OpenAI,忽然深夜放大招了——
今天半夜,OpenAI宣布推出名为Search GPT的AI搜索引擎,正式狙击搜索霸主谷歌。
据《金融时报》称,OpenAI已准备好攻进谷歌1750亿美元的搜索业务市场。

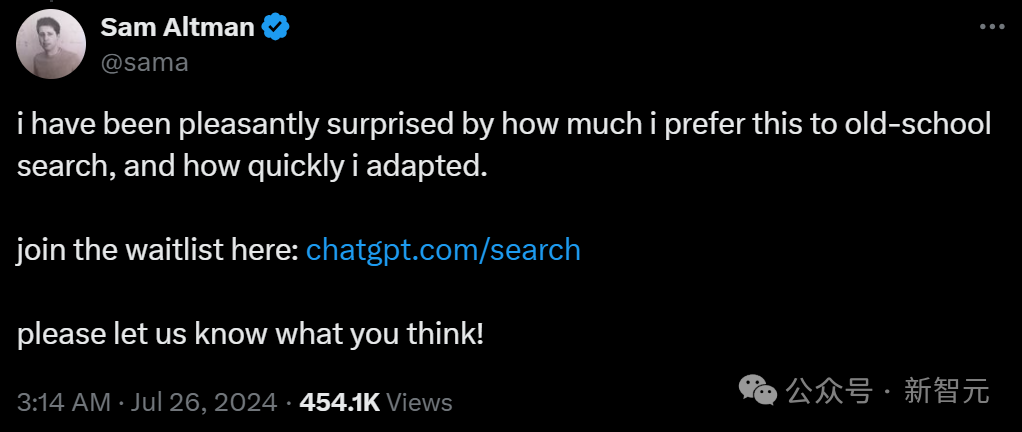
奥特曼在X上官宣此消息,大胆直言:「当今的搜索功能还有改进空间」!

没等来GPT-4o的语音功能,但ChatGPT的更新先来了。
尝试过SearchGPT的奥特曼,对于自己的全新搜索非常满意,表示跟老式搜索相比,自己更喜欢这种方式。
甚至「我适应得如此之快,这让我感到震惊!」
更暴击的是,SearchGPT的优质功能还将集成到ChatGPT中。目前SearchGPT还未开放公测,仅有1万名用户被邀请,其余想加入内测的用户,还得在官网手动申请。

申请地址:https://chatgpt.com/search
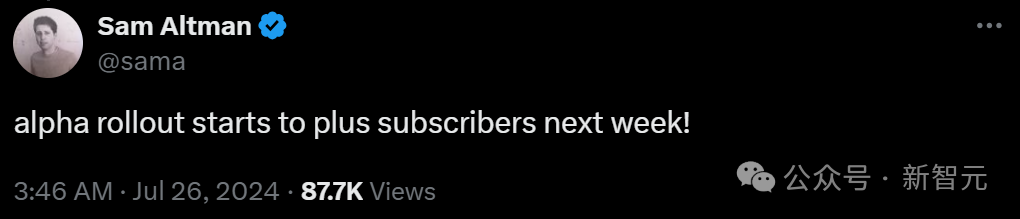
好消息是,根据奥特曼的说法,alpha测试将于下周开始开放给付费用户。
网友直言,SearchGPT对Perplexity、谷歌、必应都是迎头重击,让游戏开始吧!

