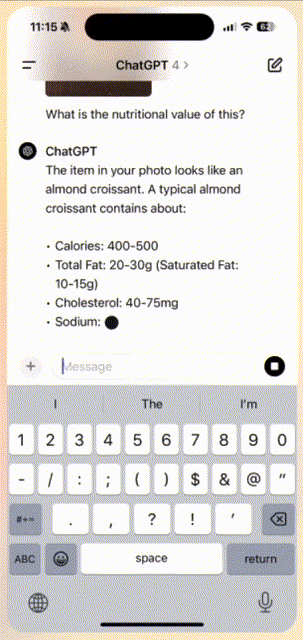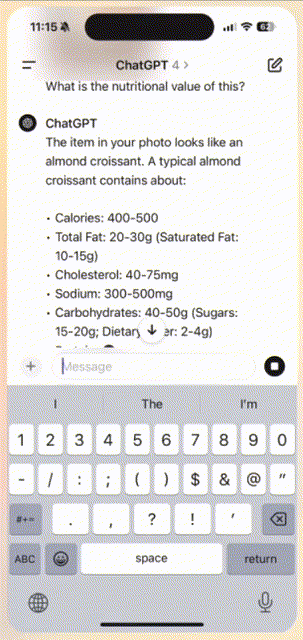
比如,你拍一张照片发给ChatGPT,然后问「这个食物的营养价值是什么」?
ChatGPT瞬间做出响应,解释了牛角包的营养价值。
免费用户还可以体验到联网搜索的快乐。(当然是最新最强模型)
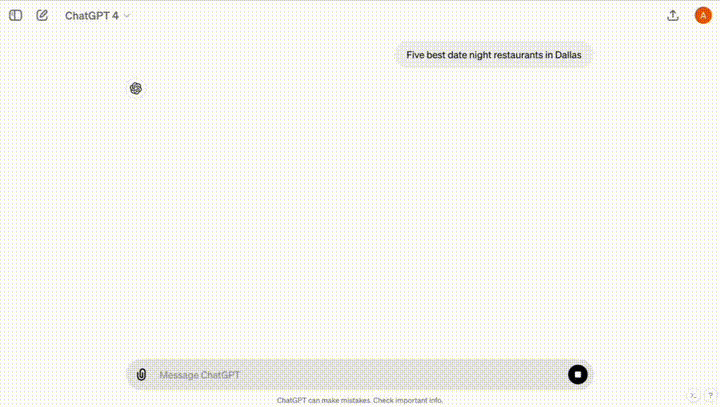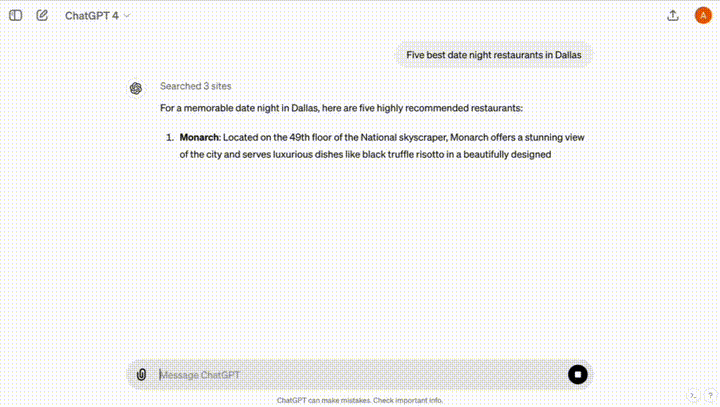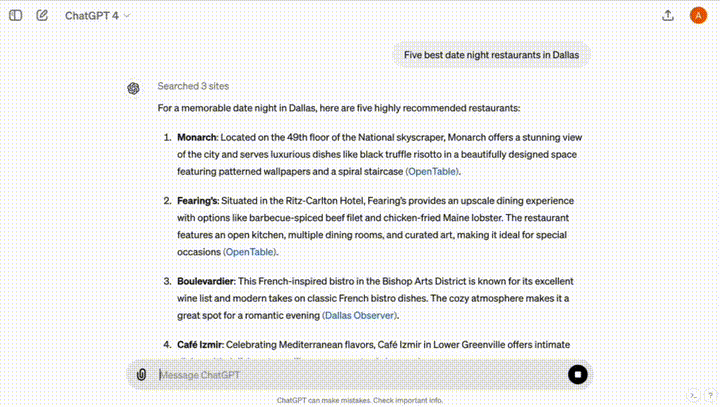