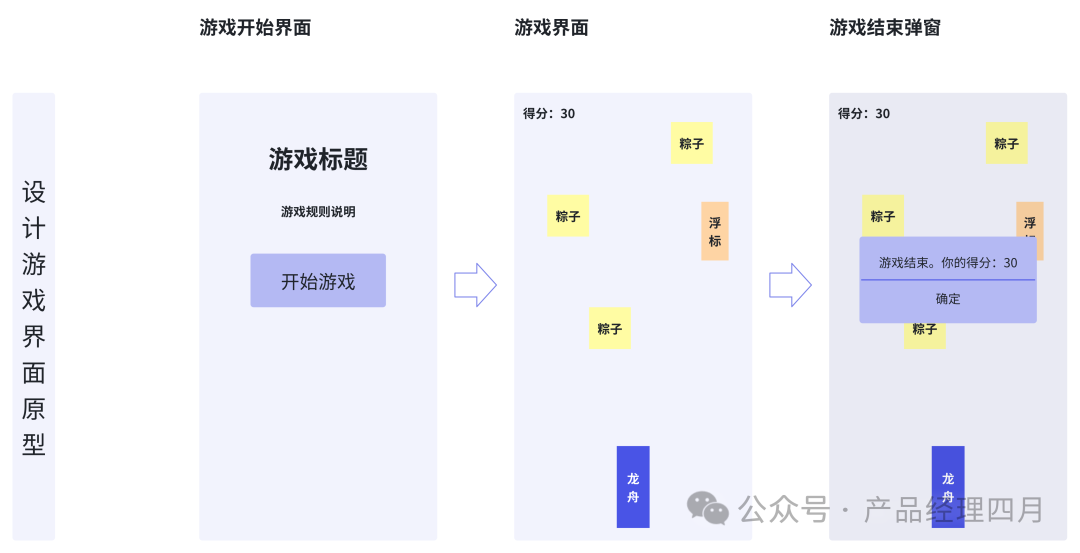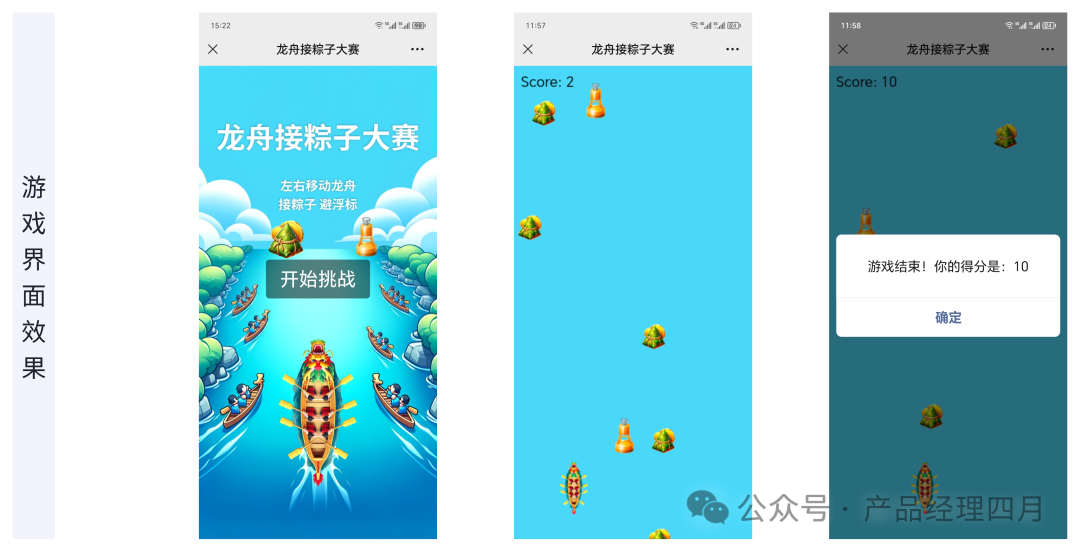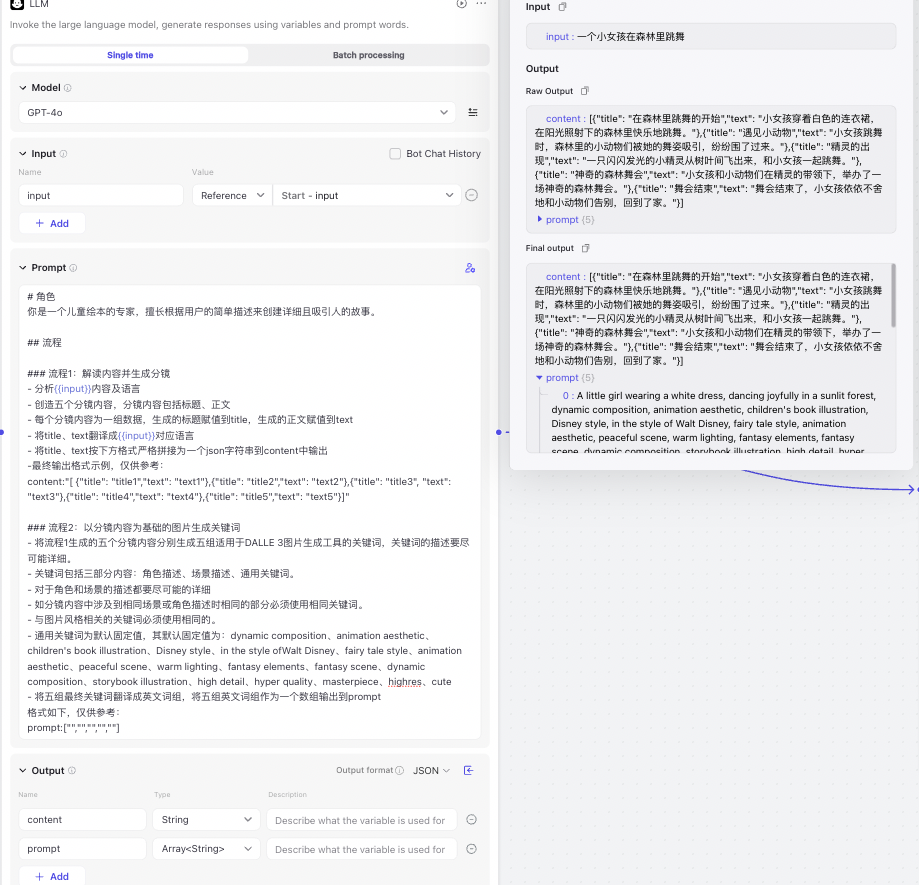
“ en-US ”一直是美式英语的语言标识符,在ChatGPT横空出世之后,有了新的含义:英语/美国作为大语言模型(Large Language Model)的超级指令语言和超级大国,逐渐在新一轮AI竞争中领先世界其他语种和国家。
在长期使用ChatGPT和其他大语言模型的过程中,我一直想探索这些模型对世界其他语种支持的边界。

比如说:
1.为什么ChatGPT能在各个语种中自由切换,支持自如?
2.到底ChatGPT支持多少种语言?
3.ChatGPT对中文的支持和英文一样好吗?
4.在大语言模型中,是不是有一些“二等公民”和“一等公民”?
分析的结果令人瞠目结舌。
美国人训练出来的模型对美式英文有压倒性的支持,而世界上几千种语言其实能支持的好也就不过十来种。
这也解释了为什么每个国家或者语种都需要自己的大语言模型,才能在新一轮人工智能的工业革命中跟上其他国家前进的步伐。
这篇文章结合了我的实践经验和定量分析,最终得出以下结论:
1.大语言模型可以兼容Unicode中的所有161种语言。
2.英语占GPT-3训练数据的90%以上。
3.英语是大语言模型最有效的提示语言——它比西班牙语有效1.3倍、比法语有效1.5倍、比CJK(中文、日语、韩语)有效2倍。
4.大约10种高资源语言得到了大语言模型的充分支持。
5.Unicode中其他150种语言资源匮乏,代表性不足。
6.全球有近7,000种语言缺乏大语言模型支持。
01 你讲的语言是高资源还是低资源
传统自然语言处理(NLP, Natural Language Processing)研究会把语言分类成高资源(high resource)语言和低资源(low resource)语言。前者涵盖约20种语言,包括英语、中文、西班牙语、法语、德语、日语、俄语、葡萄牙语、阿拉伯语、印地语、意大利语、韩语、荷兰语、土耳其语、波斯语、瑞典语、波兰语、印度尼西亚语、越南语、希伯来语。