SearchGPT对Perplexity、谷歌、必应是一个重大打击,直接与它们的搜索服务竞争。
凭借其实时获取信息和与主要新闻机构的合作伙伴关系,SearchGPT准备颠覆搜索引擎市场

一、颠覆搜索,看来是真的
从官方放出的预览demo来看,似乎不仅仅是集成了实时网络信息,应该也包括类似于「多步推理」的功能。问:我周末何时能在半月湾看到裸腮类动物?对于包含如此具体时空细节的提问,谷歌是完全束手无策,给出的模糊答案看了就头疼。
SearchGPT则不跟你玩虚的,简单明快打直球,给出准确的时间点——
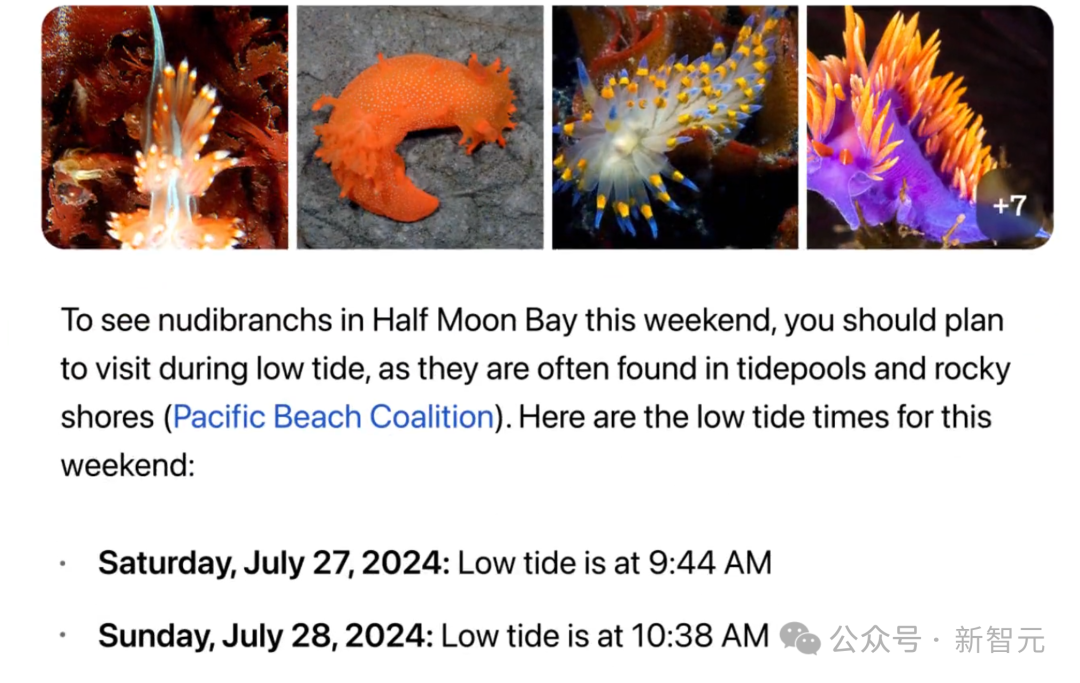
并且解释道,这类动物经常出现在潮间带和岸边岩石上,你应该在退潮时段去。
预测潮汐网站的参考链接,也贴心地附了出来。
更多的细节问题,也可以随口问它,比如那里天气如何?这周末半月湾的天气预测,就会一一给出。