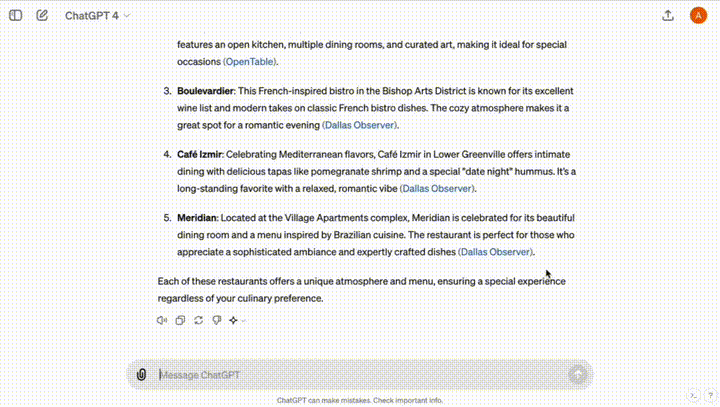
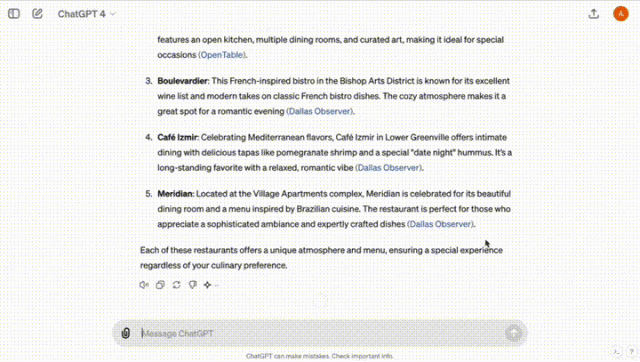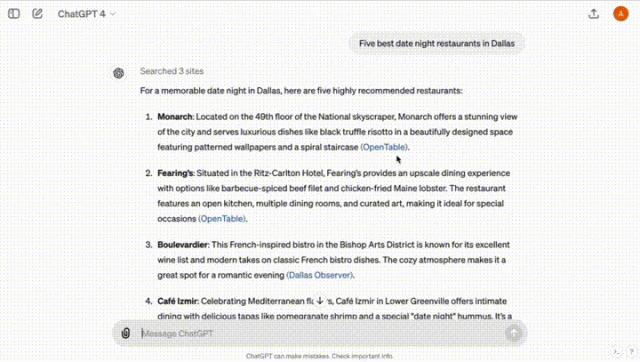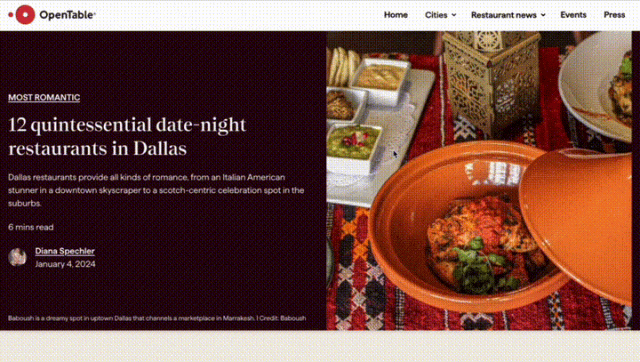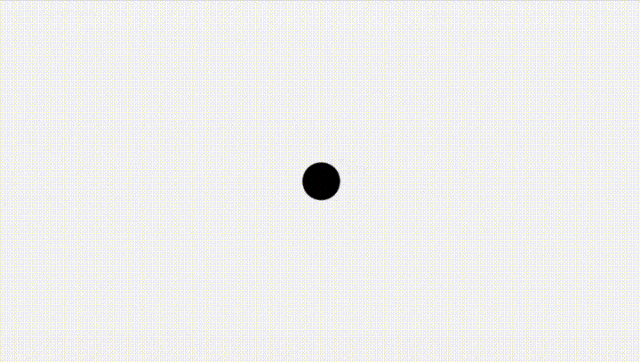
「帮我推荐达拉斯5个适合夜晚约会的餐厅」。
ChatGPT通过搜索3个网站,立即总结出了你想要的结果。
另外,免费福利还包括,在GPT商店中使用模型。