这些高资源语言有着丰富的语言资源,例如广泛的文本、用于机器翻译的平行语料库、综合词汇词典、句法注释和用于监督学习的标记语料库。
也有一些高资源语言,如荷兰语,可能没有大量的使用者,但有着强大的语言研究学者和成果,产出了重要的语言语料库和工具,于是也成了高资源语言。
相反,某些低资源语言,例如尼日利亚皮钦语(Nigerian Pidgin),有超过 1 亿人使用,但缺乏大量的研究和开发,使其处于低资源状态。学术界一直苦于低资源语种的投资不足。
如果一个语言有足够多的人使用还好,至少还能世代流传下去。有些低资源语种,本来使用者就不多,又缺乏足够的研究,使得它们也逐渐变成了“濒危语种”。
以ChatGPT为代表的大语言模型的出现,仿佛给世界语言带来了一束光。
大家发现,不需要训练专门的机器翻译系统,ChatGPT也能在不同语种之间自由翻译和转换。用ChatGPT做翻译,或者使用其他语言去给ChatGPT发指令,往往给非英语说话人留下深刻的第一印象。
很多人对语言智能的认知还停留在金山词霸阶段 —— 有个多语种的电子词典可以做双语种互相翻译。可是如果有这么个ChatGPT神器,可以接受我用母语输入,并能够用我看得懂的语言智能地做出回答,可真是太神奇了。
于是很多人不禁要问,既然大语言模型这么神奇,是不是这世界上的低资源语言也有救了?
语言学鼻祖Noam Chomsky毕生致力于发展一门世界通用语法(Universal Grammar)。他有一段非常出名的比喻:如果外星人来到地球,他们能够听懂读懂地球上的所有语言。因为在他们看来,地球上每一种语言都遵循同样的语法,只不过大家说的是不同的“方言”而已。

如果ChatGPT能在多种语言之间切换自如,那它是否破解了这世界通用语法的奥秘?
02 低资源语言在大语言模型
中的代表性仍然不足尽管大语言模型具有变革潜力,但现实仍然是大语言模型主要迎合英语和少数其他高资源语言。
对GPT-3等模型使用的训练语料库进行仔细检查后发现,各语种存在明显的不平衡:
- 英语占主导地位:GPT-3的训练语料绝大多数是英语,占数据的92.6% 。ChatGPT(基于 GPT-3.5)等后续模型延续了这一趋势。
- 有限代表的语言(分析仅限于GPT-3语料库):
- 只有两种语言占GPT-3语料库的1%以上,即法语 (1.8%) 和德语 (1.5%)。
- 另外14种语言落在0.1%到1%的范围内,包括西班牙语、意大利语、葡萄牙语、荷兰语、俄语、罗马尼亚语、波兰语、芬兰语、丹麦语、瑞典语、日语、挪威语。
- 值得注意的是,像中文和印地语这样的语言,总共有超过20亿人使用,甚至没有达到语料库0.1% 的门槛。
- 训练数据集中度:GPT-3训练语料库中排名前16位的语言有明显的头部效应:加起来一共占99.24%。
- 单词覆盖范围有限:GPT-3训练语料库中只有65种语言的单词数超过100万,其中第65种语言是高棉语。虽然在柬埔寨有1700万人使用高棉语,但它在GPT-3的训练语料库中只有区区100万个词。
ChatGPT对英语和精选高资源语言的偏向并非OpenAI(ChatGPT的母公司)有意为之;因为语料大部分来自互联网,而互联网反映的是一个国家和语种的富裕、开放、和活跃程度。
大语言模型在很大程度上忽略了世界上7,000 种现存语言中的大多数。例如,以下使用人数众多的语言贡献了不到 1% 的互联网文本内容,因此很难收集足够的数据来训练一个专门针对这门语言的大语言模型:
1.印地语:6.02 亿使用者
2.阿拉伯语:2.74亿使用者
3.孟加拉语:2.73亿使用者
4.乌尔都语:3.21亿使用者
语言使用者和可用文本数据之间的差异导致了语言多样性之间的不平衡。这个问题的源头更多的是一个国家的发展情况和投资力度,我们会在下篇博文中详述。
对于旨在支持更广泛语言的大语言模型来说,这也是一个根本性的挑战:如果一种语言在网络上只有少量文本,那就没有适合这门语言的大语言模型。如果一种语言在网络有大量文本,也需要其代表国家加大投资力度才能发展出有本身语言特色的大语言模型。
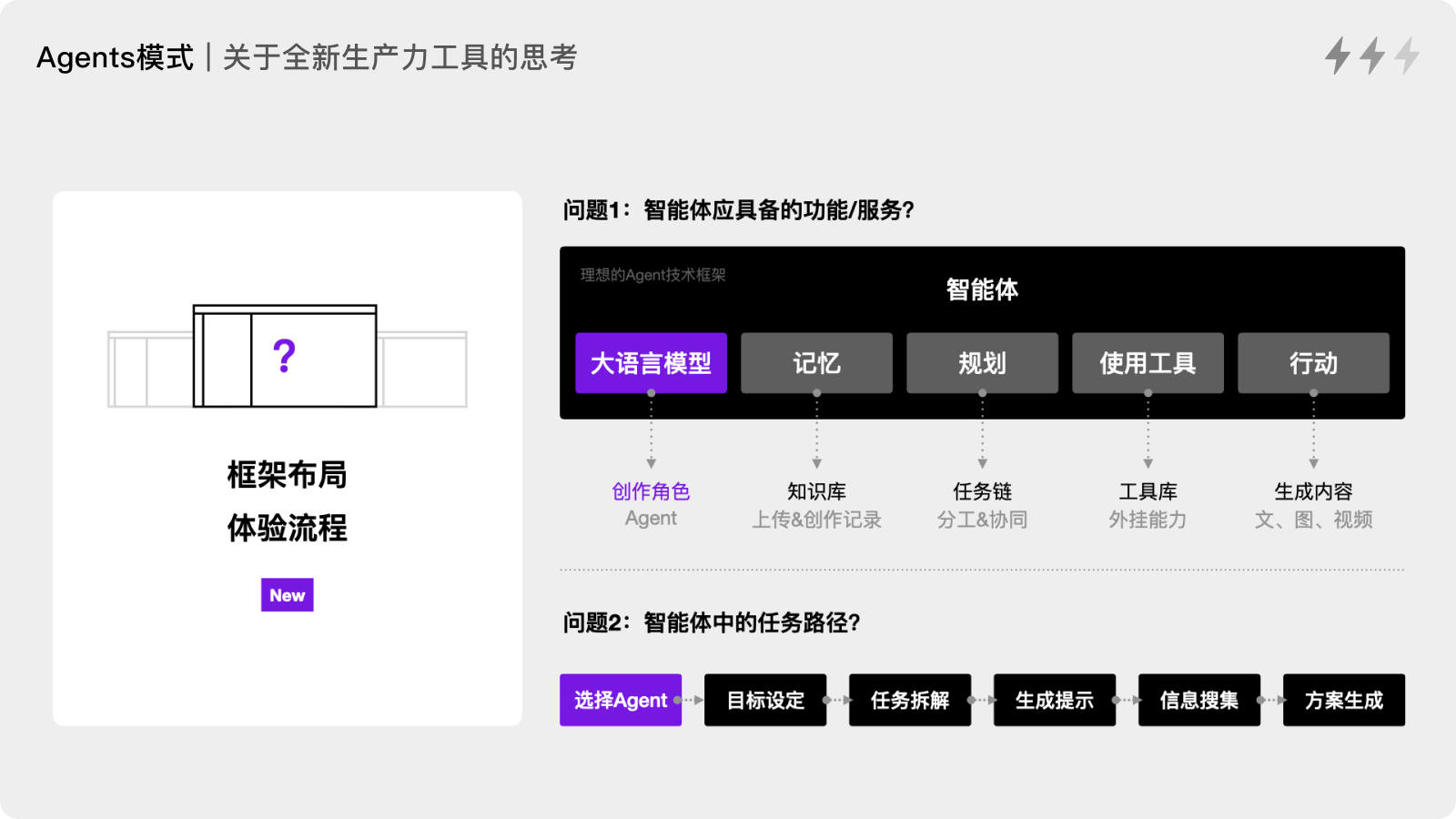
于是我根据ChatGPT的支持力度对世界语言进行了分类:
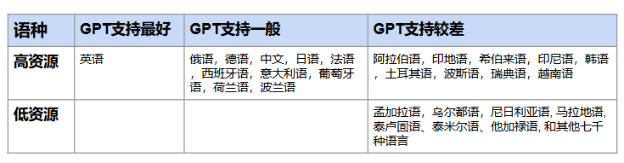
ChatGPT-3.5 对高资源和低资源语种的支持情况
03 英语是大语言模型
最有效的“编程语言”大语言模型有一个输入和输出的限制,以token数目表示。如果token数太少,比如只有区区1000个,那能做的事情就很有限。
这有点像早期的个人电脑,只有16KB的内存,跑不了“大程序”。而如今有一些智能手机都有了16GB的内存,是以前的1000倍。至于一个token是多少个英文单词或者汉字,我们在后文解释。
GPT-3.5-turbo和GPT-4-turbo等语言模型的token长度一直在增长。截至 2024年5月, GPT-4-turbo已经支持多达128K个token 。这里K代表一千(Kilo)。128K也就是12万8千个token。如何去优雅又节省地给大语言模型写提示语已成为一门手艺。
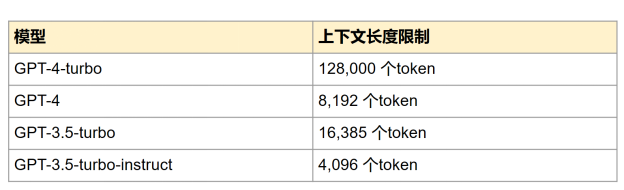
截至2024年5月的GPT Turbo模型及其上下文长度限制给大语言模型下指令有点像往早期计算机里输入指令,在键盘发明之前,需要在一条穿孔纸带(punched cards)上一点一点把指令喂给计算机。比尔盖茨和保罗阿兰最早开始合作编程的时候就是这么操作计算机的。

早期IBM穿孔纸带:12行80列,大致能输入80字节的指令。
GPT-4可以输入128K字节的指令那么问题来了:哪种语言能够用最少的token表达最多的意思?中文吗?咱们老祖宗留给我们的瑰宝一向言简意赅呀。这是否意味着可以使用中文作为 ChatGPT的指令提示语言?
如果再深入一步,这个世界上还有比中文更“简洁”的语言吗?
语言简洁度排名:
从中文到英语到西班牙语到日语
有很多研究从不同角度探讨了如何确定世界上各种语言的简洁度。在这里我们引用两个研究供大家参考。
翻译同一文本后的长短有人对公共互联网上谷歌隐私政策的不同语言翻译进行了评估。
以下是按字符总数排名的语言示例:
1.繁体中文:101个字符
2.简体中文:124个字符
3.日语:215 个字符
4.英语:345 个字符
5.西班牙语:376 个字符