同样的问题,Perplexity倒是给出了一系列相关小tips,但对于核心问题,它并没有给出有力的答案,只是含糊地推荐「退潮期」。
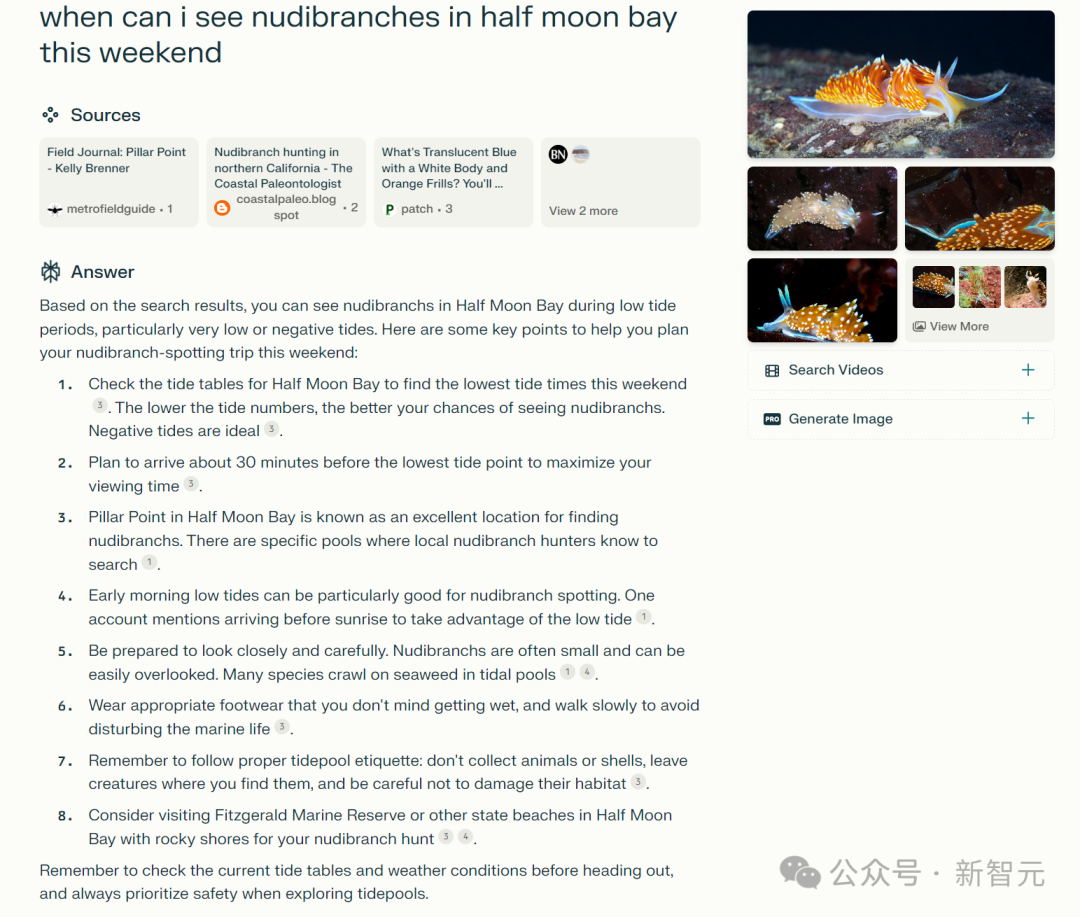
这一轮对决,谷歌和Perplexity是妥妥输了。
二、实时响应,多轮对话,取代搜索引擎
SearchGPT和谷歌搜索的体验,为何差距如此之大?OpenAI发言人Kayla Wood表示,目前SearchGPT的服务由GPT-4系列模型驱动, 采用类似ChatGPT的对话式界面和工作方式。
按照传统的搜索方式,用户在网络上检索时,往往需要多次搜索不同关键词,费时费力。
而SearchGPT颠覆了传统的搜索模式,只需像真人对话一样,表达自己的搜索诉求,即可获得实时响应,而且支持多轮对话。