4. API速度飙升2倍,再打骨折
此外,让开发者兴奋的是,GPT-4o不仅应用在ChatGPT服务中,模型的API也被同步放出,可以部署各种下游应用程序上。
同时,API的性能也有所改进,据说相比GPT-4 Turbo,推理速度提升2倍,消息限制提高五倍,而且价格还会降低50%。

OpenAI开发者在线呼吁,赶快来体验。

三、ChatGPT桌面版也来了
正如Murati一出场开宗明义的:对OpenAI来说,打造一款真正让所有人可用的产品,非常之重要。
为了让每个人无论身在何处,都能随时用上ChatGPT,OpenAI发布了ChatGPT的桌面版本。
它拥有桌面应用程序,和全新的用户界面,可以很轻易地和我们的工作流融为一体。

桌面版ChatGPT APP
只需一个简单的快捷键——Option+空格键,就可以立即召唤桌面版ChatGPT。
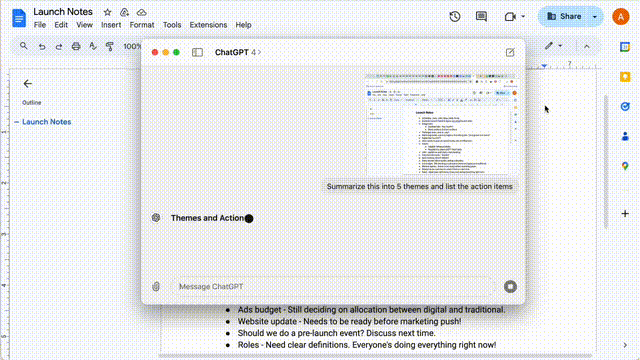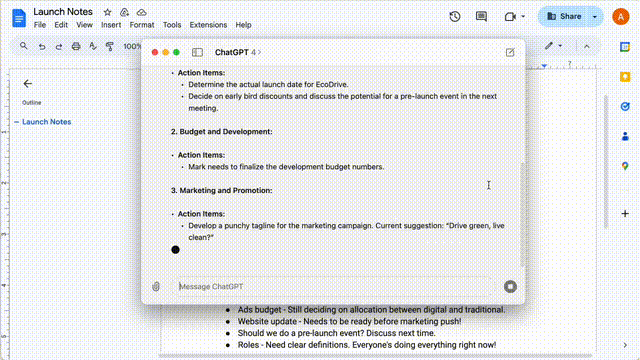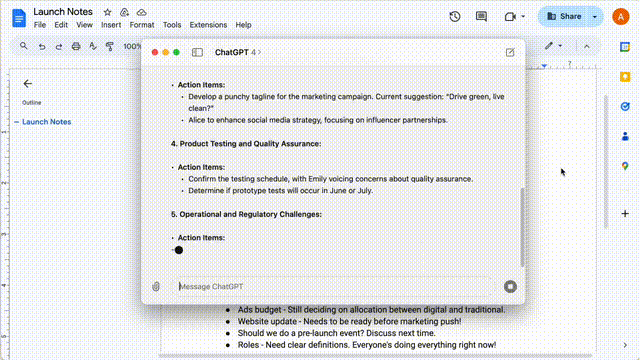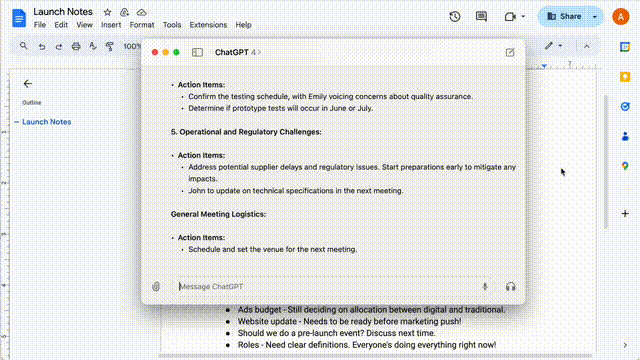
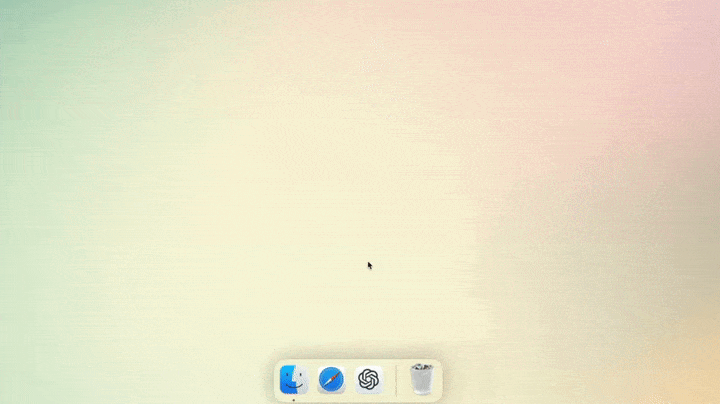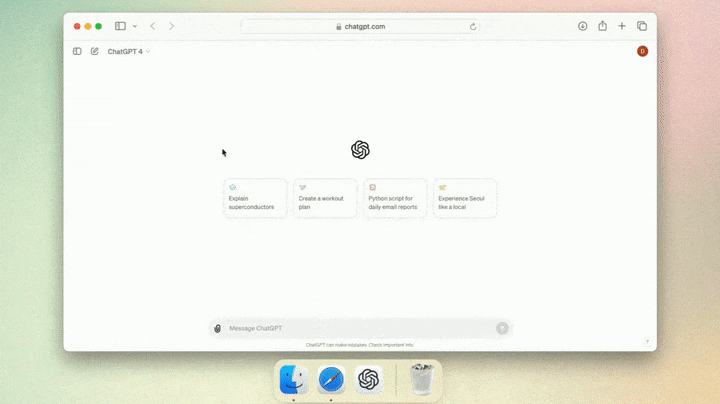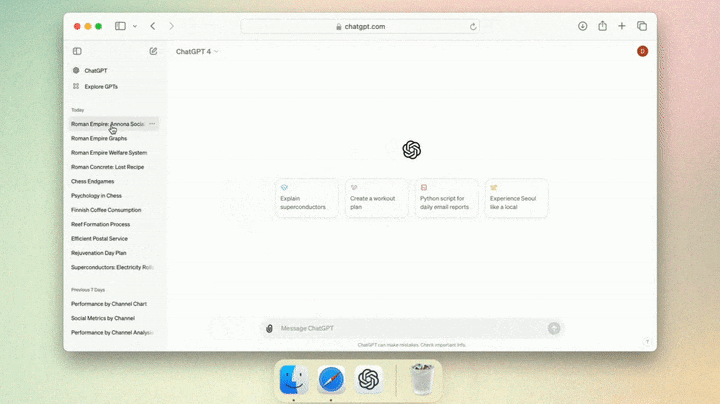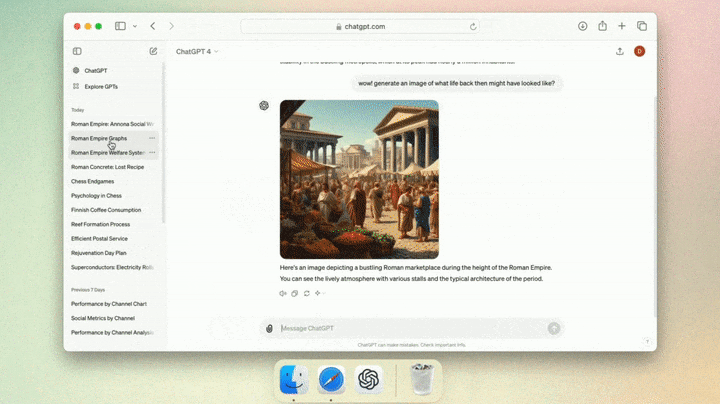
甚至,你也可以直接在应用程序中截图,并进行提问。