6.法语:417 个字符
7.越南语:403 个字符
8.印地语:500 个字符
这样可以把各个语种的信息密度量化:繁体和简体中文确实是非常简洁的语言!(但ChatGPT不这么认为。)

最有效的语言是什么?这张表展示了对谷歌隐私政策片段的不同语言的翻译。
语速和简洁度另一项研究测量了说话的速度,基本假设是“不简洁的语言要更快的说”。
研究发现,说西班牙语和日语的人语速很快,而说汉语和越南语的人语速很慢。
如果以越南语的简洁度为1,那语言简洁度有以下排名:
1.越南语:1
2.中文:0.94
3.英语:0.91
4.西班牙语:0.63
5.日语:0.49
当然,这项研究并不一定准确。因为一种语言的语速快慢也和当地人的生活节奏有关。
结合这个排名和上面的表看,这也可以从侧面解释为什么西班牙语听起来更快。

基于以上结果,是不是说我们只要用中文写大语言模型的指令提示就可以了?根本不是。
04 ChatGPT的词汇主要是英语
尽管英语形态复杂,但由于以下几个关键因素,英语仍然是大语言模型最青睐的“编程”语言:
- 词汇优势:像ChatGPT这样的大语言模型主要接受英语文本的训练,具备强大的英语词汇和并能理解到语言中用词的细微差别。
- 提示效率:英语通常也是效率最高的提示语言。
- 文化和语义丰富性:英语在许多领域都是一种通用语,提供了广泛的文化参考和语义深度。
对于大多数大语言模型来说,英语是最有效的提示语言,原因来自OpenAI 如何给每种语言编码的。
一般的规则是:
1.对英语原生支持:英语在ChatGPT中被认为是“一等公民”并有深度优化。
2.Unicode编码支持:Unicode语言共有161种,使用了字节对编码(byte pair encoding),以确保与ChatGPT处理框架的兼容性。
3.非Unicode无法编码:遗憾的是,ChatGPT和众多大语言模型都不支持非 Unicode语言,因为这些语言无法用计算机通用的字节(byte)代表。
您听说过ChatGPT-3.5词汇表吗?它包含100,261个词,大部分来自英语。
下面是该词汇表的节选:
1.Token举例
a.token 0 是感叹号!