以实时信息为基础,借助AI的理解推理和总结能力,找到想要的内容so easy。
跟传统搜索相比,SearchGPT的优化主要体现在两个方面:
其一,搜索结果更快速准确,充分发挥LLM的文本能力。
显然,对比基于关键词搜索的传统搜索引擎,AI搜索在理解问题和汇总信息方面有着显著的优势。
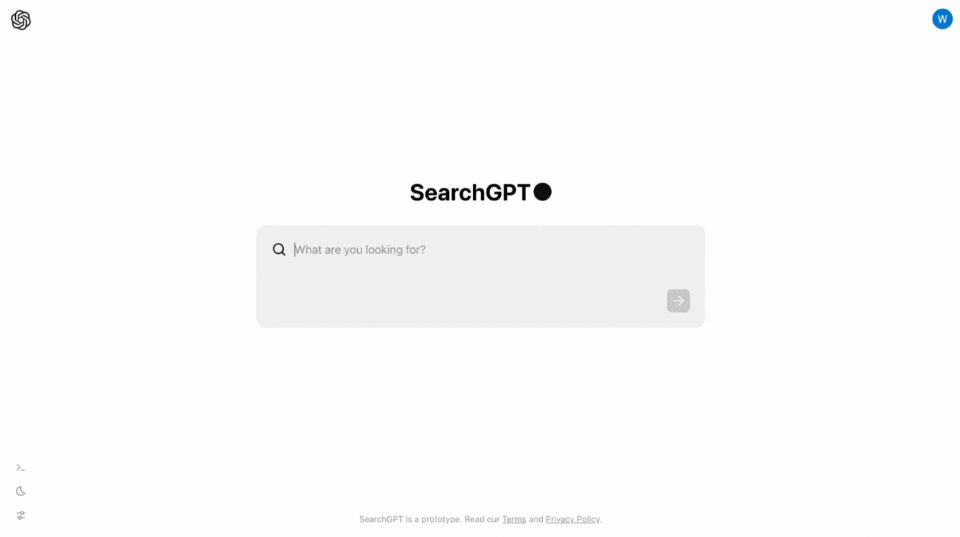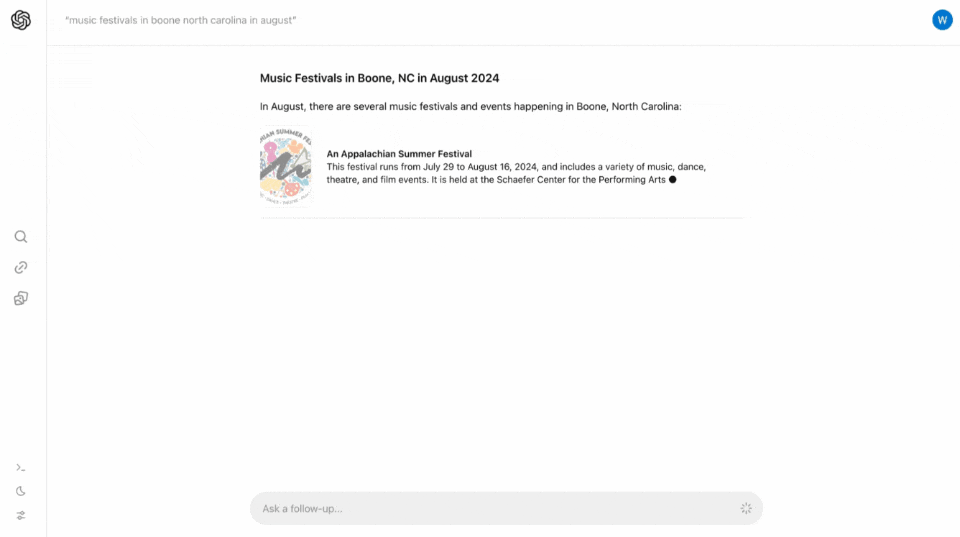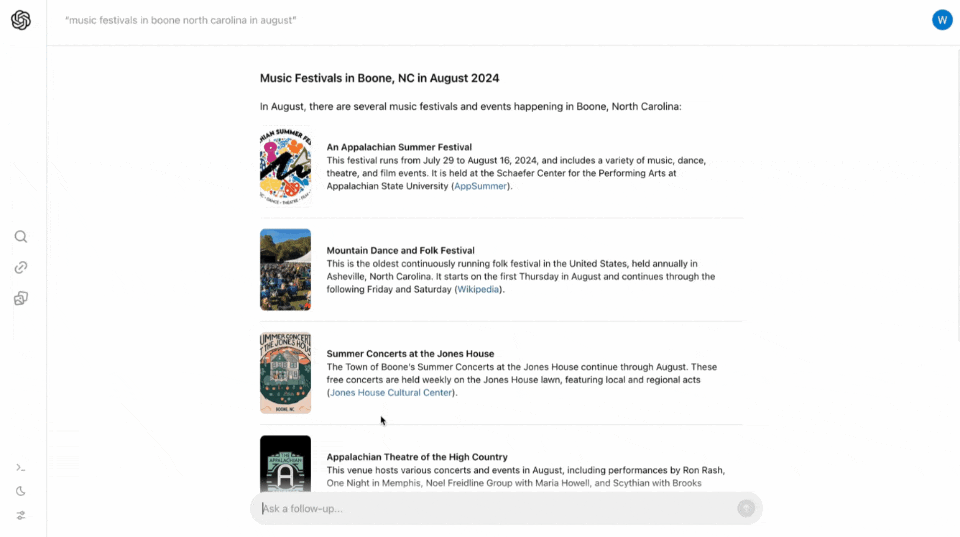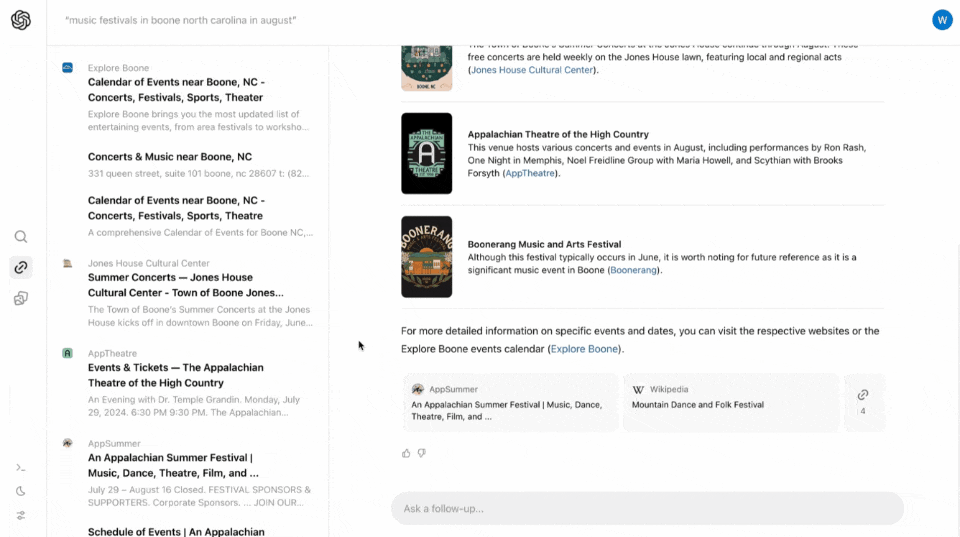
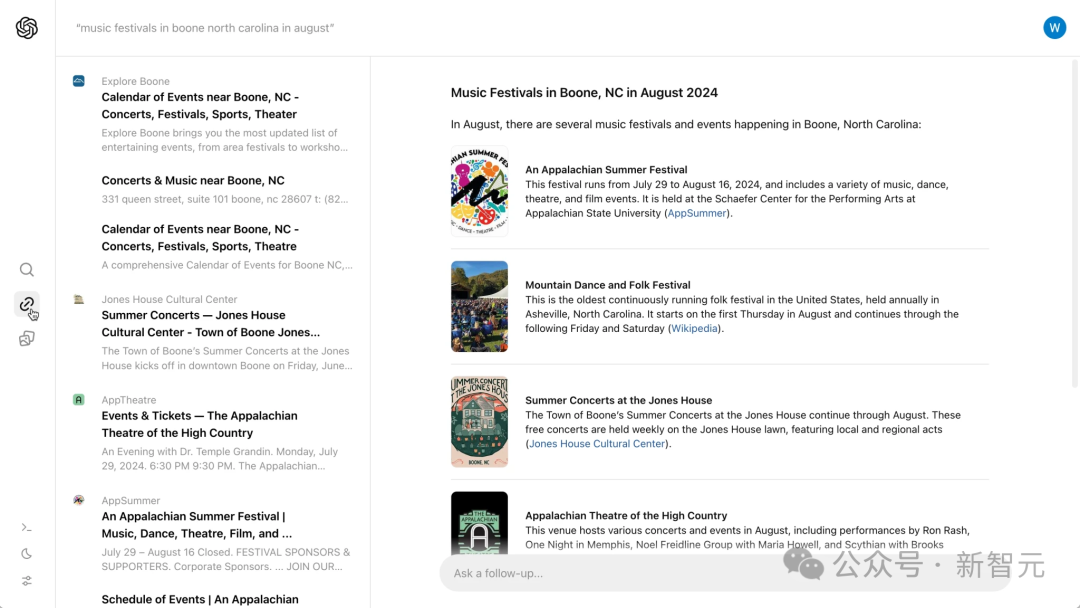
比如在搜索框内输入「八月份在北卡罗莱纳周Boone地区的音乐节」。
SearchGPT瞬间把几个相关的音乐节排列得清清楚楚,点击左侧边栏的链接按钮,还可以看到信息的来源,一键跳转买票。
而且,SearchGPT会为你提供指向相关来源的清晰链接。

2024巴黎奥运会什么时候举行?法国准备得怎么样了?它会援引路透社的报道
根据《连线》杂志的推测,SearchGPT很可能使用了检索增强生成(RAG)方法来减少回答中的幻觉,提高可信度并生成内容来源。
其二,不但能搜索结果,还能就一个细节和延申话题继续对话。
你一定有这样的体验,在搜索过程中会产生一些相关的新问题时,只能另起窗口接着搜,浏览器中开出十多个页面变成了工作日常。
传统搜索引擎就属于单次性搜索产品,检索完一个问题就结束。
而AI搜索附带有生成和对话的能力,每次查询都共享同一个上下文,让用户可以丝滑地继续话题。
最近用过ChatGPT的人,对这种体验一定不陌生。
比如它出了一些西红柿品种后,我们可以继续问:哪些是现在可以种的?