然后,让其帮你总结所截取的网页内容——「将其总结成5个主题,并列出行动计划」。

接下来,ChatGPT一通炫技,嗖嗖嗖地解决了提出的问题。
你甚至,可以从你的电脑上直接与ChatGPT进行语音对话,点击桌面应用程序右下角的耳机图标,便可开始。
同时,OpenAI还全面改版了UI界面,让它和用户的互动也变得更自然,更简单了。
四、神秘gpt2就是GPT-4o!
「这么厉害的GPT-4o,早已是你们的老熟人了」,ChatGPT官方账号在线卖起关子。

这,究竟是怎么回事?
几天前,大模型LMSYS竞技场上,一个名为gpt2神秘模型突然现身,其性能甚至超越了GPT-4。
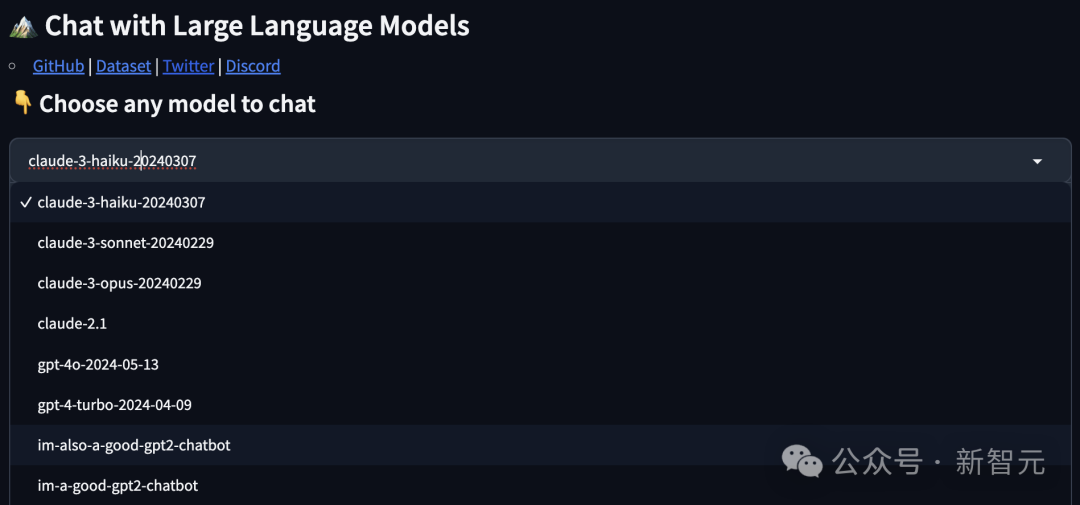
注:最初以gpt2命名,现在升级为两个版本「im-also-a-good-gpt2-chatbot」和「im-a-good-gpt2-chatbot」
全网纷纷猜测,这个模型,可能就是GPT-4.5/GPT-5。
就连Altman本人多次发贴,暗示gpt2的强大能力——