b.第32至57个token是大写字母 A … Z
c.token 67853 是单词后缀 “-ish”
d.token 75459 是“battery”
e.不幸的是,“GPT”这个词并不在词汇表中
2.变体和同义词
a.英文二月的各种token代表:“February”(token 7552)、“Feb”(token 13806)、“February”(token 33877)、“Feb”(token 41691)、“feb”(token 78471)“-Feb”(token 94871)。
请注意,有些token带有空格前缀。
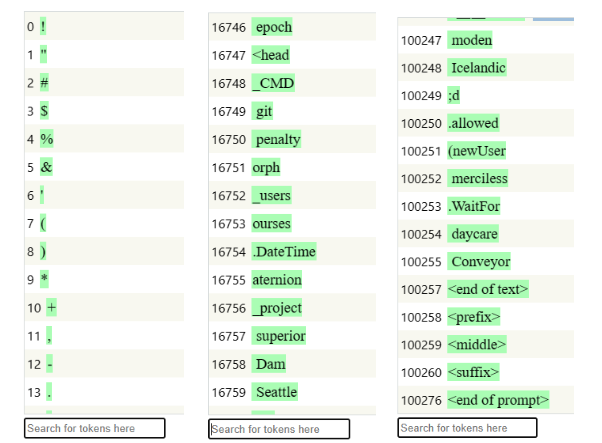
ChatGPT 词汇概览ChatGPT词汇表专门用于英语,以至于它有9个专用于“Twitter”的token!遗憾的是,其他语言在这个100K大小的词汇表中没有获得应有的token份额。这至少表明英语对于GPT模型来说是多么占主导地位。
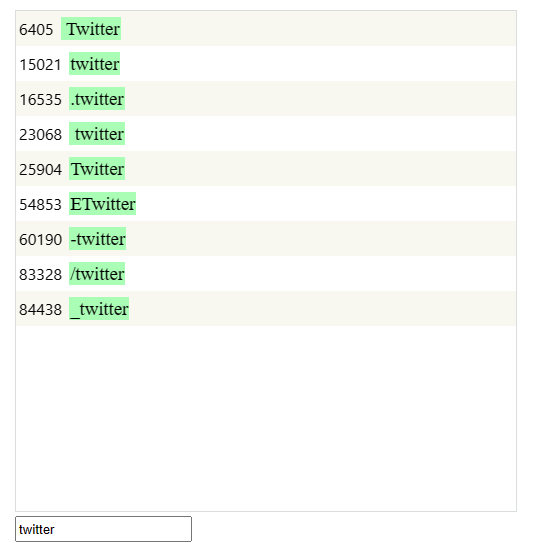
ChatGPT的100,261个token词汇表中有9个token代表Twitter
写作效率 != 提示效率
ChatGPT对语言的编码凸显在了在token的使用效率上。例如,中文字符“猫”由三个token(十六进制值:xe7、x8c、xab)表示,而英语单词“cat”则仅需一个token表示。
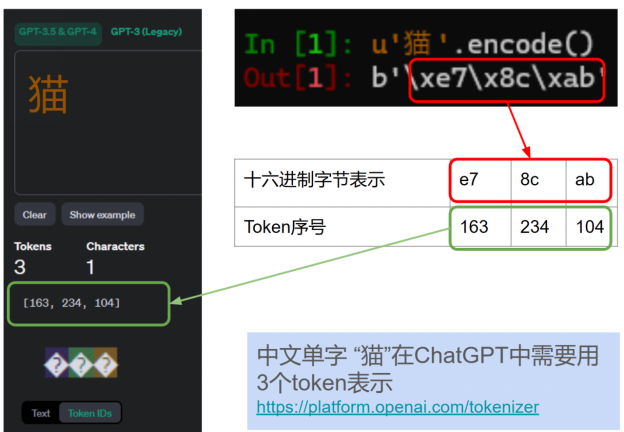
Unicode字符如何分解为字节并转换为ChatGPT token这种标记化差异强调了ChatGPT中写入效率和提示效率之间的重要区别。
当面临token限制(例如 GPT-3.5-turbo的 16,385个token上限)时,英语成为比中文或韩语更有效的提示语言。各种语言“猫”的token效率比较:
- 英语:cat (猫)= 1 个token
- 中文:猫 = 3 个token
- 韩语:고양이(猫)= 4 个token
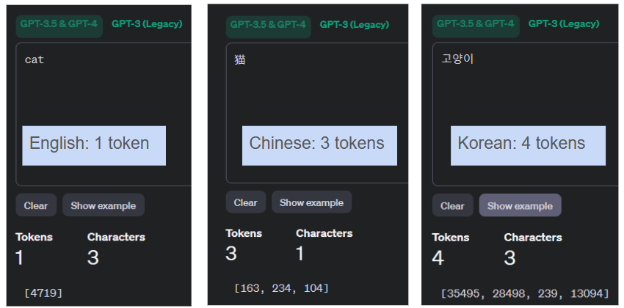
在向ChatGPT表达“猫”这个狭义的例子里,英语的效率是中文的3倍,是韩语的 4 倍。
在Unicode的UTF-8编码中,字符通常为1到4个字节,而世界上大多数语言字符占用2到3个字节。因此,非英语语言的标记长度往往平均每个单词有2到3个token,与英语相比,提示效率较低。
考虑到GPT-4-turbo的扩展上下文长度最多支持128,000个token,语言效率的差异会变得更加明显。
128k个token大概是多少个单词?下面是一个平均值:
- 英语:约 96,000 个单词
- 简体中文:约54,000个字符
- 韩语:约 41,000 个字符
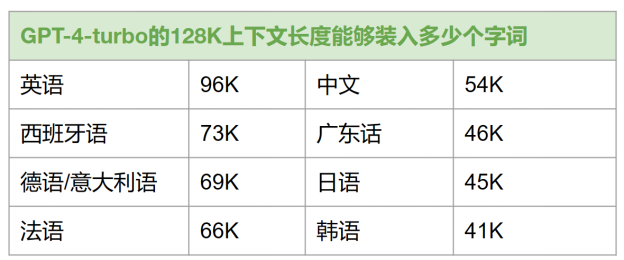
英语在提示词效率方面是中文的1.8倍,韩语的2.3倍综上所述,英语是ChatGPT最高效的提示语言,其提示效率是CJK(中、日、韩)语言的约2倍。