它会详细列出,在七月的明尼苏达州最适合种植的西红柿。

再比如,经过上一轮的搜索,你对Jones House比较感兴趣,就可以直接继续提问,「Jones House适合全家一起去看吗?」
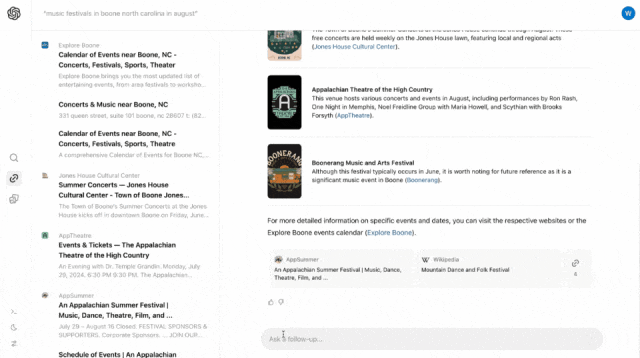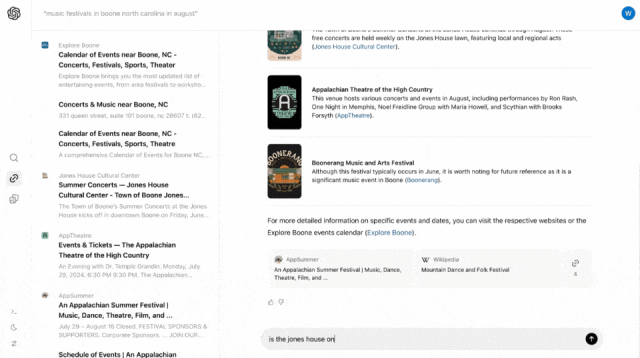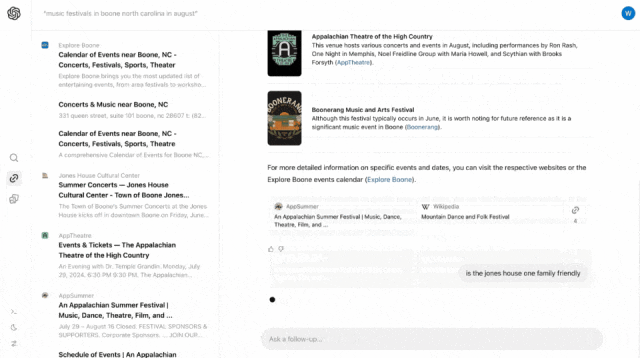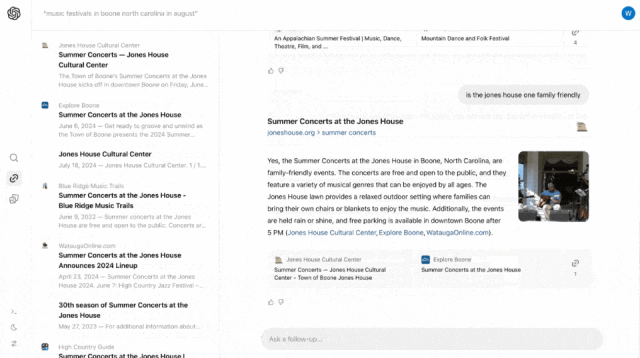
SearchGPT也秒回,「是的,Jones House免费且向公众开放,适合所有年龄段,一家人可以带一块毯子在草坪上享受音乐盛宴。」繁琐的音乐节做功课、看细节和买票等等全在SearchGPT一站式搞定,快速便捷又省心。
这种贴心高效的搜索体验,让人感慨OpenAI果然是最懂用户心的公司,把产品做到了极致。
三、谷歌危了?