如今,gpt2的身份,真的解密了。
OpenAI研究科学家William Fedus刚刚发文, 一直在测试的版本「im-also-a-good-gpt2-chatbot」就是GPT-4o。

以下是它一直以来的表现。
im-also-a-good-gpt2-chatbot总ELO得分,超过了最新的gpt4-turbo-2024-04-09。
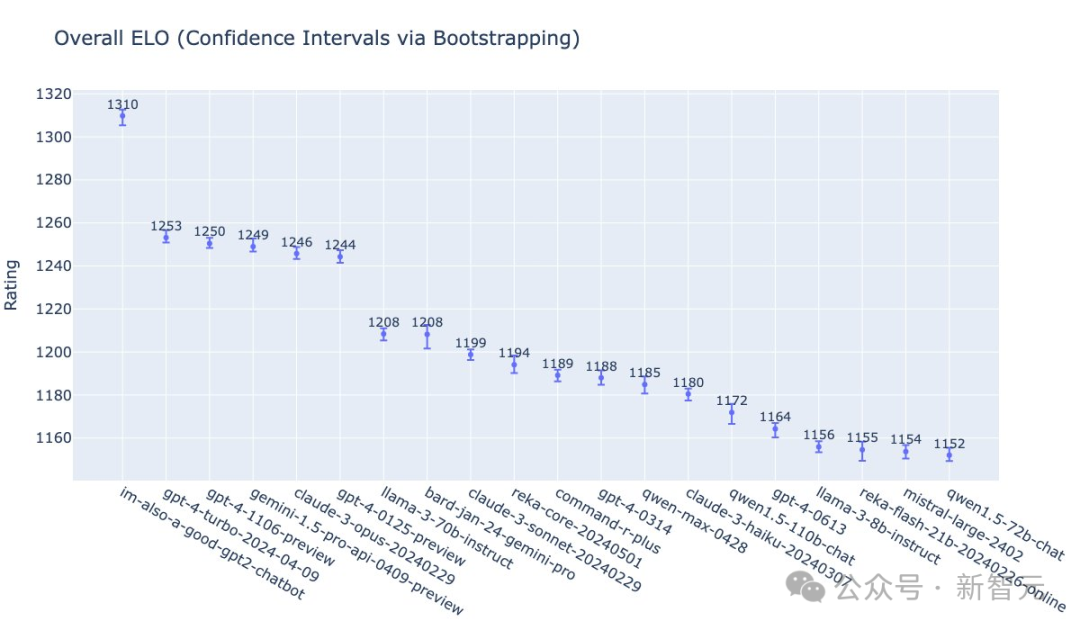
但ELO最终得分,会受到「提示」难度的限制(即无法在类似「你好吗」这种简单提示上取得任意高的胜率)。
OpenAI团队发现,在更难的提示集合上——尤其是编程方面——存在更大的差距:
而GPT-4o在我们此前的最佳模型上,ELO甚至可以提高100分。

最关键的是,GPT-4o不仅是全世界最好的模型,甚至可以在ChatGPT中免费用。

另一边,LMSYS发布了最新的gpt2-chatbots结果,已经跃升至大模型竞技场榜首!


奥特曼对此大赞,「令人惊叹的工作」!

OpenAI联创Greg Brockman表示,「初步的指标看起来很有前景」。

接下来,就看明天谷歌I/O大会上的表现了。
参考资料:
https://twitter.com/gdb/status/1790071008499544518
https://openai.com/index/hello-gpt-4o/
https://openai.com/index/gpt-4o-and-more-tools-to-chatgpt-free/