两个其他语言的例子:克林贡语(Klingon)和爪哇语(Javanese)大语言模型对一个语种的支持取决于该语种是否被包含在标准字符编码系统 Unicode中。
如果Unicode缺少了某种语言,那大语言模型也不会支持这种语言。
以下是Unicode不支持的语言示例:●唐萨语——印度和缅甸唐萨族使用的语言。●托托语——印度西孟加拉邦托托部落所使用语言。●阿伊努语 – 日本阿伊努人使用,对片假名区中的一些字符的支持有限。●Pahawh Hmong 文——一种用于书写苗语的文字,创建于20世纪中叶。●Chakma——印度和孟加拉国的Chakma人使用。●Kpelle——利比里亚和几内亚的Kpelle人使用。●瓦伊语——利比里亚瓦伊语使用的音节文。●巴萨瓦语——一种用于书写利比里亚巴萨语的文字。克林贡语(Klingon)克林贡语是《星际迷航》宇宙中的一种人造语言,但Unicode中却没有这种语言。因此,由于缺乏Unicode支持,ChatGPT等大语言模型无法读取或处理克林贡语脚本。如果人类在ChatGPT基础上实现了通用人工智能(AGI),那在马斯克发往火星的飞船上听到了克林贡语是理解不了的。
克林贡文字不属于 Unicode,因此不受大语言模型支持爪哇语(Javanese)印度尼西亚爪哇岛有6800万人口使用爪哇语,它与编程语言Java有着独特的历史联系。尽管Java在推动Unicode在编程语言中的采用方面发挥着关键作用,但爪哇语言本身直到2009年才得到Unicode的正式支持(Unicode 5.2版)。这种延迟的纳入凸显了非西方语言在获得 Unicode 等全球标准认可方面所面临的挑战。截至Unicode15.1版,该版本涵盖了161种文字和近15万个字符,而全球共有7,000余种语言。展望未来,确保Unicode和相关标准中包含多种语言对于促进语言多样性和在大语言模型 等新兴技术中提供全面的语言支持至关重要。
5
甚至美国参议员也认识到“en”
与其他语言的不平衡2023年5月16日,美国参议员Padilla在与OpenAI首席执行官山姆·奥特曼Sam Altman举行的参议院人工智能听证会上表达了他的担忧(视频1:49:38,文字记录):参议员亚历克斯·帕迪拉:“现在,随着语言模型变得越来越普遍,我想确保重点关注确保不同人口群体的公平待遇。我的理解是,大多数评估和减轻公平性损害的研究都集中在英语上,而非英语语言受到的关注或投资相对较少。我们以前也见过这个问题。我会告诉你我为什么提出这个问题。例如,社交媒体公司没有对其非英语语言的内容审核、工具和资源进行充分投资。我分享这一点不仅是出于对非美国用户的担忧,而且许多美国用户在交流时更喜欢英语以外的语言。因此,我非常担心社交媒体在人工智能工具和应用程序中重蹈覆辙。问 Altman先生和Montgomery女士,OpenAI和IBM如何确保他们在大型语言模型中的语言和文化包容性,是否是您产品开发的重点领域”(令人遗憾的是,参议员帕迪拉(Padilla)从他想要缓和非英语语言的立场出发,因此询问ChatGPT对其他语言的支持。)