而谷歌、Perplexity等搜索巨头们,接下来恐怕不好过了。
奥特曼所言的「搜索功能有改进的空间」,嘲讽意味拉满,内涵的对象自不必多说。

当然,OpenAI也同样瞄准了在AI搜索领域打天下的Perplexity AI。

OpenAI的目标是,最终将AI搜索功能重新整合到旗舰聊天机器人中。
此举是OpenAI挑战谷歌,做出的最新努力。不言而喻,OpenAI在打造强大的AI聊天机器人的早期竞赛中一直处于领先地位。
而在过去20年,谷歌一直在在线搜索领域占据主导地位。
截止6月,谷歌在全球搜索引擎市场中占到了91.05%的份额。微软必应只有3.7%的份额,而Pplexity的份额太低,无法衡量。

不甘落后的谷歌也在过去两年里,尝试将AI植入搜索引擎当中,并在去年带来了1750亿美元的收入,占总销售额一半以上。
与此同时,AI超进化为包括Perplexity在内的竞争对手,开辟了新道路。
这家成立仅两年的初创,专注于一件事「回答引擎」,现估值飙升至10亿美元。
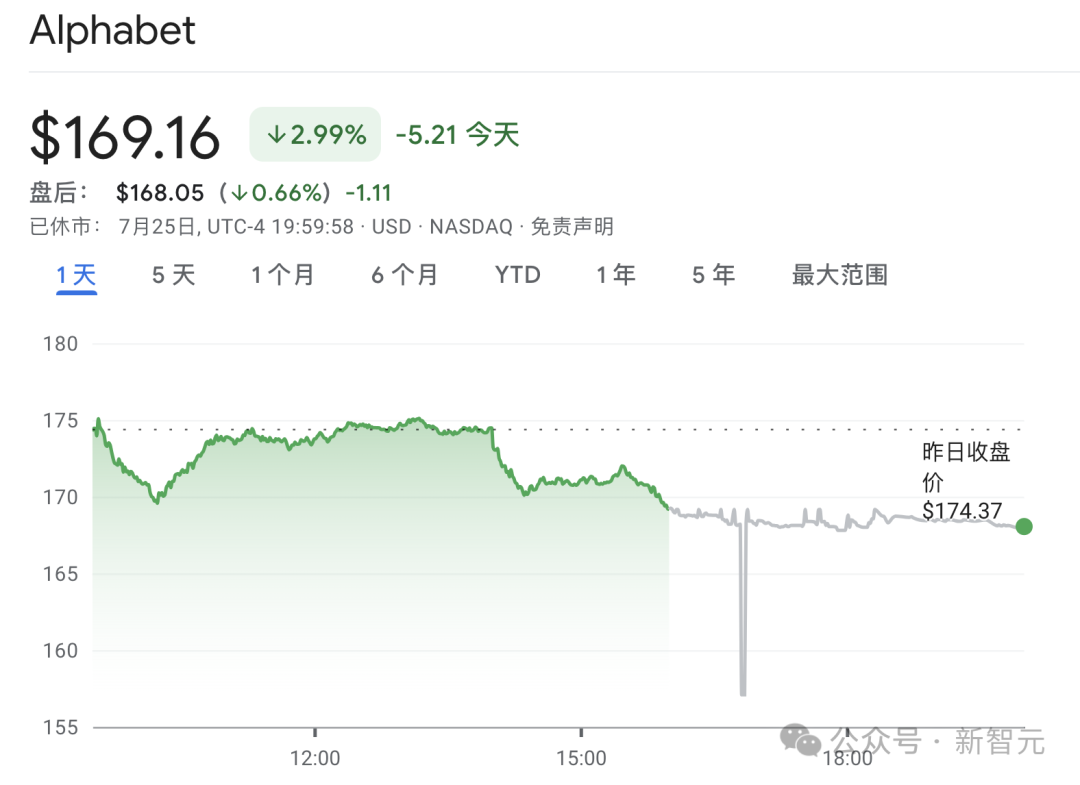
不过,谷歌「一家独大」格局、AI初创单点布局,正在面临被OpenAI颠覆的危险,OpenAI的帖子和博客发出后,谷歌母公司Alphabet的股价也变成了绿油油的一片。
事实上,谷歌在5月召开的I/O大会上就已经抢先OpenAI,发布了自己的AI搜索功能。
当天,CEO劈柴本人站台,自信满满地表示,要用Gemini的AI能力重塑搜索!