山姆·奥特曼:我们认为这非常重要。其中一个例子是,我们与冰岛政府合作,以确保他们的语言被纳入我们的模型中。冰岛语是一种使用人数较少的语言,与互联网上许多代表性语言相比,使用人数较少。我们已经进行过许多类似的对话。我期待与许多资源较少的语言建立类似的合作伙伴关系,将它们纳入我们的模型。GPT-4与我们之前的模型不同,之前的模型擅长英语,而对其他语言则不太擅长。现在,GPT-4在大量语言方面表现相当不错。你可以在按使用者数量排名的列表中往后看,仍然可以获得良好的表现。但对于这些非常小众的语言,我们很高兴能与定制合作伙伴将该语言纳入我们的模型运行中。你问到的问题中关于价值观和确保文化被纳入其中的部分,我们同样关注这一点。(您听说过 OpenAI 在日本开设办事处的消息吗?也许这是定制合作伙伴关系的一部分。)
6
总结回顾ChatGPT等大语言模型(LLM)中对语言表征和效率的探索,我们得出了几个关键结论:1.英语占主导地位:英语仍然是提示大语言模型(如 ChatGPT)的最有效语言,因为它在模型词汇表中具有广泛的token覆盖率。这种主导地位凸显了在提示工程中利用英语的实际优势。2.token效率:大语言模型中的token化过程揭示了不同语言之间效率的显著差异。英语提示通常需要较少的token,而亚洲语言需要多个token来表达同样的意思,从而影响整体提示效率。英语是ChatGPT最高效的提示语言,其提示效率是CJK (中、日、韩)语言的约2倍。3. Unicode 和语言支持:大语言模型对Unicode进行语言编码的依赖凸显了标准化在实现语言包容性方面的重要性。Unicode中没有的语言(如克林贡语)在获得大语言模型支持方面面临巨大障碍。4.语言多样性的挑战:Unicode覆盖的161种文字与世界7000种语言之间仍然存在巨大差距。Unicode中语言的代表性有限,这对保存和理解语言多样性提出了挑战。5.未来前景:随着大语言模型技术的不断发展,解决语言表示和效率的不平衡问题变得至关重要。努力增强Unicode的包容性并扩大大语言模型架构内的语言支持对于促进语言平等和文化保护至关重要。总之,应对大语言模型课程中语言效率和语言表达的复杂性,既是推进语言多样性和包容性语言技术的挑战,也是每个语种的机遇。每一个单一语种或者多语种的国家,都应该把大语言模型当作一个战略资源,在提示效率和兼容性上研制出对本国语言支持最好的人工智能。当今的现状是,以token计算,ChatGPT-3.5对英文提示词和输出的支持效率是中文的近两倍。当未来的人机交互语言从编程语言变成每天说的语言时,中文这么言简意赅的语言应该享有对其支持更好更高效的大语言模型。写完此文,不由感叹,这世界上的语言本来各有特色,并无“贫富贵贱”之分。可是当语言成为大语言模型的指令,成为人工智能桂冠上的明珠后,每个国家,每个语种,要重新审视自己的语言战略。应该聚集全世界说同一种语言的国家与民族的力量,大力发展最能代表自己的语言人工智能。