后来发生的事情我们都知道了——上线的AI Overview效果过于惨烈,「吃石头」、「披萨涂胶水」等各种翻车案例频发,被全网找乐子。
或许像SearchGPT这样先发布内测,再逐步开放,可以更好地把控产品的质量和口碑。

但也有网友担心,OpenAI又会再次放所有人的鸽子,SearchGPT的上线依旧遥遥无期。
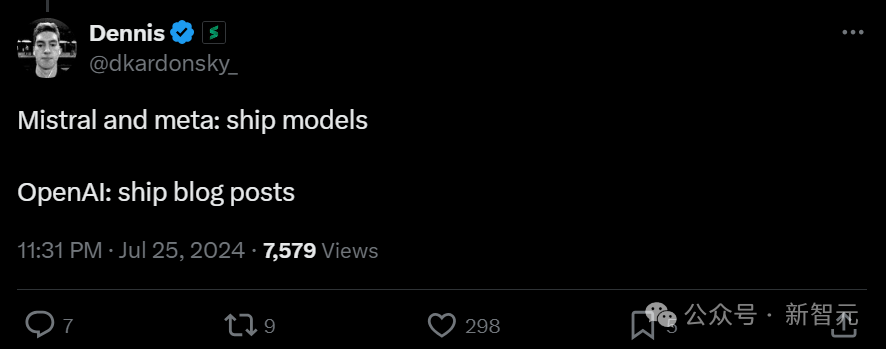
Mistral和Meta: 发模型!
OpenAI:发博客!
四、与出版商和创作者合作
OpenAI表示,SeachGPT不仅仅是搜索,而且致力于打造更佳的用户与出版商和创作者互动体验。
一直以来,搜索引擎一直是出版商和创作者接触用户的主要方式。
现在,利用AI的对话界面,可以帮助用户更快找到理想的高质量内容,并提供多种互动机会。
搜索结果中会包含清晰的内容来源和链接,用户也可以在侧边栏中快速访问更多带有源链接的结果。
News Corp首席执行官Robert Thomson表示,奥特曼和其他OpenAI领导人都认为,任何人工智能驱动的搜索都必须依赖于「由可信来源提供的最高质量、最可靠的信息」。
OpenAI还在博客中特意声明,搜索结果与GenAI模型的训练是分开的。即使不向OpenAI提供训练数据,相关内容也会出现在SearchGPT中。
最近一段时间,OpenAI与多家顶级出版商建立了合作,包括《大西洋月刊》、美联社和Business Insider的母公司Axel Springer,似乎也包括下辖《华尔街日报》、《泰晤士报》、《太阳报》的媒体巨头News Corp。
OpenAI代表向这些出版商展示了搜索功能的原型,并表示,他们可以自行选择内容来源在SerchGPT中的呈现方式。
OpenAI这种谨慎的合作态度似乎是吸取了前段时间的教训,有意规避风险。
上个月,Perplexity在搜索结果中使用了《福布斯》的一篇报道,但没有准确注明来源,直到页面底部才提及。
结果,Perplexity的CEO直接收到了《福布斯》的信函,声称要对这种侵权行为采取法律行动。

由于最近普遍的流量下降趋势,以及AI对内容行业的冲击,出版商对AI重塑新闻的方式越来越感到不安。
他们普遍担心,OpenAI或谷歌的AI搜索工具将根据原始新闻内容提供完整的答案,让用户无需阅读原始文章,进而造成在线流量和广告收入的锐减。
许多出版商都认为,向科技巨头们出售其知识产权的访问权是有价值的,因为他们需要大量数据和内容来完善其人工智能系统并创建SearchGPT等新产品。
或许,从OpenAI与媒体的合作中,我们可以推知它如此急于开展搜索业务的原因。
根据The Information本周的报道,OpenAI正在陷入财务风暴,今年的亏损可能高达50亿美元。
恰好,搜索是一项极其吸金的业务。除了可以与媒体、出版商合作,还有机会通过广告盈利。
财报显示,谷歌搜索业务仅今年第一季度的收入就达到了460亿美元。
有如此丰厚的利润前景,或许奥特曼不会舍得让SearchGPT像Sora和《Her》那样一直鸽下去。
参考资料:
https://openai.com/index/searchgpt-prototype/
https://www.ft.com/content/16c56117-a4f4-45d6-8c7b-3ef80d17d254